 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
To grok or not to grok: Disentangling generalization and memorization on corrupted algorithmic datasets
Oct 19, 2023
Robust generalization is a major challenge in deep learning, particularly when the number of trainable parameters is very large. In general, it is very difficult to know if the network has memorized a particular set of examples or understood the underlying rule (or both). Motivated by this challenge, we study an interpretable model where generalizing representations are understood analytically, and are easily distinguishable from the memorizing ones. Namely, we consider two-layer neural networks trained on modular arithmetic tasks where ($\xi \cdot 100\%$) of labels are corrupted (\emph{i.e.} some results of the modular operations in the training set are incorrect). We show that (i) it is possible for the network to memorize the corrupted labels \emph{and} achieve $100\%$ generalization at the same time; (ii) the memorizing neurons can be identified and pruned, lowering the accuracy on corrupted data and improving the accuracy on uncorrupted data; (iii) regularization methods such as weight decay, dropout and BatchNorm force the network to ignore the corrupted data during optimization, and achieve $100\%$ accuracy on the uncorrupted dataset; and (iv) the effect of these regularization methods is (``mechanistically'') interpretable: weight decay and dropout force all the neurons to learn generalizing representations, while BatchNorm de-amplifies the output of memorizing neurons and amplifies the output of the generalizing ones. Finally, we show that in the presence of regularization, the training dynamics involves two consecutive stages: first, the network undergoes the \emph{grokking} dynamics reaching high train \emph{and} test accuracy; second, it unlearns the memorizing representations, where train accuracy suddenly jumps from $100\%$ to $100 (1-\xi)\%$.
Agri-GNN: A Novel Genotypic-Topological Graph Neural Network Framework Built on GraphSAGE for Optimized Yield Prediction
Oct 19, 2023Agriculture, as the cornerstone of human civilization, constantly seeks to integrate technology for enhanced productivity and sustainability. This paper introduces $\textit{Agri-GNN}$, a novel Genotypic-Topological Graph Neural Network Framework tailored to capture the intricate spatial and genotypic interactions of crops, paving the way for optimized predictions of harvest yields. $\textit{Agri-GNN}$ constructs a Graph $\mathcal{G}$ that considers farming plots as nodes, and then methodically constructs edges between nodes based on spatial and genotypic similarity, allowing for the aggregation of node information through a genotypic-topological filter. Graph Neural Networks (GNN), by design, consider the relationships between data points, enabling them to efficiently model the interconnected agricultural ecosystem. By harnessing the power of GNNs, $\textit{Agri-GNN}$ encapsulates both local and global information from plants, considering their inherent connections based on spatial proximity and shared genotypes, allowing stronger predictions to be made than traditional Machine Learning architectures. $\textit{Agri-GNN}$ is built from the GraphSAGE architecture, because of its optimal calibration with large graphs, like those of farming plots and breeding experiments. $\textit{Agri-GNN}$ experiments, conducted on a comprehensive dataset of vegetation indices, time, genotype information, and location data, demonstrate that $\textit{Agri-GNN}$ achieves an $R^2 = .876$ in yield predictions for farming fields in Iowa. The results show significant improvement over the baselines and other work in the field. $\textit{Agri-GNN}$ represents a blueprint for using advanced graph-based neural architectures to predict crop yield, providing significant improvements over baselines in the field.
Live Graph Lab: Towards Open, Dynamic and Real Transaction Graphs with NFT
Oct 19, 2023Numerous studies have been conducted to investigate the properties of large-scale temporal graphs. Despite the ubiquity of these graphs in real-world scenarios, it's usually impractical for us to obtain the whole real-time graphs due to privacy concerns and technical limitations. In this paper, we introduce the concept of {\it Live Graph Lab} for temporal graphs, which enables open, dynamic and real transaction graphs from blockchains. Among them, Non-fungible tokens (NFTs) have become one of the most prominent parts of blockchain over the past several years. With more than \$40 billion market capitalization, this decentralized ecosystem produces massive, anonymous and real transaction activities, which naturally forms a complicated transaction network. However, there is limited understanding about the characteristics of this emerging NFT ecosystem from a temporal graph analysis perspective. To mitigate this gap, we instantiate a live graph with NFT transaction network and investigate its dynamics to provide new observations and insights. Specifically, through downloading and parsing the NFT transaction activities, we obtain a temporal graph with more than 4.5 million nodes and 124 million edges. Then, a series of measurements are presented to understand the properties of the NFT ecosystem. Through comparisons with social, citation, and web networks, our analyses give intriguing findings and point out potential directions for future exploration. Finally, we also study machine learning models in this live graph to enrich the current datasets and provide new opportunities for the graph community. The source codes and dataset are available at https://livegraphlab.github.io.
EMIT-Diff: Enhancing Medical Image Segmentation via Text-Guided Diffusion Model
Oct 19, 2023Large-scale, big-variant, and high-quality data are crucial for developing robust and successful deep-learning models for medical applications since they potentially enable better generalization performance and avoid overfitting. However, the scarcity of high-quality labeled data always presents significant challenges. This paper proposes a novel approach to address this challenge by developing controllable diffusion models for medical image synthesis, called EMIT-Diff. We leverage recent diffusion probabilistic models to generate realistic and diverse synthetic medical image data that preserve the essential characteristics of the original medical images by incorporating edge information of objects to guide the synthesis process. In our approach, we ensure that the synthesized samples adhere to medically relevant constraints and preserve the underlying structure of imaging data. Due to the random sampling process by the diffusion model, we can generate an arbitrary number of synthetic images with diverse appearances. To validate the effectiveness of our proposed method, we conduct an extensive set of medical image segmentation experiments on multiple datasets, including Ultrasound breast (+13.87%), CT spleen (+0.38%), and MRI prostate (+7.78%), achieving significant improvements over the baseline segmentation methods. For the first time, to our best knowledge, the promising results demonstrate the effectiveness of our EMIT-Diff for medical image segmentation tasks and show the feasibility of introducing a first-ever text-guided diffusion model for general medical image segmentation tasks. With carefully designed ablation experiments, we investigate the influence of various data augmentation ratios, hyper-parameter settings, patch size for generating random merging mask settings, and combined influence with different network architectures.
The Foundation Model Transparency Index
Oct 19, 2023Foundation models have rapidly permeated society, catalyzing a wave of generative AI applications spanning enterprise and consumer-facing contexts. While the societal impact of foundation models is growing, transparency is on the decline, mirroring the opacity that has plagued past digital technologies (e.g. social media). Reversing this trend is essential: transparency is a vital precondition for public accountability, scientific innovation, and effective governance. To assess the transparency of the foundation model ecosystem and help improve transparency over time, we introduce the Foundation Model Transparency Index. The Foundation Model Transparency Index specifies 100 fine-grained indicators that comprehensively codify transparency for foundation models, spanning the upstream resources used to build a foundation model (e.g data, labor, compute), details about the model itself (e.g. size, capabilities, risks), and the downstream use (e.g. distribution channels, usage policies, affected geographies). We score 10 major foundation model developers (e.g. OpenAI, Google, Meta) against the 100 indicators to assess their transparency. To facilitate and standardize assessment, we score developers in relation to their practices for their flagship foundation model (e.g. GPT-4 for OpenAI, PaLM 2 for Google, Llama 2 for Meta). We present 10 top-level findings about the foundation model ecosystem: for example, no developer currently discloses significant information about the downstream impact of its flagship model, such as the number of users, affected market sectors, or how users can seek redress for harm. Overall, the Foundation Model Transparency Index establishes the level of transparency today to drive progress on foundation model governance via industry standards and regulatory intervention.
A Fast Optimization View: Reformulating Single Layer Attention in LLM Based on Tensor and SVM Trick, and Solving It in Matrix Multiplication Time
Sep 14, 2023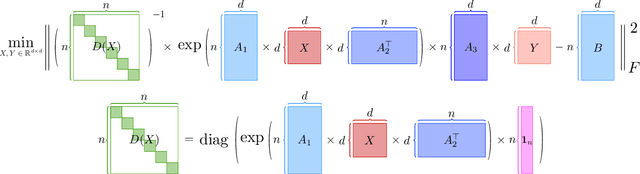

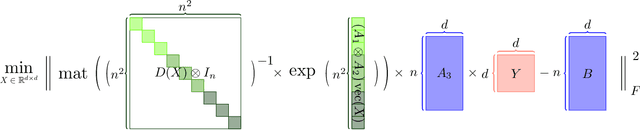
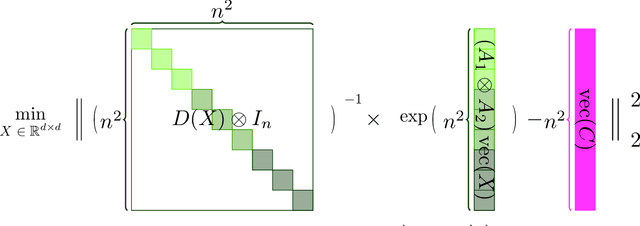
Large language models (LLMs) have played a pivotal role in revolutionizing various facets of our daily existence. Solving attention regression is a fundamental task in optimizing LLMs. In this work, we focus on giving a provable guarantee for the one-layer attention network objective function $L(X,Y) = \sum_{j_0 = 1}^n \sum_{i_0 = 1}^d ( \langle \langle \exp( \mathsf{A}_{j_0} x ) , {\bf 1}_n \rangle^{-1} \exp( \mathsf{A}_{j_0} x ), A_{3} Y_{*,i_0} \rangle - b_{j_0,i_0} )^2$. Here $\mathsf{A} \in \mathbb{R}^{n^2 \times d^2}$ is Kronecker product between $A_1 \in \mathbb{R}^{n \times d}$ and $A_2 \in \mathbb{R}^{n \times d}$. $A_3$ is a matrix in $\mathbb{R}^{n \times d}$, $\mathsf{A}_{j_0} \in \mathbb{R}^{n \times d^2}$ is the $j_0$-th block of $\mathsf{A}$. The $X, Y \in \mathbb{R}^{d \times d}$ are variables we want to learn. $B \in \mathbb{R}^{n \times d}$ and $b_{j_0,i_0} \in \mathbb{R}$ is one entry at $j_0$-th row and $i_0$-th column of $B$, $Y_{*,i_0} \in \mathbb{R}^d$ is the $i_0$-column vector of $Y$, and $x \in \mathbb{R}^{d^2}$ is the vectorization of $X$. In a multi-layer LLM network, the matrix $B \in \mathbb{R}^{n \times d}$ can be viewed as the output of a layer, and $A_1= A_2 = A_3 \in \mathbb{R}^{n \times d}$ can be viewed as the input of a layer. The matrix version of $x$ can be viewed as $QK^\top$ and $Y$ can be viewed as $V$. We provide an iterative greedy algorithm to train loss function $L(X,Y)$ up $\epsilon$ that runs in $\widetilde{O}( ({\cal T}_{\mathrm{mat}}(n,n,d) + {\cal T}_{\mathrm{mat}}(n,d,d) + d^{2\omega}) \log(1/\epsilon) )$ time. Here ${\cal T}_{\mathrm{mat}}(a,b,c)$ denotes the time of multiplying $a \times b$ matrix another $b \times c$ matrix, and $\omega\approx 2.37$ denotes the exponent of matrix multiplication.
Human-in-the-loop: The future of Machine Learning in Automated Electron Microscopy
Oct 08, 2023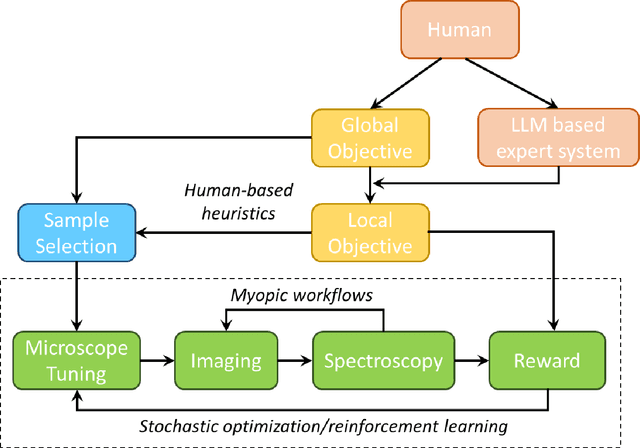
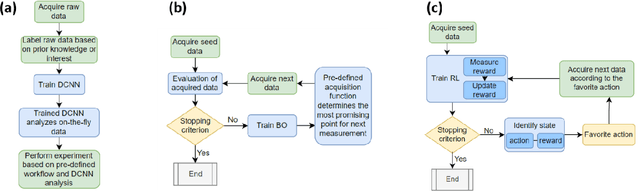

Machine learning methods are progressively gaining acceptance in the electron microscopy community for de-noising, semantic segmentation, and dimensionality reduction of data post-acquisition. The introduction of the APIs by major instrument manufacturers now allows the deployment of ML workflows in microscopes, not only for data analytics but also for real-time decision-making and feedback for microscope operation. However, the number of use cases for real-time ML remains remarkably small. Here, we discuss some considerations in designing ML-based active experiments and pose that the likely strategy for the next several years will be human-in-the-loop automated experiments (hAE). In this paradigm, the ML learning agent directly controls beam position and image and spectroscopy acquisition functions, and human operator monitors experiment progression in real- and feature space of the system and tunes the policies of the ML agent to steer the experiment towards specific objectives.
Deep Reinforcement Learning for Autonomous Vehicle Intersection Navigation
Oct 16, 2023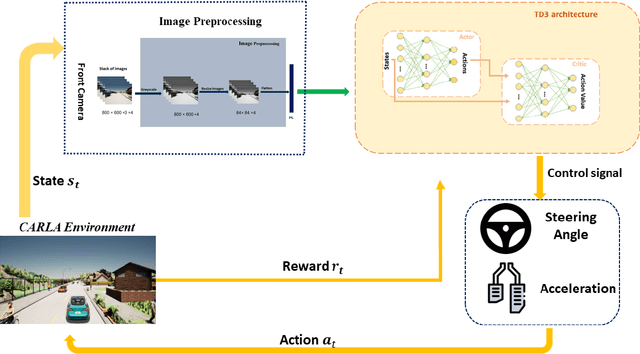
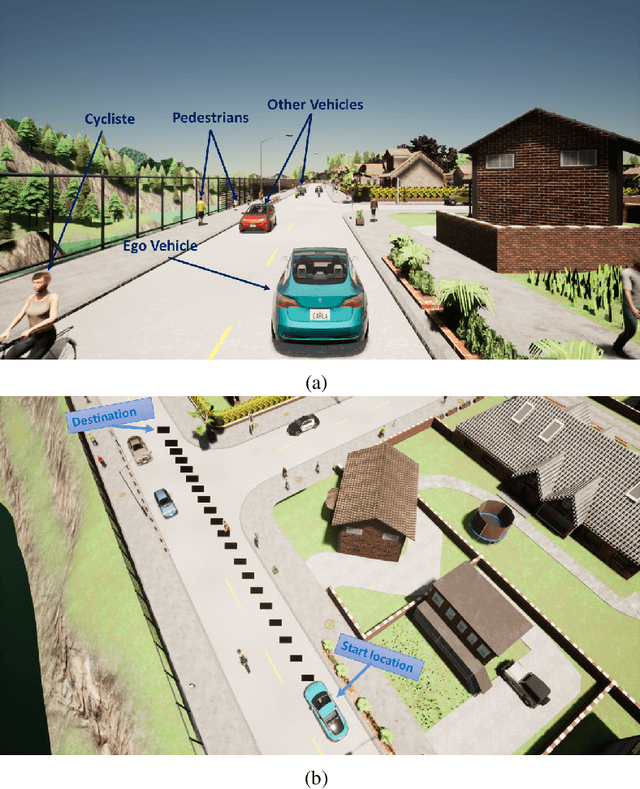
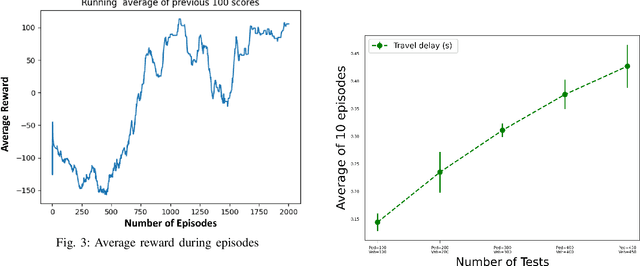
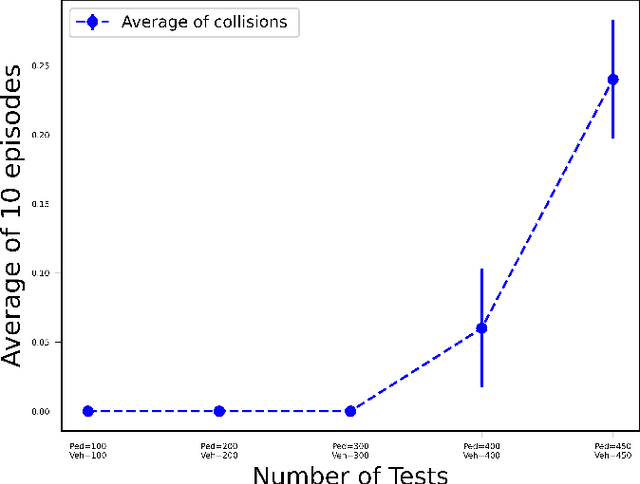
In this paper, we explore the challenges associated with navigating complex T-intersections in dense traffic scenarios for autonomous vehicles (AVs). Reinforcement learning algorithms have emerged as a promising approach to address these challenges by enabling AVs to make safe and efficient decisions in real-time. Here, we address the problem of efficiently and safely navigating T-intersections using a lower-cost, single-agent approach based on the Twin Delayed Deep Deterministic Policy Gradient (TD3) reinforcement learning algorithm. We show that our TD3-based method, when trained and tested in the CARLA simulation platform, demonstrates stable convergence and improved safety performance in various traffic densities. Our results reveal that the proposed approach enables the AV to effectively navigate T-intersections, outperforming previous methods in terms of travel delays, collision minimization, and overall cost. This study contributes to the growing body of knowledge on reinforcement learning applications in autonomous driving and highlights the potential of single-agent, cost-effective methods for addressing more complex driving scenarios and advancing reinforcement learning algorithms in the future.
Evaluation and improvement of Segment Anything Model for interactive histopathology image segmentation
Oct 16, 2023With the emergence of the Segment Anything Model (SAM) as a foundational model for image segmentation, its application has been extensively studied across various domains, including the medical field. However, its potential in the context of histopathology data, specifically in region segmentation, has received relatively limited attention. In this paper, we evaluate SAM's performance in zero-shot and fine-tuned scenarios on histopathology data, with a focus on interactive segmentation. Additionally, we compare SAM with other state-of-the-art interactive models to assess its practical potential and evaluate its generalization capability with domain adaptability. In the experimental results, SAM exhibits a weakness in segmentation performance compared to other models while demonstrating relative strengths in terms of inference time and generalization capability. To improve SAM's limited local refinement ability and to enhance prompt stability while preserving its core strengths, we propose a modification of SAM's decoder. The experimental results suggest that the proposed modification is effective to make SAM useful for interactive histology image segmentation. The code is available at \url{https://github.com/hvcl/SAM_Interactive_Histopathology}
Smart City Transportation: Deep Learning Ensemble Approach for Traffic Accident Detection
Oct 16, 2023The dynamic and unpredictable nature of road traffic necessitates effective accident detection methods for enhancing safety and streamlining traffic management in smart cities. This paper offers a comprehensive exploration study of prevailing accident detection techniques, shedding light on the nuances of other state-of-the-art methodologies while providing a detailed overview of distinct traffic accident types like rear-end collisions, T-bone collisions, and frontal impact accidents. Our novel approach introduces the I3D-CONVLSTM2D model architecture, a lightweight solution tailored explicitly for accident detection in smart city traffic surveillance systems by integrating RGB frames with optical flow information. Our experimental study's empirical analysis underscores our approach's efficacy, with the I3D-CONVLSTM2D RGB + Optical-Flow (Trainable) model outperforming its counterparts, achieving an impressive 87\% Mean Average Precision (MAP). Our findings further elaborate on the challenges posed by data imbalances, particularly when working with a limited number of datasets, road structures, and traffic scenarios. Ultimately, our research illuminates the path towards a sophisticated vision-based accident detection system primed for real-time integration into edge IoT devices within smart urban infrastructures.