 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeltaSpace: A Semantic-aligned Feature Space for Flexible Text-guided Image Editing
Oct 12, 2023
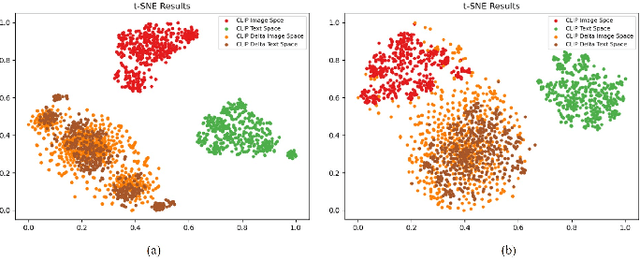
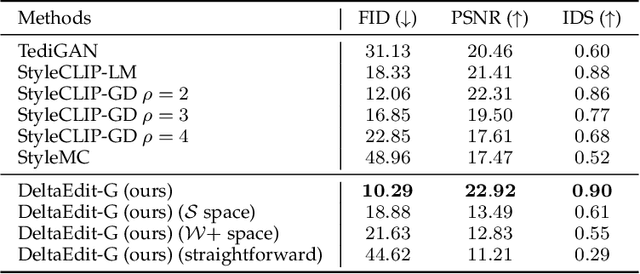


Text-guided image editing faces significant challenges to training and inference flexibility. Much literature collects large amounts of annotated image-text pairs to train text-conditioned generative models from scratch, which is expensive and not efficient. After that, some approaches that leverage pre-trained vision-language models are put forward to avoid data collection, but they are also limited by either per text-prompt optimization or inference-time hyper-parameters tuning. To address these issues, we investigate and identify a specific space, referred to as CLIP DeltaSpace, where the CLIP visual feature difference of two images is semantically aligned with the CLIP textual feature difference of their corresponding text descriptions. Based on DeltaSpace, we propose a novel framework called DeltaEdit, which maps the CLIP visual feature differences to the latent space directions of a generative model during the training phase, and predicts the latent space directions from the CLIP textual feature differences during the inference phase. And this design endows DeltaEdit with two advantages: (1) text-free training; (2) generalization to various text prompts for zero-shot inference. Extensive experiments validate the effectiveness and versatility of DeltaEdit with different generative models, including both the GAN model and the diffusion model, in achieving flexible text-guided image editing. Code is available at https://github.com/Yueming6568/DeltaEdit.
Beyond Sharing Weights in Decoupling Feature Learning Network for UAV RGB-Infrared Vehicle Re-Identification
Oct 12, 2023

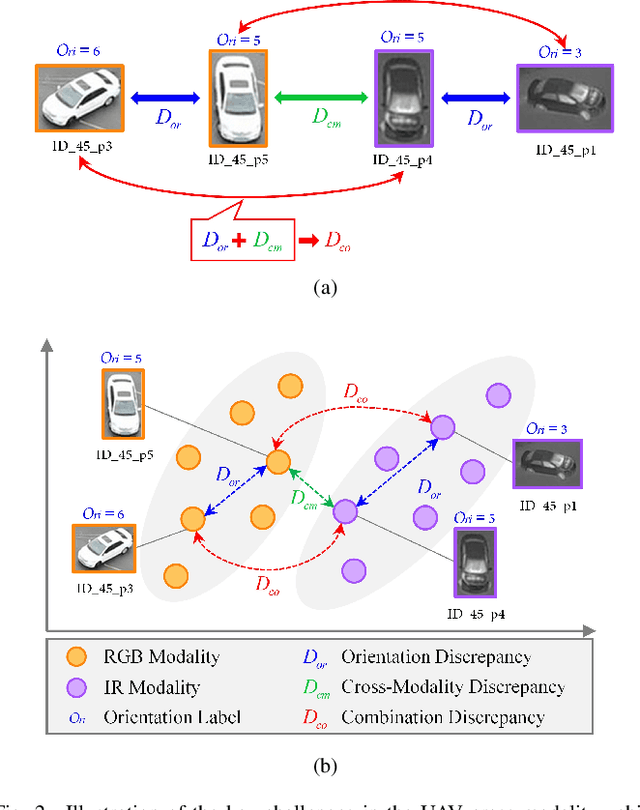

Owing to the capacity of performing full-time target search, cross-modality vehicle re-identification (Re-ID) based on unmanned aerial vehicle (UAV) is gaining more attention in both video surveillance and public security. However, this promising and innovative research has not been studied sufficiently due to the data inadequacy issue. Meanwhile, the cross-modality discrepancy and orientation discrepancy challenges further aggravate the difficulty of this task. To this end, we pioneer a cross-modality vehicle Re-ID benchmark named UAV Cross-Modality Vehicle Re-ID (UCM-VeID), containing 753 identities with 16015 RGB and 13913 infrared images. Moreover, to meet cross-modality discrepancy and orientation discrepancy challenges, we present a hybrid weights decoupling network (HWDNet) to learn the shared discriminative orientation-invariant features. For the first challenge, we proposed a hybrid weights siamese network with a well-designed weight restrainer and its corresponding objective function to learn both modality-specific and modality shared information. In terms of the second challenge, three effective decoupling structures with two pretext tasks are investigated to learn orientation-invariant feature. Comprehensive experiments are carried out to validate the effectiveness of the proposed method. The dataset and codes will be released at https://github.com/moonstarL/UAV-CM-VeID.
MCU: A Task-centric Framework for Open-ended Agent Evaluation in Minecraft
Oct 12, 2023To pursue the goal of creating an open-ended agent in Minecraft, an open-ended game environment with unlimited possibilities, this paper introduces a task-centric framework named MCU for Minecraft agent evaluation. The MCU framework leverages the concept of atom tasks as fundamental building blocks, enabling the generation of diverse or even arbitrary tasks. Within the MCU framework, each task is measured with six distinct difficulty scores (time consumption, operational effort, planning complexity, intricacy, creativity, novelty). These scores offer a multi-dimensional assessment of a task from different angles, and thus can reveal an agent's capability on specific facets. The difficulty scores also serve as the feature of each task, which creates a meaningful task space and unveils the relationship between tasks. For efficient evaluation of Minecraft agents employing the MCU framework, we maintain a unified benchmark, namely SkillForge, which comprises representative tasks with diverse categories and difficulty distribution. We also provide convenient filters for users to select tasks to assess specific capabilities of agents. We show that MCU has the high expressivity to cover all tasks used in recent literature on Minecraft agent, and underscores the need for advancements in areas such as creativity, precise control, and out-of-distribution generalization under the goal of open-ended Minecraft agent development.
MeanAP-Guided Reinforced Active Learning for Object Detection
Oct 12, 2023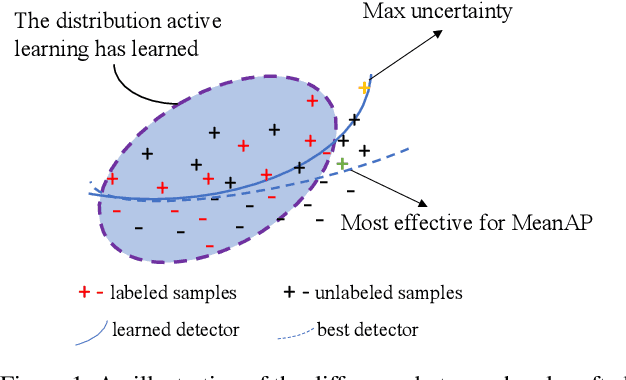
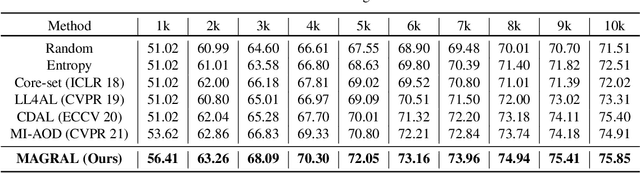
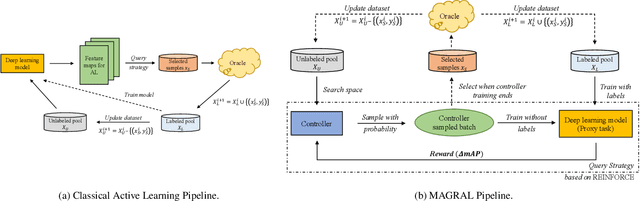
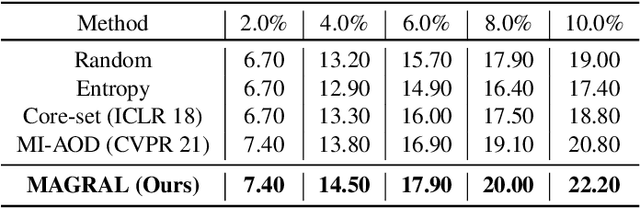
Active learning presents a promising avenue for training high-performance models with minimal labeled data, achieved by judiciously selecting the most informative instances to label and incorporating them into the task learner. Despite notable advancements in active learning for image recognition, metrics devised or learned to gauge the information gain of data, crucial for query strategy design, do not consistently align with task model performance metrics, such as Mean Average Precision (MeanAP) in object detection tasks. This paper introduces MeanAP-Guided Reinforced Active Learning for Object Detection (MAGRAL), a novel approach that directly utilizes the MeanAP metric of the task model to devise a sampling strategy employing a reinforcement learning-based sampling agent. Built upon LSTM architecture, the agent efficiently explores and selects subsequent training instances, and optimizes the process through policy gradient with MeanAP serving as reward. Recognizing the time-intensive nature of MeanAP computation at each step, we propose fast look-up tables to expedite agent training. We assess MAGRAL's efficacy across popular benchmarks, PASCAL VOC and MS COCO, utilizing different backbone architectures. Empirical findings substantiate MAGRAL's superiority over recent state-of-the-art methods, showcasing substantial performance gains. MAGRAL establishes a robust baseline for reinforced active object detection, signifying its potential in advancing the field.
Hedging Properties of Algorithmic Investment Strategies using Long Short-Term Memory and Time Series models for Equity Indices
Sep 27, 2023This paper proposes a novel approach to hedging portfolios of risky assets when financial markets are affected by financial turmoils. We introduce a completely novel approach to diversification activity not on the level of single assets but on the level of ensemble algorithmic investment strategies (AIS) built based on the prices of these assets. We employ four types of diverse theoretical models (LSTM - Long Short-Term Memory, ARIMA-GARCH - Autoregressive Integrated Moving Average - Generalized Autoregressive Conditional Heteroskedasticity, momentum, and contrarian) to generate price forecasts, which are then used to produce investment signals in single and complex AIS. In such a way, we are able to verify the diversification potential of different types of investment strategies consisting of various assets (energy commodities, precious metals, cryptocurrencies, or soft commodities) in hedging ensemble AIS built for equity indices (S&P 500 index). Empirical data used in this study cover the period between 2004 and 2022. Our main conclusion is that LSTM-based strategies outperform the other models and that the best diversifier for the AIS built for the S&P 500 index is the AIS built for Bitcoin. Finally, we test the LSTM model for a higher frequency of data (1 hour). We conclude that it outperforms the results obtained using daily data.
Machine Learning-based Positioning using Multivariate Time Series Classification for Factory Environments
Aug 22, 2023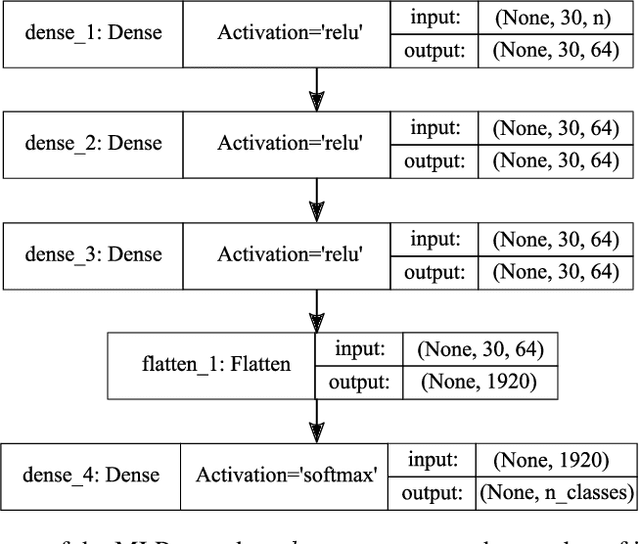

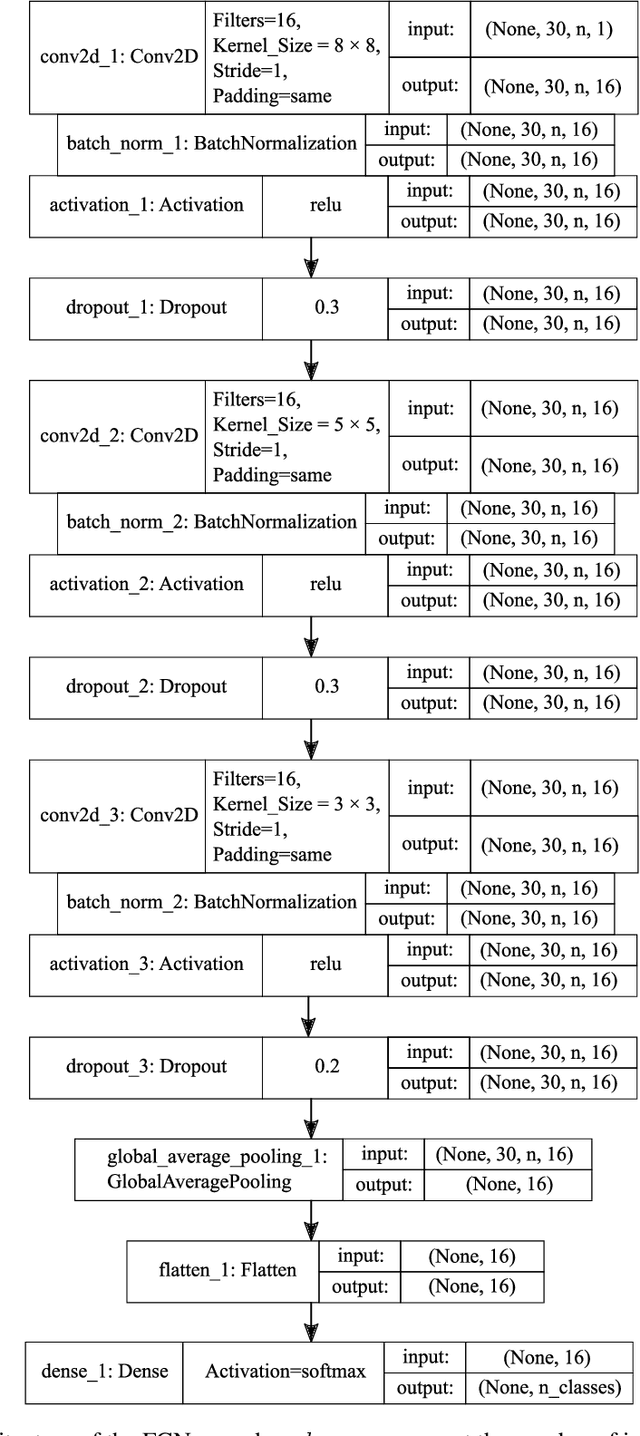

Indoor Positioning Systems (IPS) gained importance in many industrial applications. State-of-the-art solutions heavily rely on external infrastructures and are subject to potential privacy compromises, external information requirements, and assumptions, that make it unfavorable for environments demanding privacy and prolonged functionality. In certain environments deploying supplementary infrastructures for indoor positioning could be infeasible and expensive. Recent developments in machine learning (ML) offer solutions to address these limitations relying only on the data from onboard sensors of IoT devices. However, it is unclear which model fits best considering the resource constraints of IoT devices. This paper presents a machine learning-based indoor positioning system, using motion and ambient sensors, to localize a moving entity in privacy concerned factory environments. The problem is formulated as a multivariate time series classification (MTSC) and a comparative analysis of different machine learning models is conducted in order to address it. We introduce a novel time series dataset emulating the assembly lines of a factory. This dataset is utilized to assess and compare the selected models in terms of accuracy, memory footprint and inference speed. The results illustrate that all evaluated models can achieve accuracies above 80 %. CNN-1D shows the most balanced performance, followed by MLP. DT was found to have the lowest memory footprint and inference latency, indicating its potential for a deployment in real-world scenarios.
Exploring the evolution of research topics during the COVID-19 pandemic
Oct 05, 2023The COVID-19 pandemic has changed the research agendas of most scientific communities, resulting in an overwhelming production of research articles in a variety of domains, including medicine, virology, epidemiology, economy, psychology, and so on. Several open-access corpora and literature hubs were established; among them, the COVID-19 Open Research Dataset (CORD-19) has systematically gathered scientific contributions for 2.5 years, by collecting and indexing over one million articles. Here, we present the CORD-19 Topic Visualizer (CORToViz), a method and associated visualization tool for inspecting the CORD-19 textual corpus of scientific abstracts. Our method is based upon a careful selection of up-to-date technologies (including large language models), resulting in an architecture for clustering articles along orthogonal dimensions and extraction techniques for temporal topic mining. Topic inspection is supported by an interactive dashboard, providing fast, one-click visualization of topic contents as word clouds and topic trends as time series, equipped with easy-to-drive statistical testing for analyzing the significance of topic emergence along arbitrarily selected time windows. The processes of data preparation and results visualization are completely general and virtually applicable to any corpus of textual documents - thus suited for effective adaptation to other contexts.
Enhanced Human-Robot Collaboration using Constrained Probabilistic Human-Motion Prediction
Oct 05, 2023Human motion prediction is an essential step for efficient and safe human-robot collaboration. Current methods either purely rely on representing the human joints in some form of neural network-based architecture or use regression models offline to fit hyper-parameters in the hope of capturing a model encompassing human motion. While these methods provide good initial results, they are missing out on leveraging well-studied human body kinematic models as well as body and scene constraints which can help boost the efficacy of these prediction frameworks while also explicitly avoiding implausible human joint configurations. We propose a novel human motion prediction framework that incorporates human joint constraints and scene constraints in a Gaussian Process Regression (GPR) model to predict human motion over a set time horizon. This formulation is combined with an online context-aware constraints model to leverage task-dependent motions. It is tested on a human arm kinematic model and implemented on a human-robot collaborative setup with a UR5 robot arm to demonstrate the real-time capability of our approach. Simulations were also performed on datasets like HA4M and ANDY. The simulation and experimental results demonstrate considerable improvements in a Gaussian Process framework when these constraints are explicitly considered.
BTDNet: a Multi-Modal Approach for Brain Tumor Radiogenomic Classification
Oct 05, 2023Brain tumors pose significant health challenges worldwide, with glioblastoma being one of the most aggressive forms. Accurate determination of the O6-methylguanine-DNA methyltransferase (MGMT) promoter methylation status is crucial for personalized treatment strategies. However, traditional methods are labor-intensive and time-consuming. This paper proposes a novel multi-modal approach, BTDNet, leveraging multi-parametric MRI scans, including FLAIR, T1w, T1wCE, and T2 3D volumes, to predict MGMT promoter methylation status. BTDNet addresses two main challenges: the variable volume lengths (i.e., each volume consists of a different number of slices) and the volume-level annotations (i.e., the whole 3D volume is annotated and not the independent slices that it consists of). BTDNet consists of four components: i) the data augmentation one (that performs geometric transformations, convex combinations of data pairs and test-time data augmentation); ii) the 3D analysis one (that performs global analysis through a CNN-RNN); iii) the routing one (that contains a mask layer that handles variable input feature lengths), and iv) the modality fusion one (that effectively enhances data representation, reduces ambiguities and mitigates data scarcity). The proposed method outperforms by large margins the state-of-the-art methods in the RSNA-ASNR-MICCAI BraTS 2021 Challenge, offering a promising avenue for enhancing brain tumor diagnosis and treatment.
MFOS: Model-Free & One-Shot Object Pose Estimation
Oct 03, 2023Existing learning-based methods for object pose estimation in RGB images are mostly model-specific or category based. They lack the capability to generalize to new object categories at test time, hence severely hindering their practicability and scalability. Notably, recent attempts have been made to solve this issue, but they still require accurate 3D data of the object surface at both train and test time. In this paper, we introduce a novel approach that can estimate in a single forward pass the pose of objects never seen during training, given minimum input. In contrast to existing state-of-the-art approaches, which rely on task-specific modules, our proposed model is entirely based on a transformer architecture, which can benefit from recently proposed 3D-geometry general pretraining. We conduct extensive experiments and report state-of-the-art one-shot performance on the challenging LINEMOD benchmark. Finally, extensive ablations allow us to determine good practices with this relatively new type of architecture in the field.