 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time Series Analysis": models, code, and papers
Time Series Analysis of Big Data for Electricity Price and Demand to Find Cyber-Attacks part 2: Decomposition Analysis
Jul 30, 2019
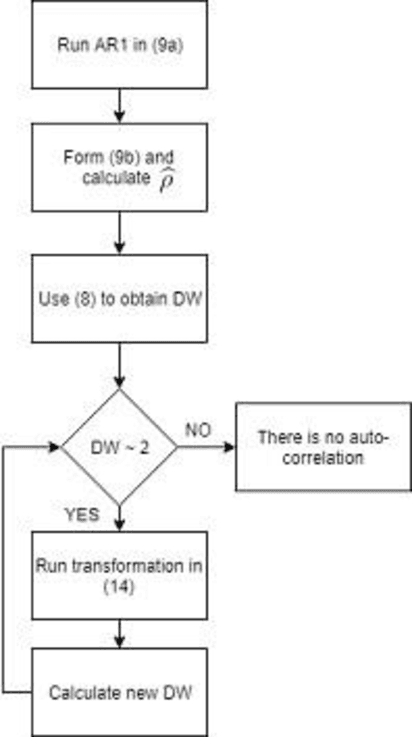
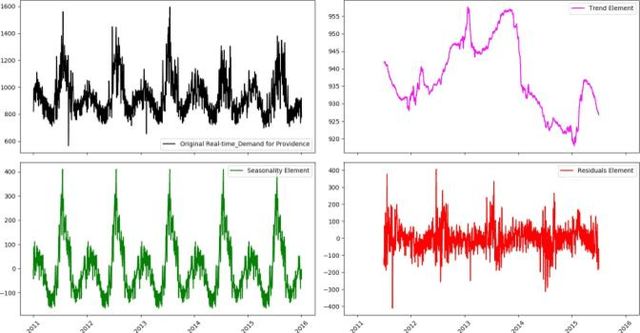
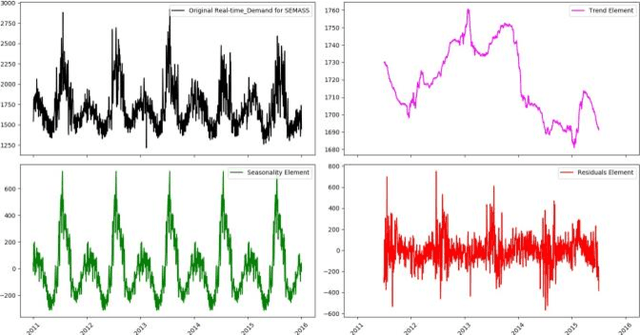
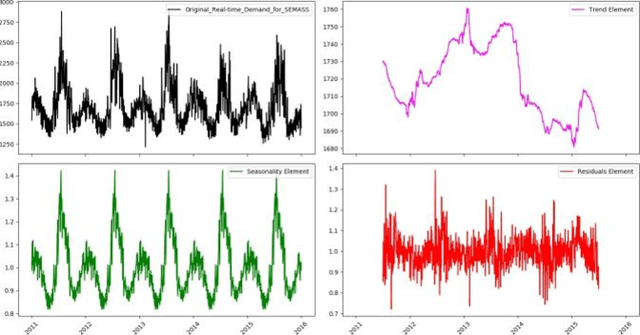
In this paper, in following of the first part (which ADF tests using ACI evaluation) has conducted, Time Series (TSs) are analyzed using decomposition analysis. In fact, TSs are composed of four components including trend (long term behavior or progression of series), cyclic component (non-periodic fluctuation behavior which are usually long term), seasonal component (periodic fluctuations due to seasonal variations like temperature, weather condition and etc.) and error term. For our case of cyber-attack detection, in this paper, two common ways of TS decomposition are investigated. The first method is additive decomposition and the second is multiplicative method to decompose a TS into its components. After decomposition, the error term is tested using Durbin-Watson and Breusch-Godfrey test to see whether the error follows any predictable pattern, it can be concluded that there is a chance of cyber-attack to the system.
Empirical Quantitative Analysis of COVID-19 Forecasting Models
Oct 01, 2021
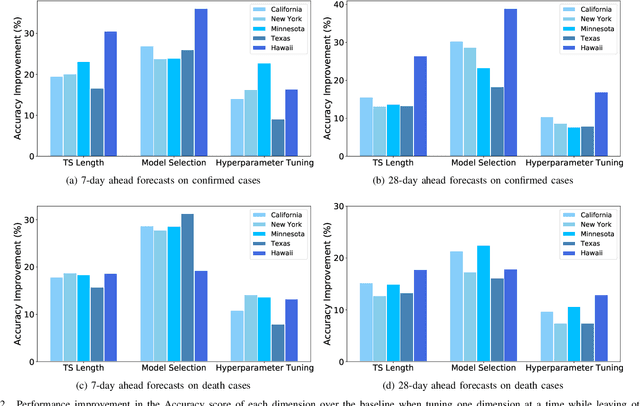
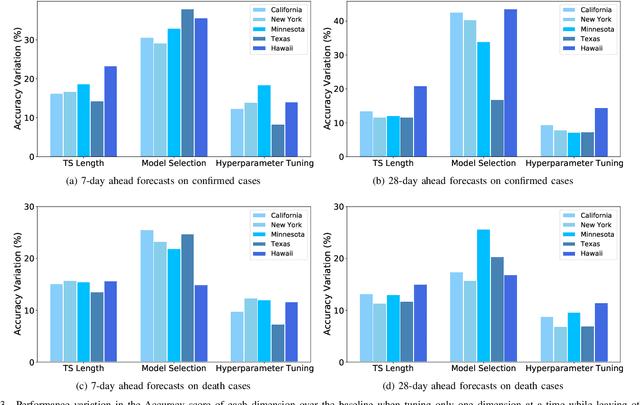
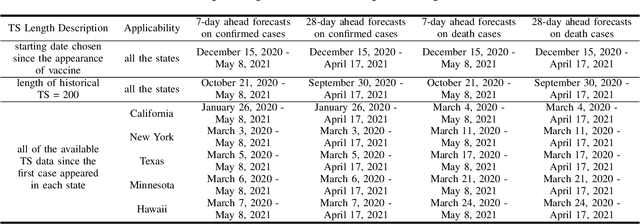
COVID-19 has been a public health emergency of international concern since early 2020. Reliable forecasting is critical to diminish the impact of this disease. To date, a large number of different forecasting models have been proposed, mainly including statistical models, compartmental models, and deep learning models. However, due to various uncertain factors across different regions such as economics and government policy, no forecasting model appears to be the best for all scenarios. In this paper, we perform quantitative analysis of COVID-19 forecasting of confirmed cases and deaths across different regions in the United States with different forecasting horizons, and evaluate the relative impacts of the following three dimensions on the predictive performance (improvement and variation) through different evaluation metrics: model selection, hyperparameter tuning, and the length of time series required for training. We find that if a dimension brings about higher performance gains, if not well-tuned, it may also lead to harsher performance penalties. Furthermore, model selection is the dominant factor in determining the predictive performance. It is responsible for both the largest improvement and the largest variation in performance in all prediction tasks across different regions. While practitioners may perform more complicated time series analysis in practice, they should be able to achieve reasonable results if they have adequate insight into key decisions like model selection.
Spatio-Temporal Representation Learning Enhanced Source Cell-phone Recognition from Speech Recordings
Aug 25, 2022
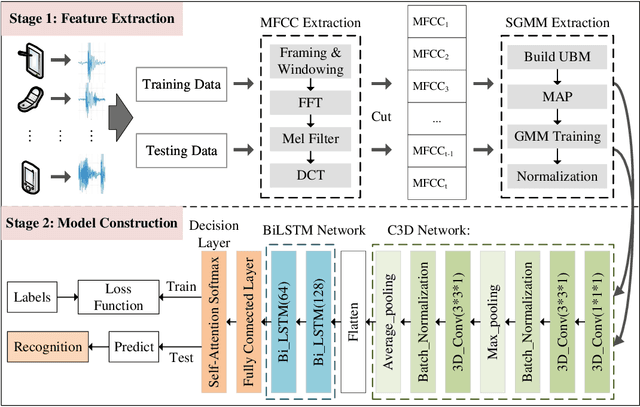
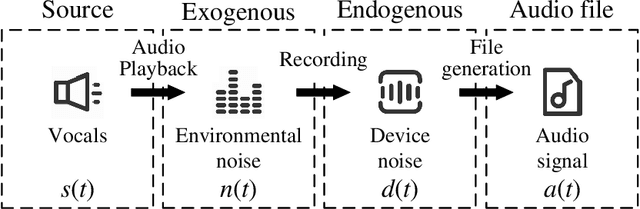

The existing source cell-phone recognition method lacks the long-term feature characterization of the source device, resulting in inaccurate representation of the source cell-phone related features which leads to insufficient recognition accuracy. In this paper, we propose a source cell-phone recognition method based on spatio-temporal representation learning, which includes two main parts: extraction of sequential Gaussian mean matrix features and construction of a recognition model based on spatio-temporal representation learning. In the feature extraction part, based on the analysis of time-series representation of recording source signals, we extract sequential Gaussian mean matrix with long-term and short-term representation ability by using the sensitivity of Gaussian mixture model to data distribution. In the model construction part, we design a structured spatio-temporal representation learning network C3D-BiLSTM to fully characterize the spatio-temporal information, combine 3D convolutional network and bidirectional long short-term memory network for short-term spectral information and long-time fluctuation information representation learning, and achieve accurate recognition of cell-phones by fusing spatio-temporal feature information of recording source signals. The method achieves an average accuracy of 99.03% for the closed-set recognition of 45 cell-phones under the CCNU\_Mobile dataset, and 98.18% in small sample size experiments, with recognition performance better than the existing state-of-the-art methods. The experimental results show that the method exhibits excellent recognition performance in multi-class cell-phones recognition.
Self-supervised learning for fast and scalable time series hyper-parameter tuning
Feb 10, 2021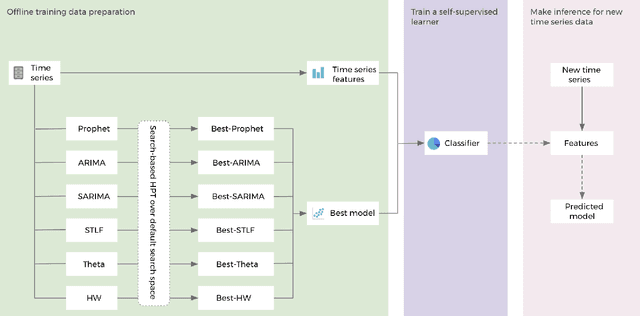

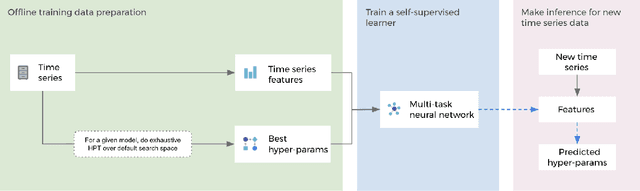
Hyper-parameters of time series models play an important role in time series analysis. Slight differences in hyper-parameters might lead to very different forecast results for a given model, and therefore, selecting good hyper-parameter values is indispensable. Most of the existing generic hyper-parameter tuning methods, such as Grid Search, Random Search, Bayesian Optimal Search, are based on one key component - search, and thus they are computationally expensive and cannot be applied to fast and scalable time-series hyper-parameter tuning (HPT). We propose a self-supervised learning framework for HPT (SSL-HPT), which uses time series features as inputs and produces optimal hyper-parameters. SSL-HPT algorithm is 6-20x faster at getting hyper-parameters compared to other search based algorithms while producing comparable accurate forecasting results in various applications.
Active Transfer Prototypical Network: An Efficient Labeling Algorithm for Time-Series Data
Sep 28, 2022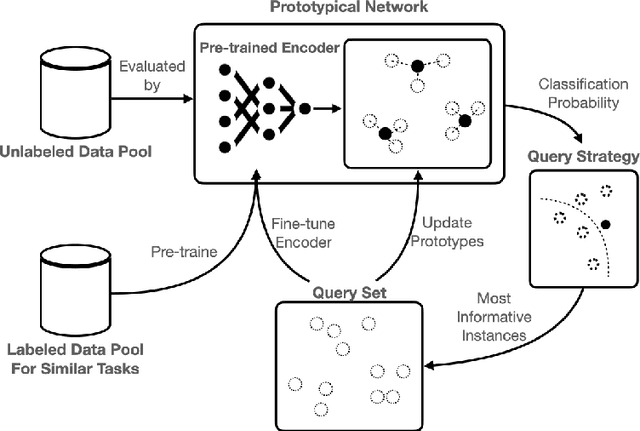
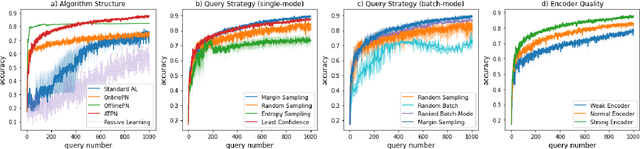
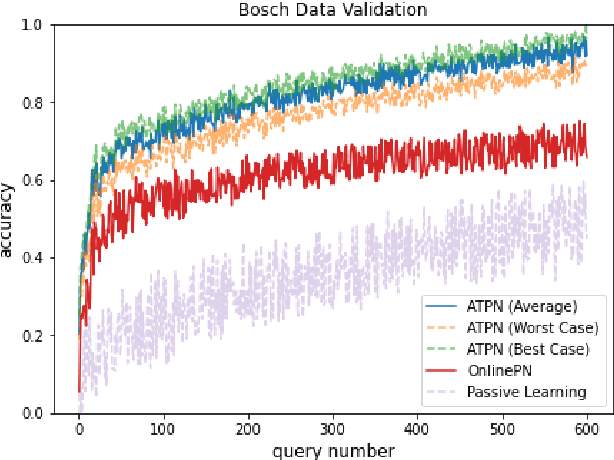
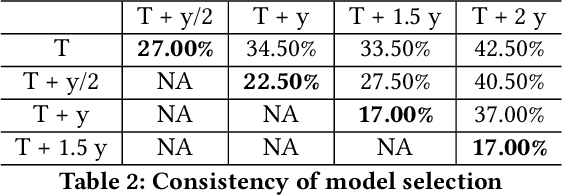
The paucity of labeled data is a typical challenge in the automotive industry. Annotating time-series measurements requires solid domain knowledge and in-depth exploratory data analysis, which implies a high labeling effort. Conventional Active Learning (AL) addresses this issue by actively querying the most informative instances based on the estimated classification probability and retraining the model iteratively. However, the learning efficiency strongly relies on the initial model, resulting in the trade-off between the size of the initial dataset and the query number. This paper proposes a novel Few-Shot Learning (FSL)-based AL framework, which addresses the trade-off problem by incorporating a Prototypical Network (ProtoNet) in the AL iterations. The results show an improvement, on the one hand, in the robustness to the initial model and, on the other hand, in the learning efficiency of the ProtoNet through the active selection of the support set in each iteration. This framework was validated on UCI HAR/HAPT dataset and a real-world braking maneuver dataset. The learning performance significantly surpasses traditional AL algorithms on both datasets, achieving 90% classification accuracy with 10% and 5% labeling effort, respectively.
HyperTime: Implicit Neural Representation for Time Series
Aug 11, 2022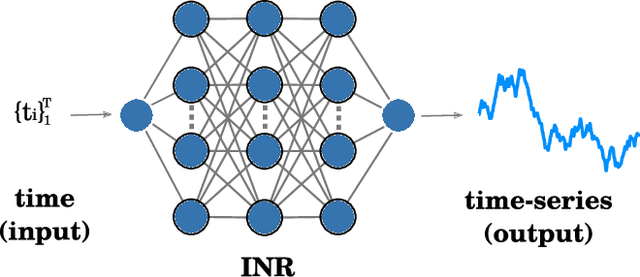
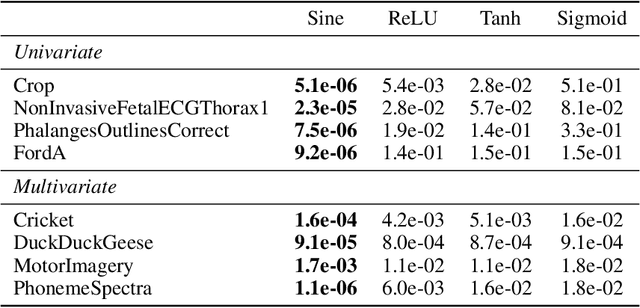
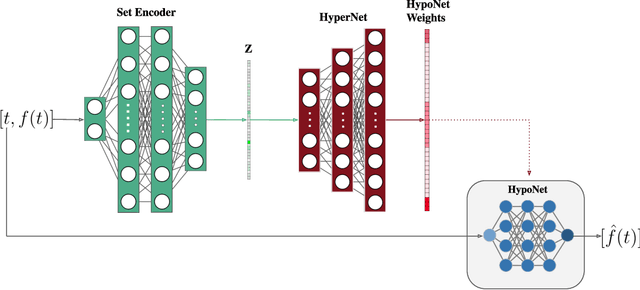
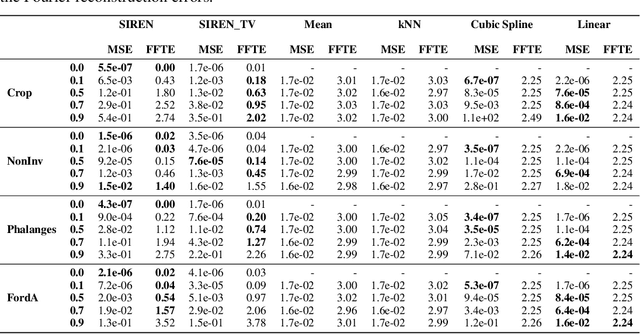
Implicit neural representations (INRs) have recently emerged as a powerful tool that provides an accurate and resolution-independent encoding of data. Their robustness as general approximators has been shown in a wide variety of data sources, with applications on image, sound, and 3D scene representation. However, little attention has been given to leveraging these architectures for the representation and analysis of time series data. In this paper, we analyze the representation of time series using INRs, comparing different activation functions in terms of reconstruction accuracy and training convergence speed. We show how these networks can be leveraged for the imputation of time series, with applications on both univariate and multivariate data. Finally, we propose a hypernetwork architecture that leverages INRs to learn a compressed latent representation of an entire time series dataset. We introduce an FFT-based loss to guide training so that all frequencies are preserved in the time series. We show that this network can be used to encode time series as INRs, and their embeddings can be interpolated to generate new time series from existing ones. We evaluate our generative method by using it for data augmentation, and show that it is competitive against current state-of-the-art approaches for augmentation of time series.
Pattern Discovery in Time Series with Byte Pair Encoding
May 30, 2021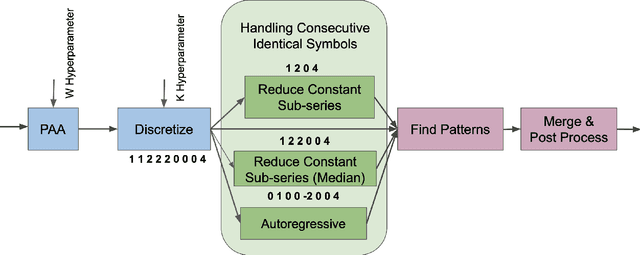
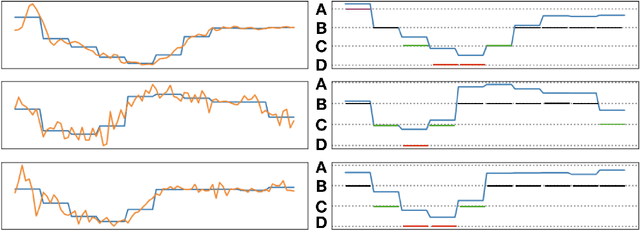
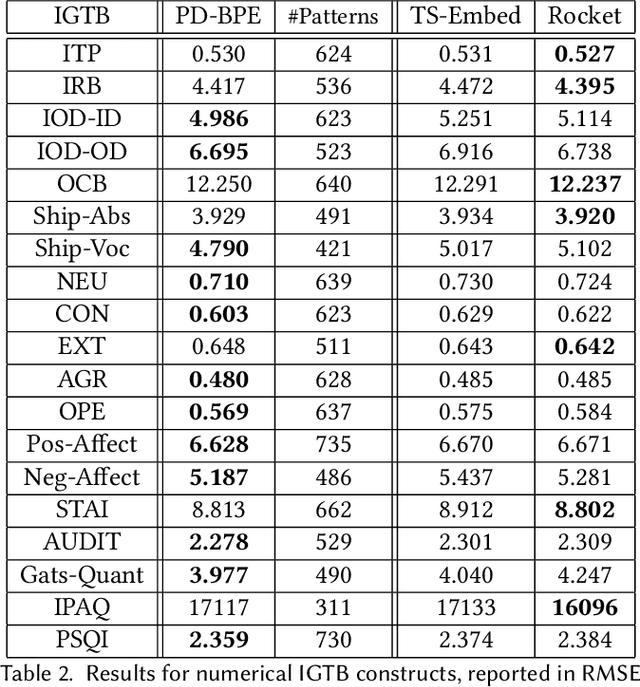
The growing popularity of wearable sensors has generated large quantities of temporal physiological and activity data. Ability to analyze this data offers new opportunities for real-time health monitoring and forecasting. However, temporal physiological data presents many analytic challenges: the data is noisy, contains many missing values, and each series has a different length. Most methods proposed for time series analysis and classification do not handle datasets with these characteristics nor do they offer interpretability and explainability, a critical requirement in the health domain. We propose an unsupervised method for learning representations of time series based on common patterns identified within them. The patterns are, interpretable, variable in length, and extracted using Byte Pair Encoding compression technique. In this way the method can capture both long-term and short-term dependencies present in the data. We show that this method applies to both univariate and multivariate time series and beats state-of-the-art approaches on a real world dataset collected from wearable sensors.
Diffusion-based Time Series Imputation and Forecasting with Structured State Space Models
Aug 19, 2022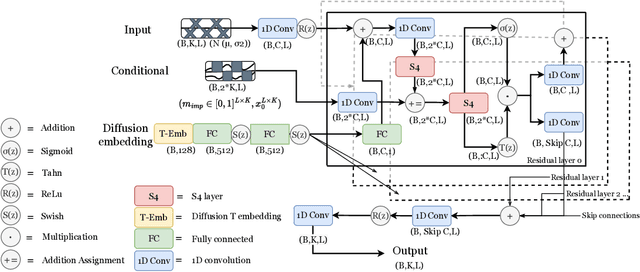
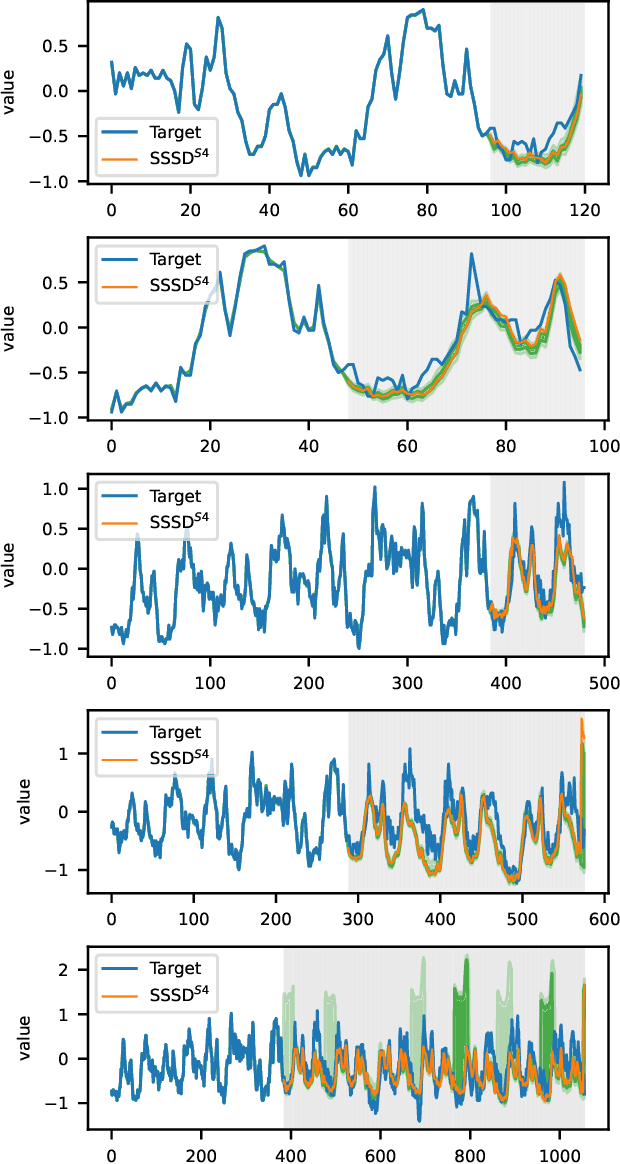
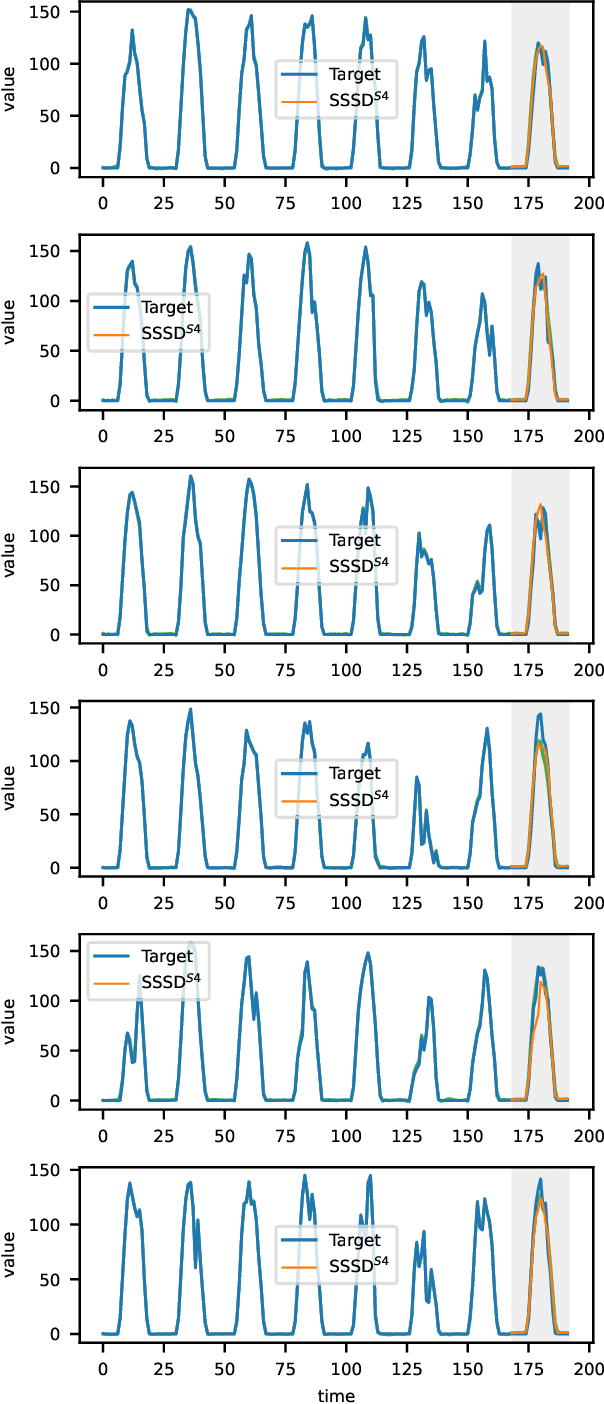
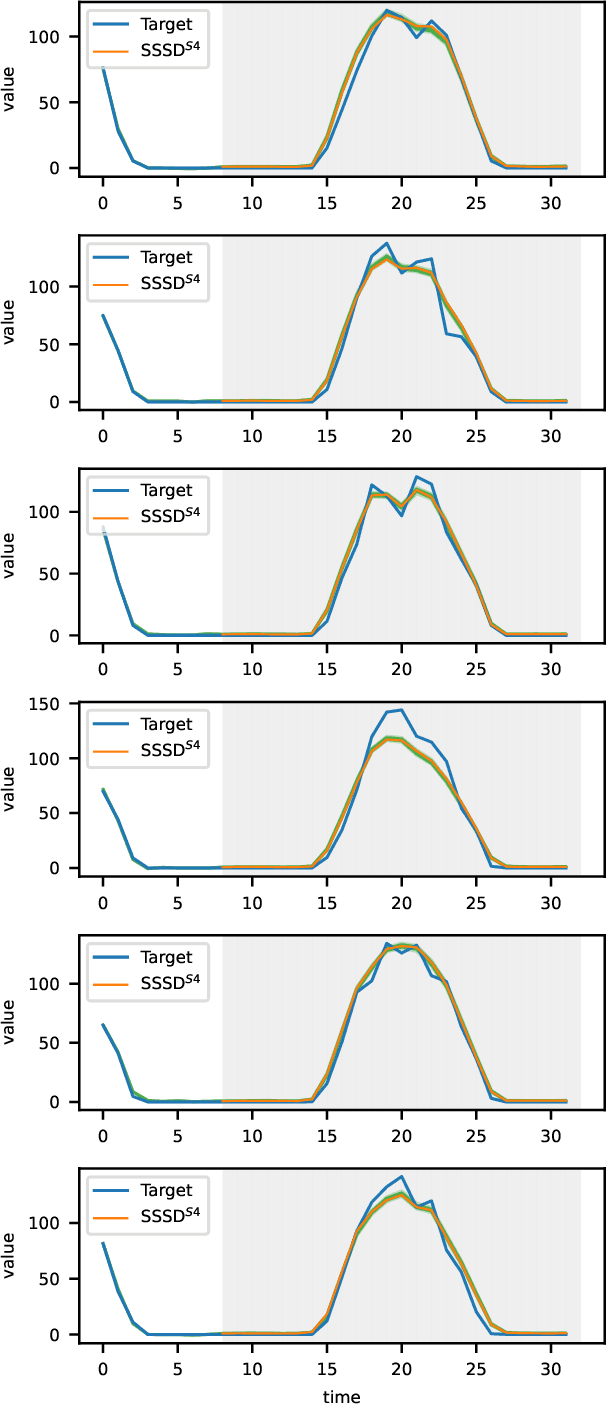
The imputation of missing values represents a significant obstacle for many real-world data analysis pipelines. Here, we focus on time series data and put forward SSSD, an imputation model that relies on two emerging technologies, (conditional) diffusion models as state-of-the-art generative models and structured state space models as internal model architecture, which are particularly suited to capture long-term dependencies in time series data. We demonstrate that SSSD matches or even exceeds state-of-the-art probabilistic imputation and forecasting performance on a broad range of data sets and different missingness scenarios, including the challenging blackout-missing scenarios, where prior approaches failed to provide meaningful results.
Bayesian Online Change Point Detection for Baseline Shifts
Jan 07, 2022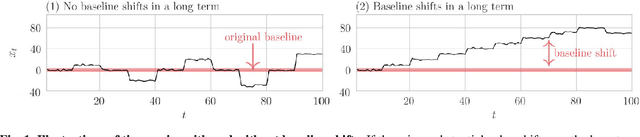
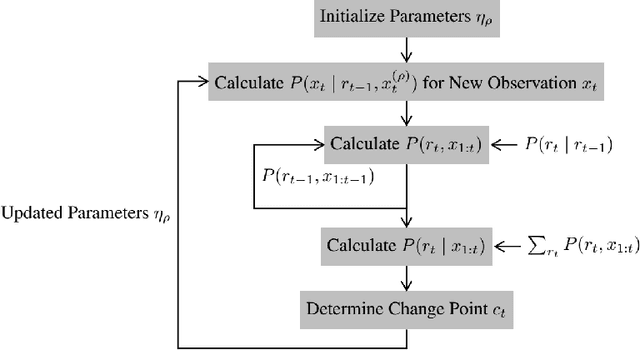

In time series data analysis, detecting change points on a real-time basis (online) is of great interest in many areas, such as finance, environmental monitoring, and medicine. One promising means to achieve this is the Bayesian online change point detection (BOCPD) algorithm, which has been successfully adopted in particular cases in which the time series of interest has a fixed baseline. However, we have found that the algorithm struggles when the baseline irreversibly shifts from its initial state. This is because with the original BOCPD algorithm, the sensitivity with which a change point can be detected is degraded if the data points are fluctuating at locations relatively far from the original baseline. In this paper, we not only extend the original BOCPD algorithm to be applicable to a time series whose baseline is constantly shifting toward unknown values but also visualize why the proposed extension works. To demonstrate the efficacy of the proposed algorithm compared to the original one, we examine these algorithms on two real-world data sets and six synthetic data sets.
* Published in Statistics, Optimization & Information Computing
Feature space approximation for kernel-based supervised learning
Nov 25, 2020
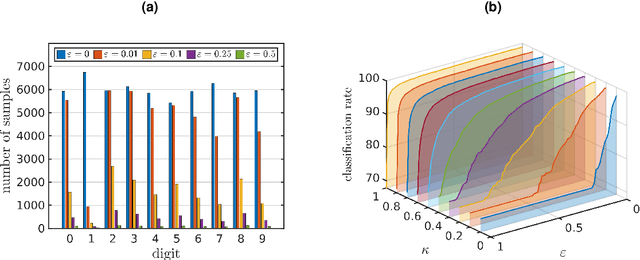
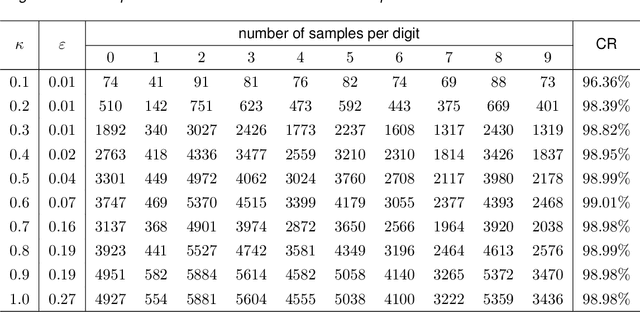
We propose a method for the approximation of high- or even infinite-dimensional feature vectors, which play an important role in supervised learning. The goal is to reduce the size of the training data, resulting in lower storage consumption and computational complexity. Furthermore, the method can be regarded as a regularization technique, which improves the generalizability of learned target functions. We demonstrate significant improvements in comparison to the computation of data-driven predictions involving the full training data set. The method is applied to classification and regression problems from different application areas such as image recognition, system identification, and oceanographic time series analysis.