 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Shallow Cross-Encoders for Low-Latency Retrieval
Mar 29, 2024
Transformer-based Cross-Encoders achieve state-of-the-art effectiveness in text retrieval. However, Cross-Encoders based on large transformer models (such as BERT or T5) are computationally expensive and allow for scoring only a small number of documents within a reasonably small latency window. However, keeping search latencies low is important for user satisfaction and energy usage. In this paper, we show that weaker shallow transformer models (i.e., transformers with a limited number of layers) actually perform better than full-scale models when constrained to these practical low-latency settings since they can estimate the relevance of more documents in the same time budget. We further show that shallow transformers may benefit from the generalized Binary Cross-Entropy (gBCE) training scheme, which has recently demonstrated success for recommendation tasks. Our experiments with TREC Deep Learning passage ranking query sets demonstrate significant improvements in shallow and full-scale models in low-latency scenarios. For example, when the latency limit is 25ms per query, MonoBERT-Large (a cross-encoder based on a full-scale BERT model) is only able to achieve NDCG@10 of 0.431 on TREC DL 2019, while TinyBERT-gBCE (a cross-encoder based on TinyBERT trained with gBCE) reaches NDCG@10 of 0.652, a +51% gain over MonoBERT-Large. We also show that shallow Cross-Encoders are effective even when used without a GPU (e.g., with CPU inference, NDCG@10 decreases only by 3% compared to GPU inference with 50ms latency), which makes Cross-Encoders practical to run even without specialized hardware acceleration.
A Peg-in-hole Task Strategy for Holes in Concrete
Mar 29, 2024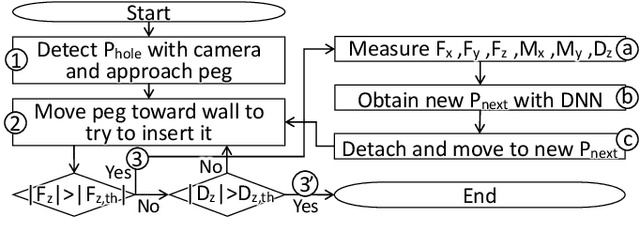
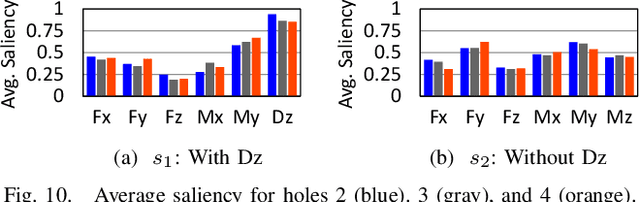
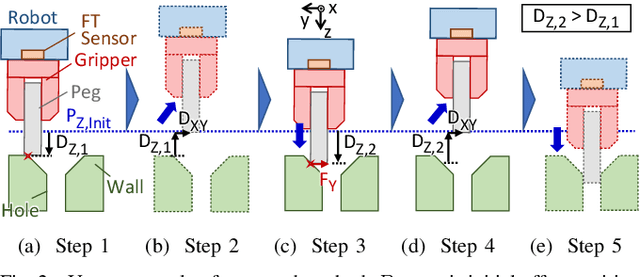
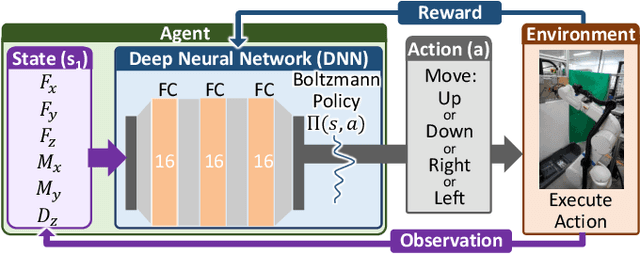
A method that enables an industrial robot to accomplish the peg-in-hole task for holes in concrete is proposed. The proposed method involves slightly detaching the peg from the wall, when moving between search positions, to avoid the negative influence of the concrete's high friction coefficient. It uses a deep neural network (DNN), trained via reinforcement learning, to effectively find holes with variable shape and surface finish (due to the brittle nature of concrete) without analytical modeling or control parameter tuning. The method uses displacement of the peg toward the wall surface, in addition to force and torque, as one of the inputs of the DNN. Since the displacement increases as the peg gets closer to the hole (due to the chamfered shape of holes in concrete), it is a useful parameter for inputting in the DNN. The proposed method was evaluated by training the DNN on a hole 500 times and attempting to find 12 unknown holes. The results of the evaluation show the DNN enabled a robot to find the unknown holes with average success rate of 96.1% and average execution time of 12.5 seconds. Additional evaluations with random initial positions and a different type of peg demonstrate the trained DNN can generalize well to different conditions. Analyses of the influence of the peg displacement input showed the success rate of the DNN is increased by utilizing this parameter. These results validate the proposed method in terms of its effectiveness and applicability to the construction industry.
* Published in 2021 IEEE International Conference on Robotics and Automation (ICRA) on 30 May 2021
T4P: Test-Time Training of Trajectory Prediction via Masked Autoencoder and Actor-specific Token Memory
Mar 15, 2024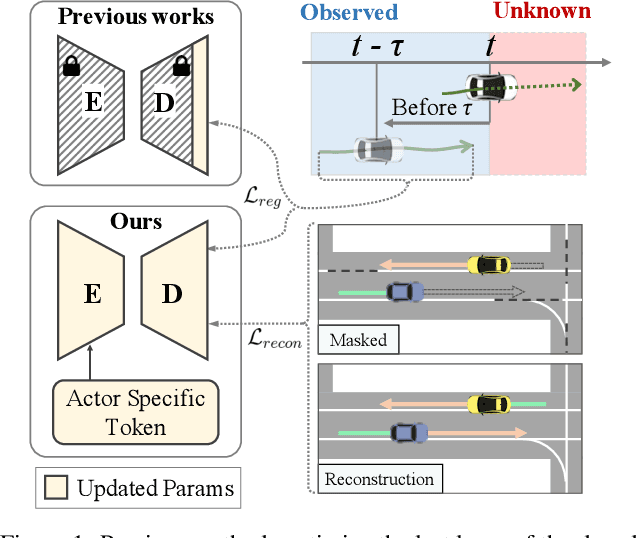
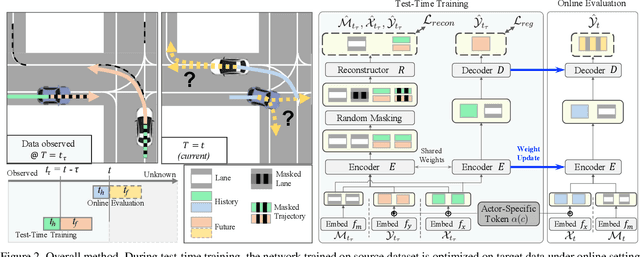
Trajectory prediction is a challenging problem that requires considering interactions among multiple actors and the surrounding environment. While data-driven approaches have been used to address this complex problem, they suffer from unreliable predictions under distribution shifts during test time. Accordingly, several online learning methods have been proposed using regression loss from the ground truth of observed data leveraging the auto-labeling nature of trajectory prediction task. We mainly tackle the following two issues. First, previous works underfit and overfit as they only optimize the last layer of the motion decoder. To this end, we employ the masked autoencoder (MAE) for representation learning to encourage complex interaction modeling in shifted test distribution for updating deeper layers. Second, utilizing the sequential nature of driving data, we propose an actor-specific token memory that enables the test-time learning of actor-wise motion characteristics. Our proposed method has been validated across various challenging cross-dataset distribution shift scenarios including nuScenes, Lyft, Waymo, and Interaction. Our method surpasses the performance of existing state-of-the-art online learning methods in terms of both prediction accuracy and computational efficiency. The code is available at https://github.com/daeheepark/T4P.
Genuine Knowledge from Practice: Diffusion Test-Time Adaptation for Video Adverse Weather Removal
Mar 12, 2024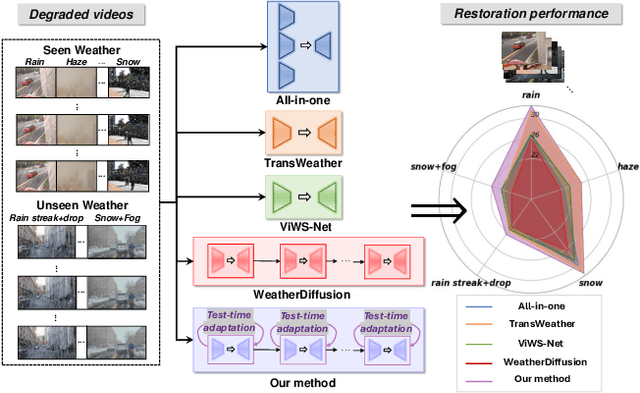
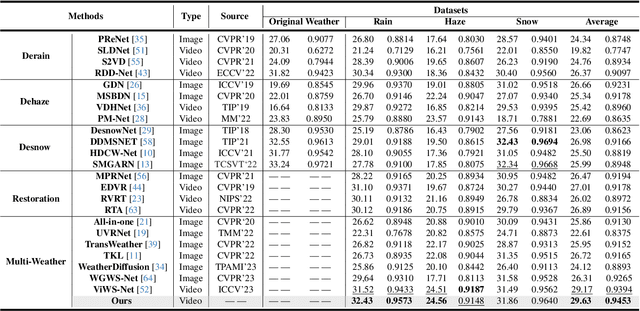
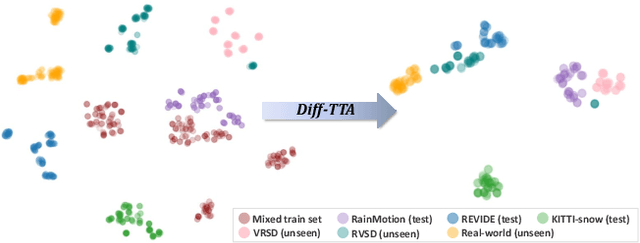
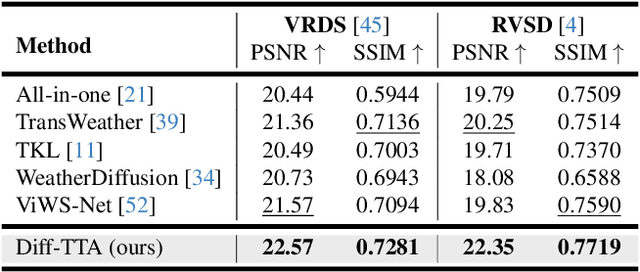
Real-world vision tasks frequently suffer from the appearance of unexpected adverse weather conditions, including rain, haze, snow, and raindrops. In the last decade, convolutional neural networks and vision transformers have yielded outstanding results in single-weather video removal. However, due to the absence of appropriate adaptation, most of them fail to generalize to other weather conditions. Although ViWS-Net is proposed to remove adverse weather conditions in videos with a single set of pre-trained weights, it is seriously blinded by seen weather at train-time and degenerates when coming to unseen weather during test-time. In this work, we introduce test-time adaptation into adverse weather removal in videos, and propose the first framework that integrates test-time adaptation into the iterative diffusion reverse process. Specifically, we devise a diffusion-based network with a novel temporal noise model to efficiently explore frame-correlated information in degraded video clips at training stage. During inference stage, we introduce a proxy task named Diffusion Tubelet Self-Calibration to learn the primer distribution of test video stream and optimize the model by approximating the temporal noise model for online adaptation. Experimental results, on benchmark datasets, demonstrate that our Test-Time Adaptation method with Diffusion-based network(Diff-TTA) outperforms state-of-the-art methods in terms of restoring videos degraded by seen weather conditions. Its generalizable capability is also validated with unseen weather conditions in both synthesized and real-world videos.
Accuracy enhancement method for speech emotion recognition from spectrogram using temporal frequency correlation and positional information learning through knowledge transfer
Mar 26, 2024In this paper, we propose a method to improve the accuracy of speech emotion recognition (SER) by using vision transformer (ViT) to attend to the correlation of frequency (y-axis) with time (x-axis) in spectrogram and transferring positional information between ViT through knowledge transfer. The proposed method has the following originality i) We use vertically segmented patches of log-Mel spectrogram to analyze the correlation of frequencies over time. This type of patch allows us to correlate the most relevant frequencies for a particular emotion with the time they were uttered. ii) We propose the use of image coordinate encoding, an absolute positional encoding suitable for ViT. By normalizing the x, y coordinates of the image to -1 to 1 and concatenating them to the image, we can effectively provide valid absolute positional information for ViT. iii) Through feature map matching, the locality and location information of the teacher network is effectively transmitted to the student network. Teacher network is a ViT that contains locality of convolutional stem and absolute position information through image coordinate encoding, and student network is a structure that lacks positional encoding in the basic ViT structure. In feature map matching stage, we train through the mean absolute error (L1 loss) to minimize the difference between the feature maps of the two networks. To validate the proposed method, three emotion datasets (SAVEE, EmoDB, and CREMA-D) consisting of speech were converted into log-Mel spectrograms for comparison experiments. The experimental results show that the proposed method significantly outperforms the state-of-the-art methods in terms of weighted accuracy while requiring significantly fewer floating point operations (FLOPs). Overall, the proposed method offers an promising solution for SER by providing improved efficiency and performance.
Spatiotemporal Representation Learning for Short and Long Medical Image Time Series
Mar 12, 2024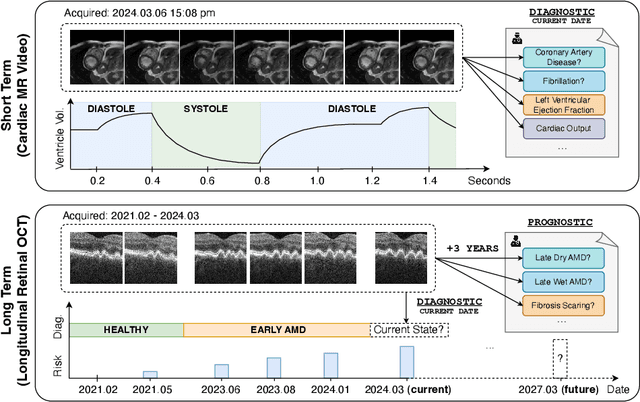
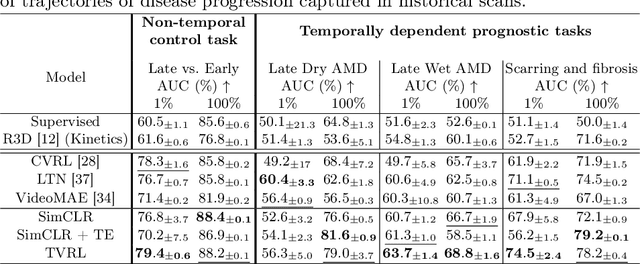
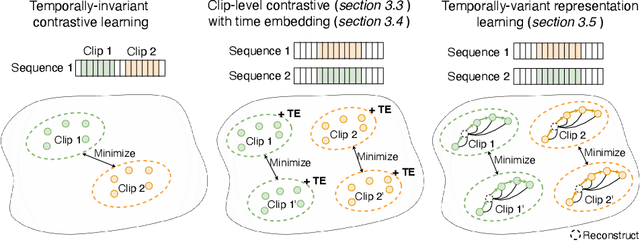
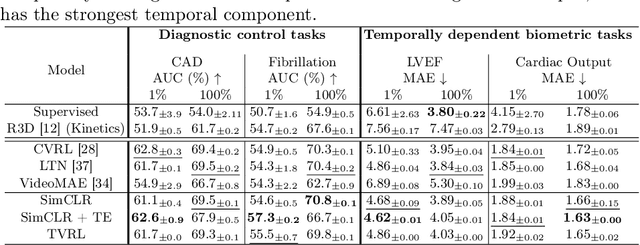
Analyzing temporal developments is crucial for the accurate prognosis of many medical conditions. Temporal changes that occur over short time scales are key to assessing the health of physiological functions, such as the cardiac cycle. Moreover, tracking longer term developments that occur over months or years in evolving processes, such as age-related macular degeneration (AMD), is essential for accurate prognosis. Despite the importance of both short and long term analysis to clinical decision making, they remain understudied in medical deep learning. State of the art methods for spatiotemporal representation learning, developed for short natural videos, prioritize the detection of temporal constants rather than temporal developments. Moreover, they do not account for varying time intervals between acquisitions, which are essential for contextualizing observed changes. To address these issues, we propose two approaches. First, we combine clip-level contrastive learning with a novel temporal embedding to adapt to irregular time series. Second, we propose masking and predicting latent frame representations of the temporal sequence. Our two approaches outperform all prior methods on temporally-dependent tasks including cardiac output estimation and three prognostic AMD tasks. Overall, this enables the automated analysis of temporal patterns which are typically overlooked in applications of deep learning to medicine.
Tracking-Assisted Object Detection with Event Cameras
Mar 27, 2024Event-based object detection has recently garnered attention in the computer vision community due to the exceptional properties of event cameras, such as high dynamic range and no motion blur. However, feature asynchronism and sparsity cause invisible objects due to no relative motion to the camera, posing a significant challenge in the task. Prior works have studied various memory mechanisms to preserve as many features as possible at the current time, guided by temporal clues. While these implicit-learned memories retain some short-term information, they still struggle to preserve long-term features effectively. In this paper, we consider those invisible objects as pseudo-occluded objects and aim to reveal their features. Firstly, we introduce visibility attribute of objects and contribute an auto-labeling algorithm to append additional visibility labels on an existing event camera dataset. Secondly, we exploit tracking strategies for pseudo-occluded objects to maintain their permanence and retain their bounding boxes, even when features have not been available for a very long time. These strategies can be treated as an explicit-learned memory guided by the tracking objective to record the displacements of objects across frames. Lastly, we propose a spatio-temporal feature aggregation module to enrich the latent features and a consistency loss to increase the robustness of the overall pipeline. We conduct comprehensive experiments to verify our method's effectiveness where still objects are retained but real occluded objects are discarded. The results demonstrate that (1) the additional visibility labels can assist in supervised training, and (2) our method outperforms state-of-the-art approaches with a significant improvement of 7.9% absolute mAP.
V2X Enabled Emergency Vehicle Alert System
Mar 28, 2024
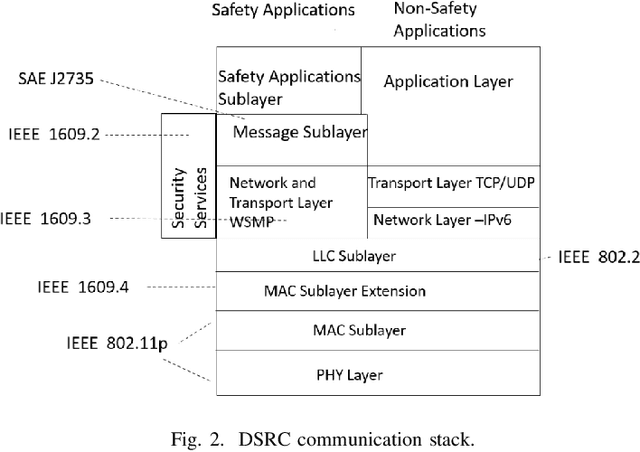


Today's major concern in traffic management systems includes time-efficient emergency transports. The awareness of environment and vehicle information is necessary for the emergency vehicles as well as the surrounding commercial vehicles that might be driven by inexperienced drivers to act accordingly if they both interact. The information exchange should be quick and accurate along with how much interactive the alerting system is with the drivers. Therefore, technologies like V2X-based alert systems can deal with such emergency situations and hence prevent potential health or social hazards. An alerting system as a part of a smart-connected city is proposed in this paper. The Dedicated Short Range Communication (DSRC) based system has tried to cover the major domain of information about misbehaving vehicles, any pedestrians on the road, and information about the emergency vehicle itself. The commercial vehicle also will have a similar alert system as an application of V2V and V2I. Further in this paper, a realtime monitoring system was developed using grafana dashboard which will be installed in the area's base station to monitor the vehicles in that area.
SpikingResformer: Bridging ResNet and Vision Transformer in Spiking Neural Networks
Mar 28, 2024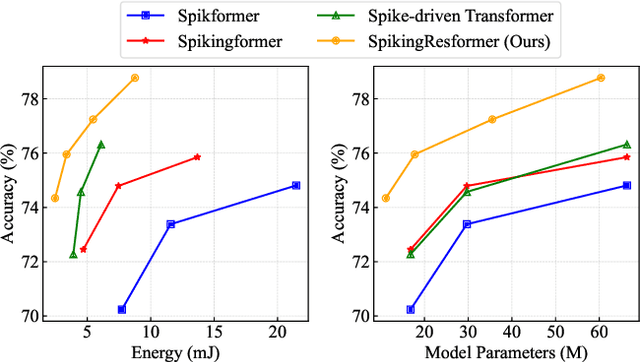

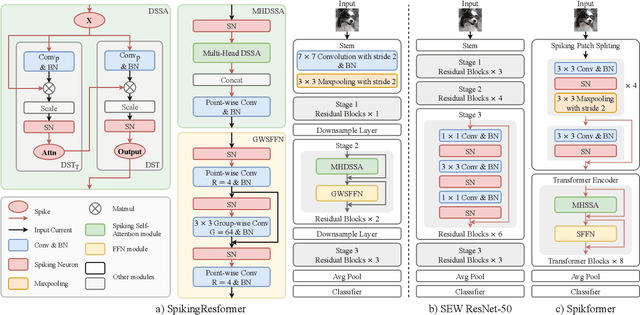
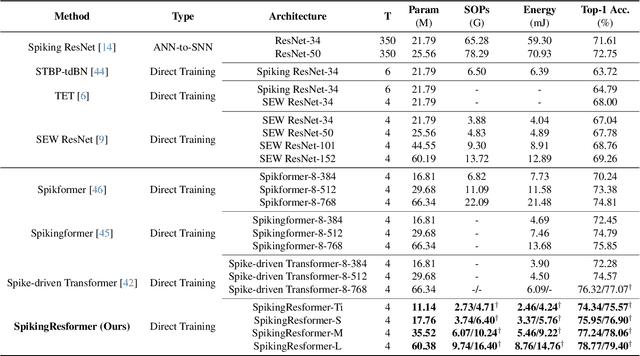
The remarkable success of Vision Transformers in Artificial Neural Networks (ANNs) has led to a growing interest in incorporating the self-attention mechanism and transformer-based architecture into Spiking Neural Networks (SNNs). While existing methods propose spiking self-attention mechanisms that are compatible with SNNs, they lack reasonable scaling methods, and the overall architectures proposed by these methods suffer from a bottleneck in effectively extracting local features. To address these challenges, we propose a novel spiking self-attention mechanism named Dual Spike Self-Attention (DSSA) with a reasonable scaling method. Based on DSSA, we propose a novel spiking Vision Transformer architecture called SpikingResformer, which combines the ResNet-based multi-stage architecture with our proposed DSSA to improve both performance and energy efficiency while reducing parameters. Experimental results show that SpikingResformer achieves higher accuracy with fewer parameters and lower energy consumption than other spiking Vision Transformer counterparts. Notably, our SpikingResformer-L achieves 79.40% top-1 accuracy on ImageNet with 4 time-steps, which is the state-of-the-art result in the SNN field.
Enhancing Research Information Systems with Identification of Domain Experts
Mar 28, 2024Research organisations and their research outputs have been growing considerably in the past decades. This large body of knowledge attracts various stakeholders, e.g., for knowledge sharing, technology transfer, or potential collaborations. However, due to the large amount of complex knowledge created, traditional methods of manually curating catalogues are often out of time, imprecise, and cumbersome. Finding domain experts and knowledge within any larger organisation, scientific and also industrial, has thus become a serious challenge. Hence, exploring an institutions domain knowledge and finding its experts can only be solved by an automated solution. This work presents the scheme of an automated approach for identifying scholarly experts based on their publications and, prospectively, their teaching materials. Based on a search engine, this approach is currently being implemented for two universities, for which some examples are presented. The proposed system will be helpful for finding peer researchers as well as starting points for knowledge exploitation and technology transfer. As the system is designed in a scalable manner, it can easily include additional institutions and hence provide a broader coverage of research facilities in the future.