 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automated Gait Generation For Walking, Soft Robotic Quadrupeds
Oct 07, 2023


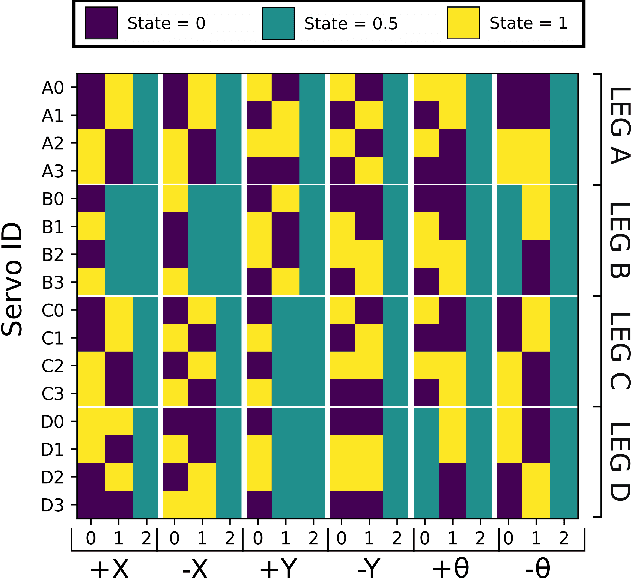
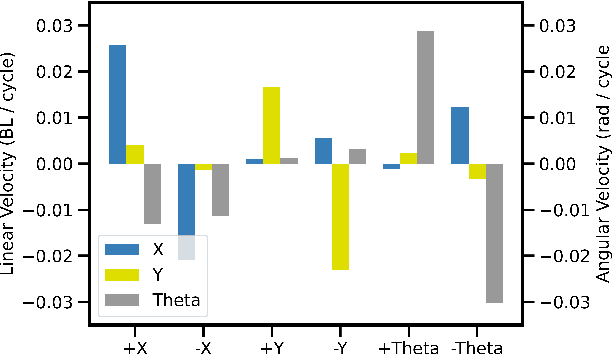
Gait generation for soft robots is challenging due to the nonlinear dynamics and high dimensional input spaces of soft actuators. Limitations in soft robotic control and perception force researchers to hand-craft open loop controllers for gait sequences, which is a non-trivial process. Moreover, short soft actuator lifespans and natural variations in actuator behavior limit machine learning techniques to settings that can be learned on the same time scales as robot deployment. Lastly, simulation is not always possible, due to heterogeneity and nonlinearity in soft robotic materials and their dynamics change due to wear. We present a sample-efficient, simulation free, method for self-generating soft robot gaits, using very minimal computation. This technique is demonstrated on a motorized soft robotic quadruped that walks using four legs constructed from 16 "handed shearing auxetic" (HSA) actuators. To manage the dimension of the search space, gaits are composed of two sequential sets of leg motions selected from 7 possible primitives. Pairs of primitives are executed on one leg at a time; we then select the best-performing pair to execute while moving on to subsequent legs. This method -- which uses no simulation, sophisticated computation, or user input -- consistently generates good translation and rotation gaits in as low as 4 minutes of hardware experimentation, outperforming hand-crafted gaits. This is the first demonstration of completely autonomous gait generation in a soft robot.
Advanced Deep Regression Models for Forecasting Time Series Oil Production
Aug 30, 2023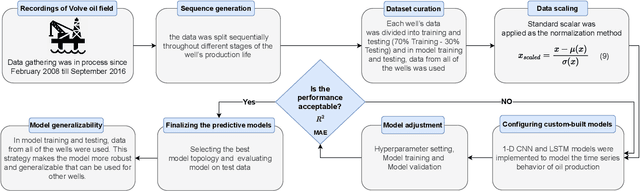
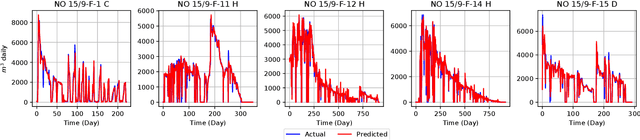
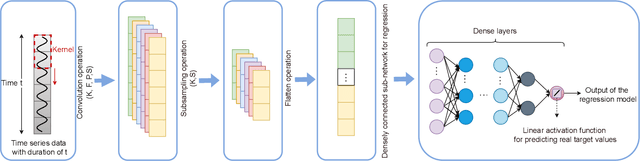
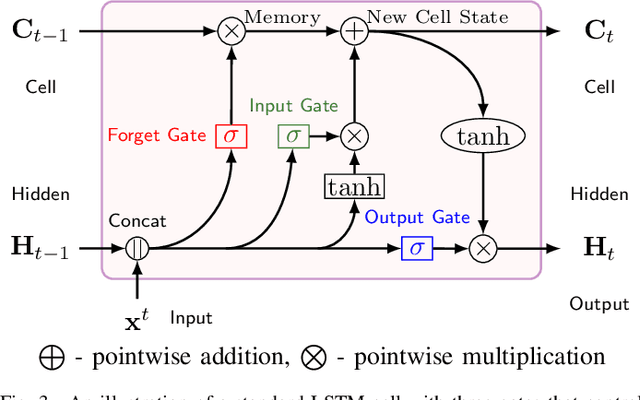
Global oil demand is rapidly increasing and is expected to reach 106.3 million barrels per day by 2040. Thus, it is vital for hydrocarbon extraction industries to forecast their production to optimize their operations and avoid losses. Big companies have realized that exploiting the power of deep learning (DL) and the massive amount of data from various oil wells for this purpose can save a lot of operational costs and reduce unwanted environmental impacts. In this direction, researchers have proposed models using conventional machine learning (ML) techniques for oil production forecasting. However, these techniques are inappropriate for this problem as they can not capture historical patterns found in time series data, resulting in inaccurate predictions. This research aims to overcome these issues by developing advanced data-driven regression models using sequential convolutions and long short-term memory (LSTM) units. Exhaustive analyses are conducted to select the optimal sequence length, model hyperparameters, and cross-well dataset formation to build highly generalized robust models. A comprehensive experimental study on Volve oilfield data validates the proposed models. It reveals that the LSTM-based sequence learning model can predict oil production better than the 1-D convolutional neural network (CNN) with mean absolute error (MAE) and R2 score of 111.16 and 0.98, respectively. It is also found that the LSTM-based model performs better than all the existing state-of-the-art solutions and achieves a 37% improvement compared to a standard linear regression, which is considered the baseline model in this work.
Unsupervised Representation Learning for Time Series: A Review
Aug 03, 2023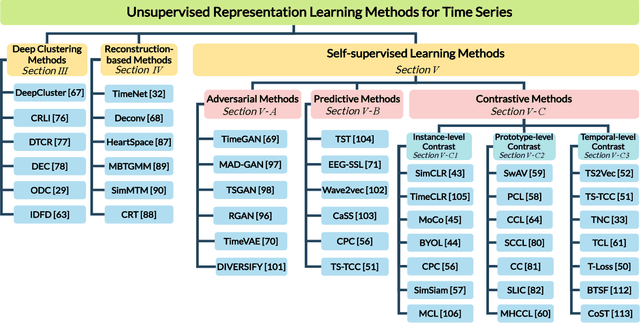
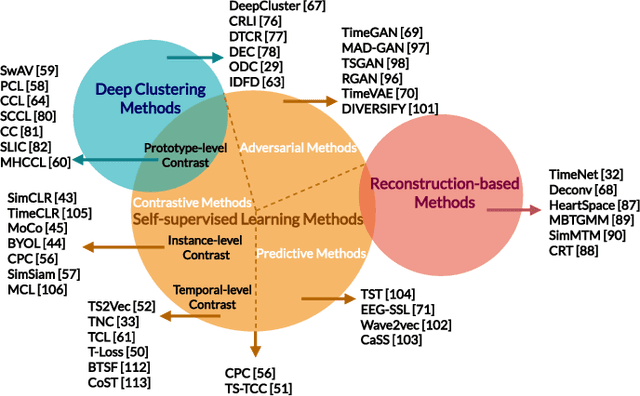

Unsupervised representation learning approaches aim to learn discriminative feature representations from unlabeled data, without the requirement of annotating every sample. Enabling unsupervised representation learning is extremely crucial for time series data, due to its unique annotation bottleneck caused by its complex characteristics and lack of visual cues compared with other data modalities. In recent years, unsupervised representation learning techniques have advanced rapidly in various domains. However, there is a lack of systematic analysis of unsupervised representation learning approaches for time series. To fill the gap, we conduct a comprehensive literature review of existing rapidly evolving unsupervised representation learning approaches for time series. Moreover, we also develop a unified and standardized library, named ULTS (i.e., Unsupervised Learning for Time Series), to facilitate fast implementations and unified evaluations on various models. With ULTS, we empirically evaluate state-of-the-art approaches, especially the rapidly evolving contrastive learning methods, on 9 diverse real-world datasets. We further discuss practical considerations as well as open research challenges on unsupervised representation learning for time series to facilitate future research in this field.
Recognition of Heat-Induced Food State Changes by Time-Series Use of Vision-Language Model for Cooking Robot
Sep 06, 2023Cooking tasks are characterized by large changes in the state of the food, which is one of the major challenges in robot execution of cooking tasks. In particular, cooking using a stove to apply heat to the foodstuff causes many special state changes that are not seen in other tasks, making it difficult to design a recognizer. In this study, we propose a unified method for recognizing changes in the cooking state of robots by using the vision-language model that can discriminate open-vocabulary objects in a time-series manner. We collected data on four typical state changes in cooking using a real robot and confirmed the effectiveness of the proposed method. We also compared the conditions and discussed the types of natural language prompts and the image regions that are suitable for recognizing the state changes.
An analysis of the derivative-free loss method for solving PDEs
Sep 28, 2023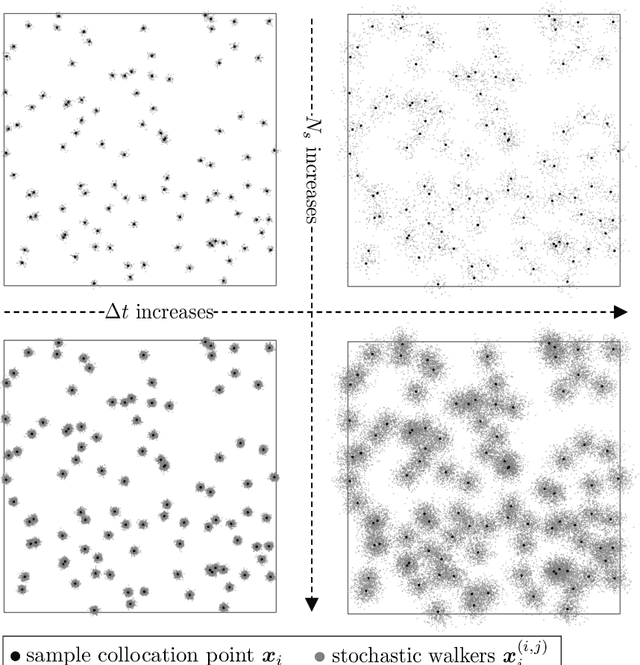
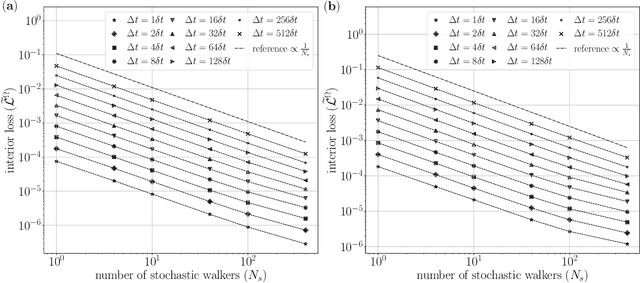
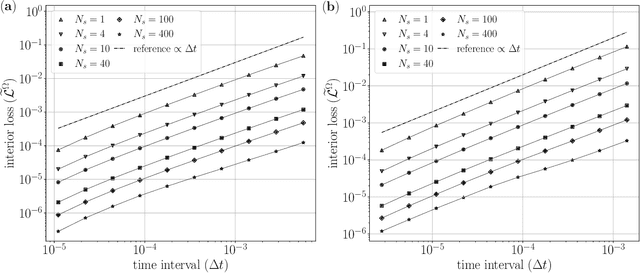
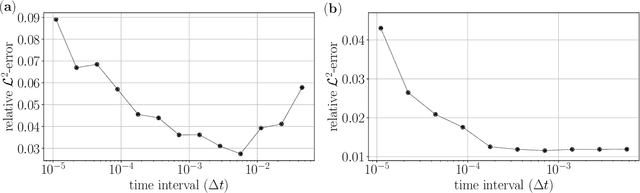
This study analyzes the derivative-free loss method to solve a certain class of elliptic PDEs using neural networks. The derivative-free loss method uses the Feynman-Kac formulation, incorporating stochastic walkers and their corresponding average values. We investigate the effect of the time interval related to the Feynman-Kac formulation and the walker size in the context of computational efficiency, trainability, and sampling errors. Our analysis shows that the training loss bias is proportional to the time interval and the spatial gradient of the neural network while inversely proportional to the walker size. We also show that the time interval must be sufficiently long to train the network. These analytic results tell that we can choose the walker size as small as possible based on the optimal lower bound of the time interval. We also provide numerical tests supporting our analysis.
Animatable Virtual Humans: Learning pose-dependent human representations in UV space for interactive performance synthesis
Oct 05, 2023
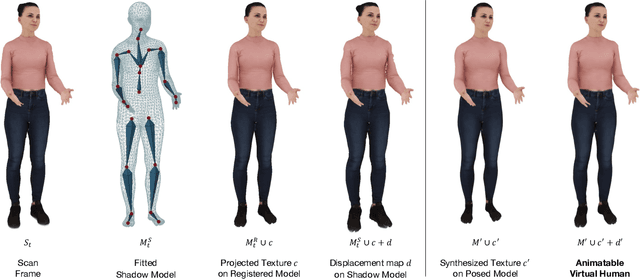
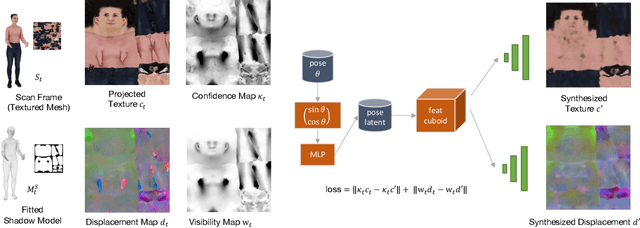

We propose a novel representation of virtual humans for highly realistic real-time animation and rendering in 3D applications. We learn pose dependent appearance and geometry from highly accurate dynamic mesh sequences obtained from state-of-the-art multiview-video reconstruction. Learning pose-dependent appearance and geometry from mesh sequences poses significant challenges, as it requires the network to learn the intricate shape and articulated motion of a human body. However, statistical body models like SMPL provide valuable a-priori knowledge which we leverage in order to constrain the dimension of the search space enabling more efficient and targeted learning and define pose-dependency. Instead of directly learning absolute pose-dependent geometry, we learn the difference between the observed geometry and the fitted SMPL model. This allows us to encode both pose-dependent appearance and geometry in the consistent UV space of the SMPL model. This approach not only ensures a high level of realism but also facilitates streamlined processing and rendering of virtual humans in real-time scenarios.
Clustering Three-Way Data with Outliers
Oct 08, 2023Matrix-variate distributions are a recent addition to the model-based clustering field, thereby making it possible to analyze data in matrix form with complex structure such as images and time series. Due to its recent appearance, there is limited literature on matrix-variate data, with even less on dealing with outliers in these models. An approach for clustering matrix-variate normal data with outliers is discussed. The approach, which uses the distribution of subset log-likelihoods, extends the OCLUST algorithm to matrix-variate normal data and uses an iterative approach to detect and trim outliers.
Active Learning with Dual Model Predictive Path-Integral Control for Interaction-Aware Autonomous Highway On-ramp Merging
Oct 11, 2023Merging into dense highway traffic for an autonomous vehicle is a complex decision-making task, wherein the vehicle must identify a potential gap and coordinate with surrounding human drivers, each of whom may exhibit diverse driving behaviors. Many existing methods consider other drivers to be dynamic obstacles and, as a result, are incapable of capturing the full intent of the human drivers via this passive planning. In this paper, we propose a novel dual control framework based on Model Predictive Path-Integral control to generate interactive trajectories. This framework incorporates a Bayesian inference approach to actively learn the agents' parameters, i.e., other drivers' model parameters. The proposed framework employs a sampling-based approach that is suitable for real-time implementation through the utilization of GPUs. We illustrate the effectiveness of our proposed methodology through comprehensive numerical simulations conducted in both high and low-fidelity simulation scenarios focusing on autonomous on-ramp merging.
To Build Our Future, We Must Know Our Past: Contextualizing Paradigm Shifts in Natural Language Processing
Oct 11, 2023NLP is in a period of disruptive change that is impacting our methodologies, funding sources, and public perception. In this work, we seek to understand how to shape our future by better understanding our past. We study factors that shape NLP as a field, including culture, incentives, and infrastructure by conducting long-form interviews with 26 NLP researchers of varying seniority, research area, institution, and social identity. Our interviewees identify cyclical patterns in the field, as well as new shifts without historical parallel, including changes in benchmark culture and software infrastructure. We complement this discussion with quantitative analysis of citation, authorship, and language use in the ACL Anthology over time. We conclude by discussing shared visions, concerns, and hopes for the future of NLP. We hope that this study of our field's past and present can prompt informed discussion of our community's implicit norms and more deliberate action to consciously shape the future.
AI/ML-based Load Prediction in IEEE 802.11 Enterprise Networks
Oct 11, 2023Enterprise Wi-Fi networks can greatly benefit from Artificial Intelligence and Machine Learning (AI/ML) thanks to their well-developed management and operation capabilities. At the same time, AI/ML-based traffic/load prediction is one of the most appealing data-driven solutions to improve the Wi-Fi experience, either through the enablement of autonomous operation or by boosting troubleshooting with forecasted network utilization. In this paper, we study the suitability and feasibility of adopting AI/ML-based load prediction in practical enterprise Wi-Fi networks. While leveraging AI/ML solutions can potentially contribute to optimizing Wi-Fi networks in terms of energy efficiency, performance, and reliability, their effective adoption is constrained to aspects like data availability and quality, computational capabilities, and energy consumption. Our results show that hardware-constrained AI/ML models can potentially predict network load with less than 20% average error and 3% 85th-percentile error, which constitutes a suitable input for proactively driving Wi-Fi network optimization.