 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TiAVox: Time-aware Attenuation Voxels for Sparse-view 4D DSA Reconstruction
Sep 05, 2023
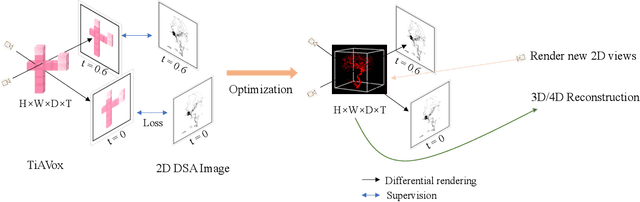
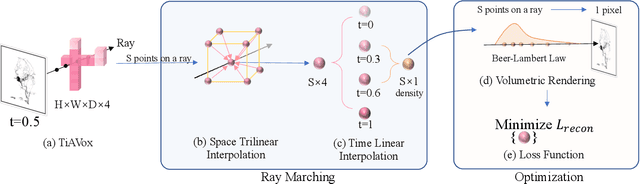
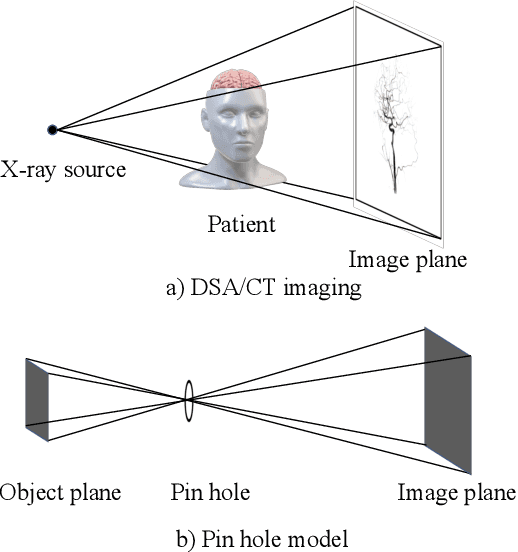
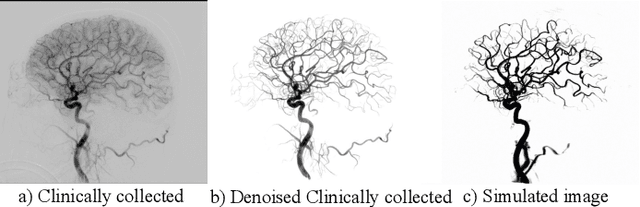
Four-dimensional Digital Subtraction Angiography (4D DSA) plays a critical role in the diagnosis of many medical diseases, such as Arteriovenous Malformations (AVM) and Arteriovenous Fistulas (AVF). Despite its significant application value, the reconstruction of 4D DSA demands numerous views to effectively model the intricate vessels and radiocontrast flow, thereby implying a significant radiation dose. To address this high radiation issue, we propose a Time-aware Attenuation Voxel (TiAVox) approach for sparse-view 4D DSA reconstruction, which paves the way for high-quality 4D imaging. Additionally, 2D and 3D DSA imaging results can be generated from the reconstructed 4D DSA images. TiAVox introduces 4D attenuation voxel grids, which reflect attenuation properties from both spatial and temporal dimensions. It is optimized by minimizing discrepancies between the rendered images and sparse 2D DSA images. Without any neural network involved, TiAVox enjoys specific physical interpretability. The parameters of each learnable voxel represent the attenuation coefficients. We validated the TiAVox approach on both clinical and simulated datasets, achieving a 31.23 Peak Signal-to-Noise Ratio (PSNR) for novel view synthesis using only 30 views on the clinically sourced dataset, whereas traditional Feldkamp-Davis-Kress methods required 133 views. Similarly, with merely 10 views from the synthetic dataset, TiAVox yielded a PSNR of 34.32 for novel view synthesis and 41.40 for 3D reconstruction. We also executed ablation studies to corroborate the essential components of TiAVox. The code will be publically available.
CylinderTag: An Accurate and Flexible Marker for Cylinder-Shape Objects Pose Estimation Based on Projective Invariants
Oct 20, 2023High-precision pose estimation based on visual markers has been a thriving research topic in the field of computer vision. However, the suitability of traditional flat markers on curved objects is limited due to the diverse shapes of curved surfaces, which hinders the development of high-precision pose estimation for curved objects. Therefore, this paper proposes a novel visual marker called CylinderTag, which is designed for developable curved surfaces such as cylindrical surfaces. CylinderTag is a cyclic marker that can be firmly attached to objects with a cylindrical shape. Leveraging the manifold assumption, the cross-ratio in projective invariance is utilized for encoding in the direction of zero curvature on the surface. Additionally, to facilitate the usage of CylinderTag, we propose a heuristic search-based marker generator and a high-performance recognizer as well. Moreover, an all-encompassing evaluation of CylinderTag properties is conducted by means of extensive experimentation, covering detection rate, detection speed, dictionary size, localization jitter, and pose estimation accuracy. CylinderTag showcases superior detection performance from varying view angles in comparison to traditional visual markers, accompanied by higher localization accuracy. Furthermore, CylinderTag boasts real-time detection capability and an extensive marker dictionary, offering enhanced versatility and practicality in a wide range of applications. Experimental results demonstrate that the CylinderTag is a highly promising visual marker for use on cylindrical-like surfaces, thus offering important guidance for future research on high-precision visual localization of cylinder-shaped objects. The code is available at: https://github.com/wsakobe/CylinderTag.
HRTF Interpolation using a Spherical Neural Process Meta-Learner
Oct 20, 2023Several individualization methods have recently been proposed to estimate a subject's Head-Related Transfer Function (HRTF) using convenient input modalities such as anthropometric measurements or pinnae photographs. There exists a need for adaptively correcting the estimation error committed by such methods using a few data point samples from the subject's HRTF, acquired using acoustic measurements or perceptual feedback. To this end, we introduce a Convolutional Conditional Neural Process meta-learner specialized in HRTF error interpolation. In particular, the model includes a Spherical Convolutional Neural Network component to accommodate the spherical geometry of HRTF data. It also exploits potential symmetries between the HRTF's left and right channels about the median axis. In this work, we evaluate the proposed model's performance purely on time-aligned spectrum interpolation grounds under a simplified setup where a generic population-mean HRTF forms the initial estimates prior to corrections instead of individualized ones. The trained model achieves up to 3 dB relative error reduction compared to state-of-the-art interpolation methods despite being trained using only 85 subjects. This improvement translates up to nearly a halving of the data point count required to achieve comparable accuracy, in particular from 50 to 28 points to reach an average of -20 dB relative error per interpolated feature. Moreover, we show that the trained model provides well-calibrated uncertainty estimates. Accordingly, such estimates can inform the sequential decision problem of acquiring as few correcting HRTF data points as needed to meet a desired level of HRTF individualization accuracy.
Eclares: Energy-Aware Clarity-Driven Ergodic Search
Oct 12, 2023

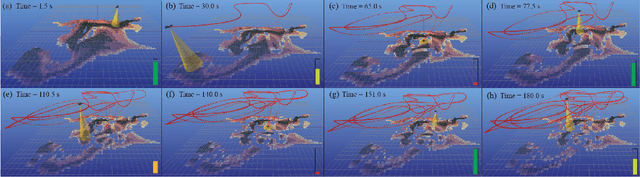
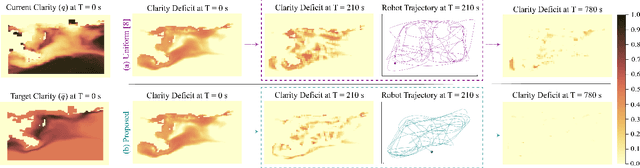
Planning informative trajectories while considering the spatial distribution of the information over the environment, as well as constraints such as the robot's limited battery capacity, makes the long-time horizon persistent coverage problem complex. Ergodic search methods consider the spatial distribution of environmental information while optimizing robot trajectories; however, current methods lack the ability to construct the target information spatial distribution for environments that vary stochastically across space and time. Moreover, current coverage methods dealing with battery capacity constraints either assume simple robot and battery models, or are computationally expensive. To address these problems, we propose a framework called Eclares, in which our contribution is two-fold. 1) First, we propose a method to construct the target information spatial distribution for ergodic trajectory optimization using clarity, an information measure bounded between [0,1]. The clarity dynamics allows us to capture information decay due to lack of measurements and to quantify the maximum attainable information in stochastic spatiotemporal environments. 2) Second, instead of directly tracking the ergodic trajectory, we introduce the energy-aware (eware) filter, which iteratively validates the ergodic trajectory to ensure that the robot has enough energy to return to the charging station when needed. The proposed eware filter is applicable to nonlinear robot models and is computationally lightweight. We demonstrate the working of the framework through a simulation case study.
Fast Ray-Tracing-Based Precise Underwater Acoustic Localization without Prior Acknowledgment of Target Depth
Oct 12, 2023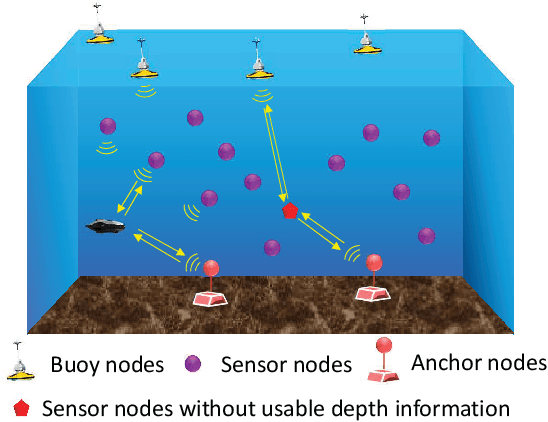
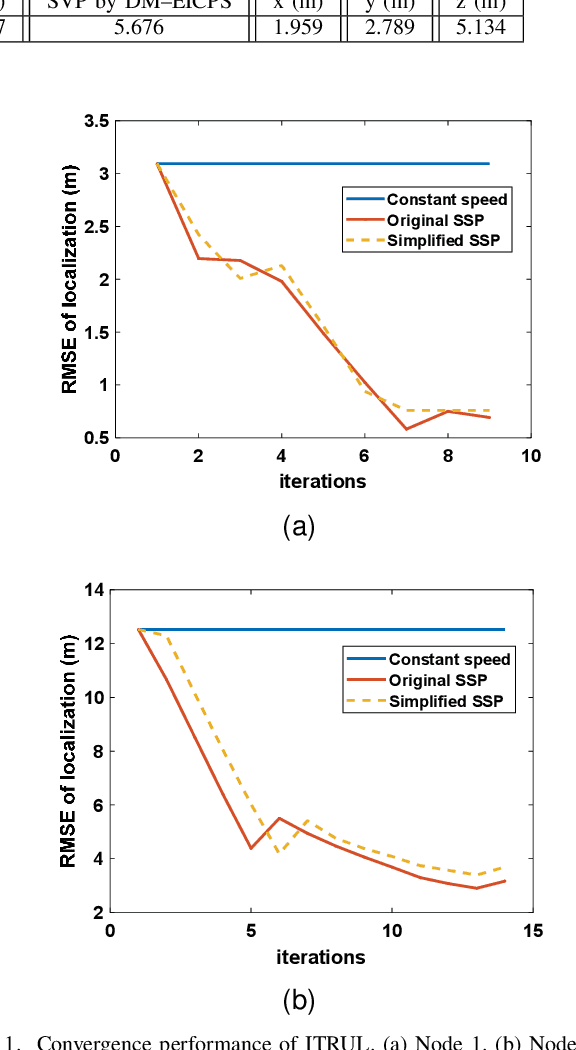
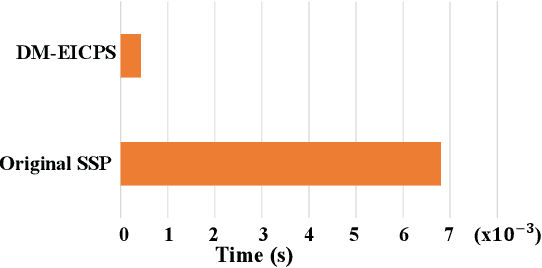
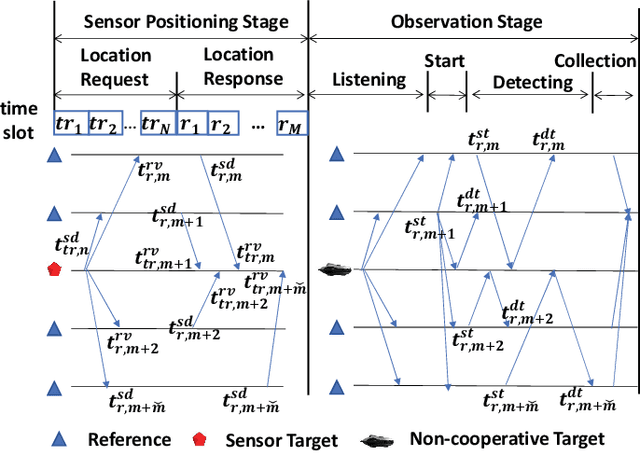
Underwater localization is of great importance for marine observation and building positioning, navigation, timing (PNT) systems that could be widely applied in disaster warning, underwater rescues and resources exploration. The uneven distribution of underwater sound velocity poses great challenge for precise underwater positioning. The current soundline correction positioning method mainly aims at scenarios with known target depth. However, for nodes that are non-cooperative nodes or lack of depth information, soundline tracking strategies cannot work well due to nonunique positional solutions. To tackle this issue, we propose an iterative ray tracing 3D underwater localization (IRTUL) method for stratification compensation. To demonstrate the feasibility of fast stratification compensation, we first derive the signal path as a function of glancing angle, and then prove that the signal propagation time and horizontal propagation distance are monotonic functions of the initial grazing angle, so that fast ray tracing can be achieved. Then, we propose an sound velocity profile (SVP) simplification method, which reduces the computational cost of ray tracing. Experimental results show that the IRTUL has the most significant distance correction in the depth direction, and the average accuracy of IRTUL has been improved by about 3 meters compared to localization model with constant sound velocity. Also, the simplified SVP can significantly improve real-time performance with average accuracy loss less than 0.2 m when used for positioning.
Neural Sampling in Hierarchical Exponential-family Energy-based Models
Oct 12, 2023Bayesian brain theory suggests that the brain employs generative models to understand the external world. The sampling-based perspective posits that the brain infers the posterior distribution through samples of stochastic neuronal responses. Additionally, the brain continually updates its generative model to approach the true distribution of the external world. In this study, we introduce the Hierarchical Exponential-family Energy-based (HEE) model, which captures the dynamics of inference and learning. In the HEE model, we decompose the partition function into individual layers and leverage a group of neurons with shorter time constants to sample the gradient of the decomposed normalization term. This allows our model to estimate the partition function and perform inference simultaneously, circumventing the negative phase encountered in conventional energy-based models (EBMs). As a result, the learning process is localized both in time and space, and the model is easy to converge. To match the brain's rapid computation, we demonstrate that neural adaptation can serve as a momentum term, significantly accelerating the inference process. On natural image datasets, our model exhibits representations akin to those observed in the biological visual system. Furthermore, for the machine learning community, our model can generate observations through joint or marginal generation. We show that marginal generation outperforms joint generation and achieves performance on par with other EBMs.
Introducing a Deep Neural Network-based Model Predictive Control Framework for Rapid Controller Implementation
Oct 12, 2023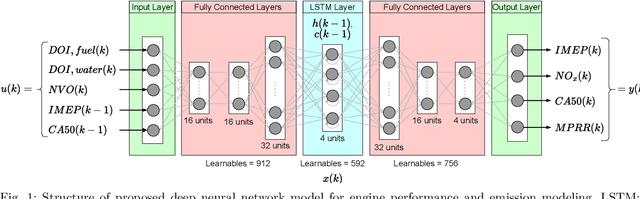
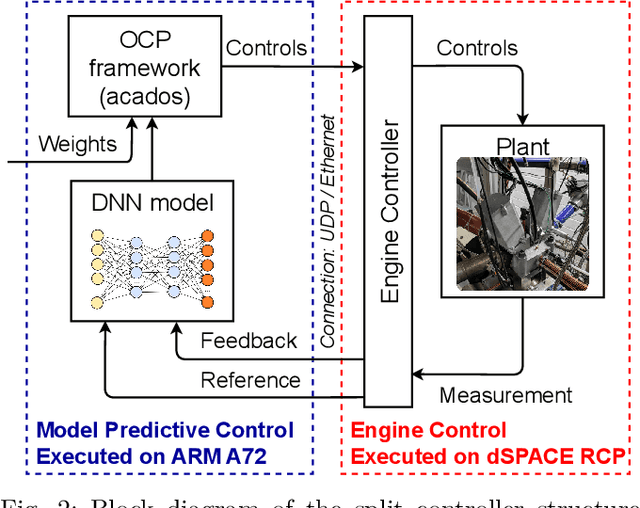
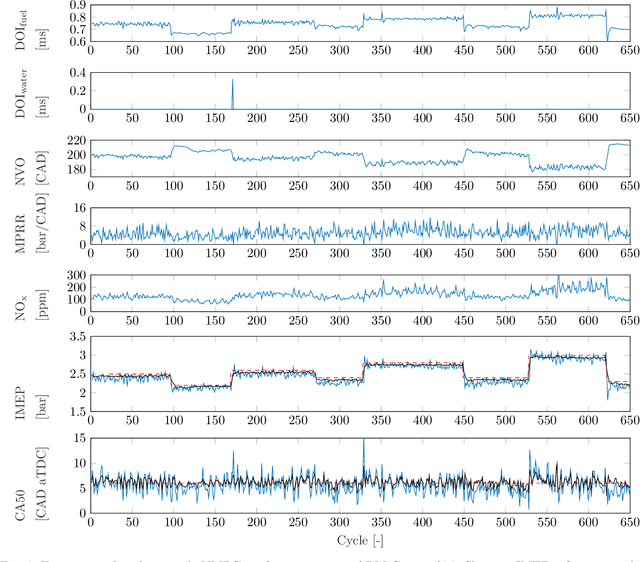
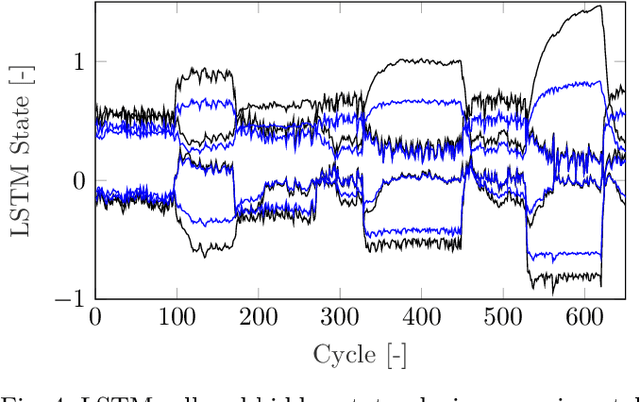
Model Predictive Control (MPC) provides an optimal control solution based on a cost function while allowing for the implementation of process constraints. As a model-based optimal control technique, the performance of MPC strongly depends on the model used where a trade-off between model computation time and prediction performance exists. One solution is the integration of MPC with a machine learning (ML) based process model which are quick to evaluate online. This work presents the experimental implementation of a deep neural network (DNN) based nonlinear MPC for Homogeneous Charge Compression Ignition (HCCI) combustion control. The DNN model consists of a Long Short-Term Memory (LSTM) network surrounded by fully connected layers which was trained using experimental engine data and showed acceptable prediction performance with under 5% error for all outputs. Using this model, the MPC is designed to track the Indicated Mean Effective Pressure (IMEP) and combustion phasing trajectories, while minimizing several parameters. Using the acados software package to enable the real-time implementation of the MPC on an ARM Cortex A72, the optimization calculations are completed within 1.4 ms. The external A72 processor is integrated with the prototyping engine controller using a UDP connection allowing for rapid experimental deployment of the NMPC. The IMEP trajectory following of the developed controller was excellent, with a root-mean-square error of 0.133 bar, in addition to observing process constraints.
Channel Autocorrelation Estimation for IRS-Aided Wireless Communications Based on Power Measurements
Oct 17, 2023Intelligent reflecting surface (IRS) can bring significant performance enhancement for wireless communication systems by reconfiguring wireless channels via passive signal reflection. However, such performance improvement generally relies on the knowledge of channel state information (CSI) for IRS-associated links. Prior IRS channel estimation strategies mainly estimate IRS-cascaded channels based on the excessive pilot signals received at the users/base station (BS) with time-varying IRS reflections, which, however, are not compatible with the existing channel training/estimation protocol for cellular networks. To address this issue, we propose in this paper a new channel estimation scheme for IRS-assisted communication systems based on the received signal power measured at the user, which is practically attainable without the need of changing the current protocol. Specifically, due to the lack of signal phase information in power measurements, the autocorrelation matrix of the BS-IRS-user cascaded channel is estimated by solving equivalent matrix-rank-minimization problems. Simulation results are provided to verify the effectiveness of the proposed channel estimation algorithm as well as the IRS passive reflection design based on the estimated channel autocorrelation matrix.
Semantic-Aware Contrastive Sentence Representation Learning with Large Language Models
Oct 17, 2023Contrastive learning has been proven to be effective in learning better sentence representations. However, to train a contrastive learning model, large numbers of labeled sentences are required to construct positive and negative pairs explicitly, such as those in natural language inference (NLI) datasets. Unfortunately, acquiring sufficient high-quality labeled data can be both time-consuming and resource-intensive, leading researchers to focus on developing methods for learning unsupervised sentence representations. As there is no clear relationship between these unstructured randomly-sampled sentences, building positive and negative pairs over them is tricky and problematic. To tackle these challenges, in this paper, we propose SemCSR, a semantic-aware contrastive sentence representation framework. By leveraging the generation and evaluation capabilities of large language models (LLMs), we can automatically construct a high-quality NLI-style corpus without any human annotation, and further incorporate the generated sentence pairs into learning a contrastive sentence representation model. Extensive experiments and comprehensive analyses demonstrate the effectiveness of our proposed framework for learning a better sentence representation with LLMs.
On Statistical Learning of Branch and Bound for Vehicle Routing Optimization
Oct 17, 2023Recently, machine learning of the branch and bound algorithm has shown promise in approximating competent solutions to NP-hard problems. In this paper, we utilize and comprehensively compare the outcomes of three neural networks--graph convolutional neural network (GCNN), GraphSAGE, and graph attention network (GAT)--to solve the capacitated vehicle routing problem. We train these neural networks to emulate the decision-making process of the computationally expensive Strong Branching strategy. The neural networks are trained on six instances with distinct topologies from the CVRPLIB and evaluated on eight additional instances. Moreover, we reduced the minimum number of vehicles required to solve a CVRP instance to a bin-packing problem, which was addressed in a similar manner. Through rigorous experimentation, we found that this approach can match or improve upon the performance of the branch and bound algorithm with the Strong Branching strategy while requiring significantly less computational time. The source code that corresponds to our research findings and methodology is readily accessible and available for reference at the following web address: https://isotlaboratory.github.io/ml4vrp