 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Will the Prince Get True Love's Kiss? On the Model Sensitivity to Gender Perturbation over Fairytale Texts
Oct 16, 2023
Recent studies show that traditional fairytales are rife with harmful gender biases. To help mitigate these gender biases in fairytales, this work aims to assess learned biases of language models by evaluating their robustness against gender perturbations. Specifically, we focus on Question Answering (QA) tasks in fairytales. Using counterfactual data augmentation to the FairytaleQA dataset, we evaluate model robustness against swapped gender character information, and then mitigate learned biases by introducing counterfactual gender stereotypes during training time. We additionally introduce a novel approach that utilizes the massive vocabulary of language models to support text genres beyond fairytales. Our experimental results suggest that models are sensitive to gender perturbations, with significant performance drops compared to the original testing set. However, when first fine-tuned on a counterfactual training dataset, models are less sensitive to the later introduced anti-gender stereotyped text.
Efficient Sim-to-real Transfer of Contact-Rich Manipulation Skills with Online Admittance Residual Learning
Oct 16, 2023
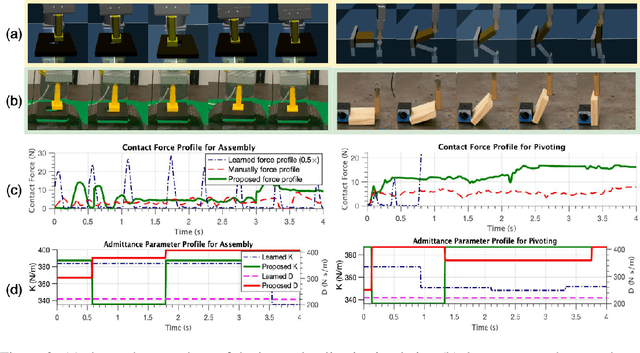
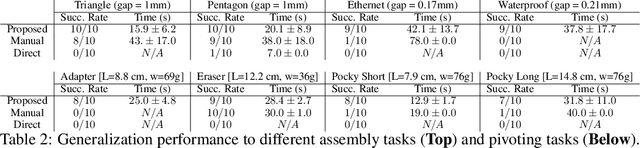

Learning contact-rich manipulation skills is essential. Such skills require the robots to interact with the environment with feasible manipulation trajectories and suitable compliance control parameters to enable safe and stable contact. However, learning these skills is challenging due to data inefficiency in the real world and the sim-to-real gap in simulation. In this paper, we introduce a hybrid offline-online framework to learn robust manipulation skills. We employ model-free reinforcement learning for the offline phase to obtain the robot motion and compliance control parameters in simulation \RV{with domain randomization}. Subsequently, in the online phase, we learn the residual of the compliance control parameters to maximize robot performance-related criteria with force sensor measurements in real time. To demonstrate the effectiveness and robustness of our approach, we provide comparative results against existing methods for assembly, pivoting, and screwing tasks.
Performance Analysis of a Low-Complexity OTFS Integrated Sensing and Communication System
Oct 16, 2023This work proposes a low-complexity estimation approach for an orthogonal time frequency space (OTFS)-based integrated sensing and communication (ISAC) system. In particular, we first define four low-dimensional matrices used to compute the channel matrix through simple algebraic manipulations. Secondly, we establish an analytical criterion, independent of system parameters, to identify the most informative elements within these derived matrices, leveraging the properties of the Dirichlet kernel. This allows the distilling of such matrices, keeping only those entries that are essential for detection, resulting in an efficient, low-complexity implementation of the sensing receiver. Numerical results, which refer to a vehicular scenario, demonstrate that the proposed approximation technique effectively preserves the sensing performance, evaluated in terms of root mean square error (RMSE) of the range and velocity estimation, while concurrently reducing the computational effort enormously.
StofNet: Super-resolution Time of Flight Network
Aug 23, 2023
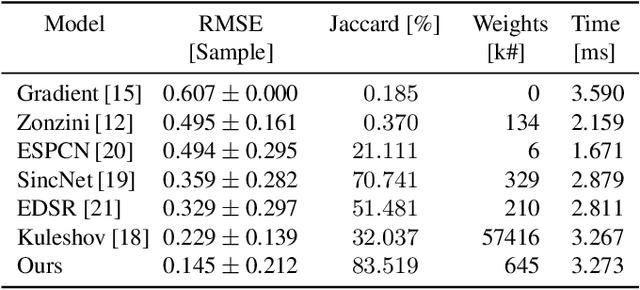
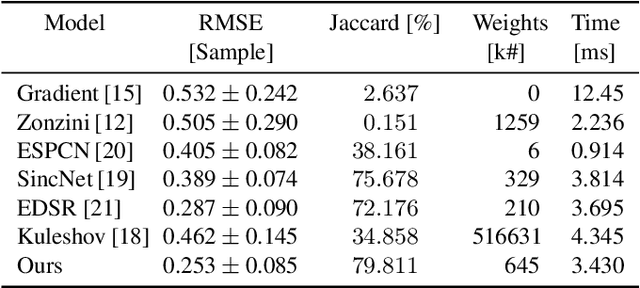
Time of Flight (ToF) is a prevalent depth sensing technology in the fields of robotics, medical imaging, and non-destructive testing. Yet, ToF sensing faces challenges from complex ambient conditions making an inverse modelling from the sparse temporal information intractable. This paper highlights the potential of modern super-resolution techniques to learn varying surroundings for a reliable and accurate ToF detection. Unlike existing models, we tailor an architecture for sub-sample precise semi-global signal localization by combining super-resolution with an efficient residual contraction block to balance between fine signal details and large scale contextual information. We consolidate research on ToF by conducting a benchmark comparison against six state-of-the-art methods for which we employ two publicly available datasets. This includes the release of our SToF-Chirp dataset captured by an airborne ultrasound transducer. Results showcase the superior performance of our proposed StofNet in terms of precision, reliability and model complexity. Our code is available at https://github.com/hahnec/stofnet.
Enhanced Backpressure Routing with Wireless Link Features
Oct 06, 2023Backpressure (BP) routing is a well-established framework for distributed routing and scheduling in wireless multi-hop networks. However, the basic BP scheme suffers from poor end-to-end delay due to the drawbacks of slow startup, random walk, and the last packet problem. Biased BP with shortest path awareness can address the first two drawbacks, and sojourn time-based backlog metrics have been proposed for the last packet problem. Furthermore, these BP variations require no additional signaling overhead in each time step compared to the basic BP. In this work, we further address three long-standing challenges associated with the aforementioned low-cost BP variations, including optimal scaling of the biases, bias maintenance under mobility, and incorporating sojourn time awareness into biased BP. Our analysis and experimental results show that proper scaling of biases can be achieved with the help of common link features, which can effectively reduce end-to-end delay of BP by mitigating the random walk of packets under low-to-medium traffic, including the last packet scenario. In addition, our low-overhead bias maintenance scheme is shown to be effective under mobility, and our bio-inspired sojourn time-aware backlog metric is demonstrated to be more efficient and effective for the last packet problem than existing approaches when incorporated into biased BP.
Near-optimal Differentially Private Client Selection in Federated Settings
Oct 13, 2023We develop an iterative differentially private algorithm for client selection in federated settings. We consider a federated network wherein clients coordinate with a central server to complete a task; however, the clients decide whether to participate or not at a time step based on their preferences -- local computation and probabilistic intent. The algorithm does not require client-to-client information exchange. The developed algorithm provides near-optimal values to the clients over long-term average participation with a certain differential privacy guarantee. Finally, we present the experimental results to check the algorithm's efficacy.
Robust Quickest Change Detection in Non-Stationary Processes
Oct 14, 2023Optimal algorithms are developed for robust detection of changes in non-stationary processes. These are processes in which the distribution of the data after change varies with time. The decision-maker does not have access to precise information on the post-change distribution. It is shown that if the post-change non-stationary family has a distribution that is least favorable in a well-defined sense, then the algorithms designed using the least favorable distributions are robust and optimal. Non-stationary processes are encountered in public health monitoring and space and military applications. The robust algorithms are applied to real and simulated data to show their effectiveness.
Predicting Financial Market Trends using Time Series Analysis and Natural Language Processing
Aug 31, 2023
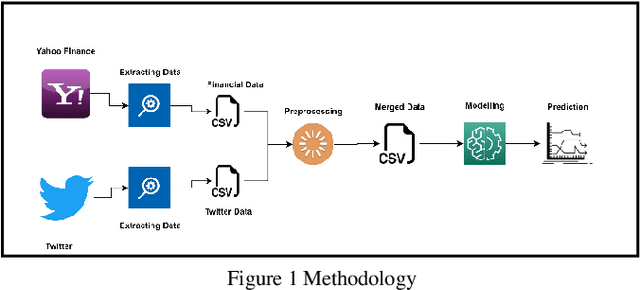
Forecasting financial market trends through time series analysis and natural language processing poses a complex and demanding undertaking, owing to the numerous variables that can influence stock prices. These variables encompass a spectrum of economic and political occurrences, as well as prevailing public attitudes. Recent research has indicated that the expression of public sentiments on social media platforms such as Twitter may have a noteworthy impact on the determination of stock prices. The objective of this study was to assess the viability of Twitter sentiments as a tool for predicting stock prices of major corporations such as Tesla, Apple. Our study has revealed a robust association between the emotions conveyed in tweets and fluctuations in stock prices. Our findings indicate that positivity, negativity, and subjectivity are the primary determinants of fluctuations in stock prices. The data was analyzed utilizing the Long-Short Term Memory neural network (LSTM) model, which is currently recognized as the leading methodology for predicting stock prices by incorporating Twitter sentiments and historical stock prices data. The models utilized in our study demonstrated a high degree of reliability and yielded precise outcomes for the designated corporations. In summary, this research emphasizes the significance of incorporating public opinions into the prediction of stock prices. The application of Time Series Analysis and Natural Language Processing methodologies can yield significant scientific findings regarding financial market patterns, thereby facilitating informed decision-making among investors. The results of our study indicate that the utilization of Twitter sentiments can serve as a potent instrument for forecasting stock prices, and ought to be factored in when formulating investment strategies.
NeuroCUT: A Neural Approach for Robust Graph Partitioning
Oct 18, 2023Graph partitioning aims to divide a graph into $k$ disjoint subsets while optimizing a specific partitioning objective. The majority of formulations related to graph partitioning exhibit NP-hardness due to their combinatorial nature. As a result, conventional approximation algorithms rely on heuristic methods, sometimes with approximation guarantees and sometimes without. Unfortunately, traditional approaches are tailored for specific partitioning objectives and do not generalize well across other known partitioning objectives from the literature. To overcome this limitation, and learn heuristics from the data directly, neural approaches have emerged, demonstrating promising outcomes. In this study, we extend this line of work through a novel framework, NeuroCut. NeuroCut introduces two key innovations over prevailing methodologies. First, it is inductive to both graph topology and the partition count, which is provided at query time. Second, by leveraging a reinforcement learning based framework over node representations derived from a graph neural network, NeuroCut can accommodate any optimization objective, even those encompassing non-differentiable functions. Through empirical evaluation, we demonstrate that NeuroCut excels in identifying high-quality partitions, showcases strong generalization across a wide spectrum of partitioning objectives, and exhibits resilience to topological modifications.
Applications of ML-Based Surrogates in Bayesian Approaches to Inverse Problems
Oct 18, 2023Neural networks have become a powerful tool as surrogate models to provide numerical solutions for scientific problems with increased computational efficiency. This efficiency can be advantageous for numerically challenging problems where time to solution is important or when evaluation of many similar analysis scenarios is required. One particular area of scientific interest is the setting of inverse problems, where one knows the forward dynamics of a system are described by a partial differential equation and the task is to infer properties of the system given (potentially noisy) observations of these dynamics. We consider the inverse problem of inferring the location of a wave source on a square domain, given a noisy solution to the 2-D acoustic wave equation. Under the assumption of Gaussian noise, a likelihood function for source location can be formulated, which requires one forward simulation of the system per evaluation. Using a standard neural network as a surrogate model makes it computationally feasible to evaluate this likelihood several times, and so Markov Chain Monte Carlo methods can be used to evaluate the posterior distribution of the source location. We demonstrate that this method can accurately infer source-locations from noisy data.