 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Divorce Prediction with Machine Learning: Insights and LIME Interpretability
Oct 12, 2023
Divorce is one of the most common social issues in developed countries like in the United States. Almost 50% of the recent marriages turn into an involuntary divorce or separation. While it is evident that people vary to a different extent, and even over time, an incident like Divorce does not interrupt the individual's daily activities; still, Divorce has a severe effect on the individual's mental health, and personal life. Within the scope of this research, the divorce prediction was carried out by evaluating a dataset named by the 'divorce predictor dataset' to correctly classify between married and Divorce people using six different machine learning algorithms- Logistic Regression (LR), Linear Discriminant Analysis (LDA), K-Nearest Neighbors (KNN), Classification and Regression Trees (CART), Gaussian Na\"ive Bayes (NB), and, Support Vector Machines (SVM). Preliminary computational results show that algorithms such as SVM, KNN, and LDA, can perform that task with an accuracy of 98.57%. This work's additional novel contribution is the detailed and comprehensive explanation of prediction probabilities using Local Interpretable Model-Agnostic Explanations (LIME). Utilizing LIME to analyze test results illustrates the possibility of differentiating between divorced and married couples. Finally, we have developed a divorce predictor app considering ten most important features that potentially affect couples in making decisions in their divorce, such tools can be used by any one in order to identify their relationship condition.
PonderV2: Pave the Way for 3D Foundation Model with A Universal Pre-training Paradigm
Oct 13, 2023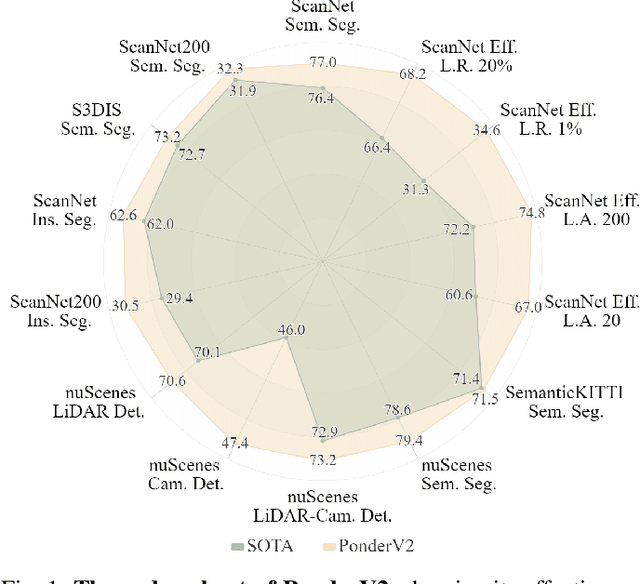
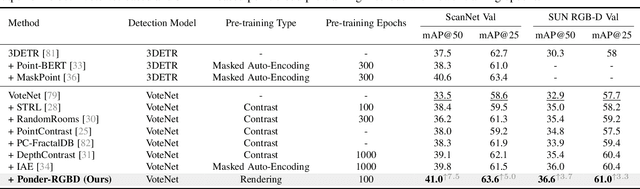
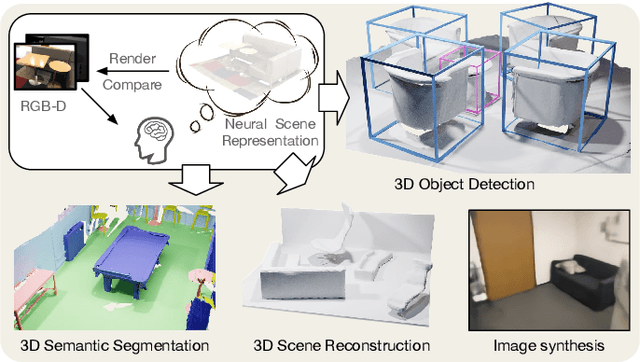

In contrast to numerous NLP and 2D computer vision foundational models, the learning of a robust and highly generalized 3D foundational model poses considerably greater challenges. This is primarily due to the inherent data variability and the diversity of downstream tasks. In this paper, we introduce a comprehensive 3D pre-training framework designed to facilitate the acquisition of efficient 3D representations, thereby establishing a pathway to 3D foundational models. Motivated by the fact that informative 3D features should be able to encode rich geometry and appearance cues that can be utilized to render realistic images, we propose a novel universal paradigm to learn point cloud representations by differentiable neural rendering, serving as a bridge between 3D and 2D worlds. We train a point cloud encoder within a devised volumetric neural renderer by comparing the rendered images with the real images. Notably, our approach demonstrates the seamless integration of the learned 3D encoder into diverse downstream tasks. These tasks encompass not only high-level challenges such as 3D detection and segmentation but also low-level objectives like 3D reconstruction and image synthesis, spanning both indoor and outdoor scenarios. Besides, we also illustrate the capability of pre-training a 2D backbone using the proposed universal methodology, surpassing conventional pre-training methods by a large margin. For the first time, PonderV2 achieves state-of-the-art performance on 11 indoor and outdoor benchmarks. The consistent improvements in various settings imply the effectiveness of the proposed method. Code and models will be made available at https://github.com/OpenGVLab/PonderV2.
Multi-Robot Geometric Task-and-Motion Planning for Collaborative Manipulation Tasks
Oct 13, 2023We address multi-robot geometric task-and-motion planning (MR-GTAMP) problems in synchronous, monotone setups. The goal of the MR-GTAMP problem is to move objects with multiple robots to goal regions in the presence of other movable objects. We focus on collaborative manipulation tasks where the robots have to adopt intelligent collaboration strategies to be successful and effective, i.e., decide which robot should move which objects to which positions, and perform collaborative actions, such as handovers. To endow robots with these collaboration capabilities, we propose to first collect occlusion and reachability information for each robot by calling motion-planning algorithms. We then propose a method that uses the collected information to build a graph structure which captures the precedence of the manipulations of different objects and supports the implementation of a mixed-integer program to guide the search for highly effective collaborative task-and-motion plans. The search process for collaborative task-and-motion plans is based on a Monte-Carlo Tree Search (MCTS) exploration strategy to achieve exploration-exploitation balance. We evaluate our framework in two challenging MR-GTAMP domains and show that it outperforms two state-of-the-art baselines with respect to the planning time, the resulting plan length and the number of objects moved. We also show that our framework can be applied to underground mining operations where a robotic arm needs to coordinate with an autonomous roof bolter. We demonstrate plan execution in two roof-bolting scenarios both in simulation and on robots.
A study on the impact of pre-trained model on Just-In-Time defect prediction
Sep 05, 2023
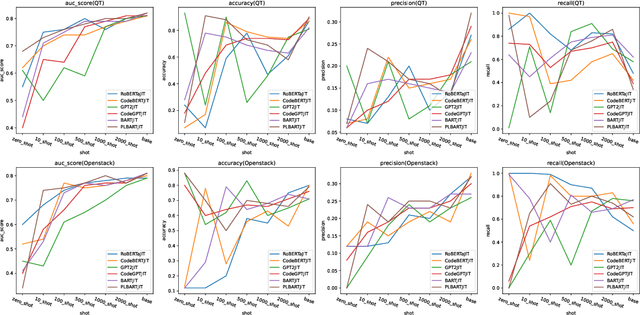
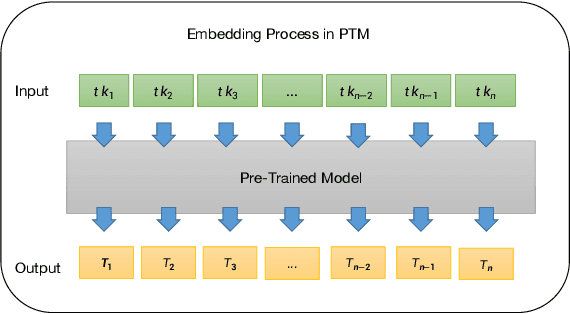
Previous researchers conducting Just-In-Time (JIT) defect prediction tasks have primarily focused on the performance of individual pre-trained models, without exploring the relationship between different pre-trained models as backbones. In this study, we build six models: RoBERTaJIT, CodeBERTJIT, BARTJIT, PLBARTJIT, GPT2JIT, and CodeGPTJIT, each with a distinct pre-trained model as its backbone. We systematically explore the differences and connections between these models. Specifically, we investigate the performance of the models when using Commit code and Commit message as inputs, as well as the relationship between training efficiency and model distribution among these six models. Additionally, we conduct an ablation experiment to explore the sensitivity of each model to inputs. Furthermore, we investigate how the models perform in zero-shot and few-shot scenarios. Our findings indicate that each model based on different backbones shows improvements, and when the backbone's pre-training model is similar, the training resources that need to be consumed are much more closer. We also observe that Commit code plays a significant role in defect detection, and different pre-trained models demonstrate better defect detection ability with a balanced dataset under few-shot scenarios. These results provide new insights for optimizing JIT defect prediction tasks using pre-trained models and highlight the factors that require more attention when constructing such models. Additionally, CodeGPTJIT and GPT2JIT achieved better performance than DeepJIT and CC2Vec on the two datasets respectively under 2000 training samples. These findings emphasize the effectiveness of transformer-based pre-trained models in JIT defect prediction tasks, especially in scenarios with limited training data.
Beyond Sharing: Conflict-Aware Multivariate Time Series Anomaly Detection
Aug 25, 2023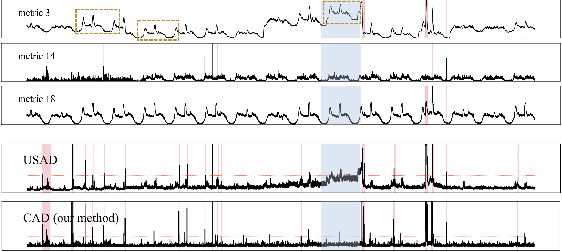
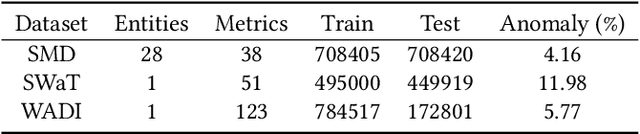
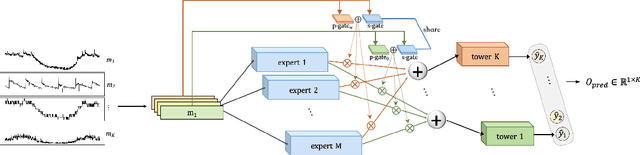
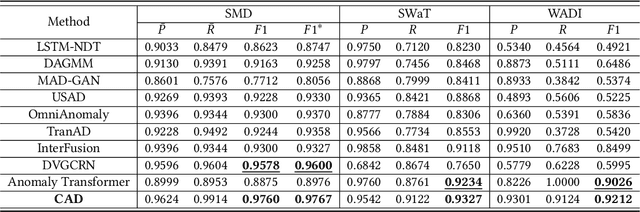
Massive key performance indicators (KPIs) are monitored as multivariate time series data (MTS) to ensure the reliability of the software applications and service system. Accurately detecting the abnormality of MTS is very critical for subsequent fault elimination. The scarcity of anomalies and manual labeling has led to the development of various self-supervised MTS anomaly detection (AD) methods, which optimize an overall objective/loss encompassing all metrics' regression objectives/losses. However, our empirical study uncovers the prevalence of conflicts among metrics' regression objectives, causing MTS models to grapple with different losses. This critical aspect significantly impacts detection performance but has been overlooked in existing approaches. To address this problem, by mimicking the design of multi-gate mixture-of-experts (MMoE), we introduce CAD, a Conflict-aware multivariate KPI Anomaly Detection algorithm. CAD offers an exclusive structure for each metric to mitigate potential conflicts while fostering inter-metric promotions. Upon thorough investigation, we find that the poor performance of vanilla MMoE mainly comes from the input-output misalignment settings of MTS formulation and convergence issues arising from expansive tasks. To address these challenges, we propose a straightforward yet effective task-oriented metric selection and p&s (personalized and shared) gating mechanism, which establishes CAD as the first practicable multi-task learning (MTL) based MTS AD model. Evaluations on multiple public datasets reveal that CAD obtains an average F1-score of 0.943 across three public datasets, notably outperforming state-of-the-art methods. Our code is accessible at https://github.com/dawnvince/MTS_CAD.
Noisy-ArcMix: Additive Noisy Angular Margin Loss Combined With Mixup Anomalous Sound Detection
Oct 10, 2023Unsupervised anomalous sound detection (ASD) aims to identify anomalous sounds by learning the features of normal operational sounds and sensing their deviations. Recent approaches have focused on the self-supervised task utilizing the classification of normal data, and advanced models have shown that securing representation space for anomalous data is important through representation learning yielding compact intra-class and well-separated intra-class distributions. However, we show that conventional approaches often fail to ensure sufficient intra-class compactness and exhibit angular disparity between samples and their corresponding centers. In this paper, we propose a training technique aimed at ensuring intra-class compactness and increasing the angle gap between normal and abnormal samples. Furthermore, we present an architecture that extracts features for important temporal regions, enabling the model to learn which time frames should be emphasized or suppressed. Experimental results demonstrate that the proposed method achieves the best performance giving 0.90%, 0.83%, and 2.16% improvement in terms of AUC, pAUC, and mAUC, respectively, compared to the state-of-the-art method on DCASE 2020 Challenge Task2 dataset.
Predicting Three Types of Freezing of Gait Events Using Deep Learning Models
Oct 10, 2023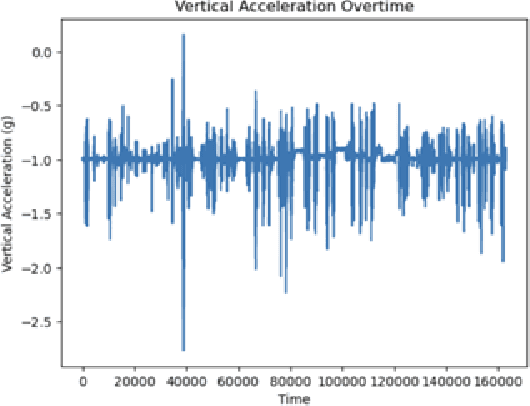
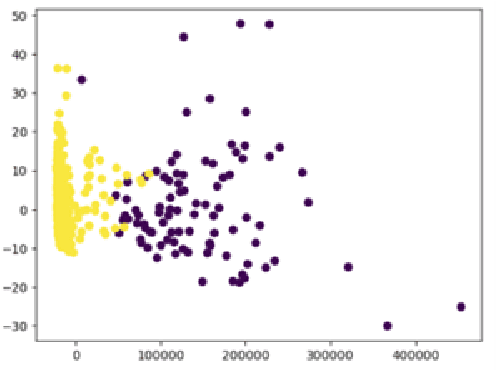
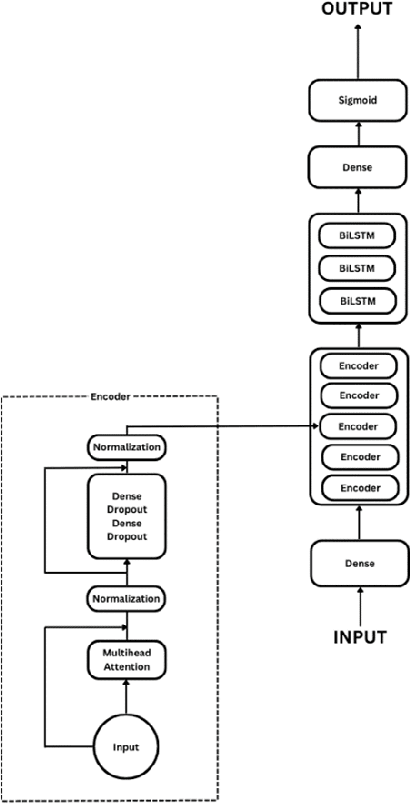
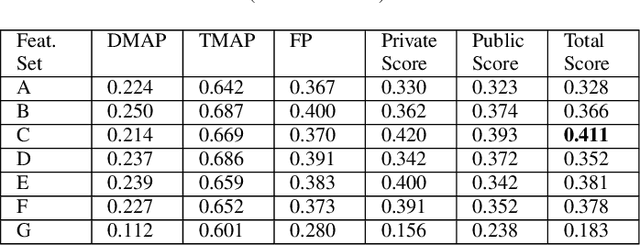
Freezing of gait is a Parkinson's Disease symptom that episodically inflicts a patient with the inability to step or turn while walking. While medical experts have discovered various triggers and alleviating actions for freezing of gait, the underlying causes and prediction models are still being explored today. Current freezing of gait prediction models that utilize machine learning achieve high sensitivity and specificity in freezing of gait predictions based on time-series data; however, these models lack specifications on the type of freezing of gait events. We develop various deep learning models using the transformer encoder architecture plus Bidirectional LSTM layers and different feature sets to predict the three different types of freezing of gait events. The best performing model achieves a score of 0.427 on testing data, which would rank top 5 in Kaggle's Freezing of Gait prediction competition, hosted by THE MICHAEL J. FOX FOUNDATION. However, we also recognize overfitting in training data that could be potentially improved through pseudo labelling on additional data and model architecture simplification.
Hierarchical Mask2Former: Panoptic Segmentation of Crops, Weeds and Leaves
Oct 10, 2023
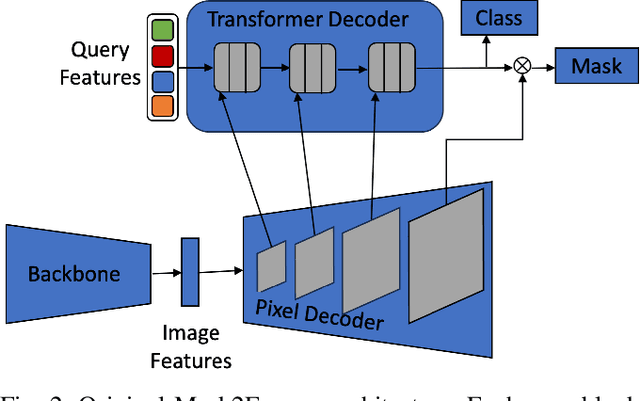
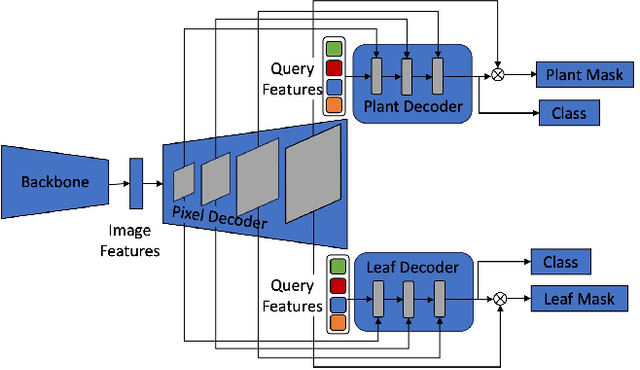
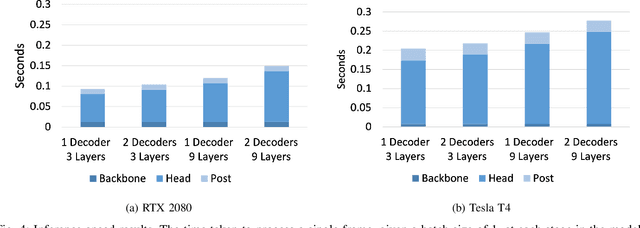
Advancements in machine vision that enable detailed inferences to be made from images have the potential to transform many sectors including agriculture. Precision agriculture, where data analysis enables interventions to be precisely targeted, has many possible applications. Precision spraying, for example, can limit the application of herbicide only to weeds, or limit the application of fertiliser only to undernourished crops, instead of spraying the entire field. The approach promises to maximise yields, whilst minimising resource use and harms to the surrounding environment. To this end, we propose a hierarchical panoptic segmentation method to simultaneously identify indicators of plant growth and locate weeds within an image. We adapt Mask2Former, a state-of-the-art architecture for panoptic segmentation, to predict crop, weed and leaf masks. We achieve a PQ{\dag} of 75.99. Additionally, we explore approaches to make the architecture more compact and therefore more suitable for time and compute constrained applications. With our more compact architecture, inference is up to 60% faster and the reduction in PQ{\dag} is less than 1%.
Neural Harmonium: An Interpretable Deep Structure for Nonlinear Dynamic System Identification with Application to Audio Processing
Oct 10, 2023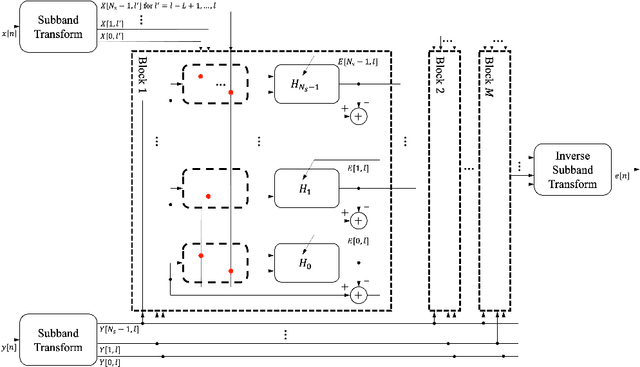
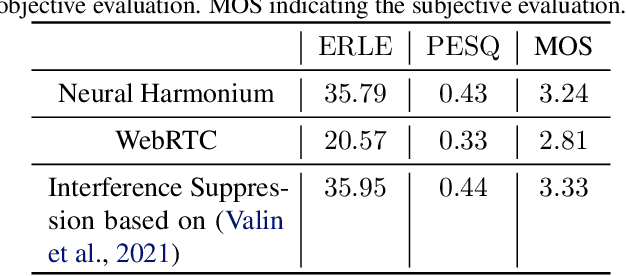
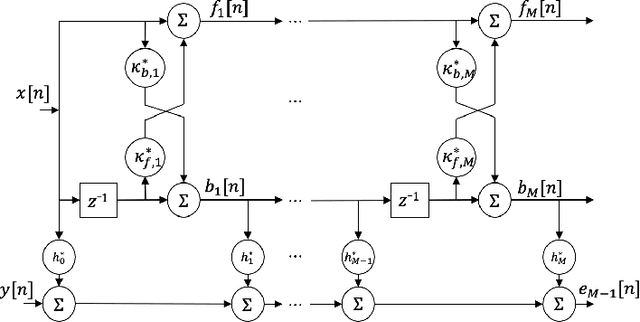

Improving the interpretability of deep neural networks has recently gained increased attention, especially when the power of deep learning is leveraged to solve problems in physics. Interpretability helps us understand a model's ability to generalize and reveal its limitations. In this paper, we introduce a causal interpretable deep structure for modeling dynamic systems. Our proposed model makes use of the harmonic analysis by modeling the system in a time-frequency domain while maintaining high temporal and spectral resolution. Moreover, the model is built in an order recursive manner which allows for fast, robust, and exact second order optimization without the need for an explicit Hessian calculation. To circumvent the resulting high dimensionality of the building blocks of our system, a neural network is designed to identify the frequency interdependencies. The proposed model is illustrated and validated on nonlinear system identification problems as required for audio signal processing tasks. Crowd-sourced experimentation contrasting the performance of the proposed approach to other state-of-the-art solutions on an acoustic echo cancellation scenario confirms the effectiveness of our method for real-life applications.
Persis: A Persian Font Recognition Pipeline Using Convolutional Neural Networks
Oct 10, 2023



What happens if we encounter a suitable font for our design work but do not know its name? Visual Font Recognition (VFR) systems are used to identify the font typeface in an image. These systems can assist graphic designers in identifying fonts used in images. A VFR system also aids in improving the speed and accuracy of Optical Character Recognition (OCR) systems. In this paper, we introduce the first publicly available datasets in the field of Persian font recognition and employ Convolutional Neural Networks (CNN) to address this problem. The results show that the proposed pipeline obtained 78.0% top-1 accuracy on our new datasets, 89.1% on the IDPL-PFOD dataset, and 94.5% on the KAFD dataset. Furthermore, the average time spent in the entire pipeline for one sample of our proposed datasets is 0.54 and 0.017 seconds for CPU and GPU, respectively. We conclude that CNN methods can be used to recognize Persian fonts without the need for additional pre-processing steps such as feature extraction, binarization, normalization, etc.