 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time Series Analysis": models, code, and papers
Time Series Using Exponential Smoothing Cells
Sep 29, 2017
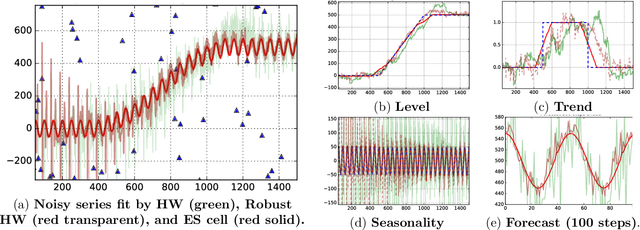
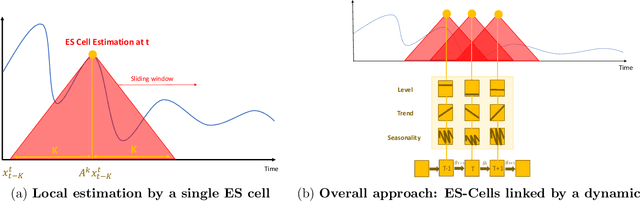
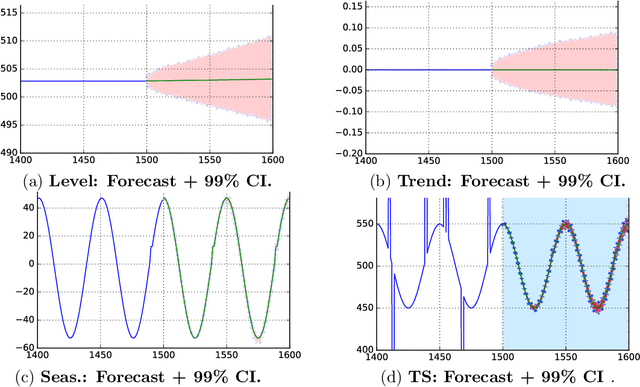
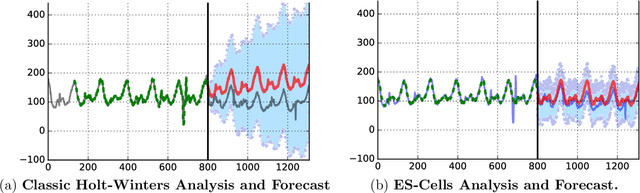
Time series analysis is used to understand and predict dynamic processes, including evolving demands in business, weather, markets, and biological rhythms. Exponential smoothing is used in all these domains to obtain simple interpretable models of time series and to forecast future values. Despite its popularity, exponential smoothing fails dramatically in the presence of outliers, large amounts of noise, or when the underlying time series changes. We propose a flexible model for time series analysis, using exponential smoothing cells for overlapping time windows. The approach can detect and remove outliers, denoise data, fill in missing observations, and provide meaningful forecasts in challenging situations. In contrast to classic exponential smoothing, which solves a nonconvex optimization problem over the smoothing parameters and initial state, the proposed approach requires solving a single structured convex optimization problem. Recent developments in efficient convex optimization of large-scale dynamic models make the approach tractable. We illustrate new capabilities using synthetic examples, and then use the approach to analyze and forecast noisy real-world time series. Code for the approach and experiments is publicly available.
A Recurrent Probabilistic Neural Network with Dimensionality Reduction Based on Time-series Discriminant Component Analysis
Nov 14, 2019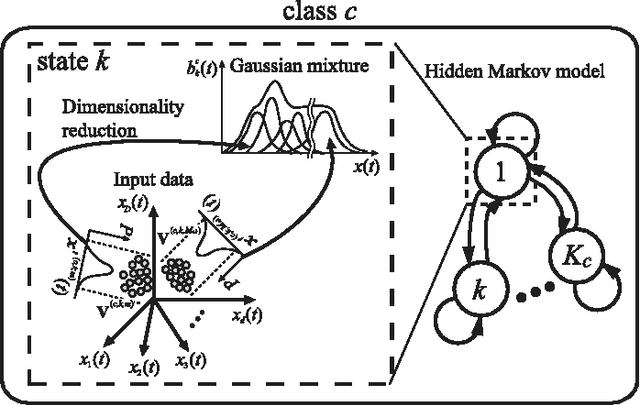
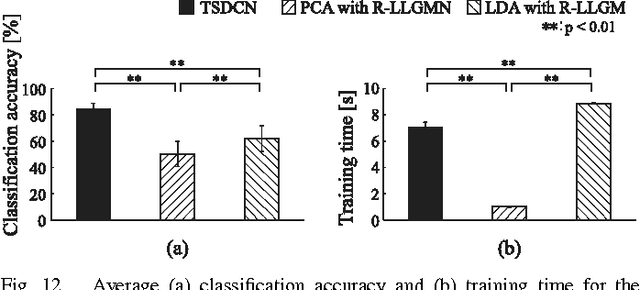
This paper proposes a probabilistic neural network developed on the basis of time-series discriminant component analysis (TSDCA) that can be used to classify high-dimensional time-series patterns. TSDCA involves the compression of high-dimensional time series into a lower-dimensional space using a set of orthogonal transformations and the calculation of posterior probabilities based on a continuous-density hidden Markov model with a Gaussian mixture model expressed in the reduced-dimensional space. The analysis can be incorporated into a neural network, which is named a time-series discriminant component network (TSDCN), so that parameters of dimensionality reduction and classification can be obtained simultaneously as network coefficients according to a backpropagation through time-based learning algorithm with the Lagrange multiplier method. The TSDCN is considered to enable high-accuracy classification of high-dimensional time-series patterns and to reduce the computation time taken for network training. The validity of the TSDCN is demonstrated for high-dimensional artificial data and EEG signals in the experiments conducted during the study.
* Published in IEEE Transactions on Neural Networks and Learning Systems
Forecasting NIFTY 50 benchmark Index using Seasonal ARIMA time series models
Jan 09, 2020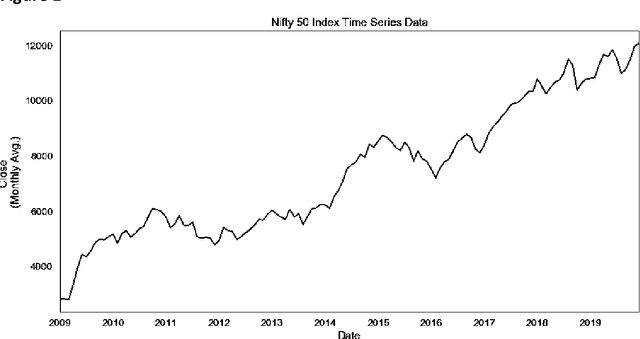
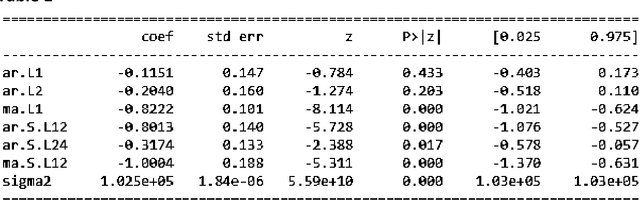
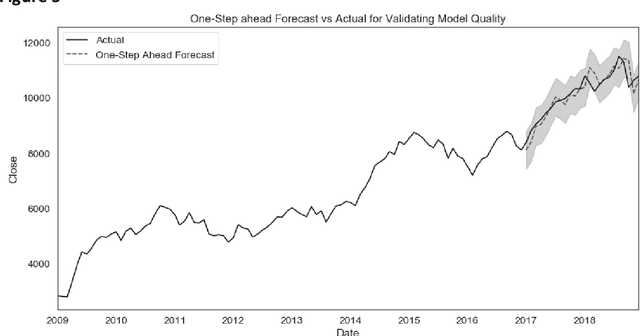
This paper analyses how Time Series Analysis techniques can be applied to capture movement of an exchange traded index in a stock market. Specifically, Seasonal Auto Regressive Integrated Moving Average (SARIMA) class of models is applied to capture the movement of Nifty 50 index which is one of the most actively exchange traded contracts globally [1]. A total of 729 model parameter combinations were evaluated and the most appropriate selected for making the final forecast based on AIC criteria [8]. NIFTY 50 can be used for a variety of purposes such as benchmarking fund portfolios, launching of index funds, exchange traded funds (ETFs) and structured products. The index tracks the behaviour of a portfolio of blue chip companies, the largest and most liquid Indian securities and can be regarded as a true reflection of the Indian stock market [2].
Optimal Transport Based Change Point Detection and Time Series Segment Clustering
Nov 04, 2019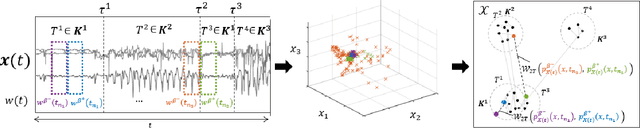


Two common problems in time series analysis are the decomposition of the data stream into disjoint segments, each of which is in some sense 'homogeneous' - a problem that is also referred to as Change Point Detection (CPD) - and the grouping of similar nonadjacent segments, or Time Series Segment Clustering (TSSC). Building upon recent theoretical advances characterizing the limiting distribution free behavior of the Wasserstein two-sample test, we propose a novel algorithm for unsupervised, distribution-free CPD, which is amenable to both offline and online settings. We also introduce a method to mitigate false positives in CPD, and address TSSC by using the Wasserstein distance between the detected segments to build an affinity matrix to which we apply spectral clustering. Results on both synthetic and real data sets show the benefits of the approach.
Crop Classification under Varying Cloud Cover with Neural Ordinary Differential Equations
Dec 04, 2020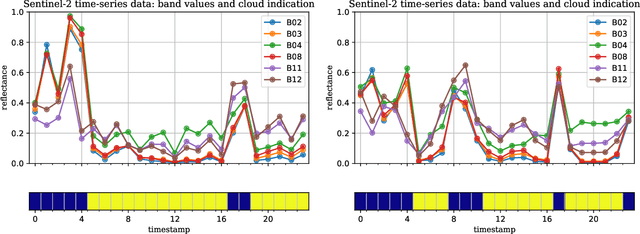

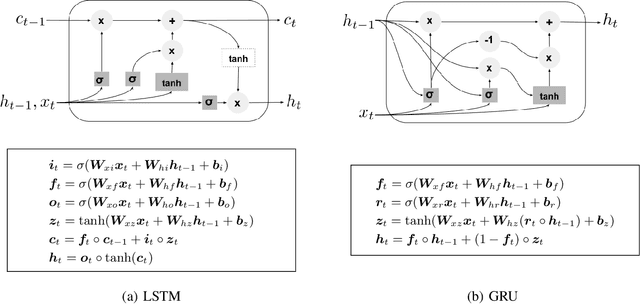
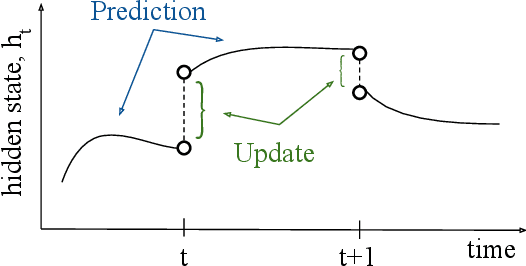
Optical satellite sensors cannot see the Earth's surface through clouds. Despite the periodic revisit cycle, image sequences acquired by Earth observation satellites are therefore irregularly sampled in time. State-of-the-art methods for crop classification (and other time series analysis tasks) rely on techniques that implicitly assume regular temporal spacing between observations, such as recurrent neural networks (RNNs). We propose to use neural ordinary differential equations (NODEs) in combination with RNNs to classify crop types in irregularly spaced image sequences. The resulting ODE-RNN models consist of two steps: an update step, where a recurrent unit assimilates new input data into the model's hidden state; and a prediction step, in which NODE propagates the hidden state until the next observation arrives. The prediction step is based on a continuous representation of the latent dynamics, which has several advantages. At the conceptual level, it is a more natural way to describe the mechanisms that govern the phenological cycle. From a practical point of view, it makes it possible to sample the system state at arbitrary points in time, such that one can integrate observations whenever they are available, and extrapolate beyond the last observation. Our experiments show that ODE-RNN indeed improves classification accuracy over common baselines such as LSTM, GRU, and temporal convolution. The gains are most prominent in the challenging scenario where only few observations are available (i.e., frequent cloud cover). Moreover, we show that the ability to extrapolate translates to better classification performance early in the season, which is important for forecasting.
Fuzzy Cognitive Maps and Hidden Markov Models: Comparative Analysis of Efficiency within the Confines of the Time Series Classification Task
Apr 28, 2022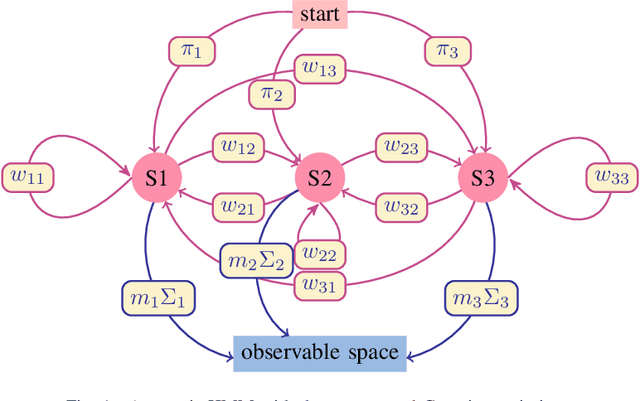
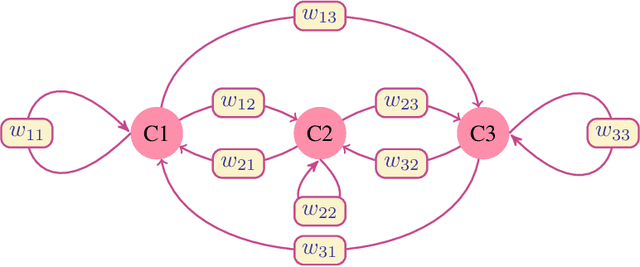
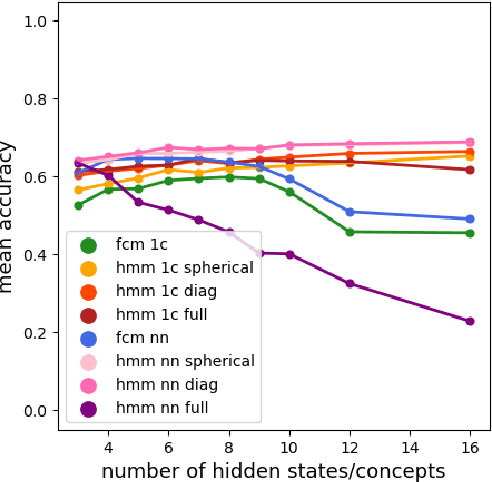
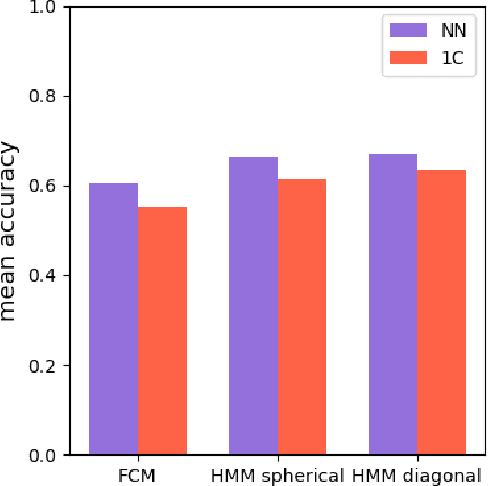
Time series classification is one of the very popular machine learning tasks. In this paper, we explore the application of Hidden Markov Model (HMM) for time series classification. We distinguish between two modes of HMM application. The first, in which a single model is built for each class. The second, in which one HMM is built for each time series. We then transfer both approaches for classifier construction to the domain of Fuzzy Cognitive Maps. The identified four models, HMM NN (HMM, one per series), HMM 1C (HMM, one per class), FCM NN, and FCM 1C are then studied in a series of experiments. We compare the performance of different models and investigate the impact of their hyperparameters on the time series classification accuracy. The empirical evaluation shows a clear advantage of the one-model-per-series approach. The results show that the choice between HMM and FCM should be dataset-dependent.
Time Series Data Augmentation for Deep Learning: A Survey
Feb 27, 2020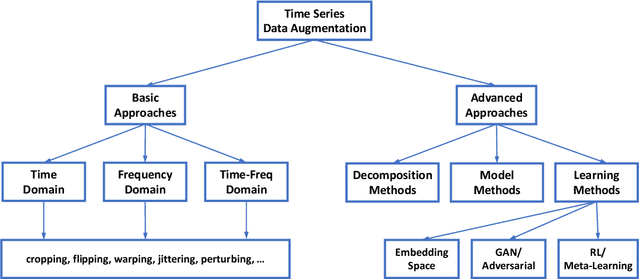
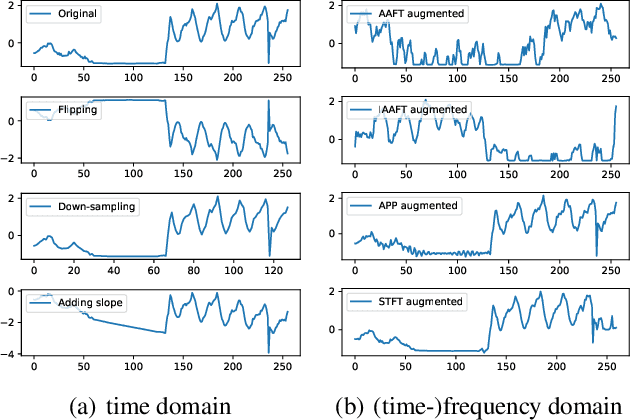

Deep learning performs remarkably well on many time series analysis tasks recently. The superior performance of deep neural networks relies heavily on a large number of training data to avoid overfitting. However, the labeled data of many real-world time series applications may be limited such as classification in medical time series and anomaly detection in AIOps. As an effective way to enhance the size and quality of the training data, data augmentation is crucial to the successful application of deep learning models on time series data. In this paper, we systematically review different data augmentation methods for time series. We propose a taxonomy for the reviewed methods, and then provide a structured review for these methods by highlighting their strengths and limitations. We also empirically compare different data augmentation methods for different tasks including time series anomaly detection, classification and forecasting. Finally, we discuss and highlight future research directions, including data augmentation in time-frequency domain, augmentation combination, and data augmentation and weighting for imbalanced class.
Exoplanet Detection using Machine Learning
Nov 28, 2020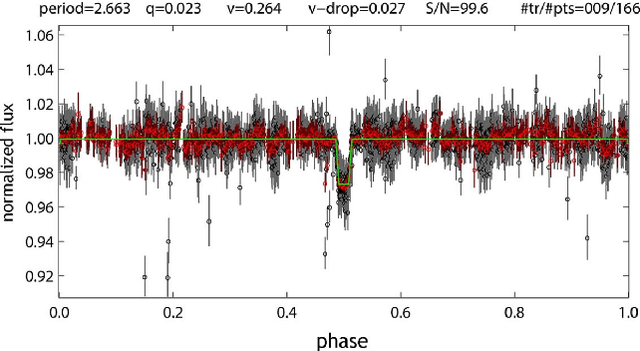
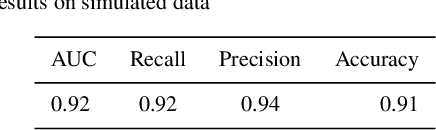
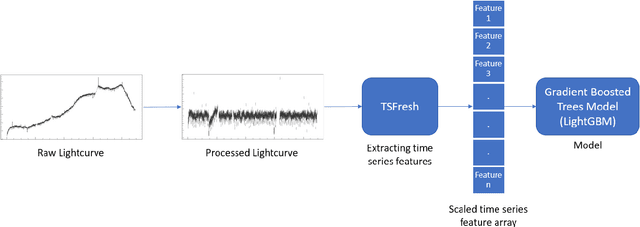

We introduce a new machine learning based technique to detect exoplanets using the transit method. Machine learning and deep learning techniques have proven to be broadly applicable in various scientific research areas. We aim to exploit some of these methods to improve the conventional algorithm based approach used in astrophysics today to detect exoplanets. We used the popular time-series analysis library 'TSFresh' to extract features from lightcurves. For each lightcurve, we extracted 789 features. These features capture information about the characteristics of a lightcurve. We used these features later to train a tree-based classifier using a popular machine learning tool 'lightgbm'. This was tested on simulated data which proved it to be more effective than conventional box least squares fitting (BLS). It produced comparable results to the existing state-of-art models while being much more computationally efficient and without needing folded and secondary views of the lightcurves. On Kepler data, the method is able to predict a planet with an AUC of 0.948 which means that, 94.8% of the time a planet signal is ranked higher than a non-planet signal and Recall of 0.96 meaning, 96% of real planets are classified as planets. With the Nasa's Transiting Exoplanet Survey Satellite (TESS), a reliable classification system is much needed as we are receiving over a million lightcurves per month. However, classification is harder as lightcurves are shorter. Our method is able to classify lightcurves with an accuracy of 98% and is able to identify planets with a Recall of 0.82.
Novel techniques for improvement the NNetEn entropy calculation for short and noisy time series
Feb 25, 2022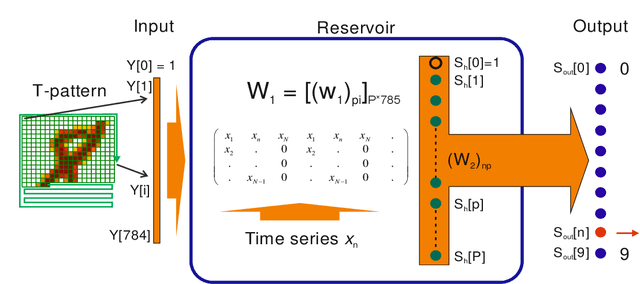
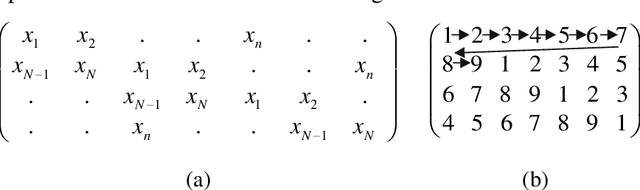

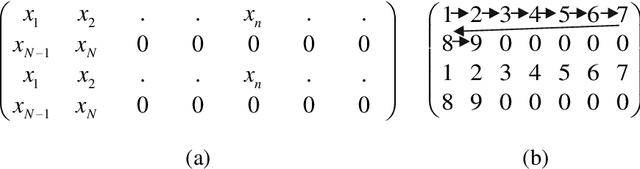
Entropy is a fundamental concept of information theory. It is widely used in the analysis of analog and digital signals. Conventional entropy measures have drawbacks, such as sensitivity to the length and amplitude of time series and low robustness to external noise. Recently, the NNetEn entropy measure has been introduced to overcome these problems. The NNetEn entropy uses a modified version of the LogNNet neural network classification model. The algorithm contains a reservoir matrix with N = 19625 elements, which the given time series should fill. Many practical time series have less than 19625 elements. Against this background, this paper investigates different duplicating and stretching techniques for filling to overcome this difficulty. The most successful technique is identified for practical applications. The presence of external noise and bias are other important issues affecting the efficiency of entropy measures. In order to perform meaningful analysis, three time series with different dynamics (chaotic, periodic, and binary), with a variation of signal-to-noise ratio (SNR) and offsets, are considered. It is shown that the error in the calculation of the NNetEn entropy does not exceed 10% when the SNR exceeds 30 dB. This opens the possibility of measuring the NNetEn of experimental signals in the presence of noise of various nature, white noise, or 1/f noise, without the need for noise filtering.
Piece-wise Matching Layer in Representation Learning for ECG Classification
Sep 26, 2020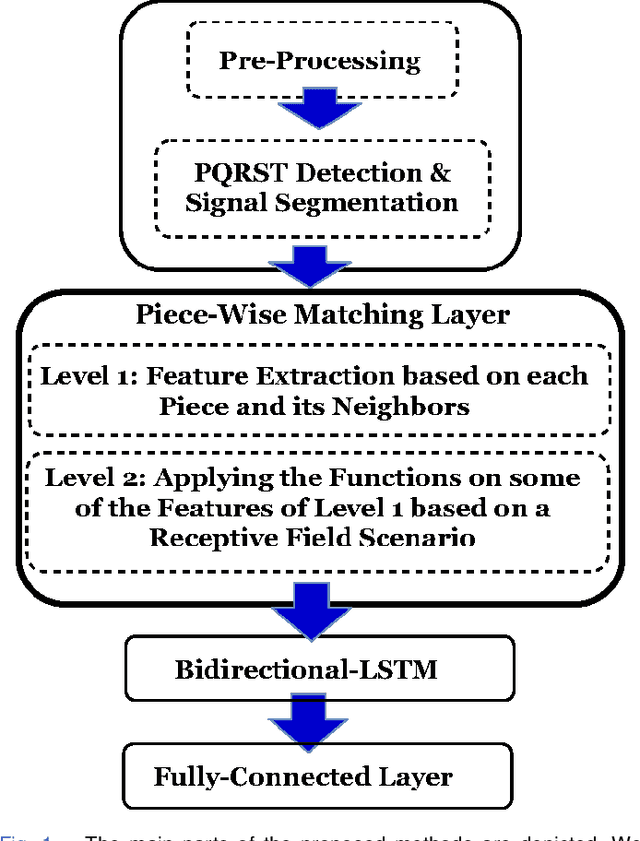
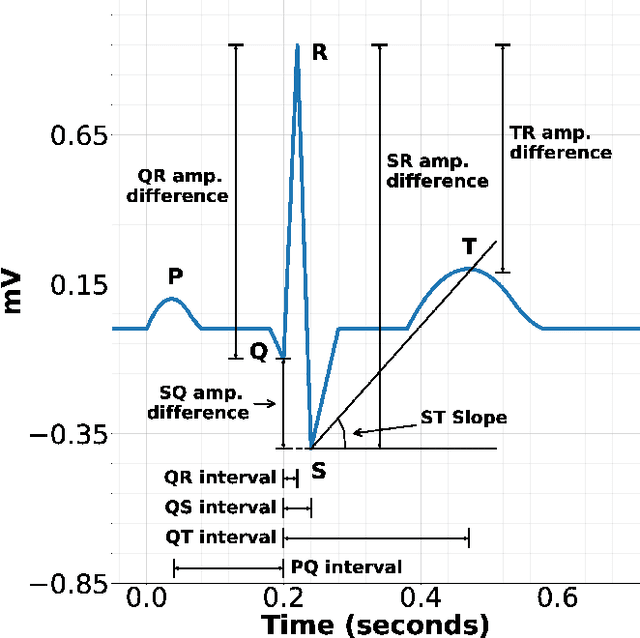
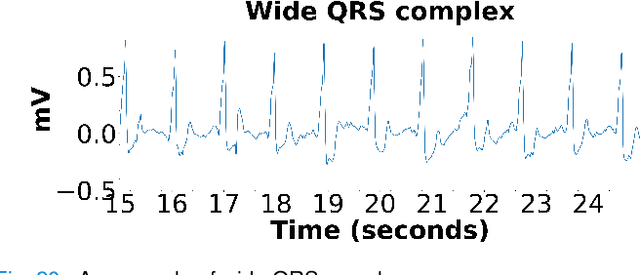
This paper proposes piece-wise matching layer as a novel layer in representation learning methods for electrocardiogram (ECG) classification. Despite the remarkable performance of representation learning methods in the analysis of time series, there are still several challenges associated with these methods ranging from the complex structures of methods, the lack of generality of solutions, the need for expert knowledge, and large-scale training datasets. We introduce the piece-wise matching layer that works based on two levels to address some of the aforementioned challenges. At the first level, a set of morphological, statistical, and frequency features and comparative forms of them are computed based on each periodic part and its neighbors. At the second level, these features are modified by predefined transformation functions based on a receptive field scenario. Several scenarios of offline processing, incremental processing, fixed sliding receptive field, and event-based triggering receptive field can be implemented based on the choice of length and mechanism of indicating the receptive field. We propose dynamic time wrapping as a mechanism that indicates a receptive field based on event triggering tactics. To evaluate the performance of this method in time series analysis, we applied the proposed layer in two publicly available datasets of PhysioNet competitions in 2015 and 2017 where the input data is ECG signal. We compared the performance of our method against a variety of known tuned methods from expert knowledge, machine learning, deep learning methods, and the combination of them. The proposed approach improves the state of the art in two known completions 2015 and 2017 around 4% and 7% correspondingly while it does not rely on in advance knowledge of the classes or the possible places of arrhythmia.