 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ConvNeXtv2 Fusion with Mask R-CNN for Automatic Region Based Coronary Artery Stenosis Detection for Disease Diagnosis
Oct 07, 2023
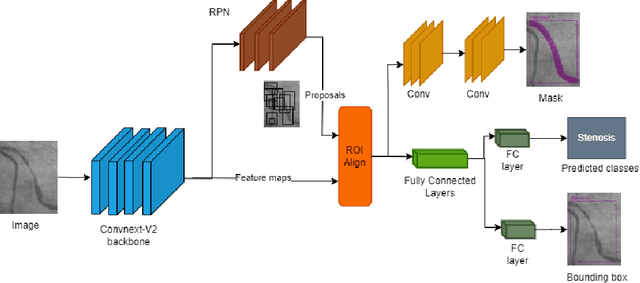

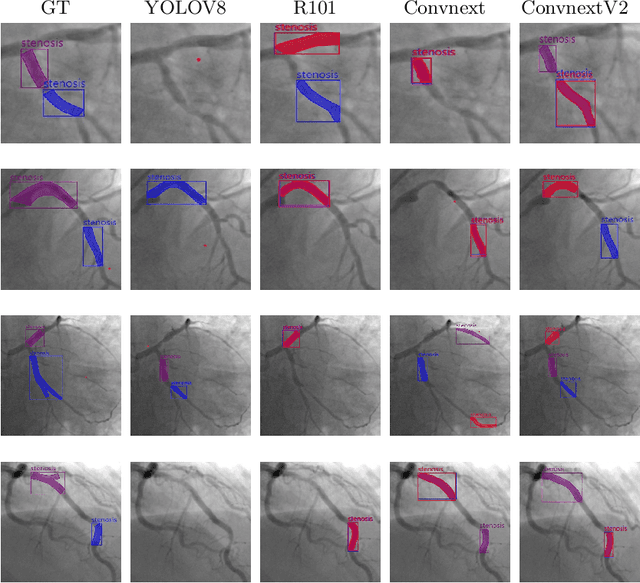

Coronary Artery Diseases although preventable are one of the leading cause of mortality worldwide. Due to the onerous nature of diagnosis, tackling CADs has proved challenging. This study addresses the automation of resource-intensive and time-consuming process of manually detecting stenotic lesions in coronary arteries in X-ray coronary angiography images. To overcome this challenge, we employ a specialized Convnext-V2 backbone based Mask RCNN model pre-trained for instance segmentation tasks. Our empirical findings affirm that the proposed model exhibits commendable performance in identifying stenotic lesions. Notably, our approach achieves a substantial F1 score of 0.5353 in this demanding task, underscoring its effectiveness in streamlining this intensive process.
Adaptive Quantization for Key Generation in Low-Power Wide-Area Networks
Oct 11, 2023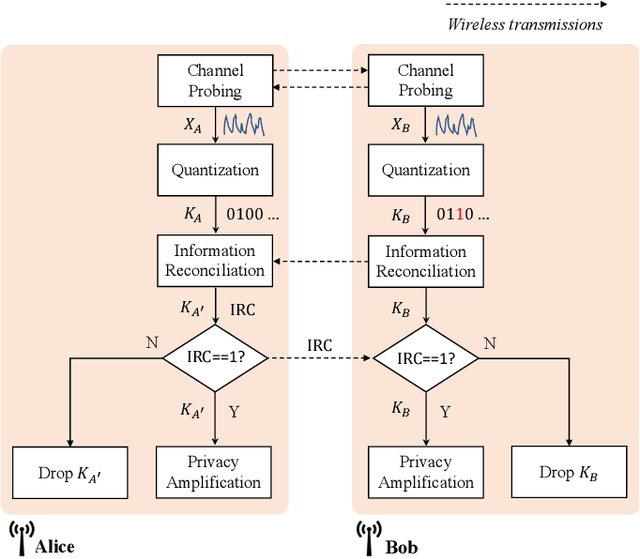
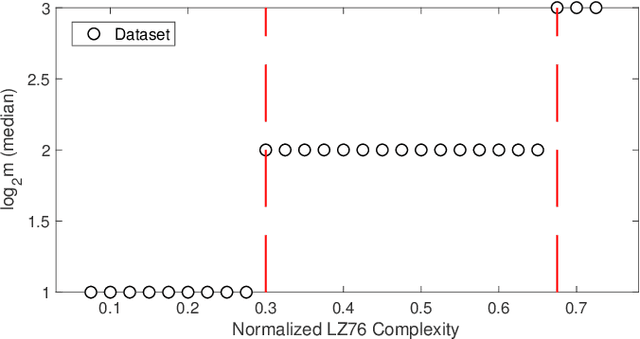
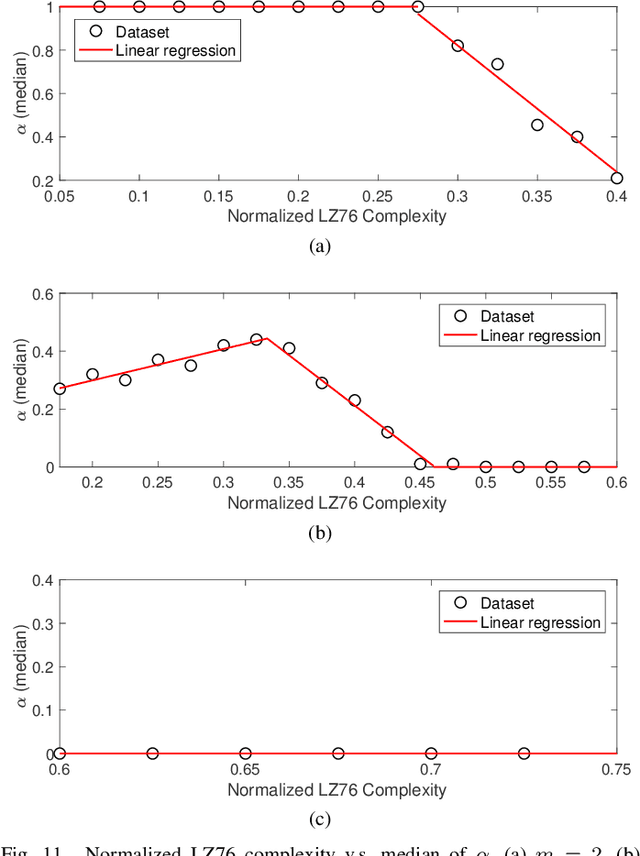
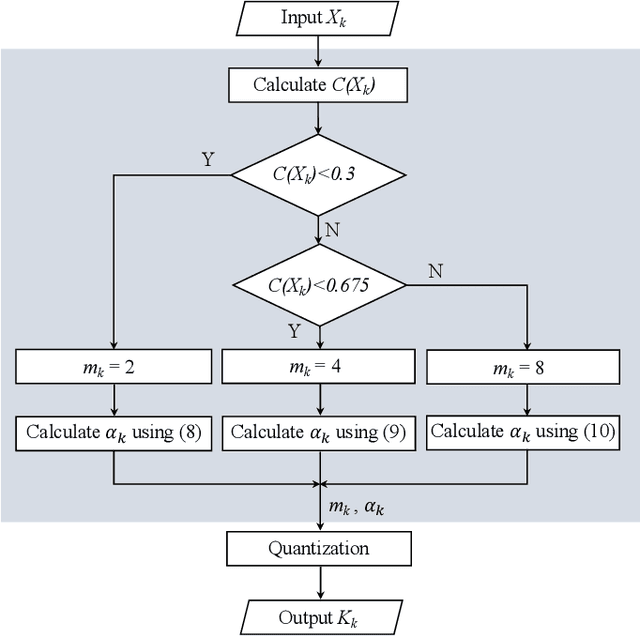
Physical layer key generation based on reciprocal and random wireless channels has been an attractive solution for securing resource-constrained low-power wide-area networks (LPWANs). When quantizing channel measurements, namely received signal strength indicator (RSSI), into key bits, the existing works mainly adopt fixed quantization levels and guard band parameters, which fail to fully extract keys from RSSI measurements. In this paper, we propose a novel adaptive quantization scheme for key generation in LPWANs, taking LoRa as a case study. The proposed adaptive quantization scheme can dynamically adjust the quantization parameters according to the randomness of RSSI measurements estimated by Lempel-Ziv complexity (LZ76), while ensuring a predefined key disagreement ratio (KDR). Specifically, our scheme uses pre-trained linear regression models to determine the appropriate quantization level and guard band parameter for each segment of RSSI measurements. Moreover, we propose a guard band parameter calibration scheme during information reconciliation during real-time key generation operation. Experimental evaluations using LoRa devices show that the proposed adaptive quantization scheme outperforms the benchmark differential quantization and fixed quantization with up to 2.35$\times$ and 1.51$\times$ key generation rate (KGR) gains, respectively.
Towards Open-Set Test-Time Adaptation Utilizing the Wisdom of Crowds in Entropy Minimization
Sep 04, 2023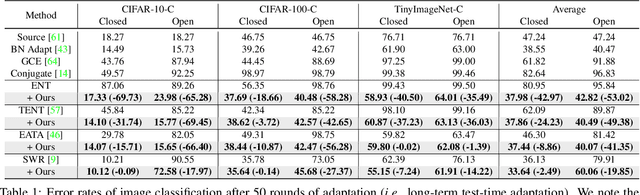
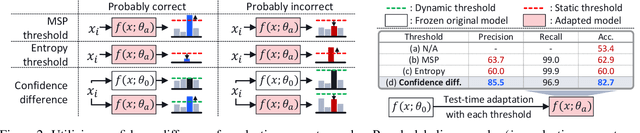
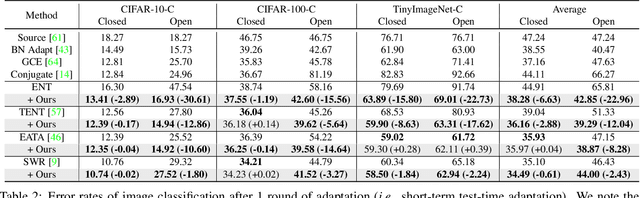
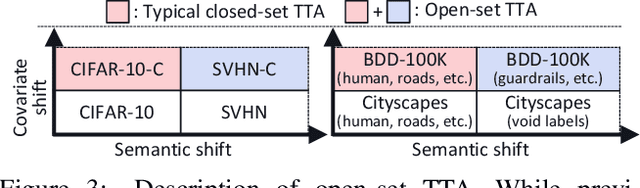
Test-time adaptation (TTA) methods, which generally rely on the model's predictions (e.g., entropy minimization) to adapt the source pretrained model to the unlabeled target domain, suffer from noisy signals originating from 1) incorrect or 2) open-set predictions. Long-term stable adaptation is hampered by such noisy signals, so training models without such error accumulation is crucial for practical TTA. To address these issues, including open-set TTA, we propose a simple yet effective sample selection method inspired by the following crucial empirical finding. While entropy minimization compels the model to increase the probability of its predicted label (i.e., confidence values), we found that noisy samples rather show decreased confidence values. To be more specific, entropy minimization attempts to raise the confidence values of an individual sample's prediction, but individual confidence values may rise or fall due to the influence of signals from numerous other predictions (i.e., wisdom of crowds). Due to this fact, noisy signals misaligned with such 'wisdom of crowds', generally found in the correct signals, fail to raise the individual confidence values of wrong samples, despite attempts to increase them. Based on such findings, we filter out the samples whose confidence values are lower in the adapted model than in the original model, as they are likely to be noisy. Our method is widely applicable to existing TTA methods and improves their long-term adaptation performance in both image classification (e.g., 49.4% reduced error rates with TENT) and semantic segmentation (e.g., 11.7% gain in mIoU with TENT).
Development of a Neural Network-based Method for Improved Imputation of Missing Values in Time Series Data by Repurposing DataWig
Aug 18, 2023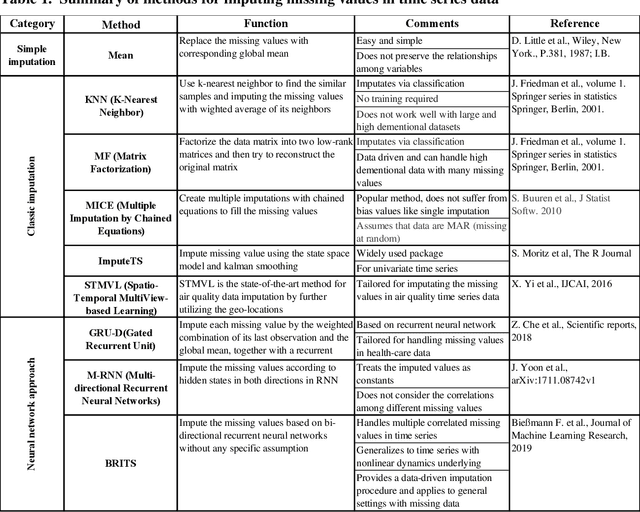
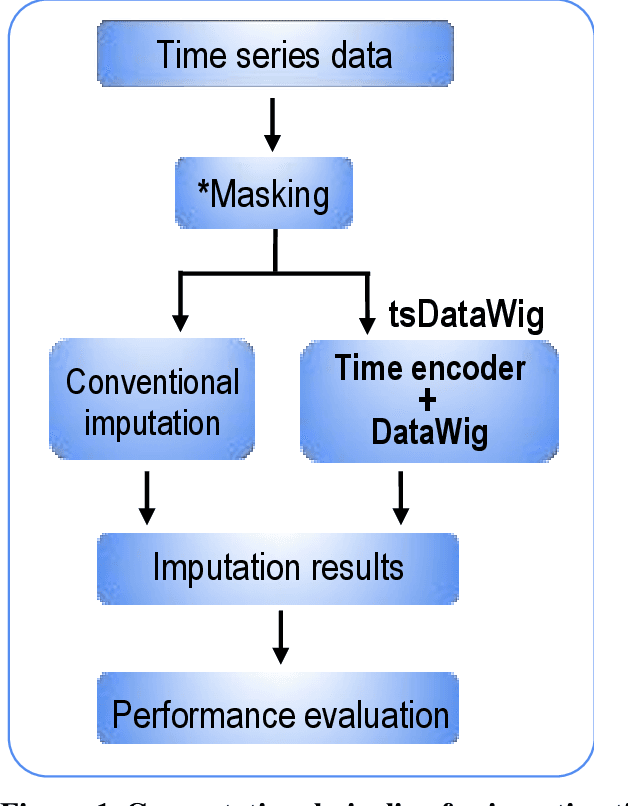
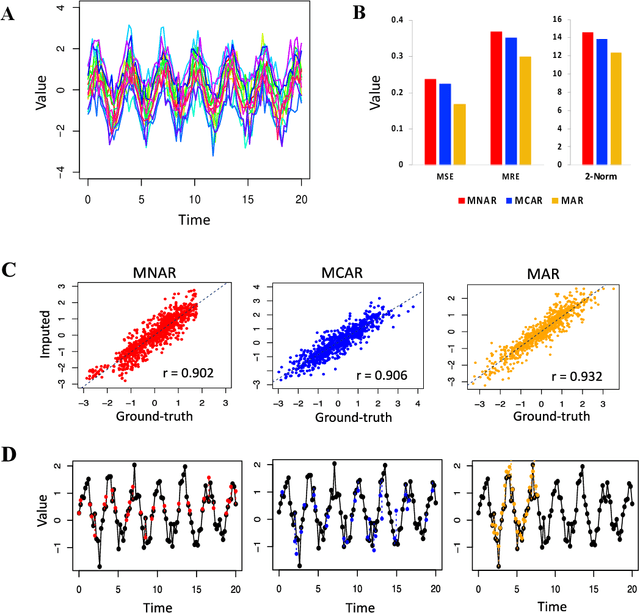
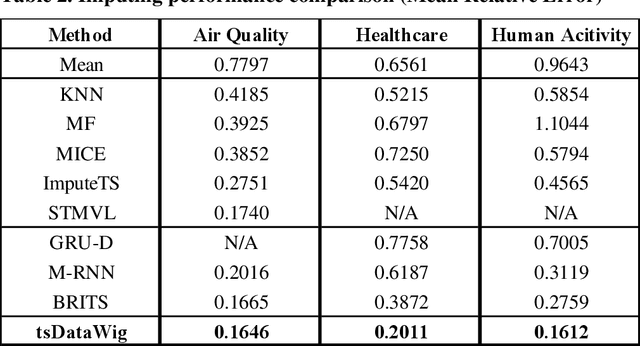
Time series data are observations collected over time intervals. Successful analysis of time series data captures patterns such as trends, cyclicity and irregularity, which are crucial for decision making in research, business, and governance. However, missing values in time series data occur often and present obstacles to successful analysis, thus they need to be filled with alternative values, a process called imputation. Although various approaches have been attempted for robust imputation of time series data, even the most advanced methods still face challenges including limited scalability, poor capacity to handle heterogeneous data types and inflexibility due to requiring strong assumptions of data missing mechanisms. Moreover, the imputation accuracy of these methods still has room for improvement. In this study, I developed tsDataWig (time-series DataWig) by modifying DataWig, a neural network-based method that possesses the capacity to process large datasets and heterogeneous data types but was designed for non-time series data imputation. Unlike the original DataWig, tsDataWig can directly handle values of time variables and impute missing values in complex time series datasets. Using one simulated and three different complex real-world time series datasets, I demonstrated that tsDataWig outperforms the original DataWig and the current state-of-the-art methods for time series data imputation and potentially has broad application due to not requiring strong assumptions of data missing mechanisms. This study provides a valuable solution for robustly imputing missing values in challenging time series datasets, which often contain millions of samples, high dimensional variables, and heterogeneous data types.
LESSON: Learning to Integrate Exploration Strategies for Reinforcement Learning via an Option Framework
Oct 05, 2023In this paper, a unified framework for exploration in reinforcement learning (RL) is proposed based on an option-critic model. The proposed framework learns to integrate a set of diverse exploration strategies so that the agent can adaptively select the most effective exploration strategy over time to realize a relevant exploration-exploitation trade-off for each given task. The effectiveness of the proposed exploration framework is demonstrated by various experiments in the MiniGrid and Atari environments.
Explicit Time Embedding Based Cascade Attention Network for Information Popularity Prediction
Aug 19, 2023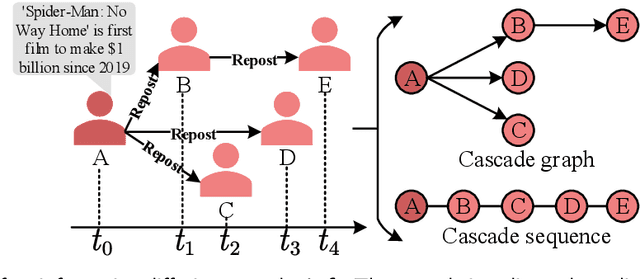
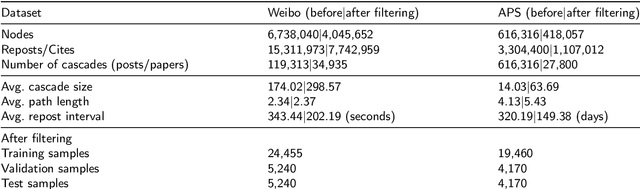
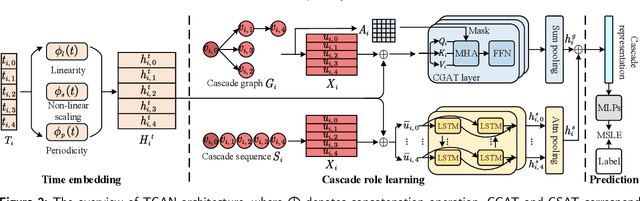
Predicting information cascade popularity is a fundamental problem in social networks. Capturing temporal attributes and cascade role information (e.g., cascade graphs and cascade sequences) is necessary for understanding the information cascade. Current methods rarely focus on unifying this information for popularity predictions, which prevents them from effectively modeling the full properties of cascades to achieve satisfactory prediction performances. In this paper, we propose an explicit Time embedding based Cascade Attention Network (TCAN) as a novel popularity prediction architecture for large-scale information networks. TCAN integrates temporal attributes (i.e., periodicity, linearity, and non-linear scaling) into node features via a general time embedding approach (TE), and then employs a cascade graph attention encoder (CGAT) and a cascade sequence attention encoder (CSAT) to fully learn the representation of cascade graphs and cascade sequences. We use two real-world datasets (i.e., Weibo and APS) with tens of thousands of cascade samples to validate our methods. Experimental results show that TCAN obtains mean logarithm squared errors of 2.007 and 1.201 and running times of 1.76 hours and 0.15 hours on both datasets, respectively. Furthermore, TCAN outperforms other representative baselines by 10.4%, 3.8%, and 10.4% in terms of MSLE, MAE, and R-squared on average while maintaining good interpretability.
Hybrid Retrieval-Augmented Generation for Real-time Composition Assistance
Aug 08, 2023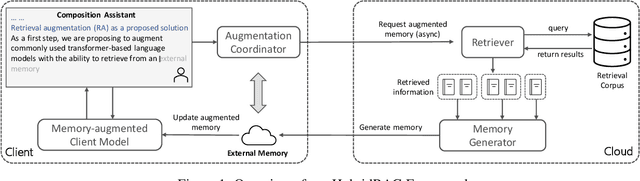

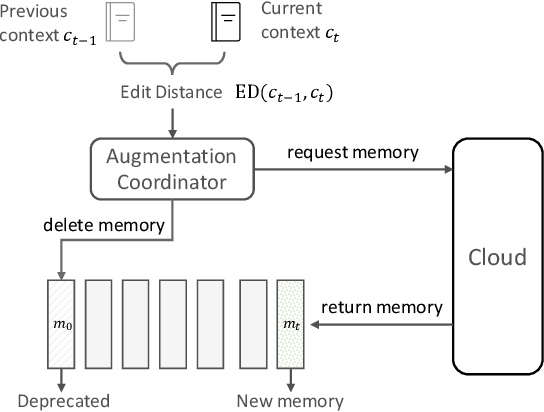

Retrieval augmented models show promise in enhancing traditional language models by improving their contextual understanding, integrating private data, and reducing hallucination. However, the processing time required for retrieval augmented large language models poses a challenge when applying them to tasks that require real-time responses, such as composition assistance. To overcome this limitation, we propose the Hybrid Retrieval-Augmented Generation (HybridRAG) framework that leverages a hybrid setting that combines both client and cloud models. HybridRAG incorporates retrieval-augmented memory generated asynchronously by a Large Language Model (LLM) in the cloud. By integrating this retrieval augmented memory, the client model acquires the capability to generate highly effective responses, benefiting from the LLM's capabilities. Furthermore, through asynchronous memory integration, the client model is capable of delivering real-time responses to user requests without the need to wait for memory synchronization from the cloud. Our experiments on Wikitext and Pile subsets show that HybridRAG achieves lower latency than a cloud-based retrieval-augmented LLM, while outperforming client-only models in utility.
DomainAdaptor: A Novel Approach to Test-time Adaptation
Aug 20, 2023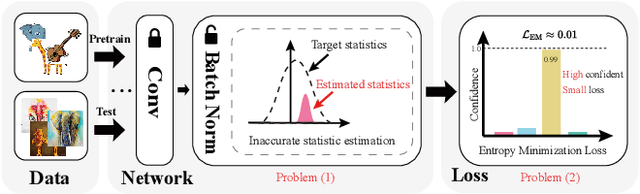
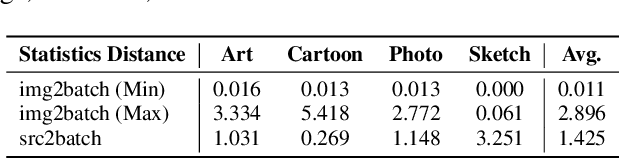

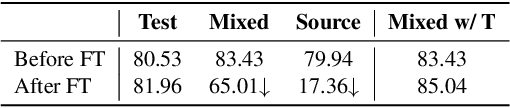
To deal with the domain shift between training and test samples, current methods have primarily focused on learning generalizable features during training and ignore the specificity of unseen samples that are also critical during the test. In this paper, we investigate a more challenging task that aims to adapt a trained CNN model to unseen domains during the test. To maximumly mine the information in the test data, we propose a unified method called DomainAdaptor for the test-time adaptation, which consists of an AdaMixBN module and a Generalized Entropy Minimization (GEM) loss. Specifically, AdaMixBN addresses the domain shift by adaptively fusing training and test statistics in the normalization layer via a dynamic mixture coefficient and a statistic transformation operation. To further enhance the adaptation ability of AdaMixBN, we design a GEM loss that extends the Entropy Minimization loss to better exploit the information in the test data. Extensive experiments show that DomainAdaptor consistently outperforms the state-of-the-art methods on four benchmarks. Furthermore, our method brings more remarkable improvement against existing methods on the few-data unseen domain. The code is available at https://github.com/koncle/DomainAdaptor.
Early Warning via tipping-preserving latent stochastic dynamical system and meta label correcting
Oct 09, 2023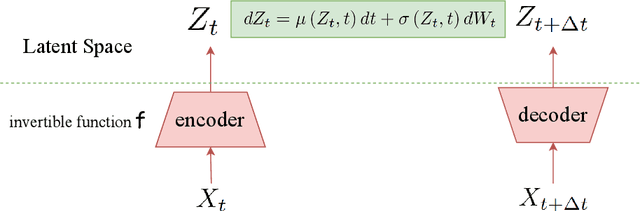
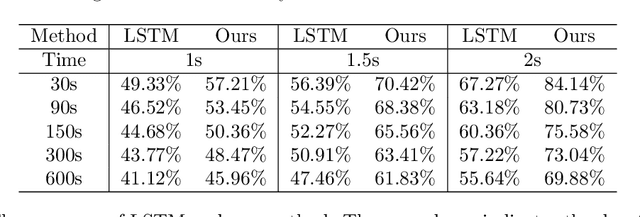
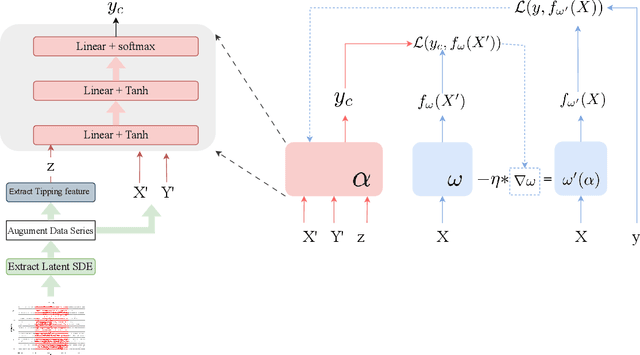
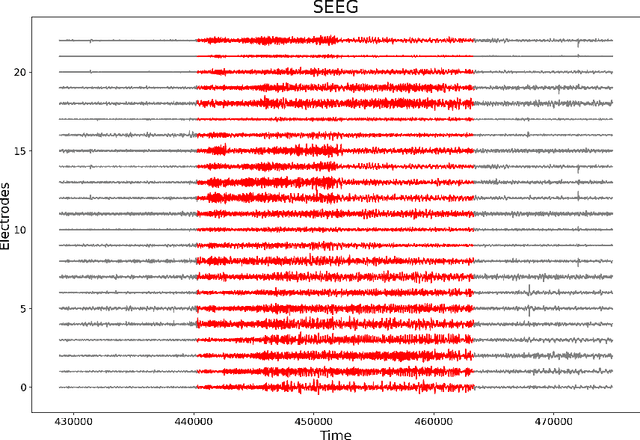
Early warning for epilepsy patients is crucial for their safety and well-being, in terms of preventing or minimizing the severity of seizures. Through the patients' EEG data, we propose a meta learning framework for improving prediction on early ictal signals. To better utilize the meta label corrector method, we fuse the information from both the real data and the augmented data from the latent Stochastic differential equation(SDE). Besides, we also optimally select the latent dynamical system via distribution of transition time between real data and that from the latent SDE. In this way, the extracted tipping dynamical feature is also integrated into the meta network to better label the noisy data. To validate our method, LSTM is implemented as the baseline model. We conduct a series of experiments to predict seizure in various long-term window from 1-2 seconds input data and find surprisingly increment of prediction accuracy.
Exoskeleton-Mediated Physical Human-Human Interaction for a Sit-to-Stand Rehabilitation Task
Oct 09, 2023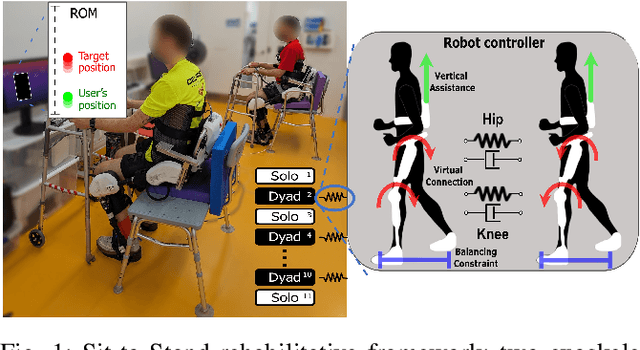
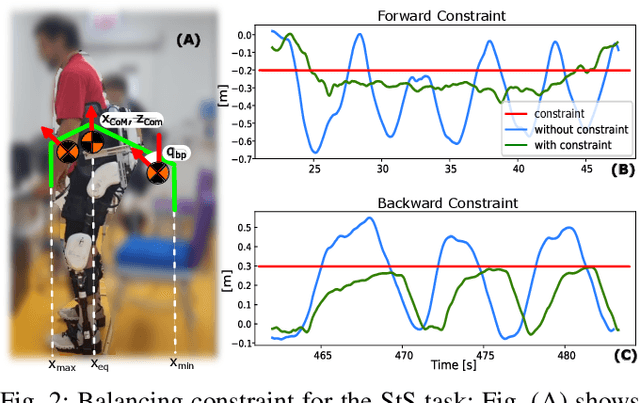
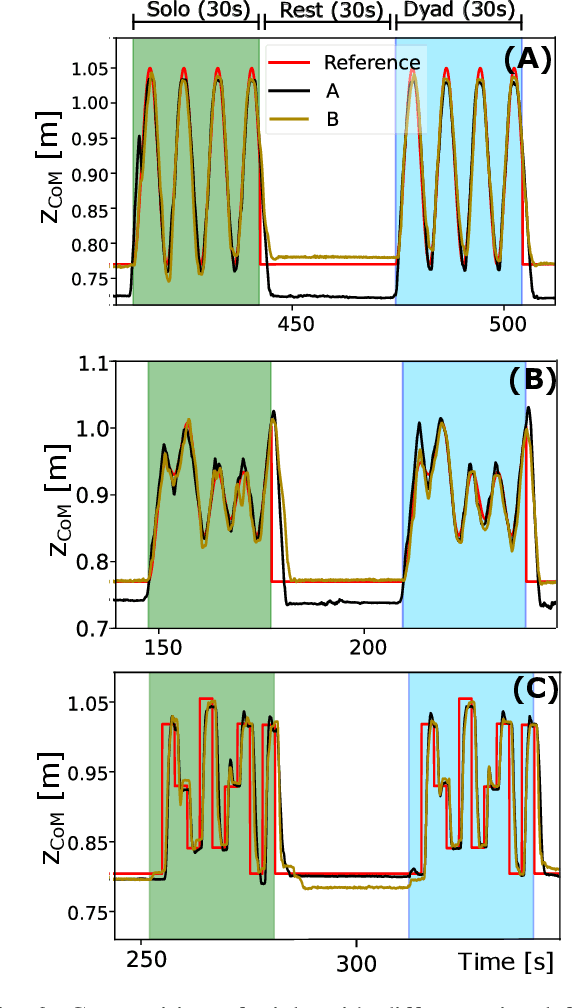
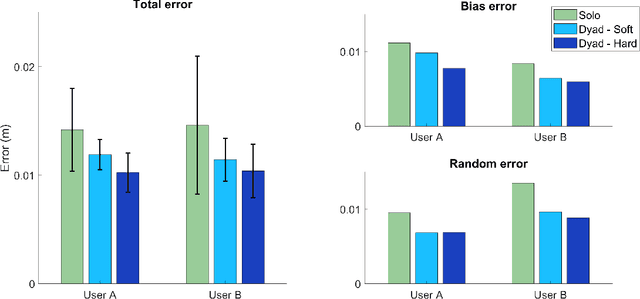
Sit-to-Stand (StS) is a fundamental daily activity that can be challenging for stroke survivors due to strength, motor control, and proprioception deficits in their lower limbs. Existing therapies involve repetitive StS exercises, but these can be physically demanding for therapists while assistive devices may limit patient participation and hinder motor learning. To address these challenges, this work proposes the use of two lower-limb exoskeletons to mediate physical interaction between therapists and patients during a StS rehabilitative task. This approach offers several advantages, including improved therapist-patient interaction, safety enforcement, and performance quantification. The whole body control of the two exoskeletons transmits online feedback between the two users, but at the same time assists in movement and ensures balance, and thus helping subjects with greater difficulty. In this study we present the architecture of the framework, presenting and discussing some technical choices made in the design.