 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Toward Inference-optimal Mixture-of-Expert Large Language Models
Apr 03, 2024
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
Terraced Compression Method with Automated Threshold Selection for Multidimensional Image Clustering of Heterogeneous Bodies
Apr 03, 2024Multispectral transmission imaging provides strong benefits for early breast cancer screening. The frame accumulation method addresses the challenge of low grayscale and signal-to-noise ratio resulting from the strong absorption and scattering of light by breast tissue. This method introduces redundancy in data while improving the grayscale and signal-to-noise ratio of the image. Existing terraced compression algorithms effectively eliminate the data redundancy introduced by frame accumulation but necessitate significant time for manual debugging of threshold values. Hence, this paper proposes an improved terrace compression algorithm. The algorithm necessitates solely the input of the desired heterogeneous body size and autonomously calculates the optimal area threshold and gradient threshold by counting the grayscale and combining its distribution. Experimental acquisition involved multi-wavelength images of heterogeneous bodies exhibiting diverse textures, depths, and thicknesses. Subsequently, the method was applied after pre-processing to determine the thresholds for terraced compression at each wavelength, coupled with a window function for multi-dimensional image clustering. The results illustrate the method's efficacy in detecting and identifying various heterogeneous body types, depths, and thicknesses. This approach is expected to accurately identify the locations and types of breast tumors in the future, thus providing a more dependable tool for early breast cancer screening.
Cross-Architecture Transfer Learning for Linear-Cost Inference Transformers
Apr 03, 2024Recently, multiple architectures has been proposed to improve the efficiency of the Transformer Language Models through changing the design of the self-attention block to have a linear-cost inference (LCI). A notable approach in this realm is the State-Space Machines (SSMs) architecture, which showed on-par performance on language modeling tasks with the self-attention transformers. However, such an architectural change requires a full pretraining of the weights from scratch, which incurs a huge cost to researchers and practitioners who want to use the new architectures. In the more traditional linear attention works, it has been proposed to approximate full attention with linear attention by swap-and-finetune framework. Motivated by this approach, we propose Cross-Architecture Transfer Learning (XATL), in which the weights of the shared components between LCI and self-attention-based transformers, such as layernorms, MLPs, input/output embeddings, are directly transferred to the new architecture from already pre-trained model parameters. We experimented the efficacy of the method on varying sizes and alternative attention architectures and show that \methodabbr significantly reduces the training time up to 2.5x times and converges to a better minimum with up to 2.6% stronger model on the LM benchmarks within the same compute budget.
HCTO: Optimality-Aware LiDAR Inertial Odometry with Hybrid Continuous Time Optimization for Compact Wearable Mapping System
Mar 21, 2024

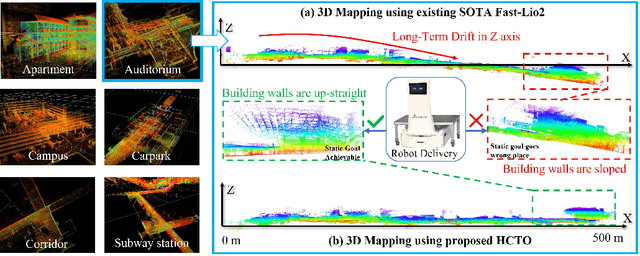
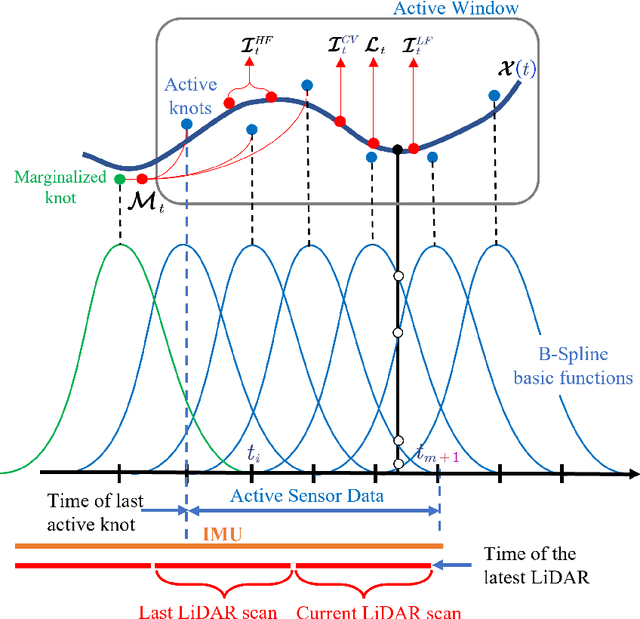
Compact wearable mapping system (WMS) has gained significant attention due to their convenience in various applications. Specifically, it provides an efficient way to collect prior maps for 3D structure inspection and robot-based "last-mile delivery" in complex environments. However, vibrations in human motion and the uneven distribution of point cloud features in complex environments often lead to rapid drift, which is a prevalent issue when applying existing LiDAR Inertial Odometry (LIO) methods on low-cost WMS. To address these limitations, we propose a novel LIO for WMSs based on Hybrid Continuous Time Optimization (HCTO) considering the optimality of Lidar correspondences. First, HCTO recognizes patterns in human motion (high-frequency part, low-frequency part, and constant velocity part) by analyzing raw IMU measurements. Second, HCTO constructs hybrid IMU factors according to different motion states, which enables robust and accurate estimation against vibration-induced noise in the IMU measurements. Third, the best point correspondences are selected using optimal design to achieve real-time performance and better odometry accuracy. We conduct experiments on head-mounted WMS datasets to evaluate the performance of our system, demonstrating significant advantages over state-of-the-art methods. Video recordings of experiments can be found on the project page of HCTO: \href{https://github.com/kafeiyin00/HCTO}{https://github.com/kafeiyin00/HCTO}.
Caformer: Rethinking Time Series Analysis from Causal Perspective
Mar 13, 2024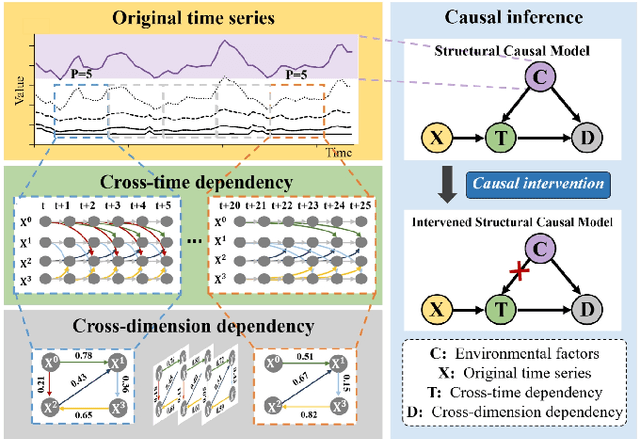
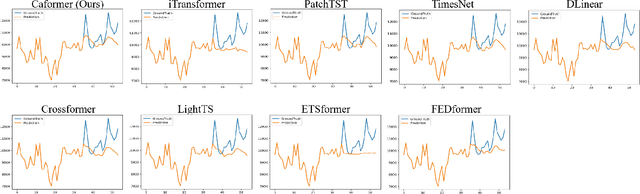
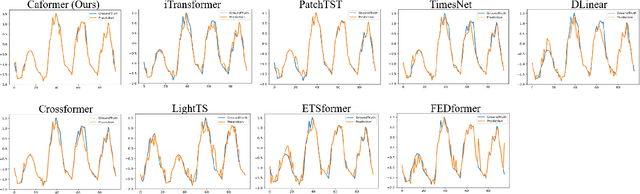
Time series analysis is a vital task with broad applications in various domains. However, effectively capturing cross-dimension and cross-time dependencies in non-stationary time series poses significant challenges, particularly in the context of environmental factors. The spurious correlation induced by the environment confounds the causal relationships between cross-dimension and cross-time dependencies. In this paper, we introduce a novel framework called Caformer (\underline{\textbf{Ca}}usal Trans\underline{\textbf{former}}) for time series analysis from a causal perspective. Specifically, our framework comprises three components: Dynamic Learner, Environment Learner, and Dependency Learner. The Dynamic Learner unveils dynamic interactions among dimensions, the Environment Learner mitigates spurious correlations caused by environment with a back-door adjustment, and the Dependency Learner aims to infer robust interactions across both time and dimensions. Our Caformer demonstrates consistent state-of-the-art performance across five mainstream time series analysis tasks, including long- and short-term forecasting, imputation, classification, and anomaly detection, with proper interpretability.
GGRt: Towards Pose-free Generalizable 3D Gaussian Splatting in Real-time
Mar 19, 2024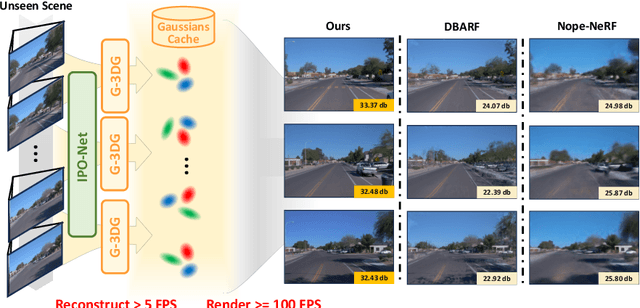
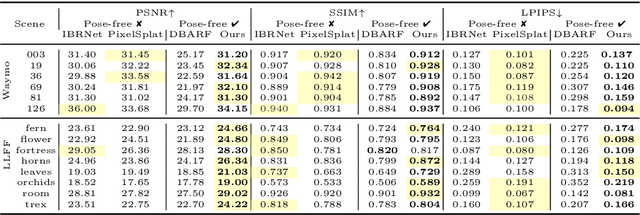
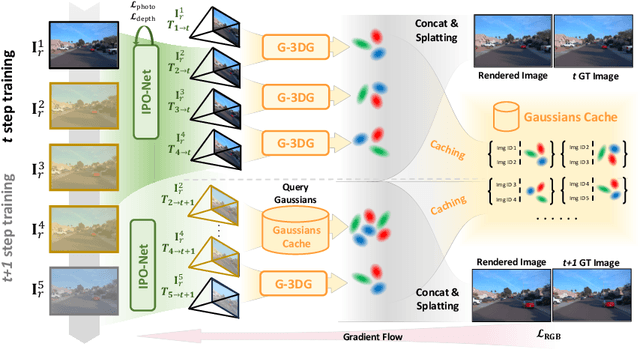

This paper presents GGRt, a novel approach to generalizable novel view synthesis that alleviates the need for real camera poses, complexity in processing high-resolution images, and lengthy optimization processes, thus facilitating stronger applicability of 3D Gaussian Splatting (3D-GS) in real-world scenarios. Specifically, we design a novel joint learning framework that consists of an Iterative Pose Optimization Network (IPO-Net) and a Generalizable 3D-Gaussians (G-3DG) model. With the joint learning mechanism, the proposed framework can inherently estimate robust relative pose information from the image observations and thus primarily alleviate the requirement of real camera poses. Moreover, we implement a deferred back-propagation mechanism that enables high-resolution training and inference, overcoming the resolution constraints of previous methods. To enhance the speed and efficiency, we further introduce a progressive Gaussian cache module that dynamically adjusts during training and inference. As the first pose-free generalizable 3D-GS framework, GGRt achieves inference at $\ge$ 5 FPS and real-time rendering at $\ge$ 100 FPS. Through extensive experimentation, we demonstrate that our method outperforms existing NeRF-based pose-free techniques in terms of inference speed and effectiveness. It can also approach the real pose-based 3D-GS methods. Our contributions provide a significant leap forward for the integration of computer vision and computer graphics into practical applications, offering state-of-the-art results on LLFF, KITTI, and Waymo Open datasets and enabling real-time rendering for immersive experiences.
Robust Overfitting Does Matter: Test-Time Adversarial Purification With FGSM
Mar 18, 2024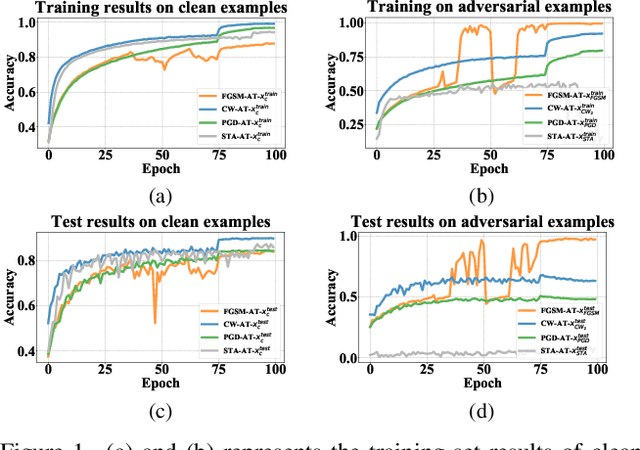
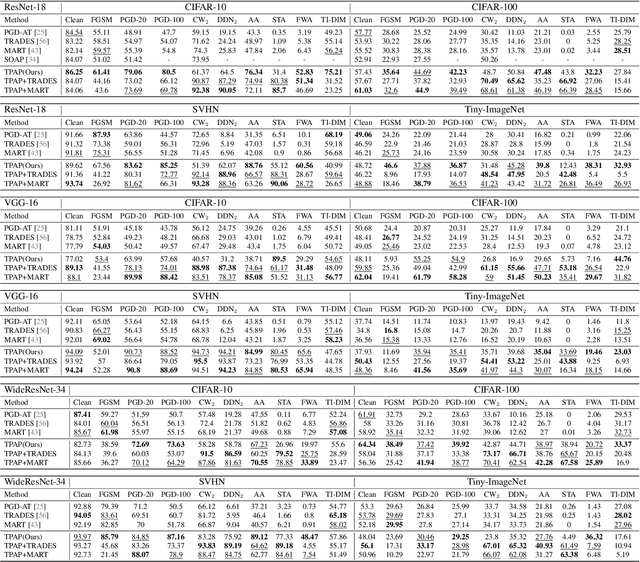
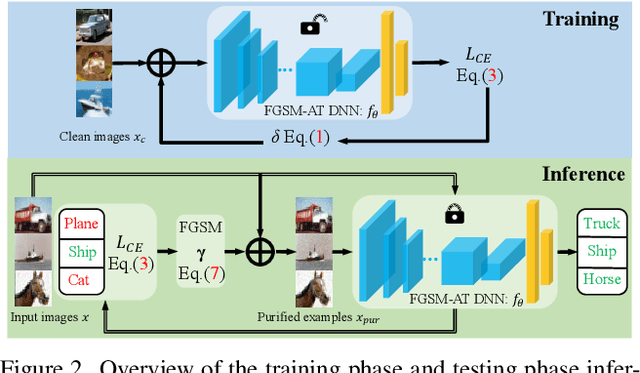
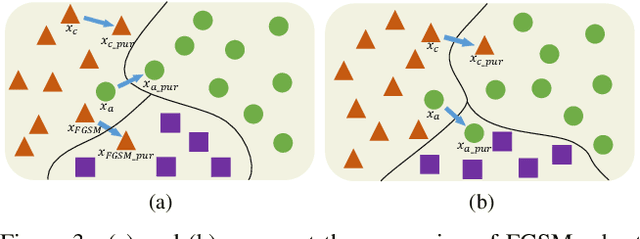
Numerous studies have demonstrated the susceptibility of deep neural networks (DNNs) to subtle adversarial perturbations, prompting the development of many advanced adversarial defense methods aimed at mitigating adversarial attacks. Current defense strategies usually train DNNs for a specific adversarial attack method and can achieve good robustness in defense against this type of adversarial attack. Nevertheless, when subjected to evaluations involving unfamiliar attack modalities, empirical evidence reveals a pronounced deterioration in the robustness of DNNs. Meanwhile, there is a trade-off between the classification accuracy of clean examples and adversarial examples. Most defense methods often sacrifice the accuracy of clean examples in order to improve the adversarial robustness of DNNs. To alleviate these problems and enhance the overall robust generalization of DNNs, we propose the Test-Time Pixel-Level Adversarial Purification (TPAP) method. This approach is based on the robust overfitting characteristic of DNNs to the fast gradient sign method (FGSM) on training and test datasets. It utilizes FGSM for adversarial purification, to process images for purifying unknown adversarial perturbations from pixels at testing time in a "counter changes with changelessness" manner, thereby enhancing the defense capability of DNNs against various unknown adversarial attacks. Extensive experimental results show that our method can effectively improve both overall robust generalization of DNNs, notably over previous methods.
Affective-NLI: Towards Accurate and Interpretable Personality Recognition in Conversation
Apr 03, 2024Personality Recognition in Conversation (PRC) aims to identify the personality traits of speakers through textual dialogue content. It is essential for providing personalized services in various applications of Human-Computer Interaction (HCI), such as AI-based mental therapy and companion robots for the elderly. Most recent studies analyze the dialog content for personality classification yet overlook two major concerns that hinder their performance. First, crucial implicit factors contained in conversation, such as emotions that reflect the speakers' personalities are ignored. Second, only focusing on the input dialog content disregards the semantic understanding of personality itself, which reduces the interpretability of the results. In this paper, we propose Affective Natural Language Inference (Affective-NLI) for accurate and interpretable PRC. To utilize affectivity within dialog content for accurate personality recognition, we fine-tuned a pre-trained language model specifically for emotion recognition in conversations, facilitating real-time affective annotations for utterances. For interpretability of recognition results, we formulate personality recognition as an NLI problem by determining whether the textual description of personality labels is entailed by the dialog content. Extensive experiments on two daily conversation datasets suggest that Affective-NLI significantly outperforms (by 6%-7%) state-of-the-art approaches. Additionally, our Flow experiment demonstrates that Affective-NLI can accurately recognize the speaker's personality in the early stages of conversations by surpassing state-of-the-art methods with 22%-34%.
DUQGen: Effective Unsupervised Domain Adaptation of Neural Rankers by Diversifying Synthetic Query Generation
Apr 03, 2024State-of-the-art neural rankers pre-trained on large task-specific training data such as MS-MARCO, have been shown to exhibit strong performance on various ranking tasks without domain adaptation, also called zero-shot. However, zero-shot neural ranking may be sub-optimal, as it does not take advantage of the target domain information. Unfortunately, acquiring sufficiently large and high quality target training data to improve a modern neural ranker can be costly and time-consuming. To address this problem, we propose a new approach to unsupervised domain adaptation for ranking, DUQGen, which addresses a critical gap in prior literature, namely how to automatically generate both effective and diverse synthetic training data to fine tune a modern neural ranker for a new domain. Specifically, DUQGen produces a more effective representation of the target domain by identifying clusters of similar documents; and generates a more diverse training dataset by probabilistic sampling over the resulting document clusters. Our extensive experiments, over the standard BEIR collection, demonstrate that DUQGen consistently outperforms all zero-shot baselines and substantially outperforms the SOTA baselines on 16 out of 18 datasets, for an average of 4% relative improvement across all datasets. We complement our results with a thorough analysis for more in-depth understanding of the proposed method's performance and to identify promising areas for further improvements.
TSNet:A Two-stage Network for Image Dehazing with Multi-scale Fusion and Adaptive Learning
Apr 03, 2024Image dehazing has been a popular topic of research for a long time. Previous deep learning-based image dehazing methods have failed to achieve satisfactory dehazing effects on both synthetic datasets and real-world datasets, exhibiting poor generalization. Moreover, single-stage networks often result in many regions with artifacts and color distortion in output images. To address these issues, this paper proposes a two-stage image dehazing network called TSNet, mainly consisting of the multi-scale fusion module (MSFM) and the adaptive learning module (ALM). Specifically, MSFM and ALM enhance the generalization of TSNet. The MSFM can obtain large receptive fields at multiple scales and integrate features at different frequencies to reduce the differences between inputs and learning objectives. The ALM can actively learn of regions of interest in images and restore texture details more effectively. Additionally, TSNet is designed as a two-stage network, where the first-stage network performs image dehazing, and the second-stage network is employed to improve issues such as artifacts and color distortion present in the results of the first-stage network. We also change the learning objective from ground truth images to opposite fog maps, which improves the learning efficiency of TSNet. Extensive experiments demonstrate that TSNet exhibits superior dehazing performance on both synthetic and real-world datasets compared to previous state-of-the-art methods.