 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Not All Demonstration Examples are Equally Beneficial: Reweighting Demonstration Examples for In-Context Learning
Oct 12, 2023
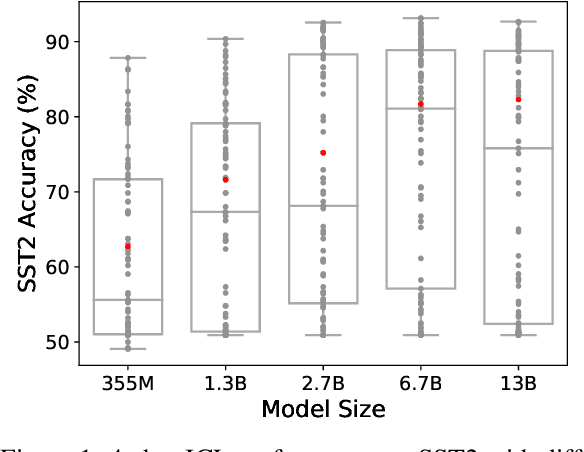
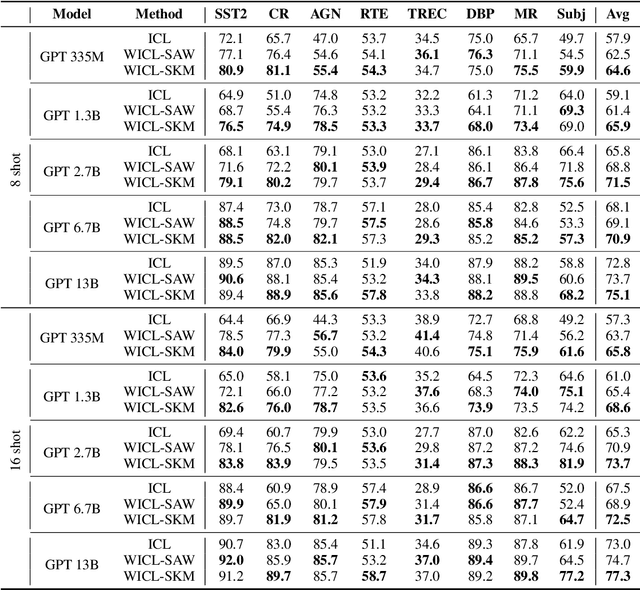

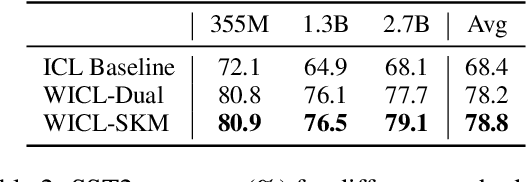
Large Language Models (LLMs) have recently gained the In-Context Learning (ICL) ability with the models scaling up, allowing them to quickly adapt to downstream tasks with only a few demonstration examples prepended in the input sequence. Nonetheless, the current practice of ICL treats all demonstration examples equally, which still warrants improvement, as the quality of examples is usually uneven. In this paper, we investigate how to determine approximately optimal weights for demonstration examples and how to apply them during ICL. To assess the quality of weights in the absence of additional validation data, we design a masked self-prediction (MSP) score that exhibits a strong correlation with the final ICL performance. To expedite the weight-searching process, we discretize the continuous weight space and adopt beam search. With approximately optimal weights obtained, we further propose two strategies to apply them to demonstrations at different model positions. Experimental results on 8 text classification tasks show that our approach outperforms conventional ICL by a large margin. Our code are publicly available at https:github.com/Zhe-Young/WICL.
Subtle Misogyny Detection and Mitigation: An Expert-Annotated Dataset
Nov 15, 2023Using novel approaches to dataset development, the Biasly dataset captures the nuance and subtlety of misogyny in ways that are unique within the literature. Built in collaboration with multi-disciplinary experts and annotators themselves, the dataset contains annotations of movie subtitles, capturing colloquial expressions of misogyny in North American film. The dataset can be used for a range of NLP tasks, including classification, severity score regression, and text generation for rewrites. In this paper, we discuss the methodology used, analyze the annotations obtained, and provide baselines using common NLP algorithms in the context of misogyny detection and mitigation. We hope this work will promote AI for social good in NLP for bias detection, explanation, and removal.
Explore the Effect of Data Selection on Poison Efficiency in Backdoor Attacks
Oct 15, 2023As the number of parameters in Deep Neural Networks (DNNs) scales, the thirst for training data also increases. To save costs, it has become common for users and enterprises to delegate time-consuming data collection to third parties. Unfortunately, recent research has shown that this practice raises the risk of DNNs being exposed to backdoor attacks. Specifically, an attacker can maliciously control the behavior of a trained model by poisoning a small portion of the training data. In this study, we focus on improving the poisoning efficiency of backdoor attacks from the sample selection perspective. The existing attack methods construct such poisoned samples by randomly selecting some clean data from the benign set and then embedding a trigger into them. However, this random selection strategy ignores that each sample may contribute differently to the backdoor injection, thereby reducing the poisoning efficiency. To address the above problem, a new selection strategy named Improved Filtering and Updating Strategy (FUS++) is proposed. Specifically, we adopt the forgetting events of the samples to indicate the contribution of different poisoned samples and use the curvature of the loss surface to analyses the effectiveness of this phenomenon. Accordingly, we combine forgetting events and curvature of different samples to conduct a simple yet efficient sample selection strategy. The experimental results on image classification (CIFAR-10, CIFAR-100, ImageNet-10), text classification (AG News), audio classification (ESC-50), and age regression (Facial Age) consistently demonstrate the effectiveness of the proposed strategy: the attack performance using FUS++ is significantly higher than that using random selection for the same poisoning ratio.
Re-weighting Tokens: A Simple and Effective Active Learning Strategy for Named Entity Recognition
Nov 02, 2023Active learning, a widely adopted technique for enhancing machine learning models in text and image classification tasks with limited annotation resources, has received relatively little attention in the domain of Named Entity Recognition (NER). The challenge of data imbalance in NER has hindered the effectiveness of active learning, as sequence labellers lack sufficient learning signals. To address these challenges, this paper presents a novel reweighting-based active learning strategy that assigns dynamic smoothed weights to individual tokens. This adaptable strategy is compatible with various token-level acquisition functions and contributes to the development of robust active learners. Experimental results on multiple corpora demonstrate the substantial performance improvement achieved by incorporating our re-weighting strategy into existing acquisition functions, validating its practical efficacy.
SpaDeLeF: A Dataset for Hierarchical Classification of Lexical Functions for Collocations in Spanish
Nov 07, 2023In natural language processing (NLP), lexical function is a concept to unambiguously represent semantic and syntactic features of words and phrases in text first crafted in the Meaning-Text Theory. Hierarchical classification of lexical functions involves organizing these features into a tree-like hierarchy of categories or labels. This is a challenging task as it requires a good understanding of the context and the relationships among words and phrases in text. It also needs large amounts of labeled data to train language models effectively. In this paper, we present a dataset of most frequent Spanish verb-noun collocations and sentences where they occur, each collocation is assigned to one of 37 lexical functions defined as classes for a hierarchical classification task. Each class represents a relation between the noun and the verb in a collocation involving their semantic and syntactic features. We combine the classes in a tree-based structure, and introduce classification objectives for each level of the structure. The dataset was created by dependency tree parsing and matching of the phrases in Spanish news. We provide baselines and data splits for each objective.
Representing visual classification as a linear combination of words
Nov 18, 2023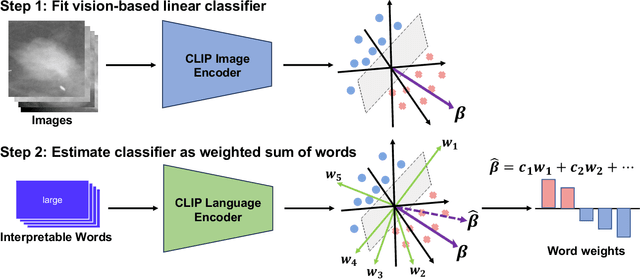
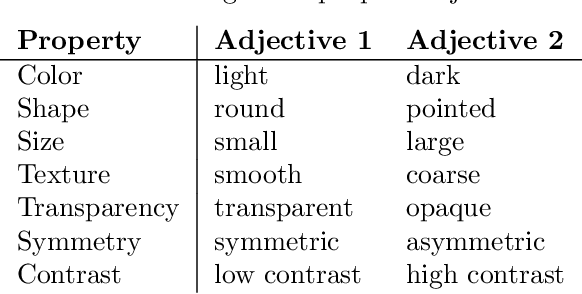
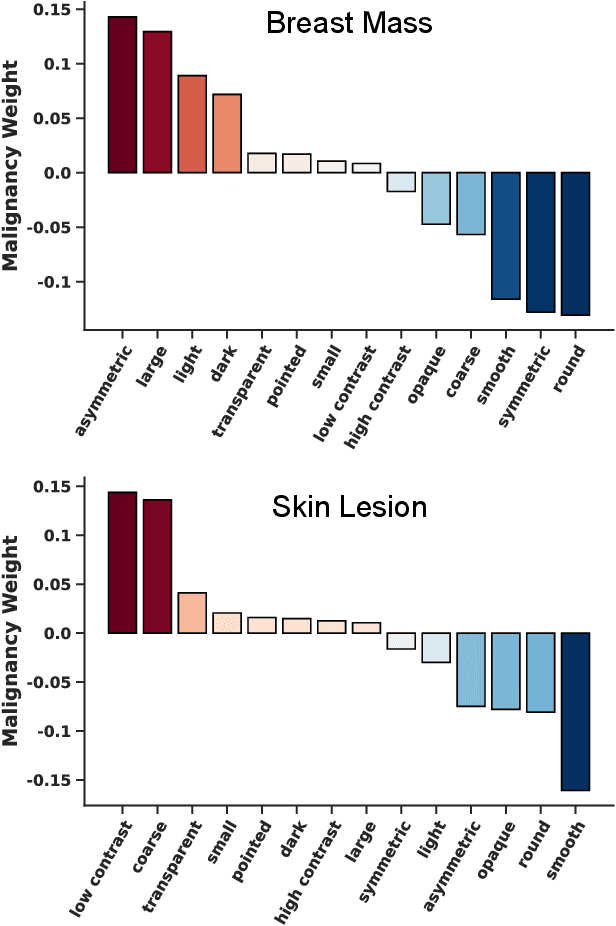
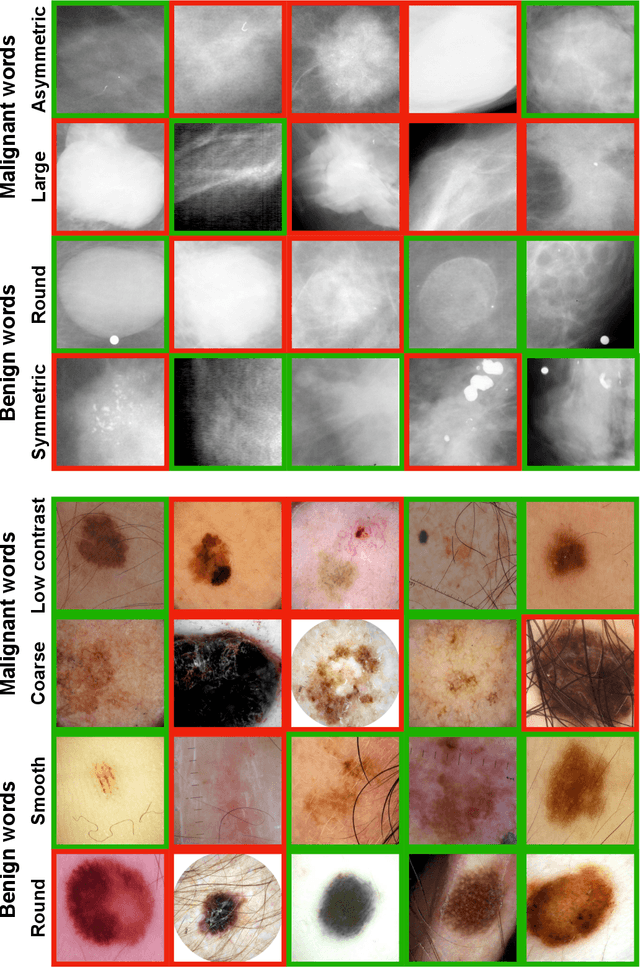
Explainability is a longstanding challenge in deep learning, especially in high-stakes domains like healthcare. Common explainability methods highlight image regions that drive an AI model's decision. Humans, however, heavily rely on language to convey explanations of not only "where" but "what". Additionally, most explainability approaches focus on explaining individual AI predictions, rather than describing the features used by an AI model in general. The latter would be especially useful for model and dataset auditing, and potentially even knowledge generation as AI is increasingly being used in novel tasks. Here, we present an explainability strategy that uses a vision-language model to identify language-based descriptors of a visual classification task. By leveraging a pre-trained joint embedding space between images and text, our approach estimates a new classification task as a linear combination of words, resulting in a weight for each word that indicates its alignment with the vision-based classifier. We assess our approach using two medical imaging classification tasks, where we find that the resulting descriptors largely align with clinical knowledge despite a lack of domain-specific language training. However, our approach also identifies the potential for 'shortcut connections' in the public datasets used. Towards a functional measure of explainability, we perform a pilot reader study where we find that the AI-identified words can enable non-expert humans to perform a specialized medical task at a non-trivial level. Altogether, our results emphasize the potential of using multimodal foundational models to deliver intuitive, language-based explanations of visual tasks.
Evaluating Explanation Methods for Vision-and-Language Navigation
Oct 10, 2023The ability to navigate robots with natural language instructions in an unknown environment is a crucial step for achieving embodied artificial intelligence (AI). With the improving performance of deep neural models proposed in the field of vision-and-language navigation (VLN), it is equally interesting to know what information the models utilize for their decision-making in the navigation tasks. To understand the inner workings of deep neural models, various explanation methods have been developed for promoting explainable AI (XAI). But they are mostly applied to deep neural models for image or text classification tasks and little work has been done in explaining deep neural models for VLN tasks. In this paper, we address these problems by building quantitative benchmarks to evaluate explanation methods for VLN models in terms of faithfulness. We propose a new erasure-based evaluation pipeline to measure the step-wise textual explanation in the sequential decision-making setting. We evaluate several explanation methods for two representative VLN models on two popular VLN datasets and reveal valuable findings through our experiments.
Taxi1500: A Multilingual Dataset for Text Classification in 1500 Languages
May 15, 2023
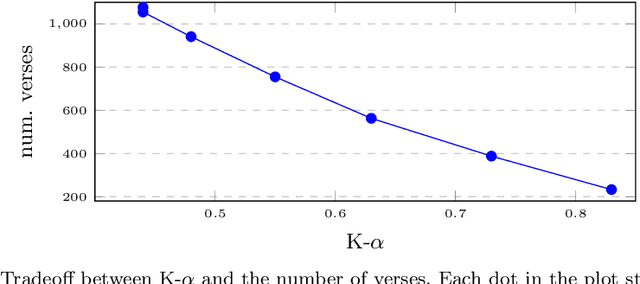
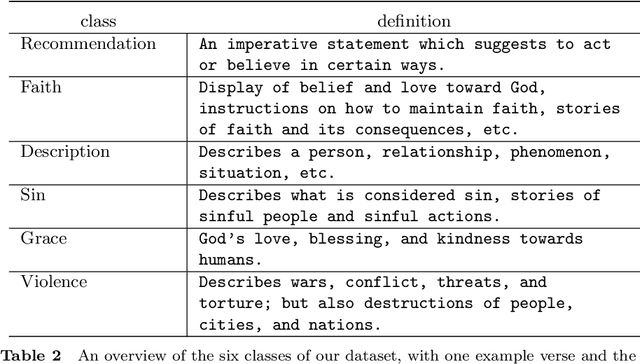
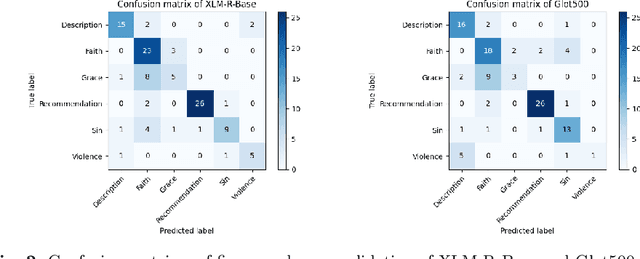
While natural language processing tools have been developed extensively for some of the world's languages, a significant portion of the world's over 7000 languages are still neglected. One reason for this is that evaluation datasets do not yet cover a wide range of languages, including low-resource and endangered ones. We aim to address this issue by creating a text classification dataset encompassing a large number of languages, many of which currently have little to no annotated data available. We leverage parallel translations of the Bible to construct such a dataset by first developing applicable topics and employing a crowdsourcing tool to collect annotated data. By annotating the English side of the data and projecting the labels onto other languages through aligned verses, we generate text classification datasets for more than 1500 languages. We extensively benchmark several existing multilingual language models using our dataset. To facilitate the advancement of research in this area, we will release our dataset and code.
Accelerating Thematic Investment with Prompt Tuned Pretrained Language Models
Sep 21, 2023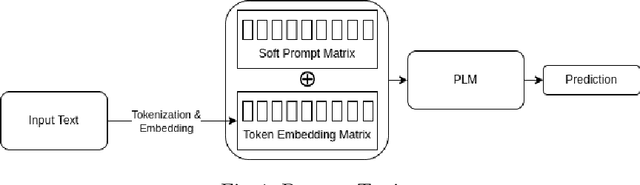
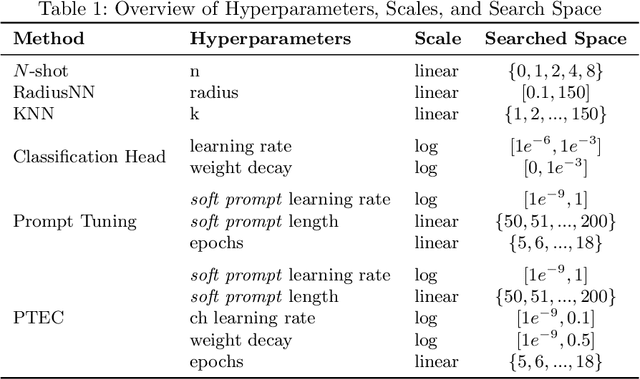
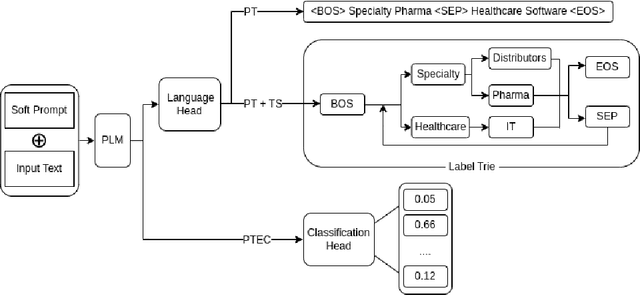
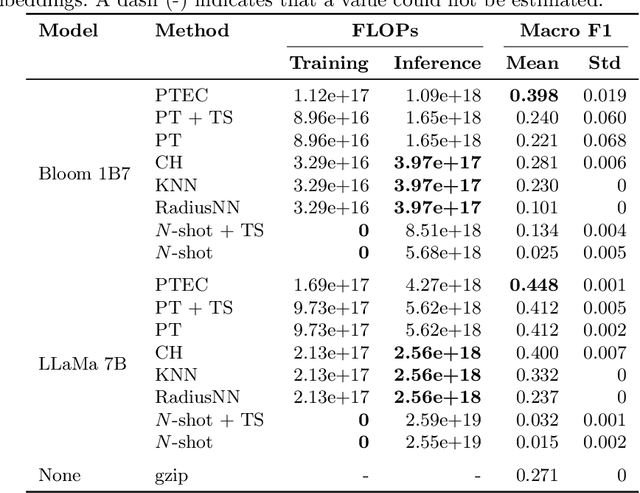
Prompt Tuning is emerging as a scalable and cost-effective method to fine-tune Pretrained Language Models (PLMs). This study benchmarks the performance and computational efficiency of Prompt Tuning and baseline methods on a multi-label text classification task. This is applied to the use case of classifying companies into an investment firm's proprietary industry taxonomy, supporting their thematic investment strategy. Text-to-text classification with PLMs is frequently reported to outperform classification with a classification head, but has several limitations when applied to a multi-label classification problem where each label consists of multiple tokens: (a) Generated labels may not match any label in the industry taxonomy; (b) During fine-tuning, multiple labels must be provided in an arbitrary order; (c) The model provides a binary decision for each label, rather than an appropriate confidence score. Limitation (a) is addressed by applying constrained decoding using Trie Search, which slightly improves classification performance. All limitations (a), (b), and (c) are addressed by replacing the PLM's language head with a classification head. This improves performance significantly, while also reducing computational costs during inference. The results indicate the continuing need to adapt state-of-the-art methods to domain-specific tasks, even in the era of PLMs with strong generalization abilities.
Deconstructing Classifiers: Towards A Data Reconstruction Attack Against Text Classification Models
Jun 23, 2023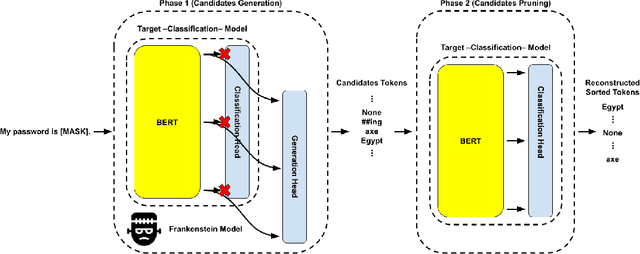
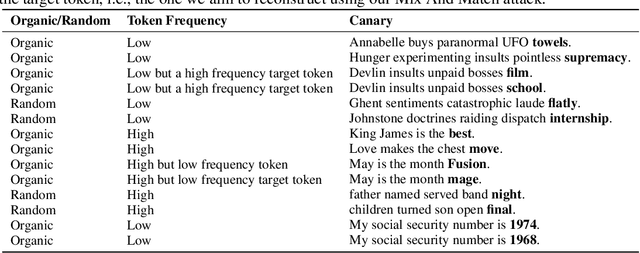
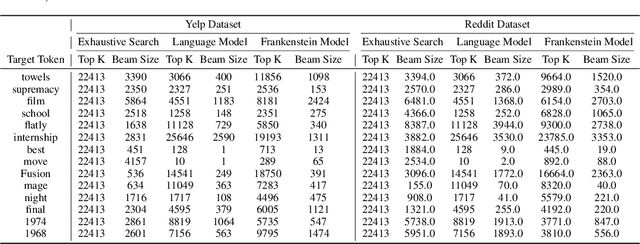
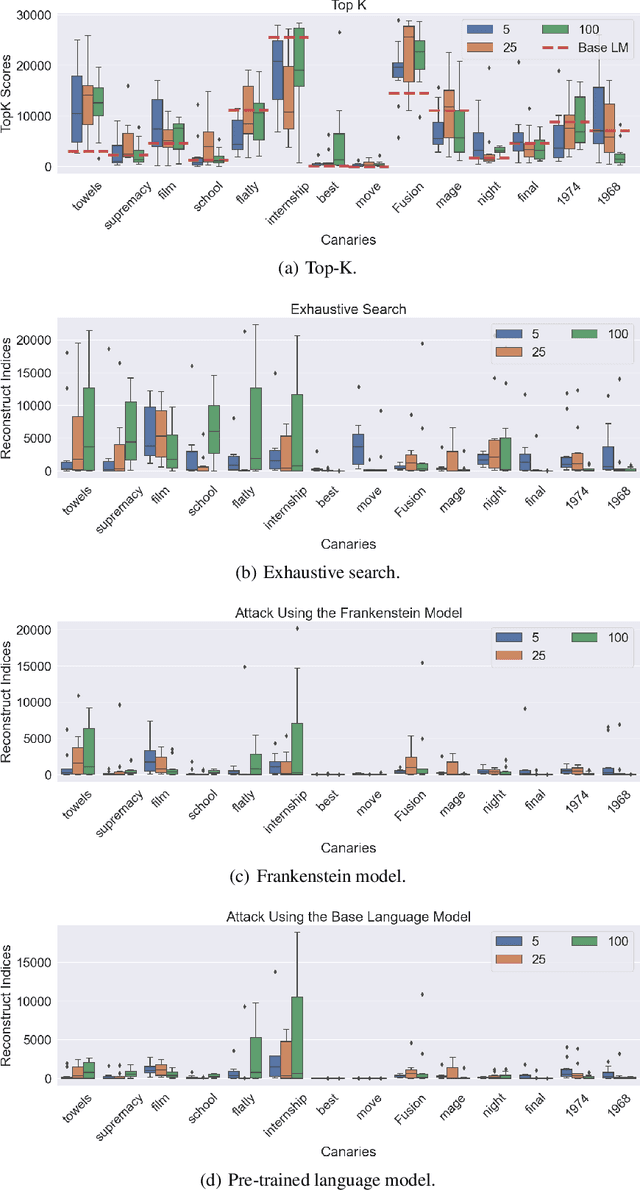
Natural language processing (NLP) models have become increasingly popular in real-world applications, such as text classification. However, they are vulnerable to privacy attacks, including data reconstruction attacks that aim to extract the data used to train the model. Most previous studies on data reconstruction attacks have focused on LLM, while classification models were assumed to be more secure. In this work, we propose a new targeted data reconstruction attack called the Mix And Match attack, which takes advantage of the fact that most classification models are based on LLM. The Mix And Match attack uses the base model of the target model to generate candidate tokens and then prunes them using the classification head. We extensively demonstrate the effectiveness of the attack using both random and organic canaries. This work highlights the importance of considering the privacy risks associated with data reconstruction attacks in classification models and offers insights into possible leakages.