 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time Series Analysis": models, code, and papers
DTWSSE: Data Augmentation with a Siamese Encoder for Time Series
Aug 23, 2021
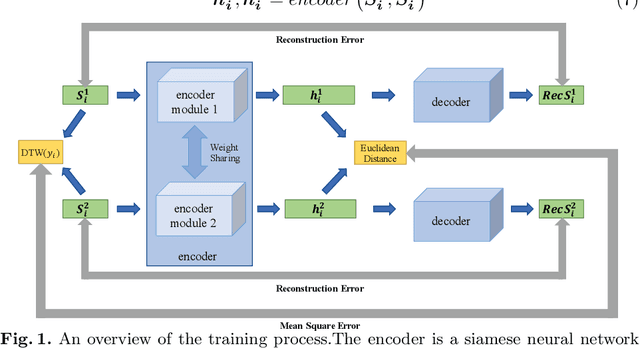
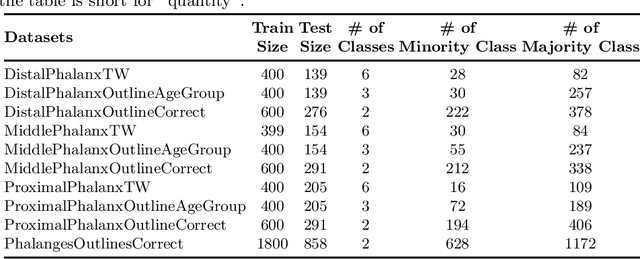
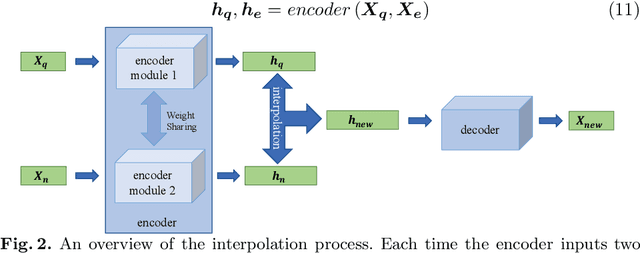
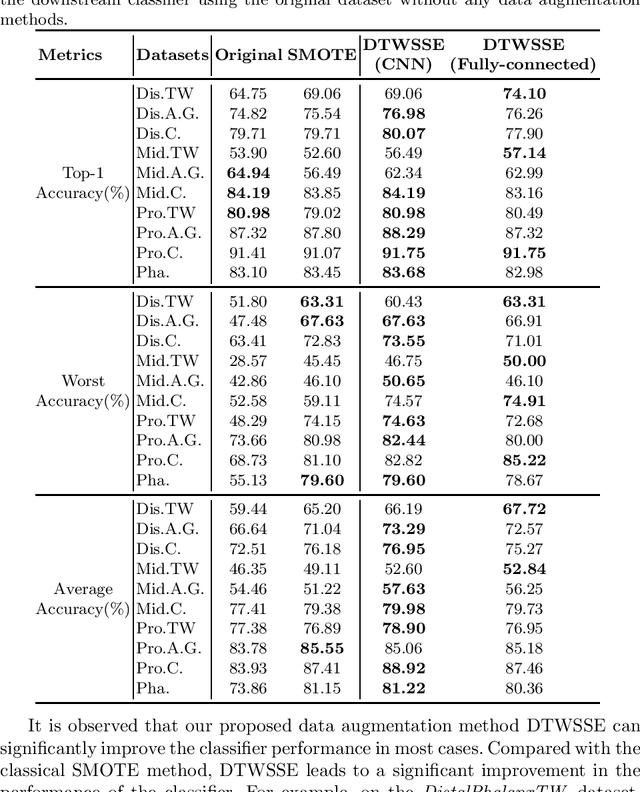
Access to labeled time series data is often limited in the real world, which constrains the performance of deep learning models in the field of time series analysis. Data augmentation is an effective way to solve the problem of small sample size and imbalance in time series datasets. The two key factors of data augmentation are the distance metric and the choice of interpolation method. SMOTE does not perform well on time series data because it uses a Euclidean distance metric and interpolates directly on the object. Therefore, we propose a DTW-based synthetic minority oversampling technique using siamese encoder for interpolation named DTWSSE. In order to reasonably measure the distance of the time series, DTW, which has been verified to be an effective method forts, is employed as the distance metric. To adapt the DTW metric, we use an autoencoder trained in an unsupervised self-training manner for interpolation. The encoder is a Siamese Neural Network for mapping the time series data from the DTW hidden space to the Euclidean deep feature space, and the decoder is used to map the deep feature space back to the DTW hidden space. We validate the proposed methods on a number of different balanced or unbalanced time series datasets. Experimental results show that the proposed method can lead to better performance of the downstream deep learning model.
Residual Networks as Flows of Velocity Fields for Diffeomorphic Time Series Alignment
Jun 22, 2021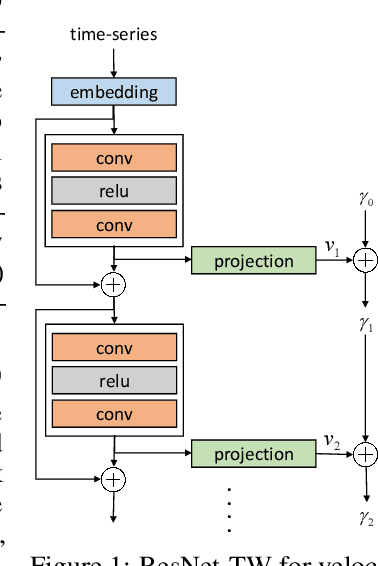

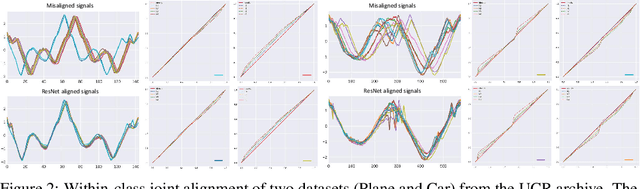
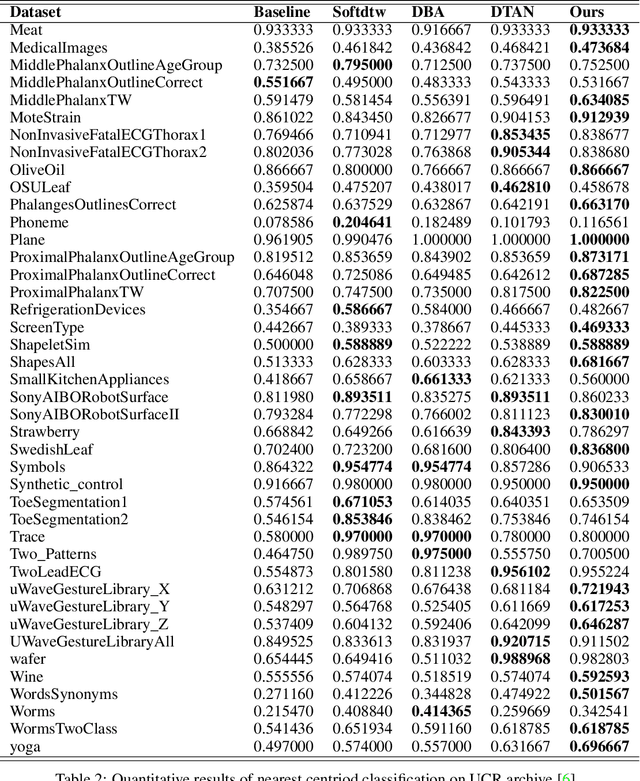
Non-linear (large) time warping is a challenging source of nuisance in time-series analysis. In this paper, we propose a novel diffeomorphic temporal transformer network for both pairwise and joint time-series alignment. Our ResNet-TW (Deep Residual Network for Time Warping) tackles the alignment problem by compositing a flow of incremental diffeomorphic mappings. Governed by the flow equation, our Residual Network (ResNet) builds smooth, fluid and regular flows of velocity fields and consequently generates smooth and invertible transformations (i.e. diffeomorphic warping functions). Inspired by the elegant Large Deformation Diffeomorphic Metric Mapping (LDDMM) framework, the final transformation is built by the flow of time-dependent vector fields which are none other than the building blocks of our Residual Network. The latter is naturally viewed as an Eulerian discretization schema of the flow equation (an ODE). Once trained, our ResNet-TW aligns unseen data by a single inexpensive forward pass. As we show in experiments on both univariate (84 datasets from UCR archive) and multivariate time-series (MSR Action-3D, Florence-3D and MSR Daily Activity), ResNet-TW achieves competitive performance in joint alignment and classification.
Time-Series Analysis via Low-Rank Matrix Factorization Applied to Infant-Sleep Data
Apr 10, 2019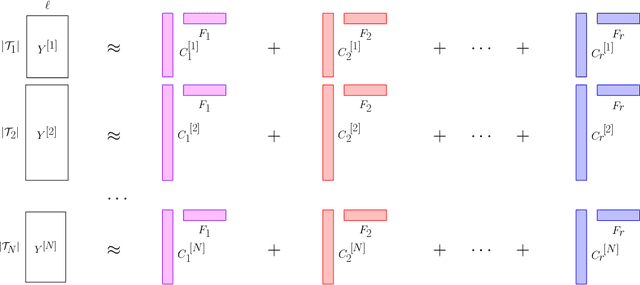
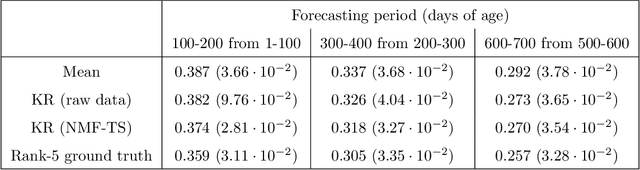
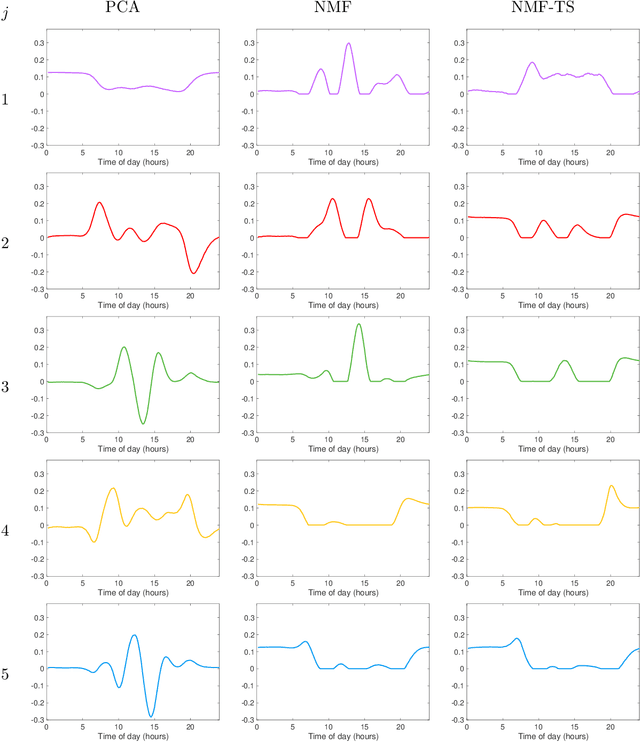
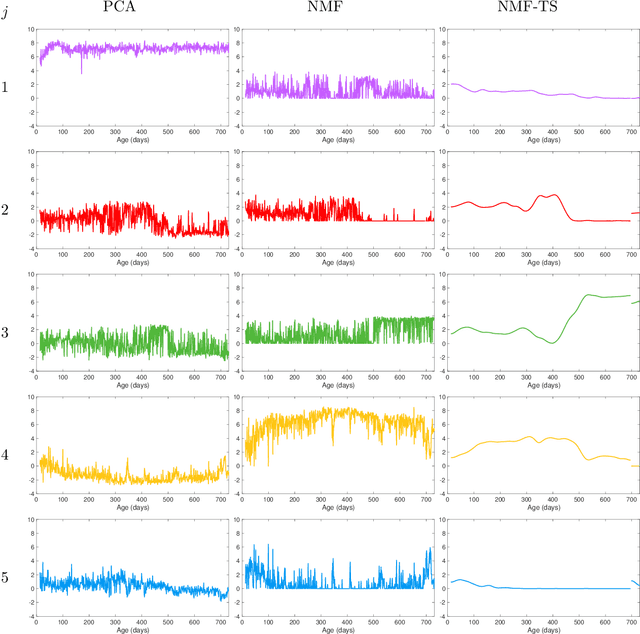
We propose a nonparametric model for time series with missing data based on low-rank matrix factorization. The model expresses each instance in a set of time series as a linear combination of a small number of shared basis functions. Constraining the functions and the corresponding coefficients to be nonnegative yields an interpretable low-dimensional representation of the data. A time-smoothing regularization term ensures that the model captures meaningful trends in the data, instead of overfitting short-term fluctuations. The low-dimensional representation makes it possible to detect outliers and cluster the time series according to the interpretable features extracted by the model, and also to perform forecasting via kernel regression. We apply our methodology to a large real-world dataset of infant-sleep data gathered by caregivers with a mobile-phone app. Our analysis automatically extracts daily-sleep patterns consistent with the existing literature. This allows us to compute sleep-development trends for the cohort, which characterize the emergence of circadian sleep and different napping habits. We apply our methodology to detect anomalous individuals, to cluster the cohort into groups with different sleeping tendencies, and to obtain improved predictions of future sleep behavior.
Time Adaptive Gaussian Model
Feb 03, 2021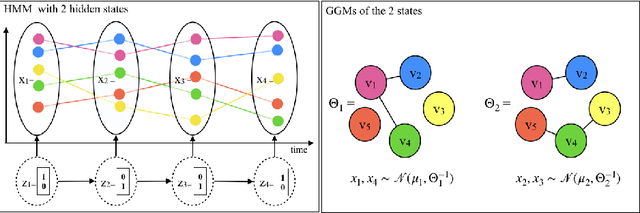
Multivariate time series analysis is becoming an integral part of data analysis pipelines. Understanding the individual time point connections between covariates as well as how these connections change in time is non-trivial. To this aim, we propose a novel method that leverages on Hidden Markov Models and Gaussian Graphical Models -- Time Adaptive Gaussian Model (TAGM). Our model is a generalization of state-of-the-art methods for the inference of temporal graphical models, its formulation leverages on both aspects of these models providing better results than current methods. In particular,it performs pattern recognition by clustering data points in time; and, it finds probabilistic (and possibly causal) relationships among the observed variables. Compared to current methods for temporal network inference, it reduces the basic assumptions while still showing good inference performances.
ConFuse: Convolutional Transform Learning Fusion Framework For Multi-Channel Data Analysis
Nov 09, 2020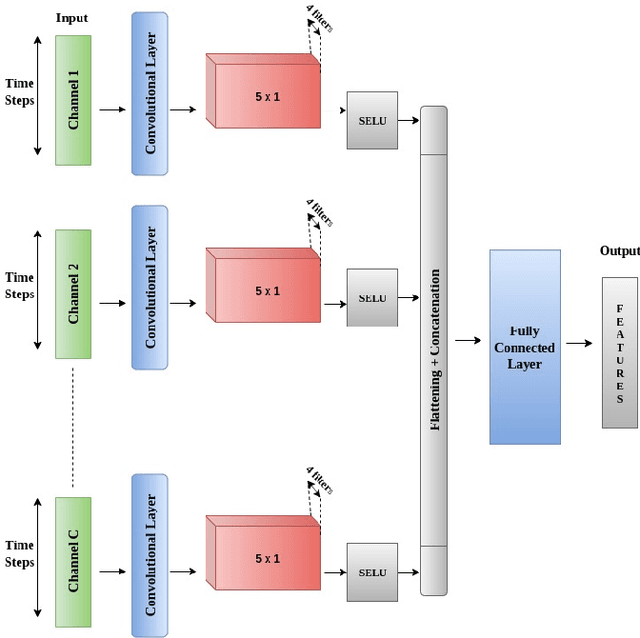
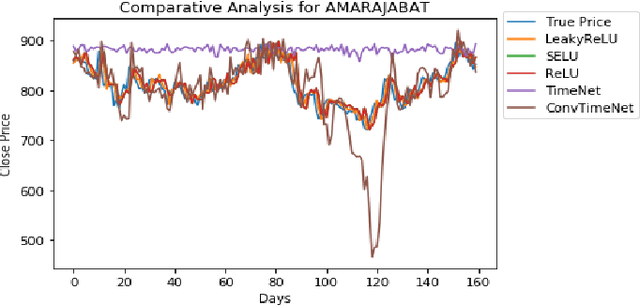
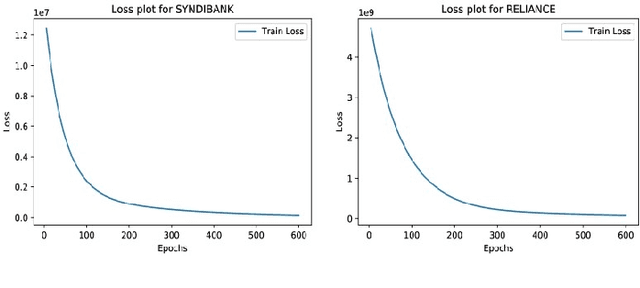
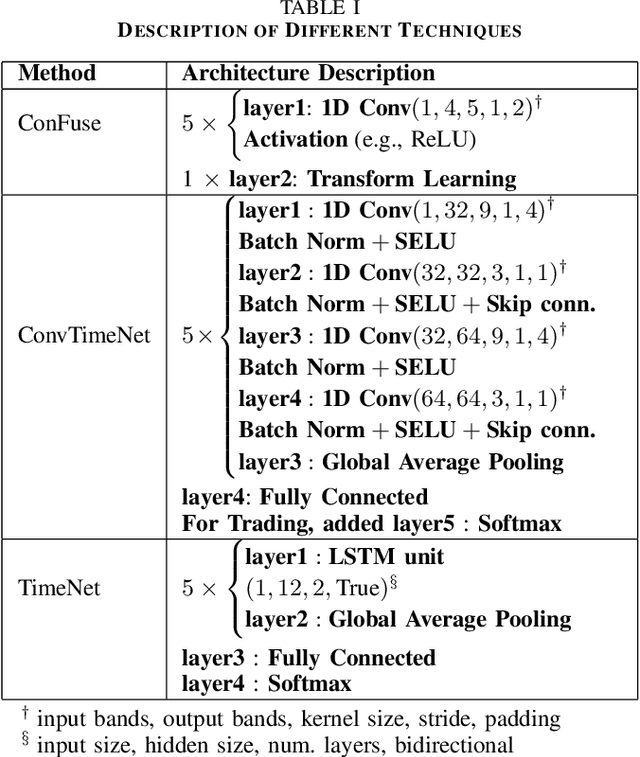
This work addresses the problem of analyzing multi-channel time series data %. In this paper, we by proposing an unsupervised fusion framework based on %the recently proposed convolutional transform learning. Each channel is processed by a separate 1D convolutional transform; the output of all the channels are fused by a fully connected layer of transform learning. The training procedure takes advantage of the proximal interpretation of activation functions. We apply the developed framework to multi-channel financial data for stock forecasting and trading. We compare our proposed formulation with benchmark deep time series analysis networks. The results show that our method yields considerably better results than those compared against.
POP: Mining POtential Performance of new fashion products via webly cross-modal query expansion
Jul 22, 2022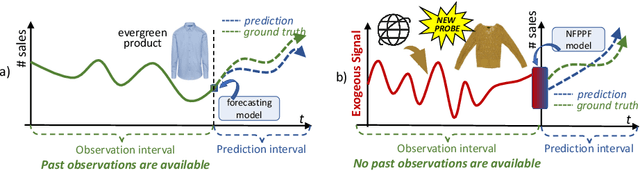
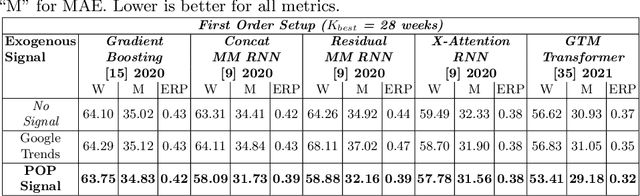

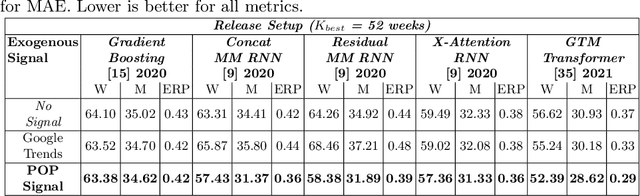
We propose a data-centric pipeline able to generate exogenous observation data for the New Fashion Product Performance Forecasting (NFPPF) problem, i.e., predicting the performance of a brand-new clothing probe with no available past observations. Our pipeline manufactures the missing past starting from a single, available image of the clothing probe. It starts by expanding textual tags associated with the image, querying related fashionable or unfashionable images uploaded on the web at a specific time in the past. A binary classifier is robustly trained on these web images by confident learning, to learn what was fashionable in the past and how much the probe image conforms to this notion of fashionability. This compliance produces the POtential Performance (POP) time series, indicating how performing the probe could have been if it were available earlier. POP proves to be highly predictive for the probe's future performance, ameliorating the sales forecasts of all state-of-the-art models on the recent VISUELLE fast-fashion dataset. We also show that POP reflects the ground-truth popularity of new styles (ensembles of clothing items) on the Fashion Forward benchmark, demonstrating that our webly-learned signal is a truthful expression of popularity, accessible by everyone and generalizable to any time of analysis. Forecasting code, data and the POP time series are available at: https://github.com/HumaticsLAB/POP-Mining-POtential-Performance
Online Metro Origin-Destination Prediction via Heterogeneous Information Aggregation
Aug 02, 2021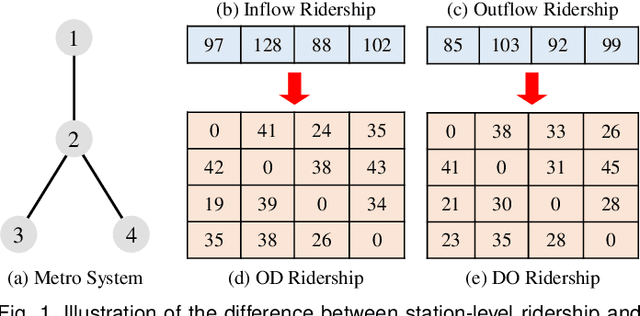
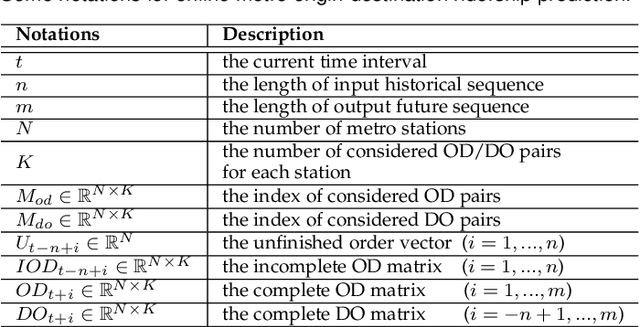
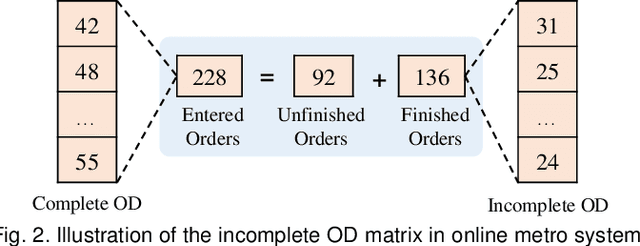
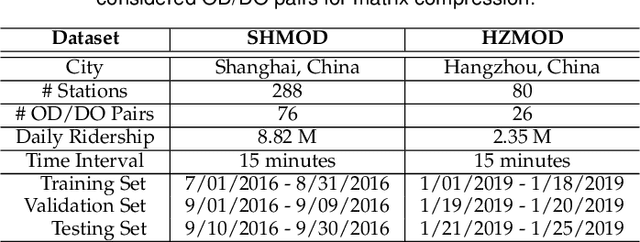
Metro origin-destination prediction is a crucial yet challenging time-series analysis task in intelligent transportation systems, which aims to accurately forecast two specific types of cross-station ridership, i.e., Origin-Destination (OD) one and Destination-Origin (DO) one. However, complete OD matrices of previous time intervals can not be obtained immediately in online metro systems, and conventional methods only used limited information to forecast the future OD and DO ridership separately. In this work, we proposed a novel neural network module termed Heterogeneous Information Aggregation Machine (HIAM), which fully exploits heterogeneous information of historical data (e.g., incomplete OD matrices, unfinished order vectors, and DO matrices) to jointly learn the evolutionary patterns of OD and DO ridership. Specifically, an OD modeling branch estimates the potential destinations of unfinished orders explicitly to complement the information of incomplete OD matrices, while a DO modeling branch takes DO matrices as input to capture the spatial-temporal distribution of DO ridership. Moreover, a Dual Information Transformer is introduced to propagate the mutual information among OD features and DO features for modeling the OD-DO causality and correlation. Based on the proposed HIAM, we develop a unified Seq2Seq network to forecast the future OD and DO ridership simultaneously. Extensive experiments conducted on two large-scale benchmarks demonstrate the effectiveness of our method for online metro origin-destination prediction.
An Empirical Evaluation of Time-Series Feature Sets
Oct 21, 2021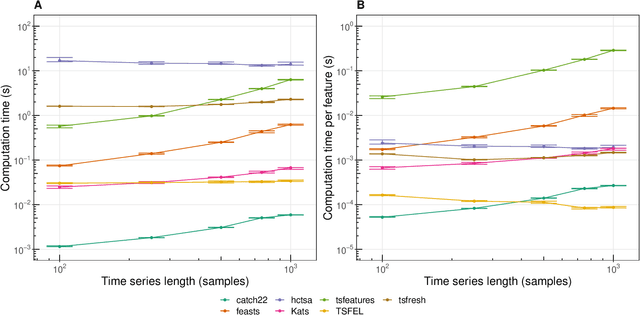
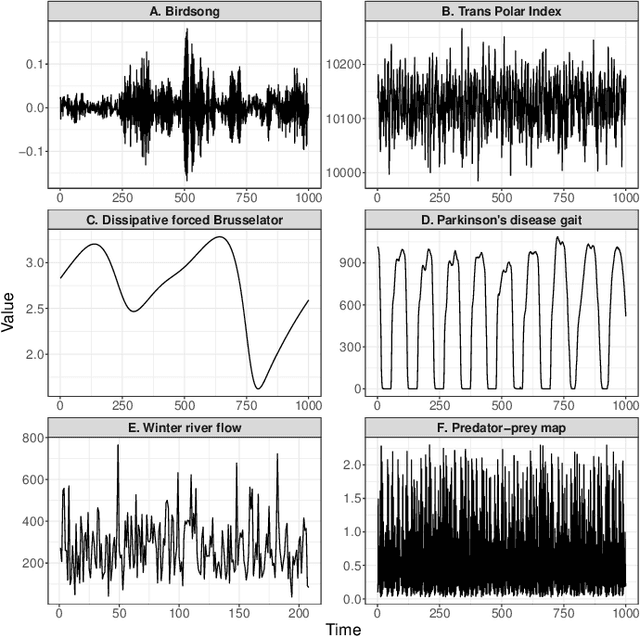
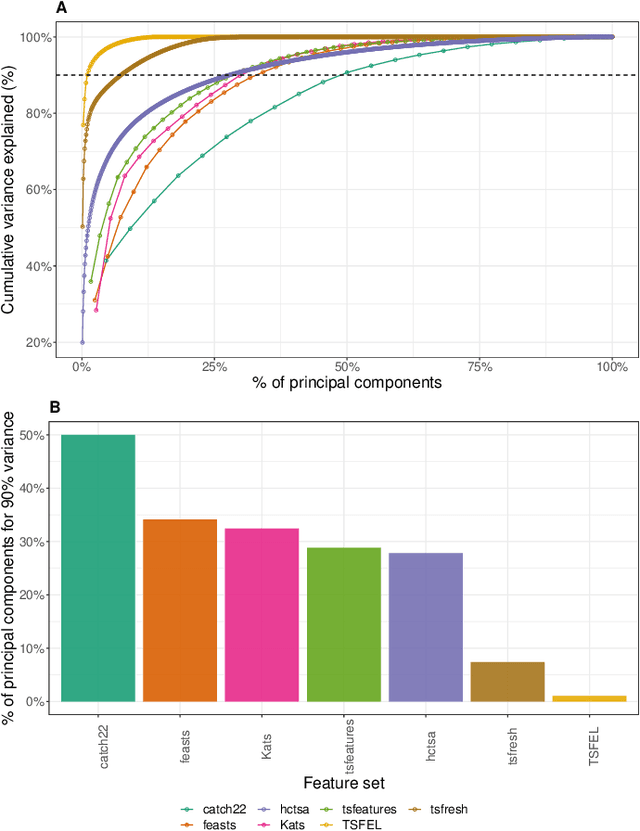
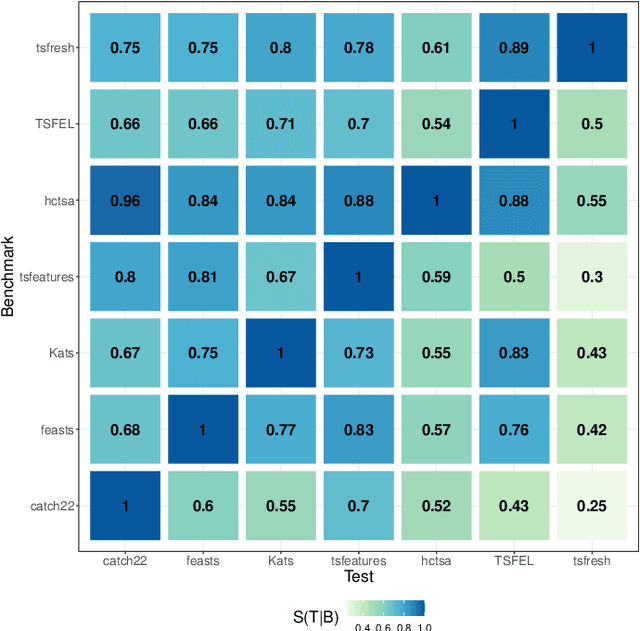
Solving time-series problems with features has been rising in popularity due to the availability of software for feature extraction. Feature-based time-series analysis can now be performed using many different feature sets, including hctsa (7730 features: Matlab), feasts (42 features: R), tsfeatures (63 features: R), Kats (40 features: Python), tsfresh (up to 1558 features: Python), TSFEL (390 features: Python), and the C-coded catch22 (22 features: Matlab, R, Python, and Julia). There is substantial overlap in the types of methods included in these sets (e.g., properties of the autocorrelation function and Fourier power spectrum), but they are yet to be systematically compared. Here we compare these seven sets on computational speed, assess the redundancy of features contained in each, and evaluate the overlap and redundancy between them. We take an empirical approach to feature similarity based on outputs across a diverse set of real-world and simulated time series. We find that feature sets vary across three orders of magnitude in their computation time per feature on a laptop for a 1000-sample series, from the fastest sets catch22 and TSFEL (~0.1ms per feature) to tsfeatures (~3s per feature). Using PCA to evaluate feature redundancy within each set, we find the highest within-set redundancy for TSFEL and tsfresh. For example, in TSFEL, 90% of the variance across 390 features can be captured with just four PCs. Finally, we introduce a metric for quantifying overlap between pairs of feature sets, which indicates substantial overlap. We found that the largest feature set, hctsa, is the most comprehensive, and that tsfresh is the most distinctive, due to its incorporation of many low-level Fourier coefficients. Our results provide empirical understanding of the differences between existing feature sets, information that can be used to better tailor feature sets to their applications.
High-Performance FPGA-based Accelerator for Bayesian Recurrent Neural Networks
Jun 04, 2021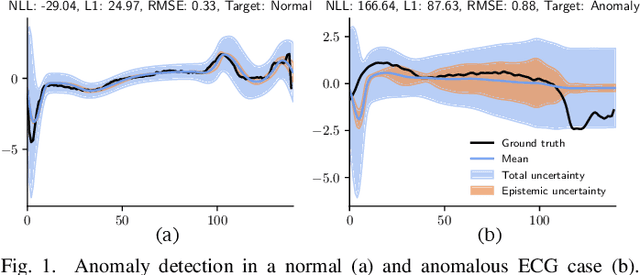
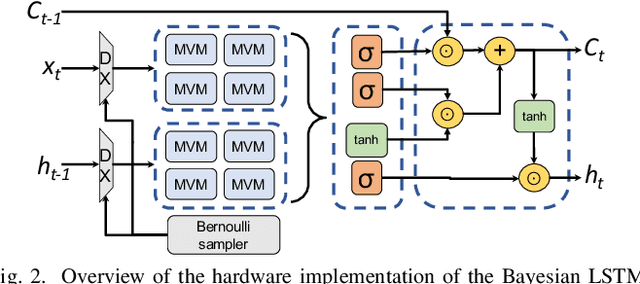
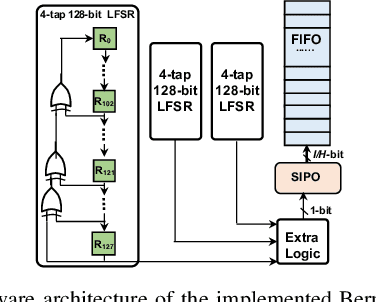
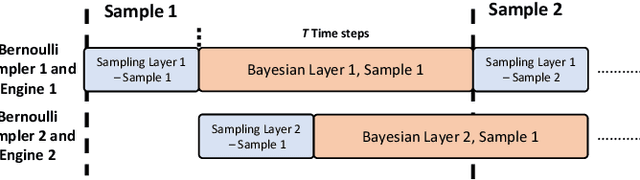
Neural networks have demonstrated their great performance in a wide range of tasks. Especially in time-series analysis, recurrent architectures based on long-short term memory (LSTM) cells have manifested excellent capability to model time dependencies in real-world data. However, standard recurrent architectures cannot estimate their uncertainty which is essential for safety-critical applications such as in medicine. In contrast, Bayesian recurrent neural networks (RNNs) are able to provide uncertainty estimation with improved accuracy. Nonetheless, Bayesian RNNs are computationally and memory demanding, which limits their practicality despite their advantages. To address this issue, we propose an FPGA-based hardware design to accelerate Bayesian LSTM-based RNNs. To further improve the overall algorithmic-hardware performance, a co-design framework is proposed to explore the most optimal algorithmic-hardware configurations for Bayesian RNNs. We conduct extensive experiments on health-related tasks to demonstrate the improvement of our design and the effectiveness of our framework. Compared with GPU implementation, our FPGA-based design can achieve up to 10 times speedup with nearly 106 times higher energy efficiency. To the best of our knowledge, this is the first work targeting the acceleration of Bayesian RNNs on FPGAs.