 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Meta learning with language models: Challenges and opportunities in the classification of imbalanced text
Oct 23, 2023
Detecting out of policy speech (OOPS) content is important but difficult. While machine learning is a powerful tool to tackle this challenging task, it is hard to break the performance ceiling due to factors like quantity and quality limitations on training data and inconsistencies in OOPS definition and data labeling. To realize the full potential of available limited resources, we propose a meta learning technique (MLT) that combines individual models built with different text representations. We analytically show that the resulting technique is numerically stable and produces reasonable combining weights. We combine the MLT with a threshold-moving (TM) technique to further improve the performance of the combined predictor on highly-imbalanced in-distribution and out-of-distribution datasets. We also provide computational results to show the statistically significant advantages of the proposed MLT approach. All authors contributed equally to this work.
Large Language Models for Failure Mode Classification: An Investigation
Sep 15, 2023In this paper we present the first investigation into the effectiveness of Large Language Models (LLMs) for Failure Mode Classification (FMC). FMC, the task of automatically labelling an observation with a corresponding failure mode code, is a critical task in the maintenance domain as it reduces the need for reliability engineers to spend their time manually analysing work orders. We detail our approach to prompt engineering to enable an LLM to predict the failure mode of a given observation using a restricted code list. We demonstrate that the performance of a GPT-3.5 model (F1=0.80) fine-tuned on annotated data is a significant improvement over a currently available text classification model (F1=0.60) trained on the same annotated data set. The fine-tuned model also outperforms the out-of-the box GPT-3.5 (F1=0.46). This investigation reinforces the need for high quality fine-tuning data sets for domain-specific tasks using LLMs.
When Automated Assessment Meets Automated Content Generation: Examining Text Quality in the Era of GPTs
Sep 25, 2023
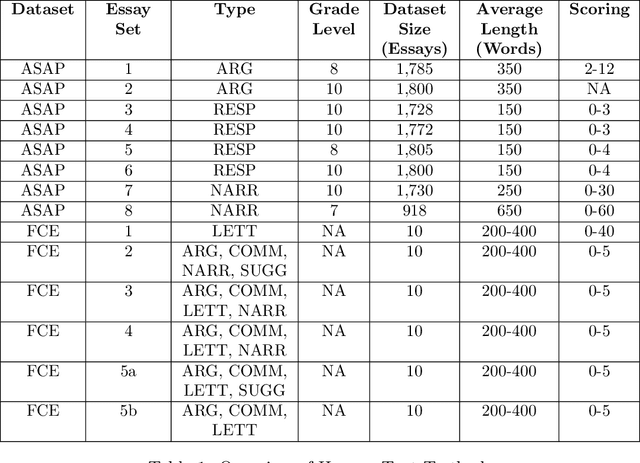
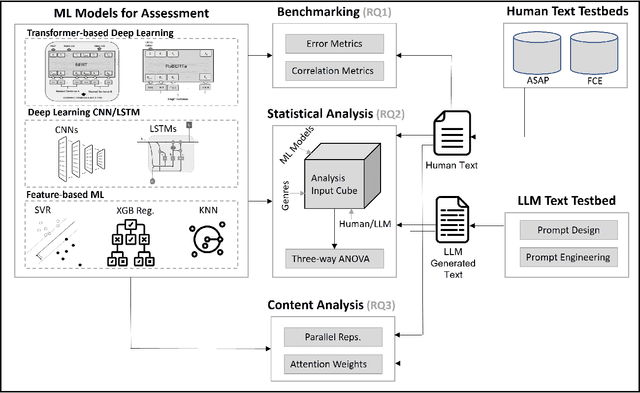
The use of machine learning (ML) models to assess and score textual data has become increasingly pervasive in an array of contexts including natural language processing, information retrieval, search and recommendation, and credibility assessment of online content. A significant disruption at the intersection of ML and text are text-generating large-language models such as generative pre-trained transformers (GPTs). We empirically assess the differences in how ML-based scoring models trained on human content assess the quality of content generated by humans versus GPTs. To do so, we propose an analysis framework that encompasses essay scoring ML-models, human and ML-generated essays, and a statistical model that parsimoniously considers the impact of type of respondent, prompt genre, and the ML model used for assessment model. A rich testbed is utilized that encompasses 18,460 human-generated and GPT-based essays. Results of our benchmark analysis reveal that transformer pretrained language models (PLMs) more accurately score human essay quality as compared to CNN/RNN and feature-based ML methods. Interestingly, we find that the transformer PLMs tend to score GPT-generated text 10-15\% higher on average, relative to human-authored documents. Conversely, traditional deep learning and feature-based ML models score human text considerably higher. Further analysis reveals that although the transformer PLMs are exclusively fine-tuned on human text, they more prominently attend to certain tokens appearing only in GPT-generated text, possibly due to familiarity/overlap in pre-training. Our framework and results have implications for text classification settings where automated scoring of text is likely to be disrupted by generative AI.
Fabricator: An Open Source Toolkit for Generating Labeled Training Data with Teacher LLMs
Sep 18, 2023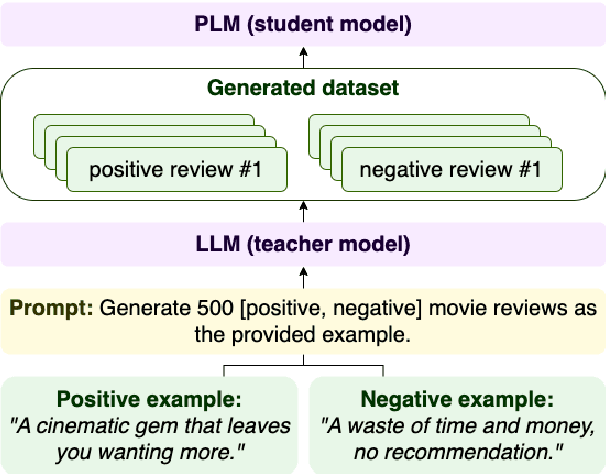
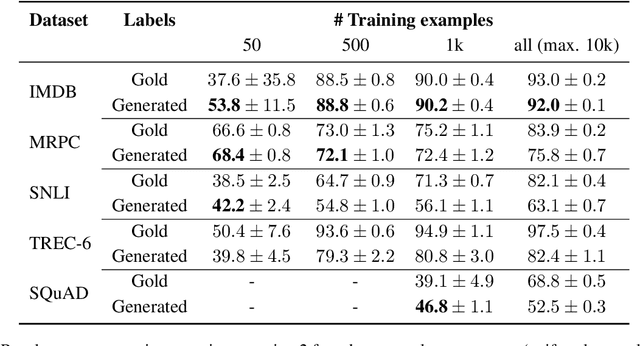
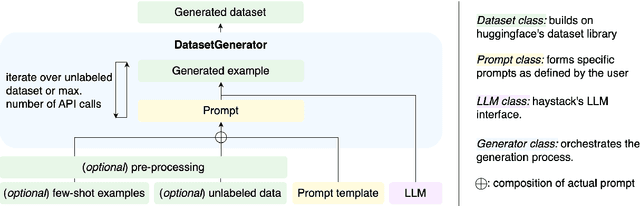

Most NLP tasks are modeled as supervised learning and thus require labeled training data to train effective models. However, manually producing such data at sufficient quality and quantity is known to be costly and time-intensive. Current research addresses this bottleneck by exploring a novel paradigm called zero-shot learning via dataset generation. Here, a powerful LLM is prompted with a task description to generate labeled data that can be used to train a downstream NLP model. For instance, an LLM might be prompted to "generate 500 movie reviews with positive overall sentiment, and another 500 with negative sentiment." The generated data could then be used to train a binary sentiment classifier, effectively leveraging an LLM as a teacher to a smaller student model. With this demo, we introduce Fabricator, an open-source Python toolkit for dataset generation. Fabricator implements common dataset generation workflows, supports a wide range of downstream NLP tasks (such as text classification, question answering, and entity recognition), and is integrated with well-known libraries to facilitate quick experimentation. With Fabricator, we aim to support researchers in conducting reproducible dataset generation experiments using LLMs and help practitioners apply this approach to train models for downstream tasks.
Latent Space Translation via Semantic Alignment
Nov 01, 2023While different neural models often exhibit latent spaces that are alike when exposed to semantically related data, this intrinsic similarity is not always immediately discernible. Towards a better understanding of this phenomenon, our work shows how representations learned from these neural modules can be translated between different pre-trained networks via simpler transformations than previously thought. An advantage of this approach is the ability to estimate these transformations using standard, well-understood algebraic procedures that have closed-form solutions. Our method directly estimates a transformation between two given latent spaces, thereby enabling effective stitching of encoders and decoders without additional training. We extensively validate the adaptability of this translation procedure in different experimental settings: across various trainings, domains, architectures (e.g., ResNet, CNN, ViT), and in multiple downstream tasks (classification, reconstruction). Notably, we show how it is possible to zero-shot stitch text encoders and vision decoders, or vice-versa, yielding surprisingly good classification performance in this multimodal setting.
A Survey on Recent Named Entity Recognition and Relation Classification Methods with Focus on Few-Shot Learning Approaches
Oct 29, 2023Named entity recognition and relation classification are key stages for extracting information from unstructured text. Several natural language processing applications utilize the two tasks, such as information retrieval, knowledge graph construction and completion, question answering and other domain-specific applications, such as biomedical data mining. We present a survey of recent approaches in the two tasks with focus on few-shot learning approaches. Our work compares the main approaches followed in the two paradigms. Additionally, we report the latest metric scores in the two tasks with a structured analysis that considers the results in the few-shot learning scope.
Food Classification using Joint Representation of Visual and Textual Data
Aug 03, 2023Food classification is an important task in health care. In this work, we propose a multimodal classification framework that uses the modified version of EfficientNet with the Mish activation function for image classification, and the traditional BERT transformer-based network is used for text classification. The proposed network and the other state-of-the-art methods are evaluated on a large open-source dataset, UPMC Food-101. The experimental results show that the proposed network outperforms the other methods, a significant difference of 11.57% and 6.34% in accuracy is observed for image and text classification, respectively, when compared with the second-best performing method. We also compared the performance in terms of accuracy, precision, and recall for text classification using both machine learning and deep learning-based models. The comparative analysis from the prediction results of both images and text demonstrated the efficiency and robustness of the proposed approach.
Fuzzy Fingerprinting Transformer Language-Models for Emotion Recognition in Conversations
Sep 08, 2023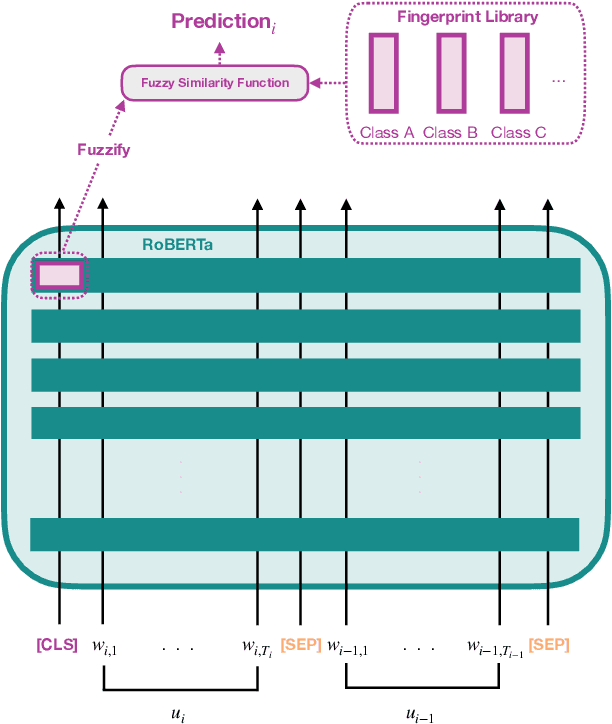
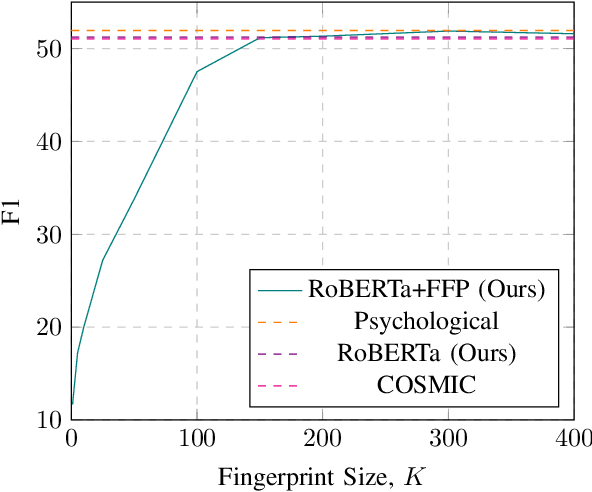
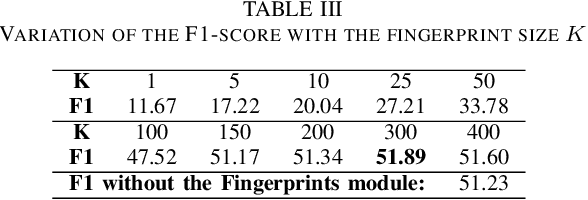
Fuzzy Fingerprints have been successfully used as an interpretable text classification technique, but, like most other techniques, have been largely surpassed in performance by Large Pre-trained Language Models, such as BERT or RoBERTa. These models deliver state-of-the-art results in several Natural Language Processing tasks, namely Emotion Recognition in Conversations (ERC), but suffer from the lack of interpretability and explainability. In this paper, we propose to combine the two approaches to perform ERC, as a means to obtain simpler and more interpretable Large Language Models-based classifiers. We propose to feed the utterances and their previous conversational turns to a pre-trained RoBERTa, obtaining contextual embedding utterance representations, that are then supplied to an adapted Fuzzy Fingerprint classification module. We validate our approach on the widely used DailyDialog ERC benchmark dataset, in which we obtain state-of-the-art level results using a much lighter model.
Ambiguity-Aware In-Context Learning with Large Language Models
Sep 14, 2023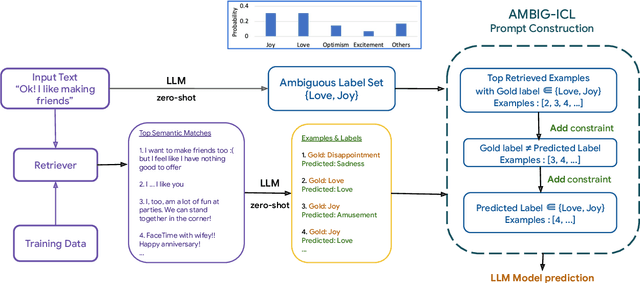
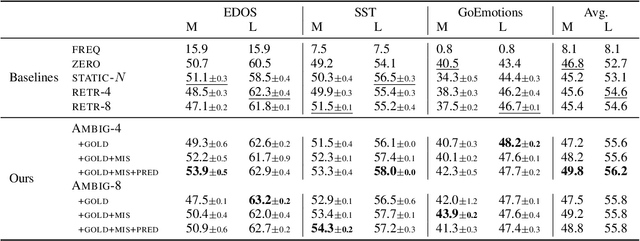
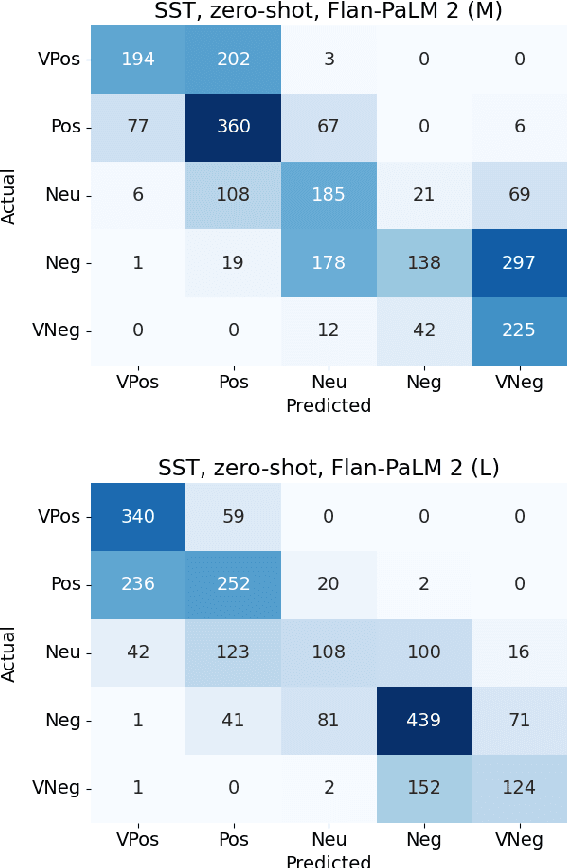
In-context learning (ICL) i.e. showing LLMs only a few task-specific demonstrations has led to downstream gains with no task-specific fine-tuning required. However, LLMs are sensitive to the choice of prompts, and therefore a crucial research question is how to select good demonstrations for ICL. One effective strategy is leveraging semantic similarity between the ICL demonstrations and test inputs by using a text retriever, which however is sub-optimal as that does not consider the LLM's existing knowledge about that task. From prior work (Min et al., 2022), we already know that labels paired with the demonstrations bias the model predictions. This leads us to our hypothesis whether considering LLM's existing knowledge about the task, especially with respect to the output label space can help in a better demonstration selection strategy. Through extensive experimentation on three text classification tasks, we find that it is beneficial to not only choose semantically similar ICL demonstrations but also to choose those demonstrations that help resolve the inherent label ambiguity surrounding the test example. Interestingly, we find that including demonstrations that the LLM previously mis-classified and also fall on the test example's decision boundary, brings the most performance gain.
Performance of Data Augmentation Methods for Brazilian Portuguese Text Classification
Apr 05, 2023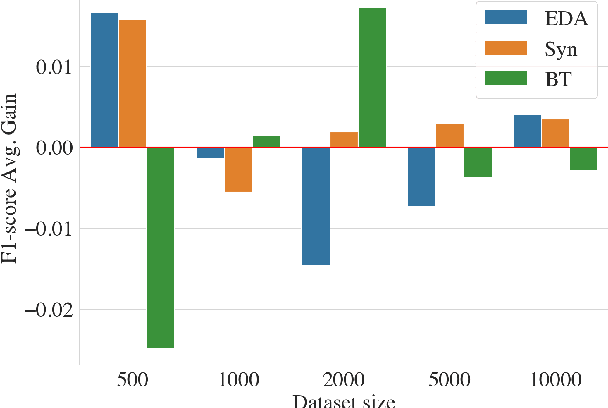
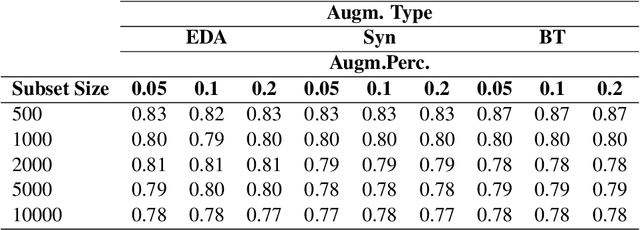
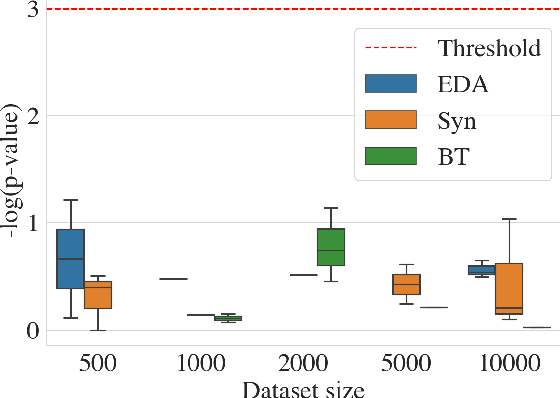
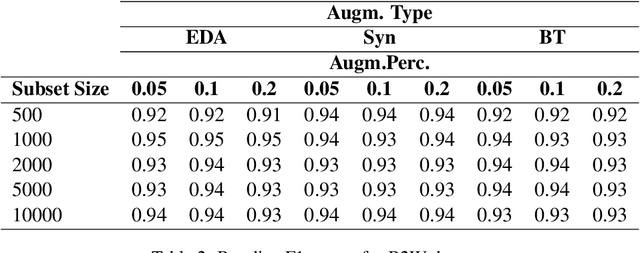
Improving machine learning performance while increasing model generalization has been a constantly pursued goal by AI researchers. Data augmentation techniques are often used towards achieving this target, and most of its evaluation is made using English corpora. In this work, we took advantage of different existing data augmentation methods to analyze their performances applied to text classification problems using Brazilian Portuguese corpora. As a result, our analysis shows some putative improvements in using some of these techniques; however, it also suggests further exploitation of language bias and non-English text data scarcity.