 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Comparing the robustness of modern no-reference image- and video-quality metrics to adversarial attacks
Oct 10, 2023
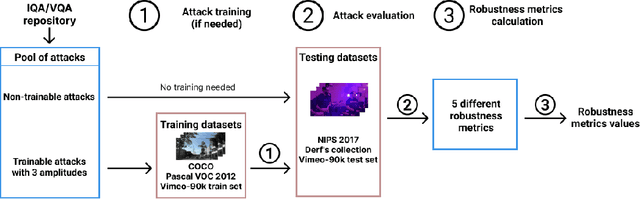
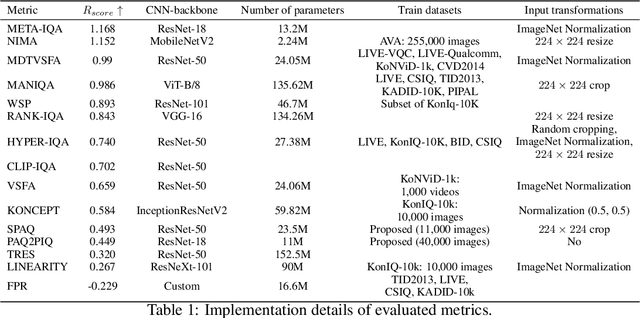
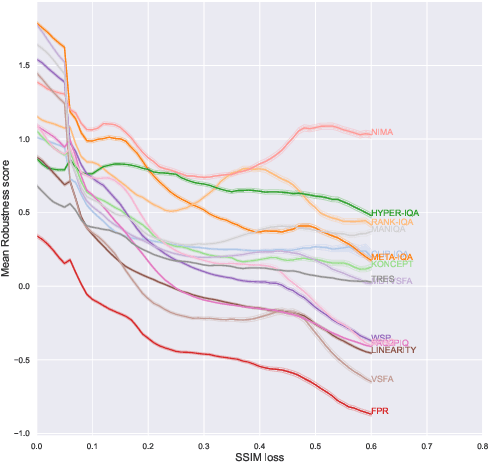
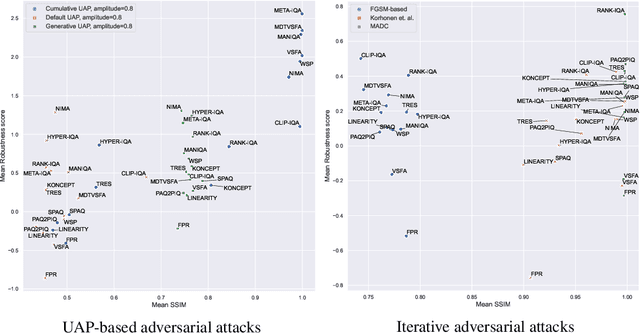
Nowadays neural-network-based image- and video-quality metrics show better performance compared to traditional methods. However, they also became more vulnerable to adversarial attacks that increase metrics' scores without improving visual quality. The existing benchmarks of quality metrics compare their performance in terms of correlation with subjective quality and calculation time. However, the adversarial robustness of image-quality metrics is also an area worth researching. In this paper, we analyse modern metrics' robustness to different adversarial attacks. We adopted adversarial attacks from computer vision tasks and compared attacks' efficiency against 15 no-reference image/video-quality metrics. Some metrics showed high resistance to adversarial attacks which makes their usage in benchmarks safer than vulnerable metrics. The benchmark accepts new metrics submissions for researchers who want to make their metrics more robust to attacks or to find such metrics for their needs. Try our benchmark using pip install robustness-benchmark.
Sparse Fine-tuning for Inference Acceleration of Large Language Models
Oct 13, 2023We consider the problem of accurate sparse fine-tuning of large language models (LLMs), that is, fine-tuning pretrained LLMs on specialized tasks, while inducing sparsity in their weights. On the accuracy side, we observe that standard loss-based fine-tuning may fail to recover accuracy, especially at high sparsities. To address this, we perform a detailed study of distillation-type losses, determining an L2-based distillation approach we term SquareHead which enables accurate recovery even at higher sparsities, across all model types. On the practical efficiency side, we show that sparse LLMs can be executed with speedups by taking advantage of sparsity, for both CPU and GPU runtimes. While the standard approach is to leverage sparsity for computational reduction, we observe that in the case of memory-bound LLMs sparsity can also be leveraged for reducing memory bandwidth. We exhibit end-to-end results showing speedups due to sparsity, while recovering accuracy, on T5 (language translation), Whisper (speech translation), and open GPT-type (MPT for text generation). For MPT text generation, we show for the first time that sparse fine-tuning can reach 75% sparsity without accuracy drops, provide notable end-to-end speedups for both CPU and GPU inference, and highlight that sparsity is also compatible with quantization approaches. Models and software for reproducing our results are provided in Section 6.
A Spatial-Temporal Dual-Mode Mixed Flow Network for Panoramic Video Salient Object Detection
Oct 13, 2023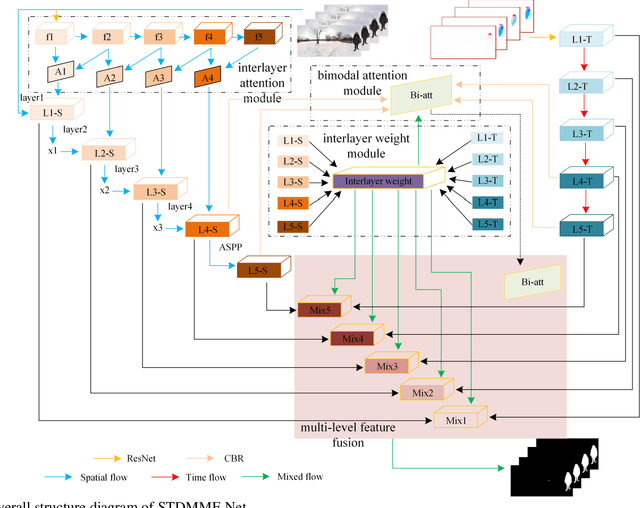
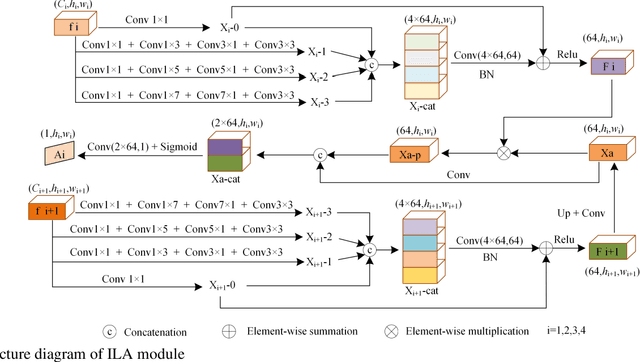
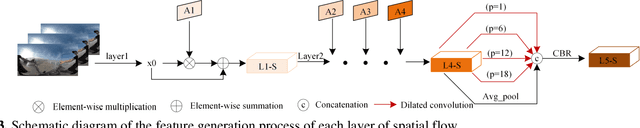
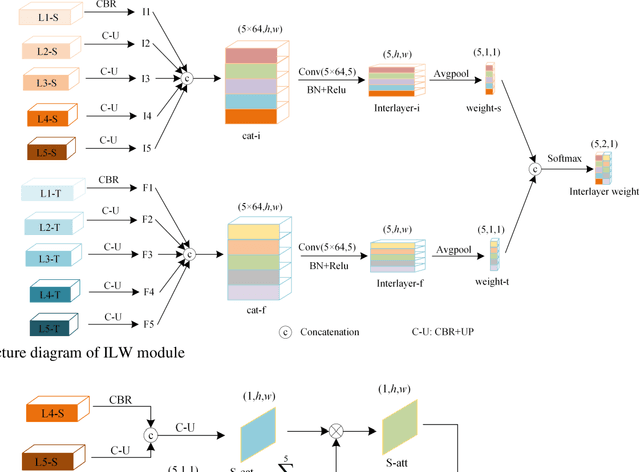
Salient object detection (SOD) in panoramic video is still in the initial exploration stage. The indirect application of 2D video SOD method to the detection of salient objects in panoramic video has many unmet challenges, such as low detection accuracy, high model complexity, and poor generalization performance. To overcome these hurdles, we design an Inter-Layer Attention (ILA) module, an Inter-Layer weight (ILW) module, and a Bi-Modal Attention (BMA) module. Based on these modules, we propose a Spatial-Temporal Dual-Mode Mixed Flow Network (STDMMF-Net) that exploits the spatial flow of panoramic video and the corresponding optical flow for SOD. First, the ILA module calculates the attention between adjacent level features of consecutive frames of panoramic video to improve the accuracy of extracting salient object features from the spatial flow. Then, the ILW module quantifies the salient object information contained in the features of each level to improve the fusion efficiency of the features of each level in the mixed flow. Finally, the BMA module improves the detection accuracy of STDMMF-Net. A large number of subjective and objective experimental results testify that the proposed method demonstrates better detection accuracy than the state-of-the-art (SOTA) methods. Moreover, the comprehensive performance of the proposed method is better in terms of memory required for model inference, testing time, complexity, and generalization performance.
Offline Reinforcement Learning for Optimizing Production Bidding Policies
Oct 13, 2023The online advertising market, with its thousands of auctions run per second, presents a daunting challenge for advertisers who wish to optimize their spend under a budget constraint. Thus, advertising platforms typically provide automated agents to their customers, which act on their behalf to bid for impression opportunities in real time at scale. Because these proxy agents are owned by the platform but use advertiser funds to operate, there is a strong practical need to balance reliability and explainability of the agent with optimizing power. We propose a generalizable approach to optimizing bidding policies in production environments by learning from real data using offline reinforcement learning. This approach can be used to optimize any differentiable base policy (practically, a heuristic policy based on principles which the advertiser can easily understand), and only requires data generated by the base policy itself. We use a hybrid agent architecture that combines arbitrary base policies with deep neural networks, where only the optimized base policy parameters are eventually deployed, and the neural network part is discarded after training. We demonstrate that such an architecture achieves statistically significant performance gains in both simulated and at-scale production bidding environments. Our approach does not incur additional infrastructure, safety, or explainability costs, as it directly optimizes parameters of existing production routines without replacing them with black box-style models like neural networks.
Computing Marginal and Conditional Divergences between Decomposable Models with Applications
Oct 13, 2023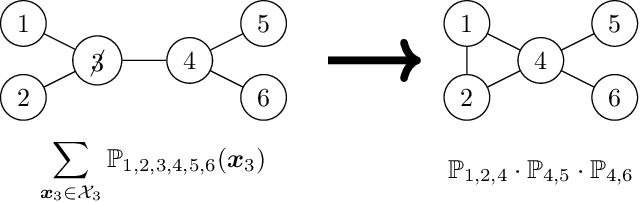
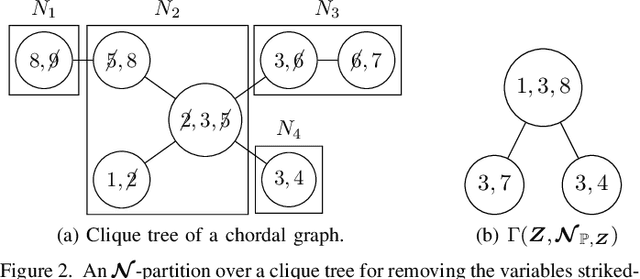


The ability to compute the exact divergence between two high-dimensional distributions is useful in many applications but doing so naively is intractable. Computing the alpha-beta divergence -- a family of divergences that includes the Kullback-Leibler divergence and Hellinger distance -- between the joint distribution of two decomposable models, i.e chordal Markov networks, can be done in time exponential in the treewidth of these models. However, reducing the dissimilarity between two high-dimensional objects to a single scalar value can be uninformative. Furthermore, in applications such as supervised learning, the divergence over a conditional distribution might be of more interest. Therefore, we propose an approach to compute the exact alpha-beta divergence between any marginal or conditional distribution of two decomposable models. Doing so tractably is non-trivial as we need to decompose the divergence between these distributions and therefore, require a decomposition over the marginal and conditional distributions of these models. Consequently, we provide such a decomposition and also extend existing work to compute the marginal and conditional alpha-beta divergence between these decompositions. We then show how our method can be used to analyze distributional changes by first applying it to a benchmark image dataset. Finally, based on our framework, we propose a novel way to quantify the error in contemporary superconducting quantum computers. Code for all experiments is available at: https://lklee.dev/pub/2023-icdm/code
SiamAF: Learning Shared Information from ECG and PPG Signals for Robust Atrial Fibrillation Detection
Oct 13, 2023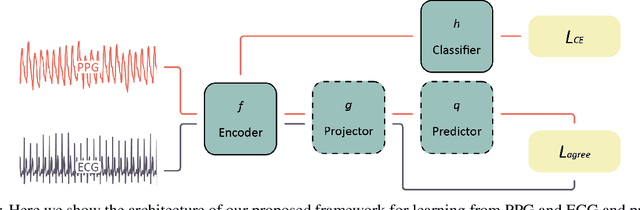

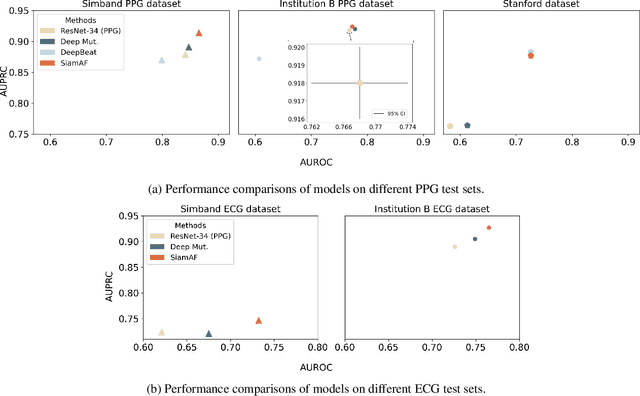
Atrial fibrillation (AF) is the most common type of cardiac arrhythmia. It is associated with an increased risk of stroke, heart failure, and other cardiovascular complications, but can be clinically silent. Passive AF monitoring with wearables may help reduce adverse clinical outcomes related to AF. Detecting AF in noisy wearable data poses a significant challenge, leading to the emergence of various deep learning techniques. Previous deep learning models learn from a single modality, either electrocardiogram (ECG) or photoplethysmography (PPG) signals. However, deep learning models often struggle to learn generalizable features and rely on features that are more susceptible to corruption from noise, leading to sub-optimal performances in certain scenarios, especially with low-quality signals. Given the increasing availability of ECG and PPG signal pairs from wearables and bedside monitors, we propose a new approach, SiamAF, leveraging a novel Siamese network architecture and joint learning loss function to learn shared information from both ECG and PPG signals. At inference time, the proposed model is able to predict AF from either PPG or ECG and outperforms baseline methods on three external test sets. It learns medically relevant features as a result of our novel architecture design. The proposed model also achieves comparable performance to traditional learning regimes while requiring much fewer training labels, providing a potential approach to reduce future reliance on manual labeling.
Efficient Apple Maturity and Damage Assessment: A Lightweight Detection Model with GAN and Attention Mechanism
Oct 13, 2023This study proposes a method based on lightweight convolutional neural networks (CNN) and generative adversarial networks (GAN) for apple ripeness and damage level detection tasks. Initially, a lightweight CNN model is designed by optimizing the model's depth and width, as well as employing advanced model compression techniques, successfully reducing the model's parameter and computational requirements, thus enhancing real-time performance in practical applications. Simultaneously, attention mechanisms are introduced, dynamically adjusting the importance of different feature layers to improve the performance in object detection tasks. To address the issues of sample imbalance and insufficient sample size, GANs are used to generate realistic apple images, expanding the training dataset and enhancing the model's recognition capability when faced with apples of varying ripeness and damage levels. Furthermore, by applying the object detection network for damage location annotation on damaged apples, the accuracy of damage level detection is improved, providing a more precise basis for decision-making. Experimental results show that in apple ripeness grading detection, the proposed model achieves 95.6\%, 93.8\%, 95.0\%, and 56.5 in precision, recall, accuracy, and FPS, respectively. In apple damage level detection, the proposed model reaches 95.3\%, 93.7\%, and 94.5\% in precision, recall, and mAP, respectively. In both tasks, the proposed method outperforms other mainstream models, demonstrating the excellent performance and high practical value of the proposed method in apple ripeness and damage level detection tasks.
Optimal Receive Filter Design for Misaligned Over-the-Air Computation
Sep 27, 2023Over-the-air computation (OAC) is a promising wireless communication method for aggregating data from many devices in dense wireless networks. The fundamental idea of OAC is to exploit signal superposition to compute functions of multiple simultaneously transmitted signals. However, the time- and phase-alignment of these superimposed signals have a significant effect on the quality of function computation. In this study, we analyze the OAC problem for a system with unknown random time delays and phase shifts. We show that the classical matched filter does not produce optimal results, and generates bias in the function estimates. To counteract this, we propose a new filter design and show that, under a bound on the maximum time delay, it is possible to achieve unbiased function computation. Additionally, we propose a Tikhonov regularization problem that produces an optimal filter given a tradeoff between the bias and noise-induced variance of the function estimates. When the time delays are long compared to the length of the transmitted pulses, our filter vastly outperforms the matched filter both in terms of bias and mean-squared error (MSE). For shorter time delays, our proposal yields similar MSE as the matched filter, while reducing the bias.
Exploiting Manifold Structured Data Priors for Improved MR Fingerprinting Reconstruction
Oct 14, 2023Estimating tissue parameter maps with high accuracy and precision from highly undersampled measurements presents one of the major challenges in MR fingerprinting (MRF). Many existing works project the recovered voxel fingerprints onto the Bloch manifold to improve reconstruction performance. However, little research focuses on exploiting the latent manifold structure priors among fingerprints. To fill this gap, we propose a novel MRF reconstruction framework based on manifold structured data priors. Since it is difficult to directly estimate the fingerprint manifold structure, we model the tissue parameters as points on a low-dimensional parameter manifold. We reveal that the fingerprint manifold shares the same intrinsic topology as the parameter manifold, although being embedded in different Euclidean spaces. To exploit the non-linear and non-local redundancies in MRF data, we divide the MRF data into spatial patches, and the similarity measurement among data patches can be accurately obtained using the Euclidean distance between the corresponding patches in the parameter manifold. The measured similarity is then used to construct the graph Laplacian operator, which represents the fingerprint manifold structure. Thus, the fingerprint manifold structure is introduced in the reconstruction framework by using the low-dimensional parameter manifold. Additionally, we incorporate the locally low-rank prior in the reconstruction framework to further utilize the local correlations within each patch for improved reconstruction performance. We also adopt a GPU-accelerated NUFFT library to accelerate reconstruction in non-Cartesian sampling scenarios. Experimental results demonstrate that our method can achieve significantly improved reconstruction performance with reduced computational time over the state-of-the-art methods.
Efficient Integrators for Diffusion Generative Models
Oct 11, 2023
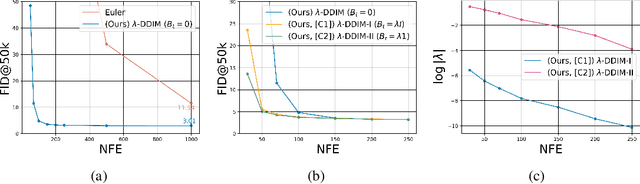

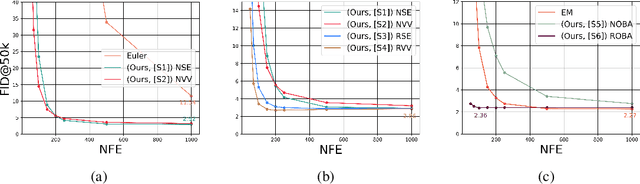
Diffusion models suffer from slow sample generation at inference time. Therefore, developing a principled framework for fast deterministic/stochastic sampling for a broader class of diffusion models is a promising direction. We propose two complementary frameworks for accelerating sample generation in pre-trained models: Conjugate Integrators and Splitting Integrators. Conjugate integrators generalize DDIM, mapping the reverse diffusion dynamics to a more amenable space for sampling. In contrast, splitting-based integrators, commonly used in molecular dynamics, reduce the numerical simulation error by cleverly alternating between numerical updates involving the data and auxiliary variables. After extensively studying these methods empirically and theoretically, we present a hybrid method that leads to the best-reported performance for diffusion models in augmented spaces. Applied to Phase Space Langevin Diffusion [Pandey & Mandt, 2023] on CIFAR-10, our deterministic and stochastic samplers achieve FID scores of 2.11 and 2.36 in only 100 network function evaluations (NFE) as compared to 2.57 and 2.63 for the best-performing baselines, respectively. Our code and model checkpoints will be made publicly available at \url{https://github.com/mandt-lab/PSLD}.