 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time Series Analysis": models, code, and papers
Time to Focus: A Comprehensive Benchmark Using Time Series Attribution Methods
Feb 08, 2022
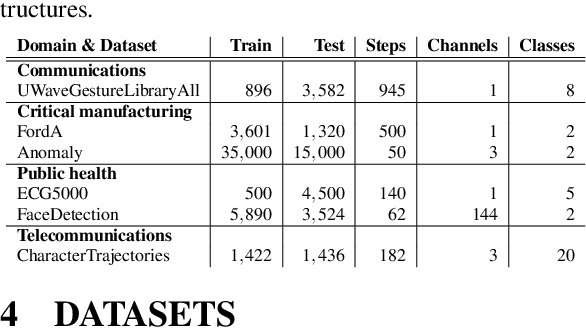
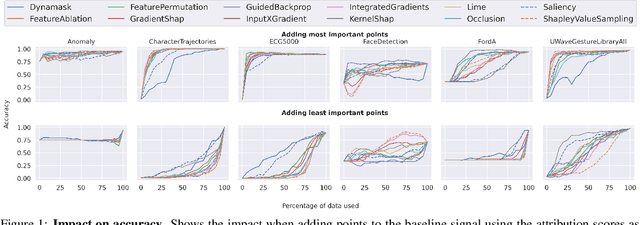
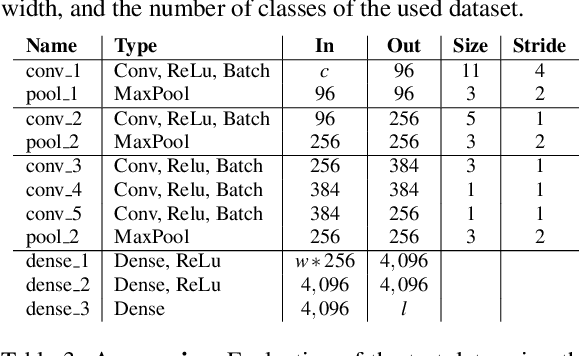
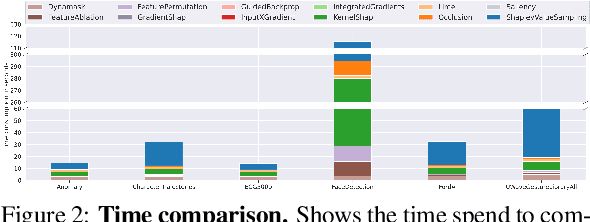
In the last decade neural network have made huge impact both in industry and research due to their ability to extract meaningful features from imprecise or complex data, and by achieving super human performance in several domains. However, due to the lack of transparency the use of these networks is hampered in the areas with safety critical areas. In safety-critical areas, this is necessary by law. Recently several methods have been proposed to uncover this black box by providing interpreation of predictions made by these models. The paper focuses on time series analysis and benchmark several state-of-the-art attribution methods which compute explanations for convolutional classifiers. The presented experiments involve gradient-based and perturbation-based attribution methods. A detailed analysis shows that perturbation-based approaches are superior concerning the Sensitivity and occlusion game. These methods tend to produce explanations with higher continuity. Contrarily, the gradient-based techniques are superb in runtime and Infidelity. In addition, a validation the dependence of the methods on the trained model, feasible application domains, and individual characteristics is attached. The findings accentuate that choosing the best-suited attribution method is strongly correlated with the desired use case. Neither category of attribution methods nor a single approach has shown outstanding performance across all aspects.
Time Series Analysis of Electricity Price and Demand to Find Cyber-attacks using Stationary Analysis
Jul 23, 2019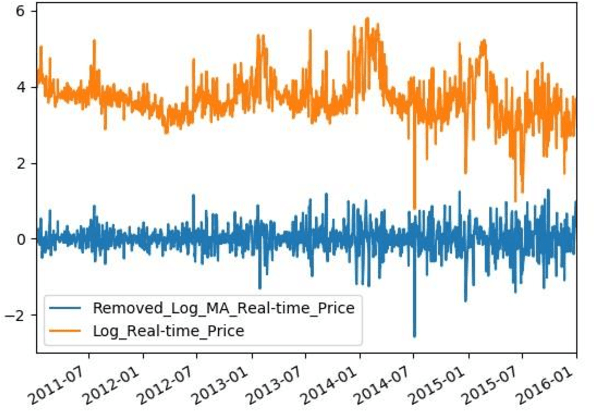
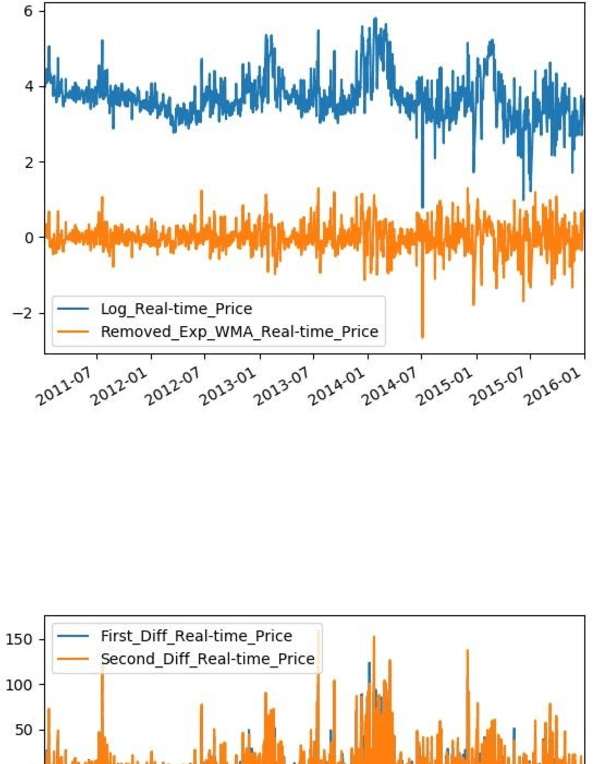
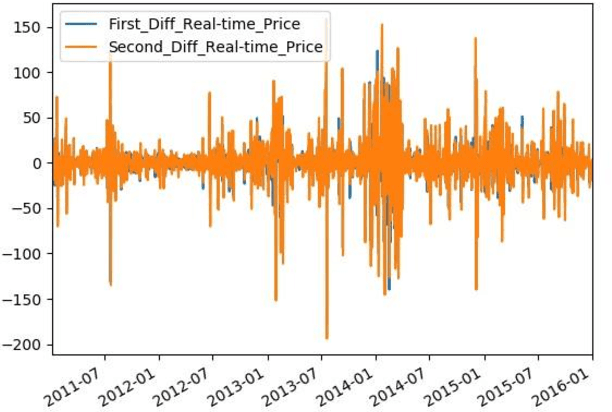
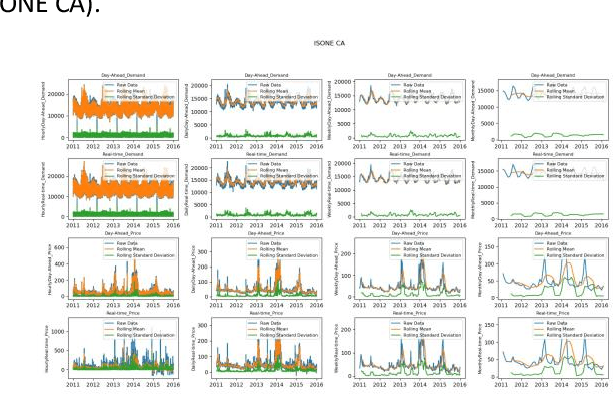
With developing of computation tools in the last years, data analysis methods to find insightful information are becoming more common among industries and researchers. This paper is the first part of the times series analysis of New England electricity price and demand to find anomaly in the data. In this paper time-series stationary criteria to prepare data for further times-series related analysis is investigated. Three main analysis are conducted in this paper, including moving average, moving standard deviation and augmented Dickey-Fuller test. The data used in this paper is New England big data from 9 different operational zones. For each zone, 4 different variables including day-ahead (DA) electricity demand, price and real-time (RT) electricity demand price are considered.
Disentangling modes with crossover instantaneous frequencies by synchrosqueezed chirplet transforms, from theory to application
Dec 03, 2021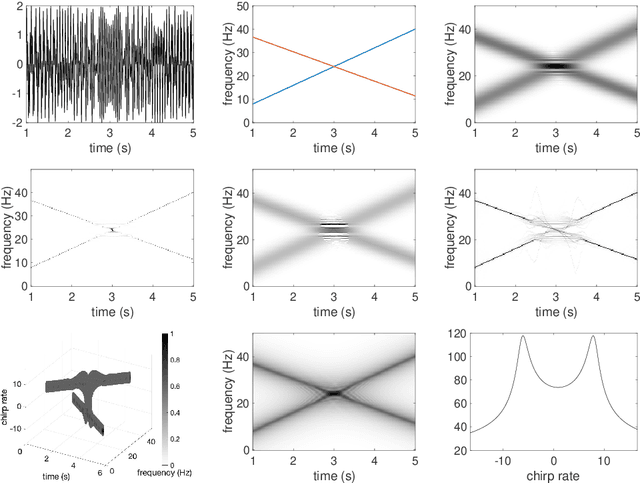
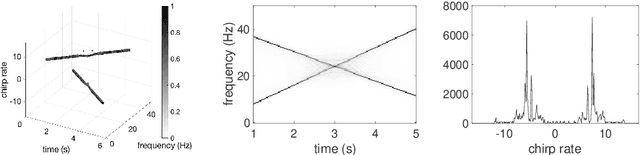
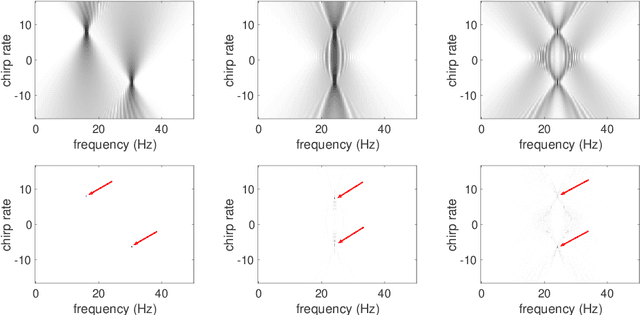
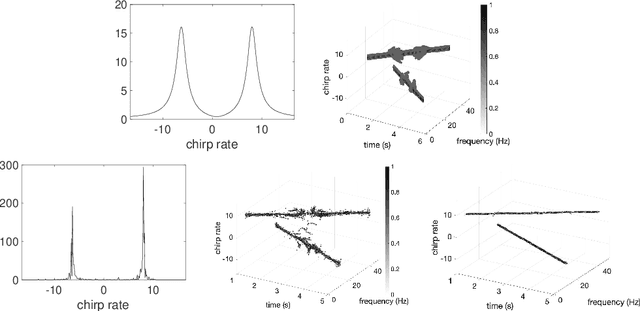
Analysis of signals with oscillatory modes with crossover instantaneous frequencies is a challenging problem in time series analysis. One way to handle this problem is lifting the 2-dimensional time-frequency representation to a 3-dimensional representation, called time-frequency-chirp rate (TFC) representation, by adding one extra chirp rate parameter so that crossover frequencies are disentangles in higher dimension. The chirplet transform is an algorithm for this lifting idea. However, in practice we found that it has a stronger "blurring" effect in the chirp rate axis, which limits its application in real world data. Moreover, to our knowledge, we have limited mathematical understanding of the chirplet transform in the literature. Motivated by real world data challenges, in this paper, we propose the synchrosqueezed chirplet transform (SCT) that gives a concentrated TFC representation that the contrast is enhanced so that one can distinguish different modes even with crossover instantaneous frequencies. We also analyze chirplet transform and provide theoretical guarantee of SCT.
A Synthetic Dataset for 5G UAV Attacks Based on Observable Network Parameters
Nov 05, 2022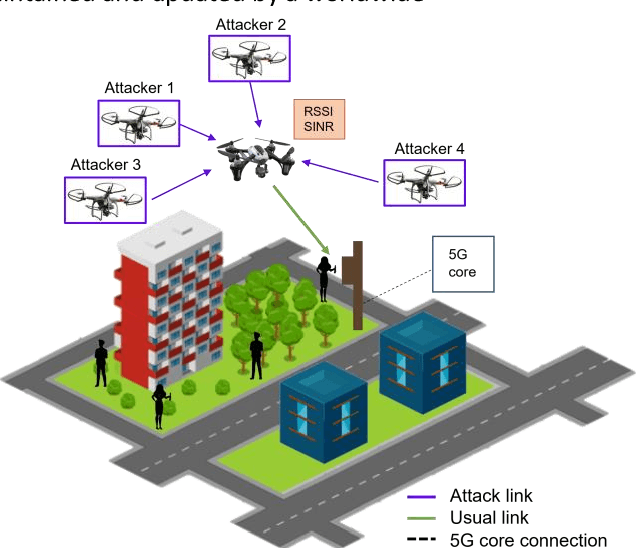

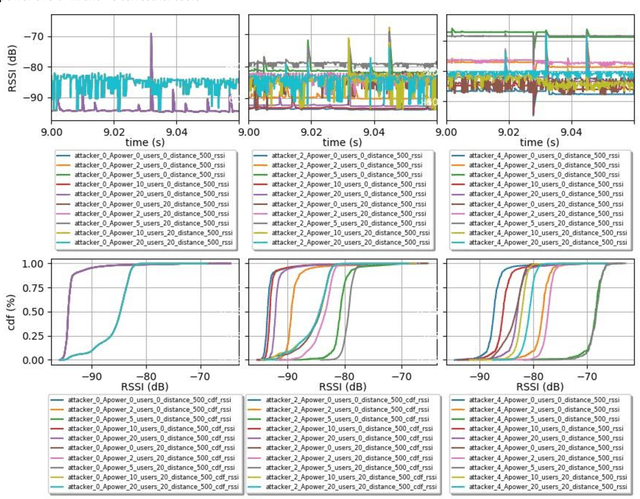
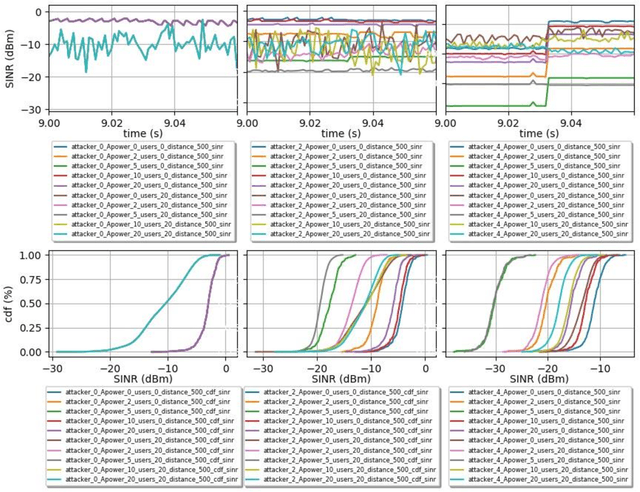
Synthetic datasets are beneficial for machine learning researchers due to the possibility of experimenting with new strategies and algorithms in the training and testing phases. These datasets can easily include more scenarios that might be costly to research with real data or can complement and, in some cases, replace real data measurements, depending on the quality of the synthetic data. They can also solve the unbalanced data problem, avoid overfitting, and can be used in training while testing can be done with real data. In this paper, we present, to the best of our knowledge, the first synthetic dataset for Unmanned Aerial Vehicle (UAV) attacks in 5G and beyond networks based on the following key observable network parameters that indicate power levels: the Received Signal Strength Indicator (RSSI) and the Signal to Interference-plus-Noise Ratio (SINR). The main objective of this data is to enable deep network development for UAV communication security. Especially, for algorithm development or the analysis of time-series data applied to UAV attack recognition. Our proposed dataset provides insights into network functionality when static or moving UAV attackers target authenticated UAVs in an urban environment. The dataset also considers the presence and absence of authenticated terrestrial users in the network, which may decrease the deep networks ability to identify attacks. Furthermore, the data provides deeper comprehension of the metrics available in the 5G physical and MAC layers for machine learning and statistics research. The dataset will available at link archive-beta.ics.uci.edu
Detecting Attacks on IoT Devices using Featureless 1D-CNN
Sep 09, 2021
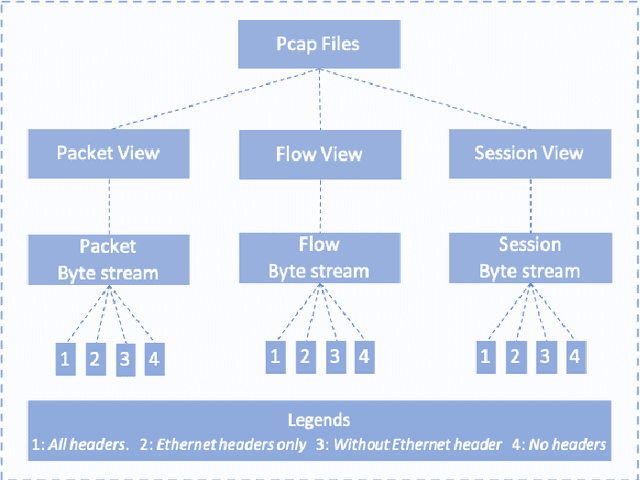
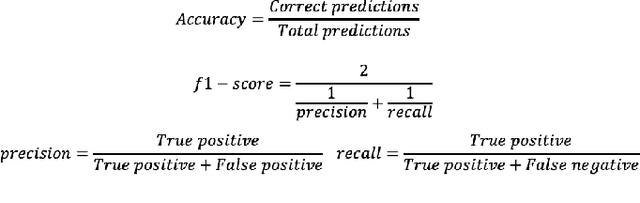
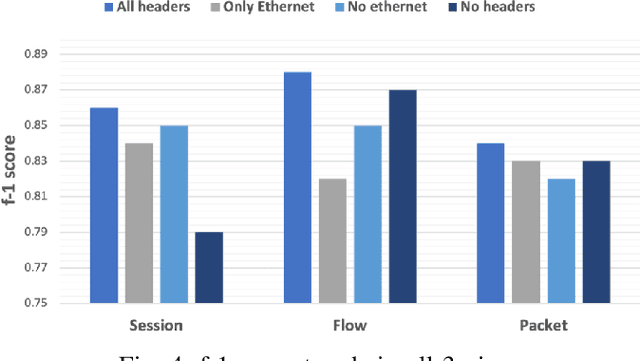
The generalization of deep learning has helped us, in the past, address challenges such as malware identification and anomaly detection in the network security domain. However, as effective as it is, scarcity of memory and processing power makes it difficult to perform these tasks in Internet of Things (IoT) devices. This research finds an easy way out of this bottleneck by depreciating the need for feature engineering and subsequent processing in machine learning techniques. In this study, we introduce a Featureless machine learning process to perform anomaly detection. It uses unprocessed byte streams of packets as training data. Featureless machine learning enables a low cost and low memory time-series analysis of network traffic. It benefits from eliminating the significant investment in subject matter experts and the time required for feature engineering.
Randomized Signature Layers for Signal Extraction in Time Series Data
Jan 02, 2022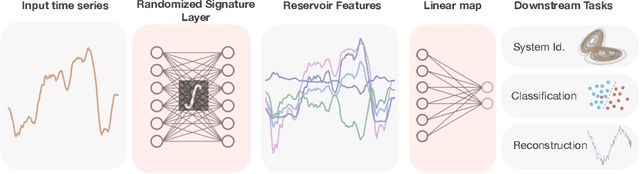

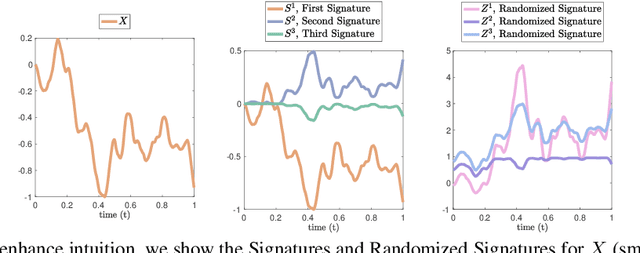
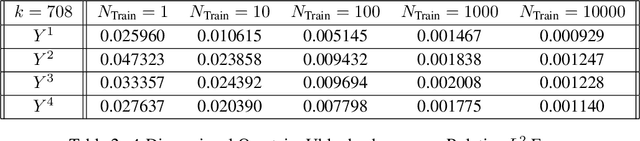
Time series analysis is a widespread task in Natural Sciences, Social Sciences, and Engineering. A fundamental problem is finding an expressive yet efficient-to-compute representation of the input time series to use as a starting point to perform arbitrary downstream tasks. In this paper, we build upon recent works that use the Signature of a path as a feature map and investigate a computationally efficient technique to approximate these features based on linear random projections. We present several theoretical results to justify our approach and empirically validate that our random projections can effectively retrieve the underlying Signature of a path. We show the surprising performance of the proposed random features on several tasks, including (1) mapping the controls of stochastic differential equations to the corresponding solutions and (2) using the Randomized Signatures as time series representation for classification tasks. When compared to corresponding truncated Signature approaches, our Randomizes Signatures are more computationally efficient in high dimensions and often lead to better accuracy and faster training. Besides providing a new tool to extract Signatures and further validating the high level of expressiveness of such features, we believe our results provide interesting conceptual links between several existing research areas, suggesting new intriguing directions for future investigations.
A Time Series Analysis of Emotional Loading in Central Bank Statements
Nov 26, 2019
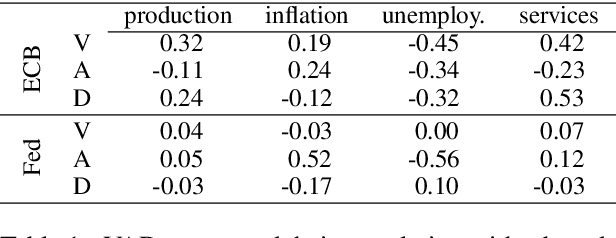
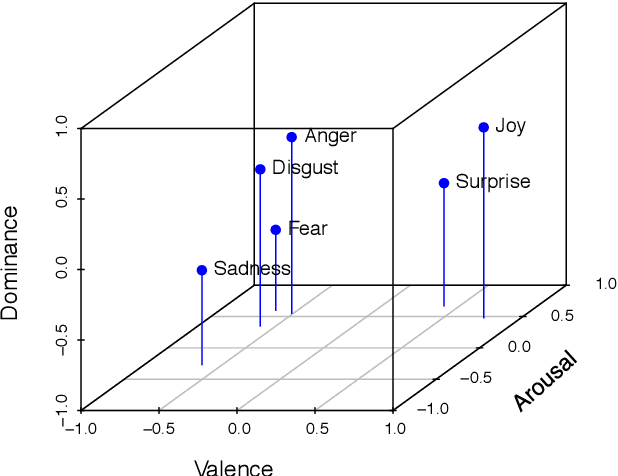
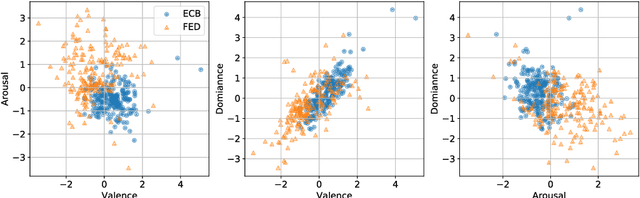
We examine the affective content of central bank press statements using emotion analysis. Our focus is on two major international players, the European Central Bank (ECB) and the US Federal Reserve Bank (Fed), covering a time span from 1998 through 2019. We reveal characteristic patterns in the emotional dimensions of valence, arousal, and dominance and find---despite the commonly established attitude that emotional wording in central bank communication should be avoided---a correlation between the state of the economy and particularly the dominance dimension in the press releases under scrutiny and, overall, an impact of the president in office.
* Published at ECONLP 2019
Scheduling Planting Time Through Developing an Optimization Model and Analysis of Time Series Growing Degree Units
Jul 02, 2022
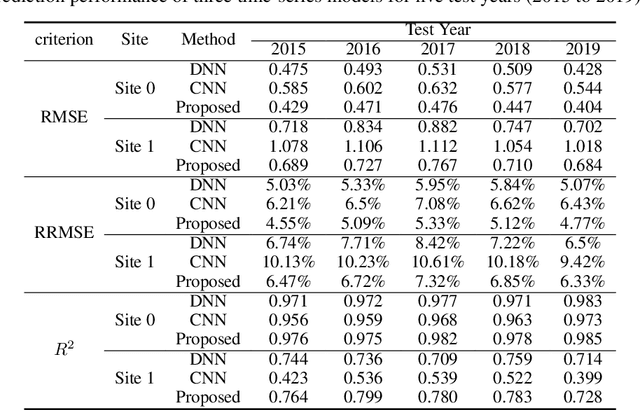
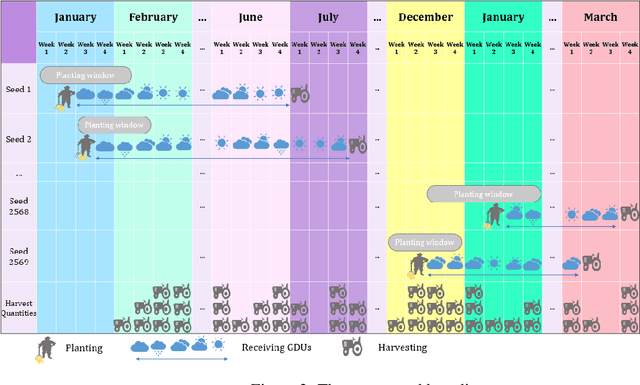
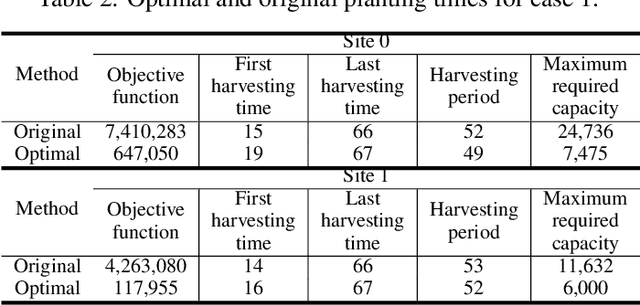
Producing higher-quality crops within shortened breeding cycles ensures global food availability and security, but this improvement intensifies logistical and productivity challenges for seed industries in the year-round breeding process due to the storage limitations. In the 2021 Syngenta crop challenge in analytics, Syngenta raised the problem to design an optimization model for the planting time scheduling in the 2020 year-round breeding process so that there is a consistent harvest quantity each week. They released a dataset that contained 2569 seed populations with their planting windows, required growing degree units for harvesting, and their harvest quantities at two sites. To address this challenge, we developed a new framework that consists of a weather time series model and an optimization model to schedule the planting time. A deep recurrent neural network was designed to predict the weather into the future, and a Gaussian process model on top of the time-series model was developed to model the uncertainty of forecasted weather. The proposed optimization models also scheduled the seed population's planting time at the fewest number of weeks with a more consistent weekly harvest quantity. Using the proposed optimization models can decrease the required capacity by 69% at site 0 and up to 51% at site 1 compared to the original planting time.
Evaluating Impact of Social Media Posts by Executives on Stock Prices
Nov 01, 2022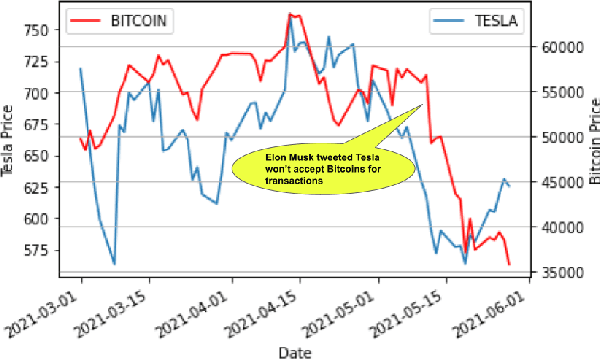
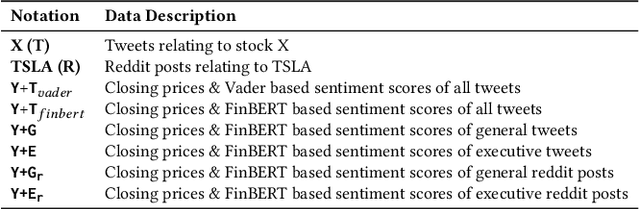
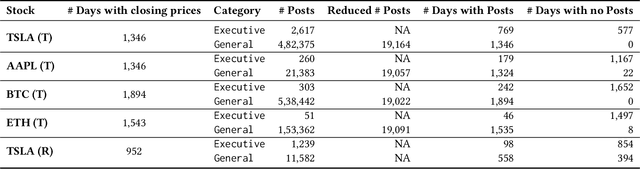
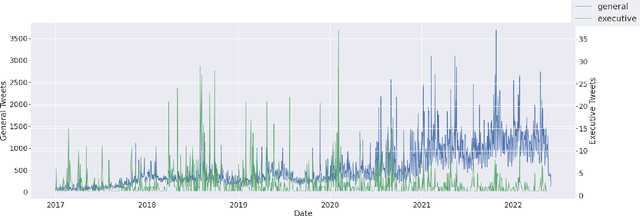
Predicting stock market movements has always been of great interest to investors and an active area of research. Research has proven that popularity of products is highly influenced by what people talk about. Social media like Twitter, Reddit have become hotspots of such influences. This paper investigates the impact of social media posts on close price prediction of stocks using Twitter and Reddit posts. Our objective is to integrate sentiment of social media data with historical stock data and study its effect on closing prices using time series models. We carried out rigorous experiments and deep analysis using multiple deep learning based models on different datasets to study the influence of posts by executives and general people on the close price. Experimental results on multiple stocks (Apple and Tesla) and decentralised currencies (Bitcoin and Ethereum) consistently show improvements in prediction on including social media data and greater improvements on including executive posts.
Privacy Meets Explainability: A Comprehensive Impact Benchmark
Nov 08, 2022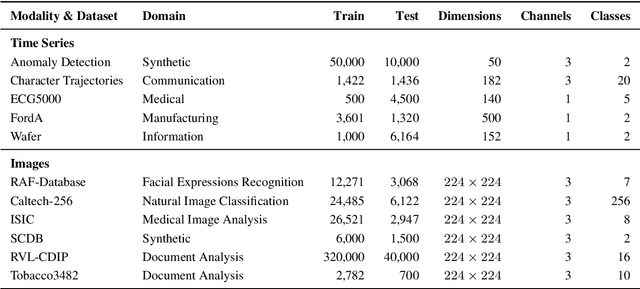
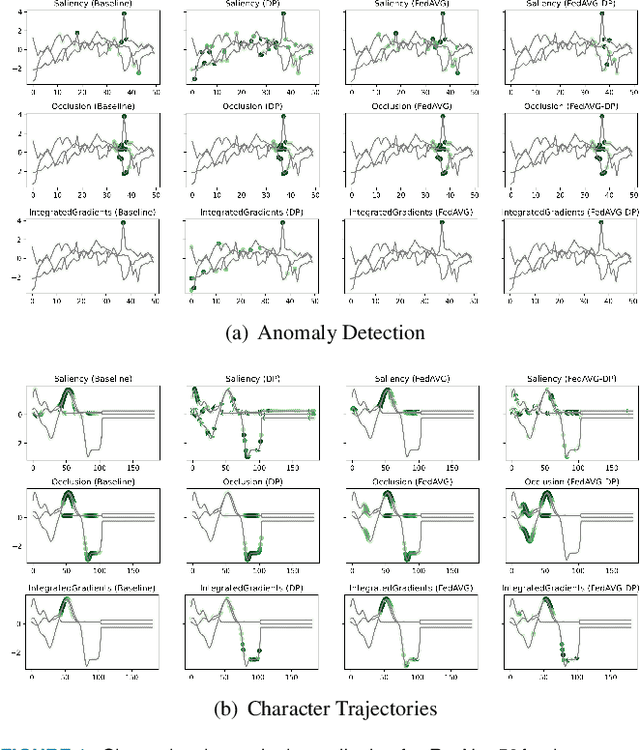
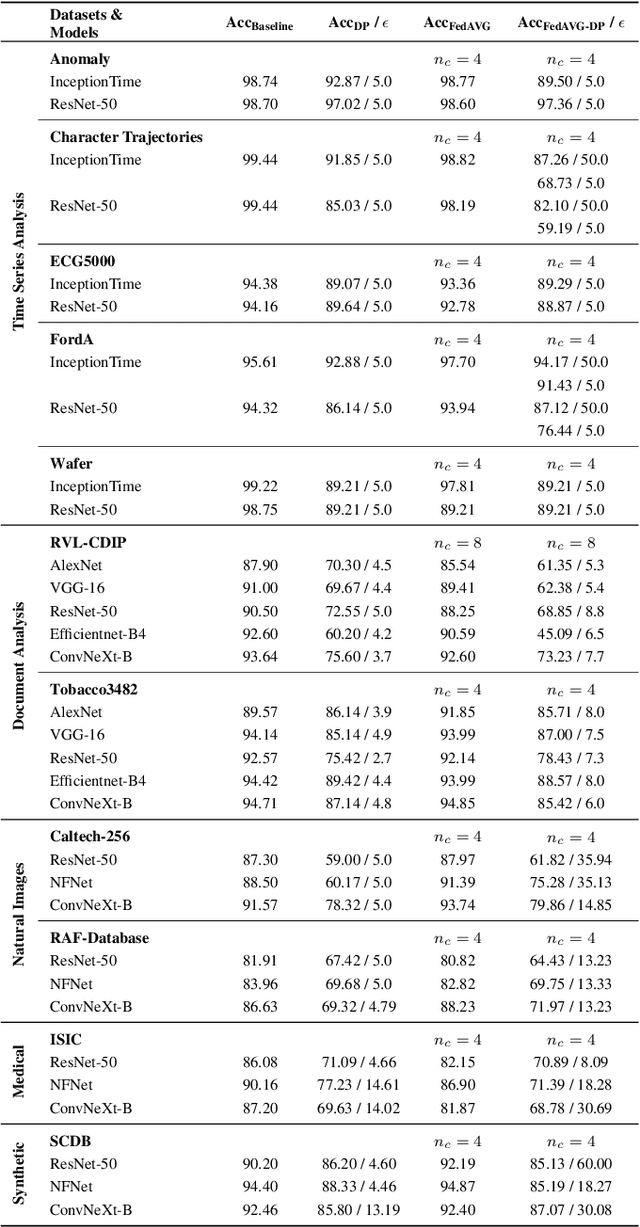

Since the mid-10s, the era of Deep Learning (DL) has continued to this day, bringing forth new superlatives and innovations each year. Nevertheless, the speed with which these innovations translate into real applications lags behind this fast pace. Safety-critical applications, in particular, underlie strict regulatory and ethical requirements which need to be taken care of and are still active areas of debate. eXplainable AI (XAI) and privacy-preserving machine learning (PPML) are both crucial research fields, aiming at mitigating some of the drawbacks of prevailing data-hungry black-box models in DL. Despite brisk research activity in the respective fields, no attention has yet been paid to their interaction. This work is the first to investigate the impact of private learning techniques on generated explanations for DL-based models. In an extensive experimental analysis covering various image and time series datasets from multiple domains, as well as varying privacy techniques, XAI methods, and model architectures, the effects of private training on generated explanations are studied. The findings suggest non-negligible changes in explanations through the introduction of privacy. Apart from reporting individual effects of PPML on XAI, the paper gives clear recommendations for the choice of techniques in real applications. By unveiling the interdependencies of these pivotal technologies, this work is a first step towards overcoming the remaining hurdles for practically applicable AI in safety-critical domains.