 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Enhancing Black-Box Few-Shot Text Classification with Prompt-Based Data Augmentation
May 23, 2023

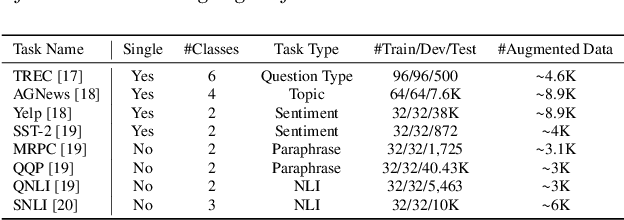

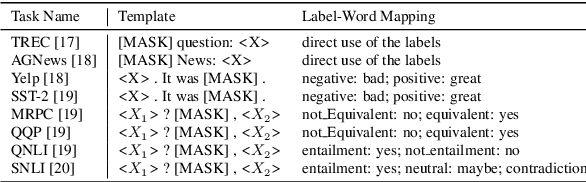
Training or finetuning large-scale language models (LLMs) such as GPT-3 requires substantial computation resources, motivating recent efforts to explore parameter-efficient adaptation to downstream tasks. One practical area of research is to treat these models as black boxes and interact with them through their inference APIs. In this paper, we investigate how to optimize few-shot text classification without accessing the gradients of the LLMs. To achieve this, we treat the black-box model as a feature extractor and train a classifier with the augmented text data. Data augmentation is performed using prompt-based finetuning on an auxiliary language model with a much smaller parameter size than the black-box model. Through extensive experiments on eight text classification datasets, we show that our approach, dubbed BT-Classifier, significantly outperforms state-of-the-art black-box few-shot learners and performs on par with methods that rely on full-model tuning.
SCAT: Robust Self-supervised Contrastive Learning via Adversarial Training for Text Classification
Jul 04, 2023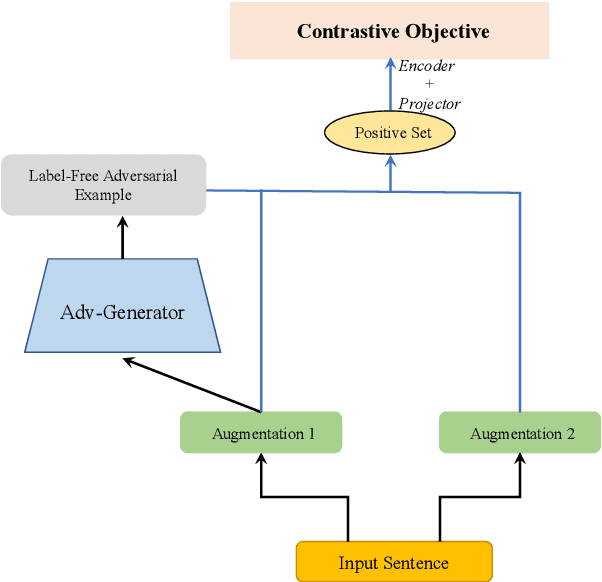
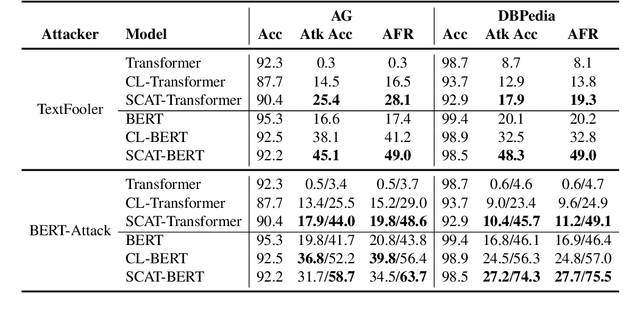
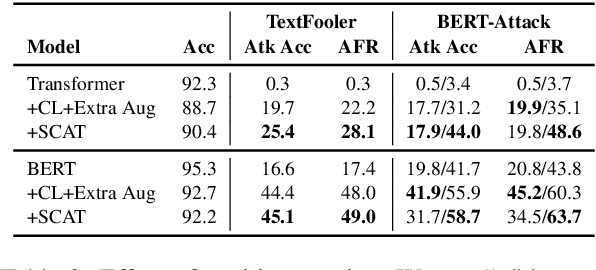
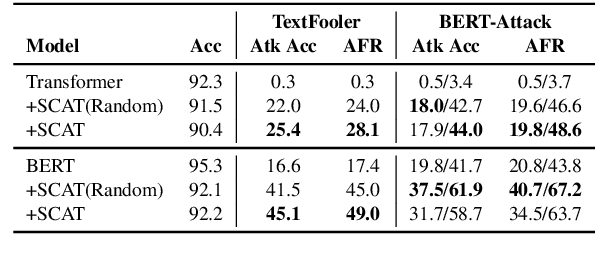
Despite their promising performance across various natural language processing (NLP) tasks, current NLP systems are vulnerable to textual adversarial attacks. To defend against these attacks, most existing methods apply adversarial training by incorporating adversarial examples. However, these methods have to rely on ground-truth labels to generate adversarial examples, rendering it impractical for large-scale model pre-training which is commonly used nowadays for NLP and many other tasks. In this paper, we propose a novel learning framework called SCAT (Self-supervised Contrastive Learning via Adversarial Training), which can learn robust representations without requiring labeled data. Specifically, SCAT modifies random augmentations of the data in a fully labelfree manner to generate adversarial examples. Adversarial training is achieved by minimizing the contrastive loss between the augmentations and their adversarial counterparts. We evaluate SCAT on two text classification datasets using two state-of-the-art attack schemes proposed recently. Our results show that SCAT can not only train robust language models from scratch, but it can also significantly improve the robustness of existing pre-trained language models. Moreover, to demonstrate its flexibility, we show that SCAT can also be combined with supervised adversarial training to further enhance model robustness.
Large-Scale Korean Text Dataset for Classifying Biased Speech in Real-World Online Services
Oct 06, 2023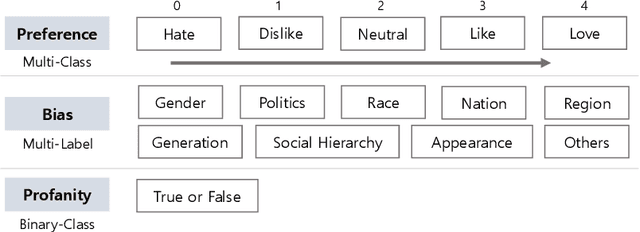
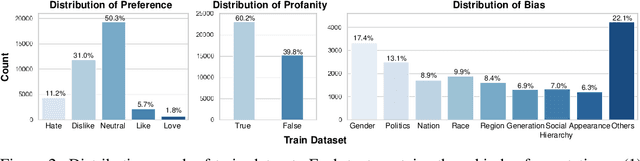
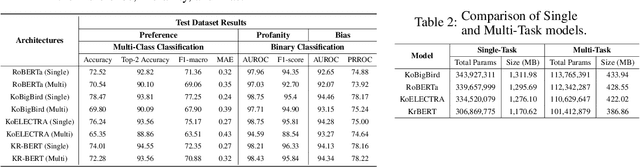

With the growth of online services, the need for advanced text classification algorithms, such as sentiment analysis and biased text detection, has become increasingly evident. The anonymous nature of online services often leads to the presence of biased and harmful language, posing challenges to maintaining the health of online communities. This phenomenon is especially relevant in South Korea, where large-scale hate speech detection algorithms have not yet been broadly explored. In this paper, we introduce a new comprehensive, large-scale dataset collected from a well-known South Korean SNS platform. Our proposed dataset provides annotations including (1) Preferences, (2) Profanities, and (3) Nine types of Bias for the text samples, enabling multi-task learning for simultaneous classification of user-generated texts. Leveraging state-of-the-art BERT-based language models, our approach surpasses human-level accuracy across diverse classification tasks, as measured by various metrics. Beyond academic contributions, our work can provide practical solutions for real-world hate speech and bias mitigation, contributing directly to the improvement of online community health. Our work provides a robust foundation for future research aiming to improve the quality of online discourse and foster societal well-being. All source codes and datasets are publicly accessible at https://github.com/Dasol-Choi/KoMultiText.
DKEC: Domain Knowledge Enhanced Multi-Label Classification for Electronic Health Records
Oct 10, 2023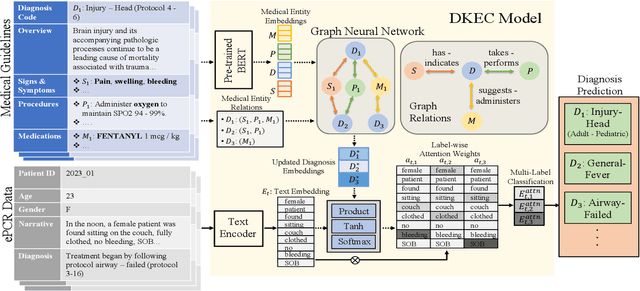



Multi-label text classification (MLTC) tasks in the medical domain often face long-tail label distribution, where rare classes have fewer training samples than frequent classes. Although previous works have explored different model architectures and hierarchical label structures to find important features, most of them neglect to incorporate the domain knowledge from medical guidelines. In this paper, we present DKEC, Domain Knowledge Enhanced Classifier for medical diagnosis prediction with two innovations: (1) a label-wise attention mechanism that incorporates a heterogeneous graph and domain ontologies to capture the semantic relationships between medical entities, (2) a simple yet effective group-wise training method based on similarity of labels to increase samples of rare classes. We evaluate DKEC on two real-world medical datasets: the RAA dataset, a collection of 4,417 patient care reports from emergency medical services (EMS) incidents, and a subset of 53,898 reports from the MIMIC-III dataset. Experimental results show that our method outperforms the state-of-the-art, particularly for the few-shot (tail) classes. More importantly, we study the applicability of DKEC to different language models and show that DKEC can help the smaller language models achieve comparable performance to large language models.
Harnessing Pre-Trained Sentence Transformers for Offensive Language Detection in Indian Languages
Oct 03, 2023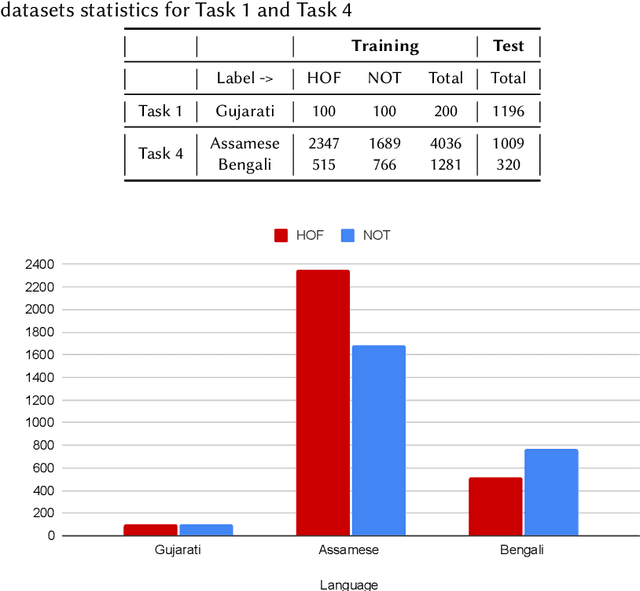
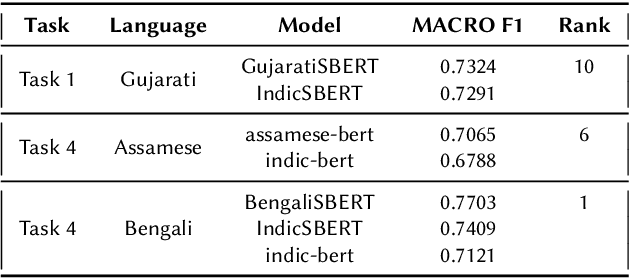
In our increasingly interconnected digital world, social media platforms have emerged as powerful channels for the dissemination of hate speech and offensive content. This work delves into the domain of hate speech detection, placing specific emphasis on three low-resource Indian languages: Bengali, Assamese, and Gujarati. The challenge is framed as a text classification task, aimed at discerning whether a tweet contains offensive or non-offensive content. Leveraging the HASOC 2023 datasets, we fine-tuned pre-trained BERT and SBERT models to evaluate their effectiveness in identifying hate speech. Our findings underscore the superiority of monolingual sentence-BERT models, particularly in the Bengali language, where we achieved the highest ranking. However, the performance in Assamese and Gujarati languages signifies ongoing opportunities for enhancement. Our goal is to foster inclusive online spaces by countering hate speech proliferation.
Out-of-Distribution Detection by Leveraging Between-Layer Transformation Smoothness
Oct 04, 2023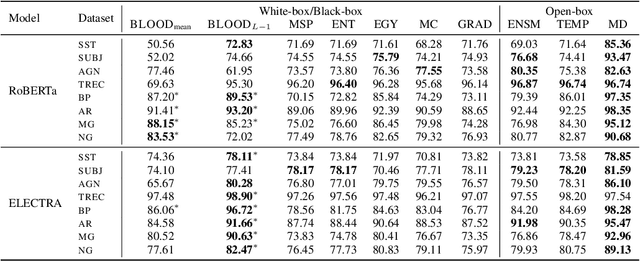
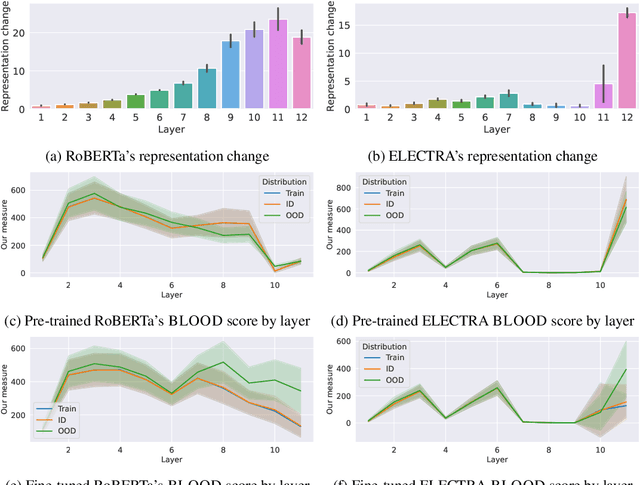
Effective OOD detection is crucial for reliable machine learning models, yet most current methods are limited in practical use due to requirements like access to training data or intervention in training. We present a novel method for detecting OOD data in deep neural networks based on transformation smoothness between intermediate layers of a network (BLOOD), which is applicable to pre-trained models without access to training data. BLOOD utilizes the tendency of between-layer representation transformations of in-distribution (ID) data to be smoother than the corresponding transformations of OOD data, a property that we also demonstrate empirically for Transformer networks. We evaluate BLOOD on several text classification tasks with Transformer networks and demonstrate that it outperforms methods with comparable resource requirements. Our analysis also suggests that when learning simpler tasks, OOD data transformations maintain their original sharpness, whereas sharpness increases with more complex tasks.
Unleashing the power of Neural Collapse for Transferability Estimation
Oct 09, 2023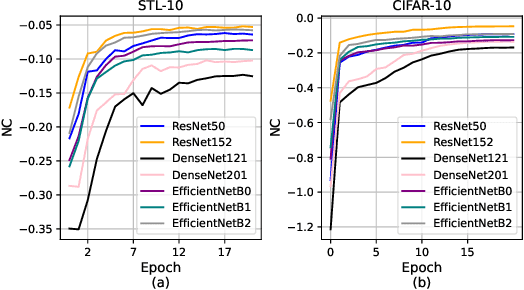
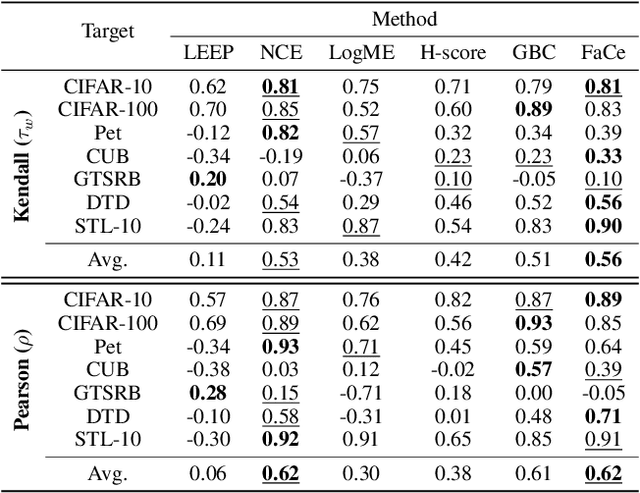
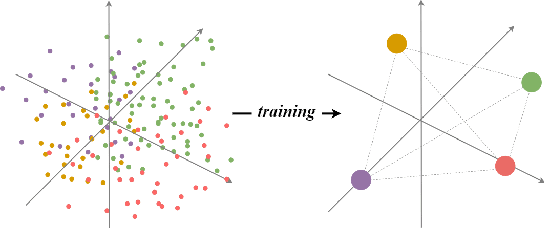
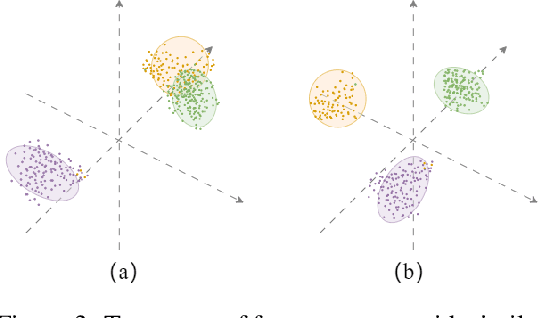
Transferability estimation aims to provide heuristics for quantifying how suitable a pre-trained model is for a specific downstream task, without fine-tuning them all. Prior studies have revealed that well-trained models exhibit the phenomenon of Neural Collapse. Based on a widely used neural collapse metric in existing literature, we observe a strong correlation between the neural collapse of pre-trained models and their corresponding fine-tuned models. Inspired by this observation, we propose a novel method termed Fair Collapse (FaCe) for transferability estimation by comprehensively measuring the degree of neural collapse in the pre-trained model. Typically, FaCe comprises two different terms: the variance collapse term, which assesses the class separation and within-class compactness, and the class fairness term, which quantifies the fairness of the pre-trained model towards each class. We investigate FaCe on a variety of pre-trained classification models across different network architectures, source datasets, and training loss functions. Results show that FaCe yields state-of-the-art performance on different tasks including image classification, semantic segmentation, and text classification, which demonstrate the effectiveness and generalization of our method.
Understanding and Mitigating Spurious Correlations in Text Classification
May 23, 2023
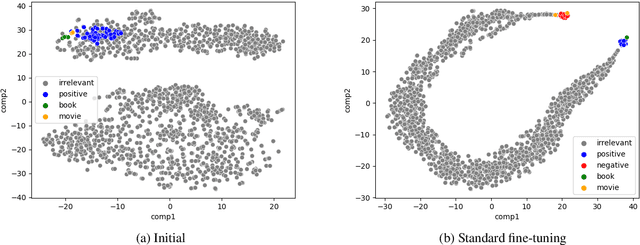
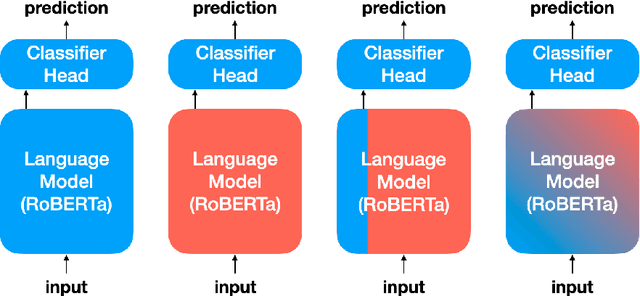
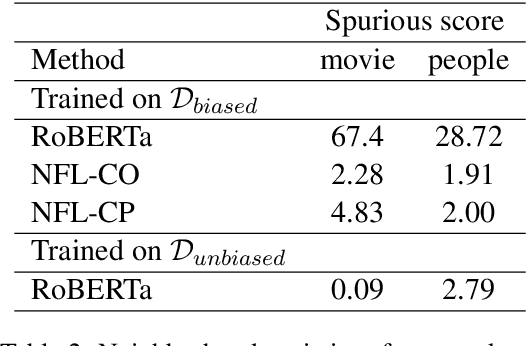
Recent work has shown that deep learning models are prone to exploit spurious correlations that are present in the training set, yet may not hold true in general. A sentiment classifier may erroneously learn that the token spielberg is always tied to positive movie reviews. Relying on spurious correlations may lead to significant degradation in generalizability and should be avoided. In this paper, we propose a neighborhood analysis framework to explain how exactly language models exploit spurious correlations. Driven by the analysis, we propose a family of regularization methods, NFL (do Not Forget your Language) to prevent the situation. Experiments on two text classification tasks show that NFL brings a significant improvement over standard fine-tuning in terms of robustness without sacrificing in-distribution accuracy.
Analyzing Textual Data for Fatality Classification in Afghanistan's Armed Conflicts: A BERT Approach
Oct 12, 2023Afghanistan has witnessed many armed conflicts throughout history, especially in the past 20 years; these events have had a significant impact on human lives, including military and civilians, with potential fatalities. In this research, we aim to leverage state-of-the-art machine learning techniques to classify the outcomes of Afghanistan armed conflicts to either fatal or non-fatal based on their textual descriptions provided by the Armed Conflict Location & Event Data Project (ACLED) dataset. The dataset contains comprehensive descriptions of armed conflicts in Afghanistan that took place from August 2021 to March 2023. The proposed approach leverages the power of BERT (Bidirectional Encoder Representations from Transformers), a cutting-edge language representation model in natural language processing. The classifier utilizes the raw textual description of an event to estimate the likelihood of the event resulting in a fatality. The model achieved impressive performance on the test set with an accuracy of 98.8%, recall of 98.05%, precision of 99.6%, and an F1 score of 98.82%. These results highlight the model's robustness and indicate its potential impact in various areas such as resource allocation, policymaking, and humanitarian aid efforts in Afghanistan. The model indicates a machine learning-based text classification approach using the ACLED dataset to accurately classify fatality in Afghanistan armed conflicts, achieving robust performance with the BERT model and paving the way for future endeavors in predicting event severity in Afghanistan.
Memoria: Hebbian Memory Architecture for Human-Like Sequential Processing
Oct 04, 2023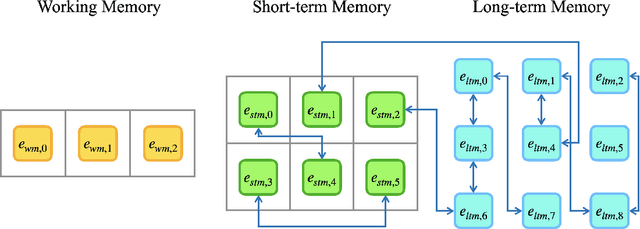

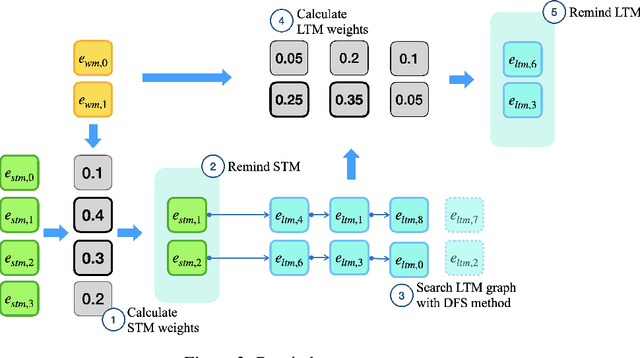

Transformers have demonstrated their success in various domains and tasks. However, Transformers struggle with long input sequences due to their limited capacity. While one solution is to increase input length, endlessly stretching the length is unrealistic. Furthermore, humans selectively remember and use only relevant information from inputs, unlike Transformers which process all raw data from start to end. We introduce Memoria, a general memory network that applies Hebbian theory which is a major theory explaining human memory formulation to enhance long-term dependencies in neural networks. Memoria stores and retrieves information called engram at multiple memory levels of working memory, short-term memory, and long-term memory, using connection weights that change according to Hebb's rule. Through experiments with popular Transformer-based models like BERT and GPT, we present that Memoria significantly improves the ability to consider long-term dependencies in various tasks. Results show that Memoria outperformed existing methodologies in sorting and language modeling, and long text classification.