 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
ChatGraph: Interpretable Text Classification by Converting ChatGPT Knowledge to Graphs
May 03, 2023
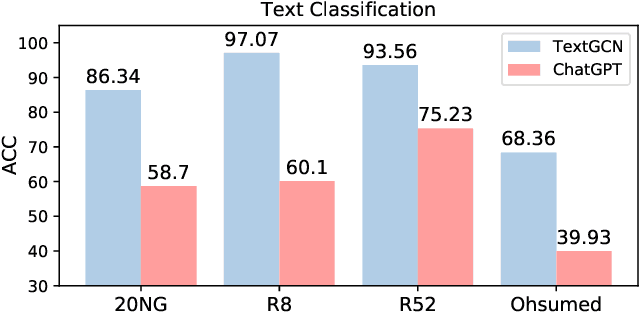
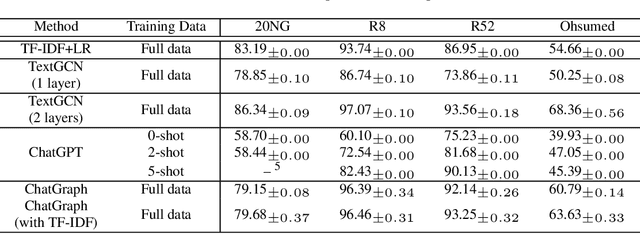
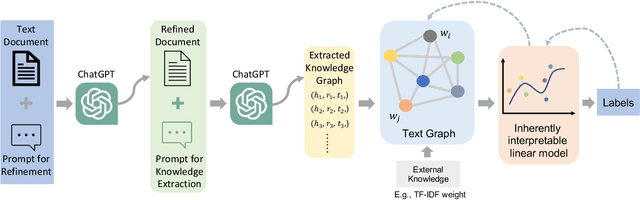

ChatGPT, as a recently launched large language model (LLM), has shown superior performance in various natural language processing (NLP) tasks. However, two major limitations hinder its potential applications: (1) the inflexibility of finetuning on downstream tasks and (2) the lack of interpretability in the decision-making process. To tackle these limitations, we propose a novel framework that leverages the power of ChatGPT for specific tasks, such as text classification, while improving its interpretability. The proposed framework conducts a knowledge graph extraction task to extract refined and structural knowledge from the raw data using ChatGPT. The rich knowledge is then converted into a graph, which is further used to train an interpretable linear classifier to make predictions. To evaluate the effectiveness of our proposed method, we conduct experiments on four datasets. The result shows that our method can significantly improve the performance compared to directly utilizing ChatGPT for text classification tasks. And our method provides a more transparent decision-making process compared with previous text classification methods.
Linear Classifier: An Often-Forgotten Baseline for Text Classification
Jun 12, 2023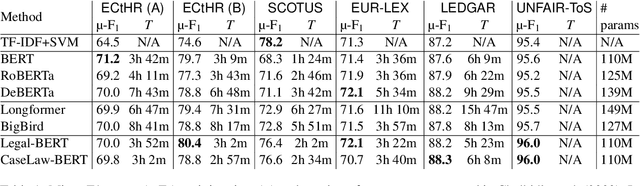
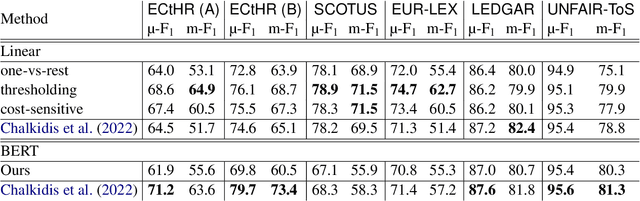
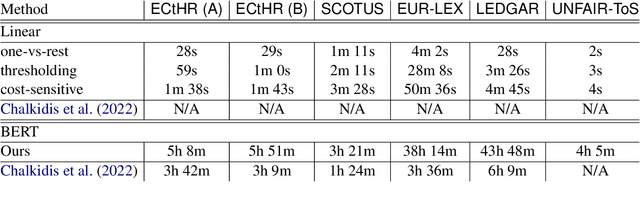

Large-scale pre-trained language models such as BERT are popular solutions for text classification. Due to the superior performance of these advanced methods, nowadays, people often directly train them for a few epochs and deploy the obtained model. In this opinion paper, we point out that this way may only sometimes get satisfactory results. We argue the importance of running a simple baseline like linear classifiers on bag-of-words features along with advanced methods. First, for many text data, linear methods show competitive performance, high efficiency, and robustness. Second, advanced models such as BERT may only achieve the best results if properly applied. Simple baselines help to confirm whether the results of advanced models are acceptable. Our experimental results fully support these points.
United We Stand: Using Epoch-wise Agreement of Ensembles to Combat Overfit
Oct 17, 2023Deep neural networks have become the method of choice for solving many image classification tasks, largely because they can fit very complex functions defined over raw images. The downside of such powerful learners is the danger of overfitting the training set, leading to poor generalization, which is usually avoided by regularization and "early stopping" of the training. In this paper, we propose a new deep network ensemble classifier that is very effective against overfit. We begin with the theoretical analysis of a regression model, whose predictions - that the variance among classifiers increases when overfit occurs - is demonstrated empirically in deep networks in common use. Guided by these results, we construct a new ensemble-based prediction method designed to combat overfit, where the prediction is determined by the most consensual prediction throughout the training. On multiple image and text classification datasets, we show that when regular ensembles suffer from overfit, our method eliminates the harmful reduction in generalization due to overfit, and often even surpasses the performance obtained by early stopping. Our method is easy to implement, and can be integrated with any training scheme and architecture, without additional prior knowledge beyond the training set. Accordingly, it is a practical and useful tool to overcome overfit.
Effects of Human Adversarial and Affable Samples on BERT Generalizability
Oct 13, 2023
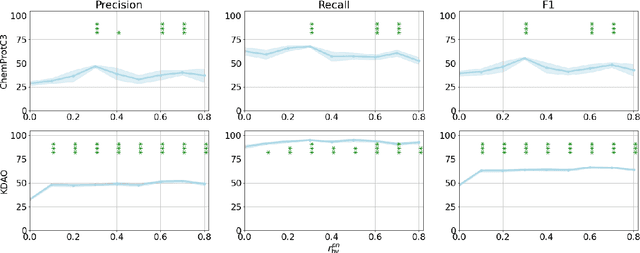

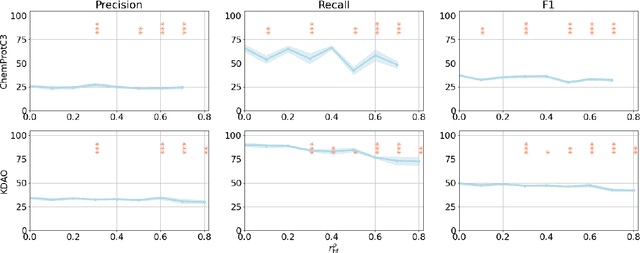
BERT-based models have had strong performance on leaderboards, yet have been demonstrably worse in real-world settings requiring generalization. Limited quantities of training data is considered a key impediment to achieving generalizability in machine learning. In this paper, we examine the impact of training data quality, not quantity, on a model's generalizability. We consider two characteristics of training data: the portion of human-adversarial (h-adversarial), i.e., sample pairs with seemingly minor differences but different ground-truth labels, and human-affable (h-affable) training samples, i.e., sample pairs with minor differences but the same ground-truth label. We find that for a fixed size of training samples, as a rule of thumb, having 10-30% h-adversarial instances improves the precision, and therefore F1, by up to 20 points in the tasks of text classification and relation extraction. Increasing h-adversarials beyond this range can result in performance plateaus or even degradation. In contrast, h-affables may not contribute to a model's generalizability and may even degrade generalization performance.
Point, Segment and Count: A Generalized Framework for Object Counting
Nov 21, 2023Class-agnostic object counting aims to count all objects in an image with respect to example boxes or class names, \emph{a.k.a} few-shot and zero-shot counting. Current state-of-the-art methods highly rely on density maps to predict object counts, which lacks model interpretability. In this paper, we propose a generalized framework for both few-shot and zero-shot object counting based on detection. Our framework combines the superior advantages of two foundation models without compromising their zero-shot capability: (\textbf{i}) SAM to segment all possible objects as mask proposals, and (\textbf{ii}) CLIP to classify proposals to obtain accurate object counts. However, this strategy meets the obstacles of efficiency overhead and the small crowded objects that cannot be localized and distinguished. To address these issues, our framework, termed PseCo, follows three steps: point, segment, and count. Specifically, we first propose a class-agnostic object localization to provide accurate but least point prompts for SAM, which consequently not only reduces computation costs but also avoids missing small objects. Furthermore, we propose a generalized object classification that leverages CLIP image/text embeddings as the classifier, following a hierarchical knowledge distillation to obtain discriminative classifications among hierarchical mask proposals. Extensive experimental results on FSC-147 dataset demonstrate that PseCo achieves state-of-the-art performance in both few-shot/zero-shot object counting/detection, with additional results on large-scale COCO and LVIS datasets. The source code is available at \url{https://github.com/Hzzone/PseCo}.
Mixed-Distil-BERT: Code-mixed Language Modeling for Bangla, English, and Hindi
Sep 19, 2023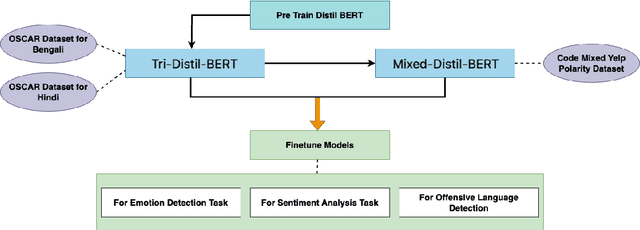
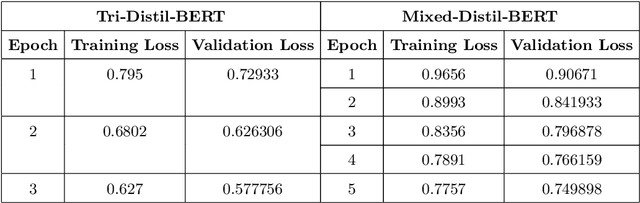
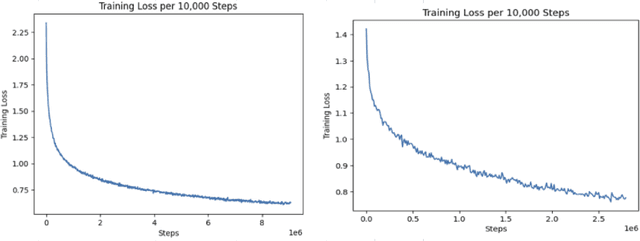
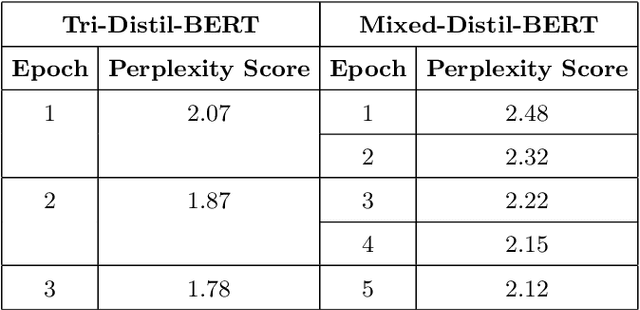
One of the most popular downstream tasks in the field of Natural Language Processing is text classification. Text classification tasks have become more daunting when the texts are code-mixed. Though they are not exposed to such text during pre-training, different BERT models have demonstrated success in tackling Code-Mixed NLP challenges. Again, in order to enhance their performance, Code-Mixed NLP models have depended on combining synthetic data with real-world data. It is crucial to understand how the BERT models' performance is impacted when they are pretrained using corresponding code-mixed languages. In this paper, we introduce Tri-Distil-BERT, a multilingual model pre-trained on Bangla, English, and Hindi, and Mixed-Distil-BERT, a model fine-tuned on code-mixed data. Both models are evaluated across multiple NLP tasks and demonstrate competitive performance against larger models like mBERT and XLM-R. Our two-tiered pre-training approach offers efficient alternatives for multilingual and code-mixed language understanding, contributing to advancements in the field.
Generative Calibration for In-context Learning
Oct 16, 2023As one of the most exciting features of large language models (LLMs), in-context learning is a mixed blessing. While it allows users to fast-prototype a task solver with only a few training examples, the performance is generally sensitive to various configurations of the prompt such as the choice or order of the training examples. In this paper, we for the first time theoretically and empirically identify that such a paradox is mainly due to the label shift of the in-context model to the data distribution, in which LLMs shift the label marginal $p(y)$ while having a good label conditional $p(x|y)$. With this understanding, we can simply calibrate the in-context predictive distribution by adjusting the label marginal, which is estimated via Monte-Carlo sampling over the in-context model, i.e., generation of LLMs. We call our approach as generative calibration. We conduct exhaustive experiments with 12 text classification tasks and 12 LLMs scaling from 774M to 33B, generally find that the proposed method greatly and consistently outperforms the ICL as well as state-of-the-art calibration methods, by up to 27% absolute in macro-F1. Meanwhile, the proposed method is also stable under different prompt configurations.
An Improved Neural Network Model Based On CNN Using For Fruit Sugar Degree Detection
Nov 18, 2023Artificial Intelligence(AI) widely applies in Image Classification and Recognition, Text Understanding and Natural Language Processing, which makes great progress. In this paper, we introduced AI into the fruit quality detection field. We designed a fruit sugar degree regression model using an Artificial Neural Network based on spectra of fruits within the visible/near-infrared(V/NIR)range. After analysis of fruit spectra, we innovatively proposed a new neural network structure: low layers consist of a Multilayer Perceptron(MLP), a middle layer is a 2-dimensional correlation matrix layer, and high layers consist of several Convolutional Neural Network(CNN) layers. In this study, we used fruit sugar value as a detection target, collecting two fruits called Gan Nan Navel and Tian Shan Pear as samples, doing experiments respectively, and comparing their results. We used Analysis of Variance(ANOVA) to evaluate the reliability of the dataset we collected. Then, we tried multiple strategies to process spectrum data, evaluating their effects. In this paper, we tried to add Wavelet Decomposition(WD) to reduce feature dimensions and a Genetic Algorithm(GA) to find excellent features. Then, we compared Neural Network models with traditional Partial Least Squares(PLS) based models. We also compared the neural network structure we designed(MLP-CNN) with other traditional neural network structures. In this paper, we proposed a new evaluation standard derived from dataset standard deviation(STD) for evaluating detection performance, validating the viability of using an artificial neural network model to do fruit sugar degree nondestructive detection.
Retrieval-augmented Multi-label Text Classification
May 22, 2023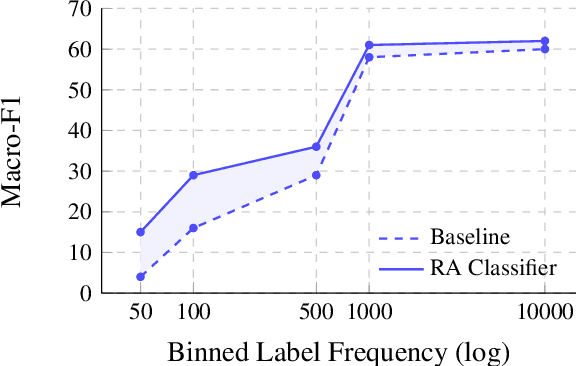

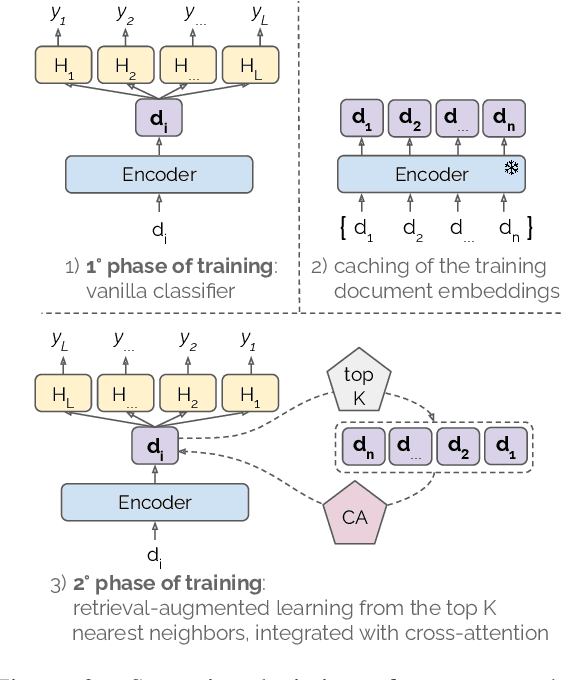
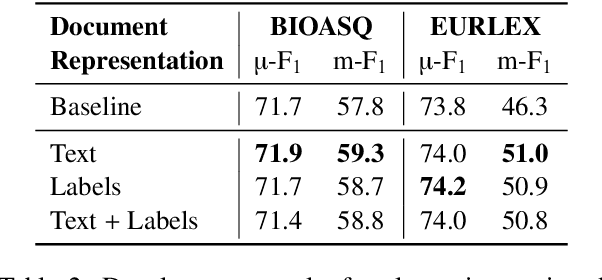
Multi-label text classification (MLC) is a challenging task in settings of large label sets, where label support follows a Zipfian distribution. In this paper, we address this problem through retrieval augmentation, aiming to improve the sample efficiency of classification models. Our approach closely follows the standard MLC architecture of a Transformer-based encoder paired with a set of classification heads. In our case, however, the input document representation is augmented through cross-attention to similar documents retrieved from the training set and represented in a task-specific manner. We evaluate this approach on four datasets from the legal and biomedical domains, all of which feature highly skewed label distributions. Our experiments show that retrieval augmentation substantially improves model performance on the long tail of infrequent labels especially so for lower-resource training scenarios and more challenging long-document data scenarios.
Not All Demonstration Examples are Equally Beneficial: Reweighting Demonstration Examples for In-Context Learning
Oct 12, 2023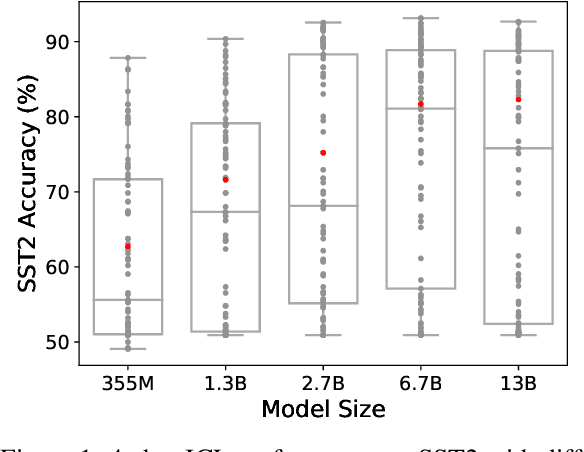
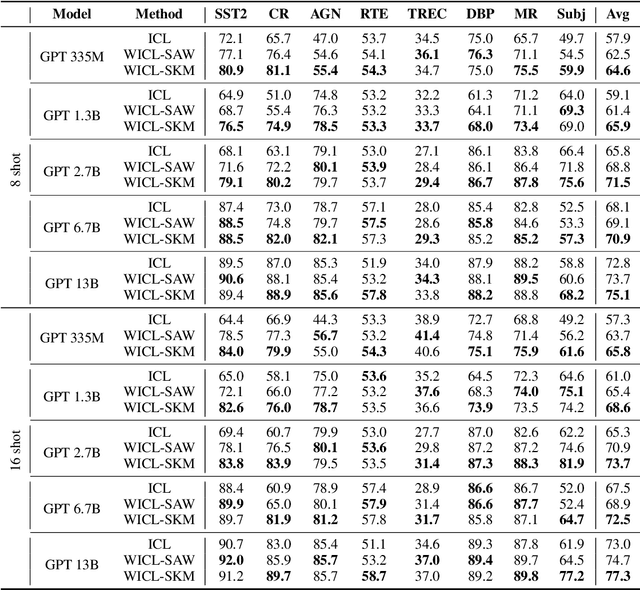

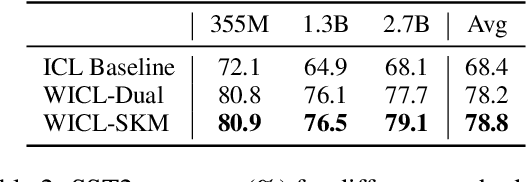
Large Language Models (LLMs) have recently gained the In-Context Learning (ICL) ability with the models scaling up, allowing them to quickly adapt to downstream tasks with only a few demonstration examples prepended in the input sequence. Nonetheless, the current practice of ICL treats all demonstration examples equally, which still warrants improvement, as the quality of examples is usually uneven. In this paper, we investigate how to determine approximately optimal weights for demonstration examples and how to apply them during ICL. To assess the quality of weights in the absence of additional validation data, we design a masked self-prediction (MSP) score that exhibits a strong correlation with the final ICL performance. To expedite the weight-searching process, we discretize the continuous weight space and adopt beam search. With approximately optimal weights obtained, we further propose two strategies to apply them to demonstrations at different model positions. Experimental results on 8 text classification tasks show that our approach outperforms conventional ICL by a large margin. Our code are publicly available at https:github.com/Zhe-Young/WICL.