 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Manipulating the Label Space for In-Context Classification
Dec 01, 2023
After pre-training by generating the next word conditional on previous words, the Language Model (LM) acquires the ability of In-Context Learning (ICL) that can learn a new task conditional on the context of the given in-context examples (ICEs). Similarly, visually-conditioned Language Modelling is also used to train Vision-Language Models (VLMs) with ICL ability. However, such VLMs typically exhibit weaker classification abilities compared to contrastive learning-based models like CLIP, since the Language Modelling objective does not directly contrast whether an object is paired with a text. To improve the ICL of classification, using more ICEs to provide more knowledge is a straightforward way. However, this may largely increase the selection time, and more importantly, the inclusion of additional in-context images tends to extend the length of the in-context sequence beyond the processing capacity of a VLM. To alleviate these limitations, we propose to manipulate the label space of each ICE to increase its knowledge density, allowing for fewer ICEs to convey as much information as a larger set would. Specifically, we propose two strategies which are Label Distribution Enhancement and Visual Descriptions Enhancement to improve In-context classification performance on diverse datasets, including the classic ImageNet and more fine-grained datasets like CUB-200. Specifically, using our approach on ImageNet, we increase accuracy from 74.70\% in a 4-shot setting to 76.21\% with just 2 shots. surpassing CLIP by 0.67\%. On CUB-200, our method raises 1-shot accuracy from 48.86\% to 69.05\%, 12.15\% higher than CLIP. The code is given in https://anonymous.4open.science/r/MLS_ICC.
XAL: EXplainable Active Learning Makes Classifiers Better Low-resource Learners
Oct 09, 2023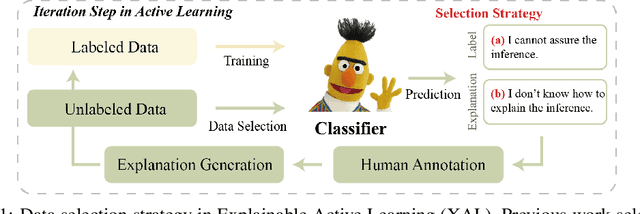

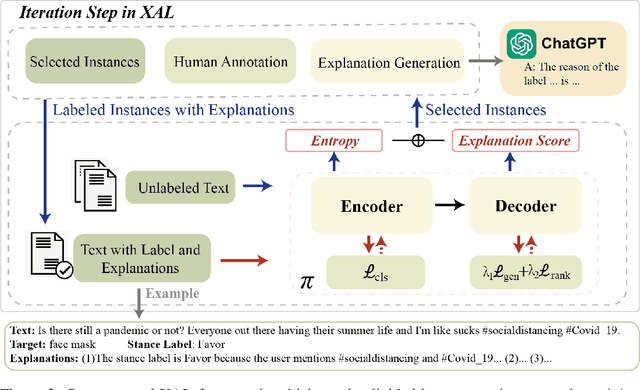
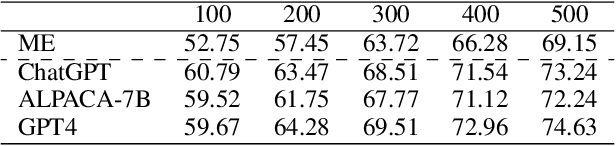
Active learning aims to construct an effective training set by iteratively curating the most informative unlabeled data for annotation, which is practical in low-resource tasks. Most active learning techniques in classification rely on the model's uncertainty or disagreement to choose unlabeled data. However, previous work indicates that existing models are poor at quantifying predictive uncertainty, which can lead to over-confidence in superficial patterns and a lack of exploration. Inspired by the cognitive processes in which humans deduce and predict through causal information, we propose a novel Explainable Active Learning framework (XAL) for low-resource text classification, which aims to encourage classifiers to justify their inferences and delve into unlabeled data for which they cannot provide reasonable explanations. Specifically, besides using a pre-trained bi-directional encoder for classification, we employ a pre-trained uni-directional decoder to generate and score the explanation. A ranking loss is proposed to enhance the decoder's capability in scoring explanations. During the selection of unlabeled data, we combine the predictive uncertainty of the encoder and the explanation score of the decoder to acquire informative data for annotation. As XAL is a general framework for text classification, we test our methods on six different classification tasks. Extensive experiments show that XAL achieves substantial improvement on all six tasks over previous AL methods. Ablation studies demonstrate the effectiveness of each component, and human evaluation shows that the model trained in XAL performs surprisingly well in explaining its prediction.
Unsupervised Calibration through Prior Adaptation for Text Classification using Large Language Models
Jul 13, 2023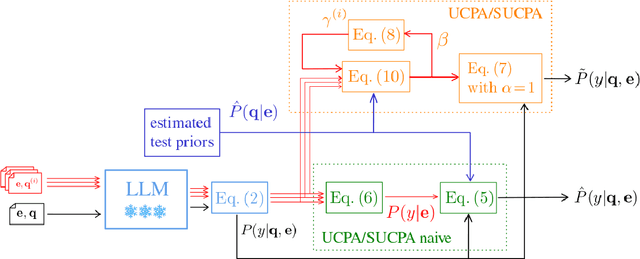
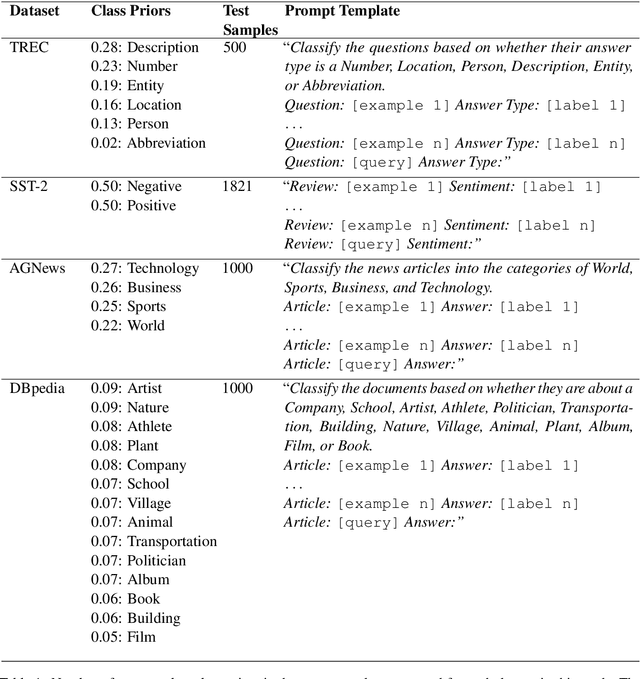
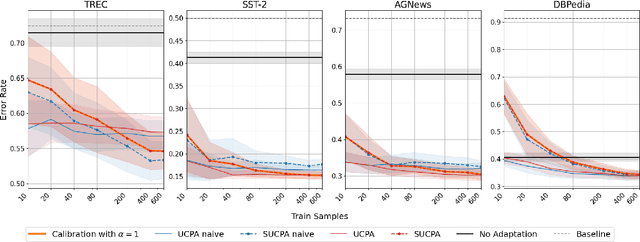
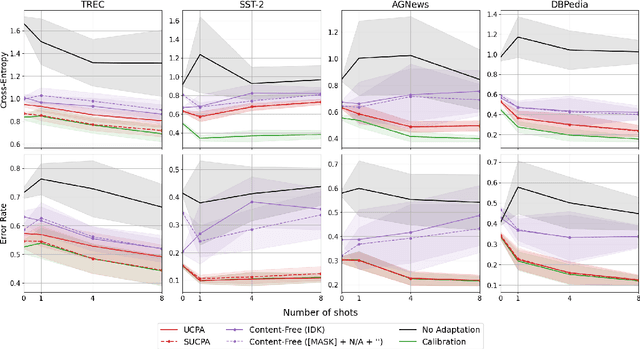
A wide variety of natural language tasks are currently being addressed with large-scale language models (LLMs). These models are usually trained with a very large amount of unsupervised text data and adapted to perform a downstream natural language task using methods like fine-tuning, calibration or in-context learning. In this work, we propose an approach to adapt the prior class distribution to perform text classification tasks without the need for labelled samples and only few in-domain sample queries. The proposed approach treats the LLM as a black box, adding a stage where the model posteriors are calibrated to the task. Results show that these methods outperform the un-adapted model for different number of training shots in the prompt and a previous approach were calibration is performed without using any adaptation data.
Automatic Report Generation for Histopathology images using pre-trained Vision Transformers and BERT
Dec 03, 2023Deep learning for histopathology has been successfully used for disease classification, image segmentation and more. However, combining image and text modalities using current state-of-the-art methods has been a challenge due to the high resolution of histopathology images. Automatic report generation for histopathology images is one such challenge. In this work, we show that using an existing pre-trained Vision Transformer in a two-step process of first using it to encode 4096x4096 sized patches of the Whole Slide Image (WSI) and then using it as the encoder and a pre-trained Bidirectional Encoder Representations from Transformers (BERT) model for language modeling-based decoder for report generation, we can build a fairly performant and portable report generation mechanism that takes into account the whole of the high resolution image, instead of just the patches. Our method allows us to not only generate and evaluate captions that describe the image, but also helps us classify the image into tissue types and the gender of the patient as well. Our best performing model achieves a 79.98% accuracy in Tissue Type classification and 66.36% accuracy in classifying the sex of the patient the tissue came from, with a BLEU-4 score of 0.5818 in our caption generation task.
In-Context Learning for Text Classification with Many Labels
Sep 19, 2023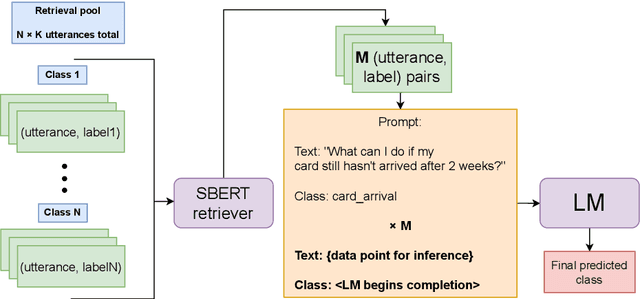
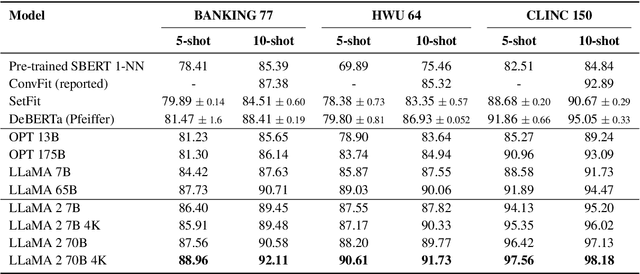
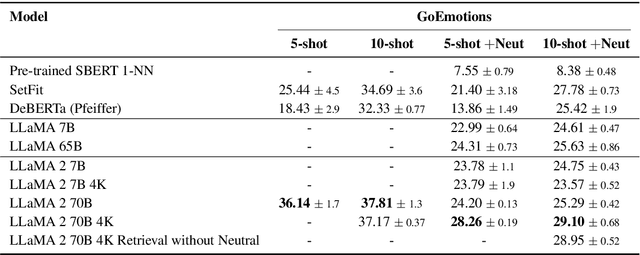
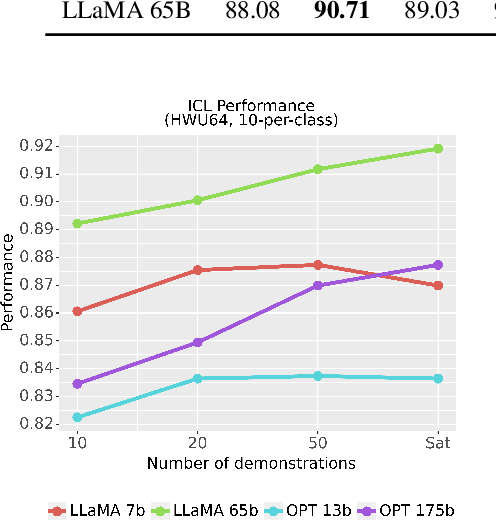
In-context learning (ICL) using large language models for tasks with many labels is challenging due to the limited context window, which makes it difficult to fit a sufficient number of examples in the prompt. In this paper, we use a pre-trained dense retrieval model to bypass this limitation, giving the model only a partial view of the full label space for each inference call. Testing with recent open-source LLMs (OPT, LLaMA), we set new state of the art performance in few-shot settings for three common intent classification datasets, with no finetuning. We also surpass fine-tuned performance on fine-grained sentiment classification in certain cases. We analyze the performance across number of in-context examples and different model scales, showing that larger models are necessary to effectively and consistently make use of larger context lengths for ICL. By running several ablations, we analyze the model's use of: a) the similarity of the in-context examples to the current input, b) the semantic content of the class names, and c) the correct correspondence between examples and labels. We demonstrate that all three are needed to varying degrees depending on the domain, contrary to certain recent works.
Generative AI Text Classification using Ensemble LLM Approaches
Sep 14, 2023



Large Language Models (LLMs) have shown impressive performance across a variety of Artificial Intelligence (AI) and natural language processing tasks, such as content creation, report generation, etc. However, unregulated malign application of these models can create undesirable consequences such as generation of fake news, plagiarism, etc. As a result, accurate detection of AI-generated language can be crucial in responsible usage of LLMs. In this work, we explore 1) whether a certain body of text is AI generated or written by human, and 2) attribution of a specific language model in generating a body of text. Texts in both English and Spanish are considered. The datasets used in this study are provided as part of the Automated Text Identification (AuTexTification) shared task. For each of the research objectives stated above, we propose an ensemble neural model that generates probabilities from different pre-trained LLMs which are used as features to a Traditional Machine Learning (TML) classifier following it. For the first task of distinguishing between AI and human generated text, our model ranked in fifth and thirteenth place (with macro $F1$ scores of 0.733 and 0.649) for English and Spanish texts, respectively. For the second task on model attribution, our model ranked in first place with macro $F1$ scores of 0.625 and 0.653 for English and Spanish texts, respectively.
Augmenting Low-Resource Text Classification with Graph-Grounded Pre-training and Prompting
May 05, 2023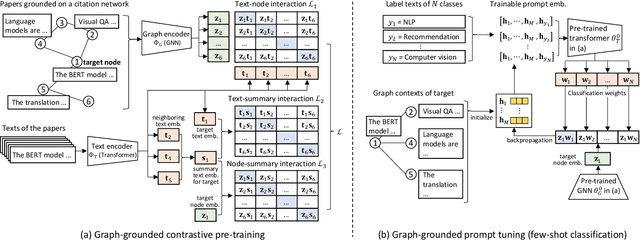
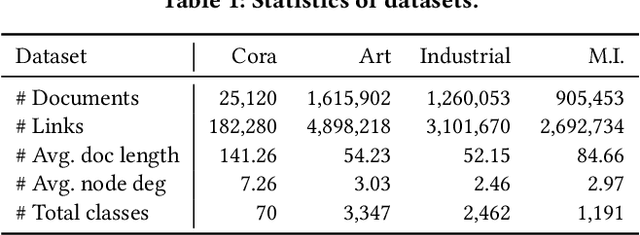
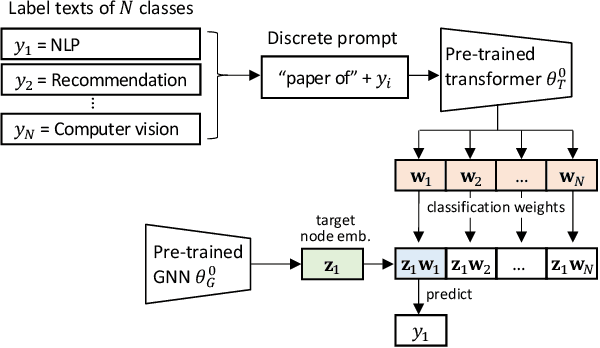
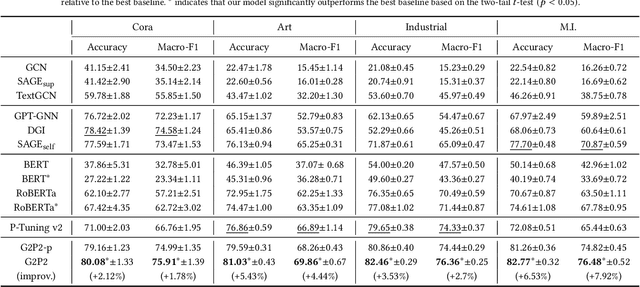
Text classification is a fundamental problem in information retrieval with many real-world applications, such as predicting the topics of online articles and the categories of e-commerce product descriptions. However, low-resource text classification, with few or no labeled samples, poses a serious concern for supervised learning. Meanwhile, many text data are inherently grounded on a network structure, such as a hyperlink/citation network for online articles, and a user-item purchase network for e-commerce products. These graph structures capture rich semantic relationships, which can potentially augment low-resource text classification. In this paper, we propose a novel model called Graph-Grounded Pre-training and Prompting (G2P2) to address low-resource text classification in a two-pronged approach. During pre-training, we propose three graph interaction-based contrastive strategies to jointly pre-train a graph-text model; during downstream classification, we explore prompting for the jointly pre-trained model to achieve low-resource classification. Extensive experiments on four real-world datasets demonstrate the strength of G2P2 in zero- and few-shot low-resource text classification tasks.
PromptCBLUE: A Chinese Prompt Tuning Benchmark for the Medical Domain
Oct 22, 2023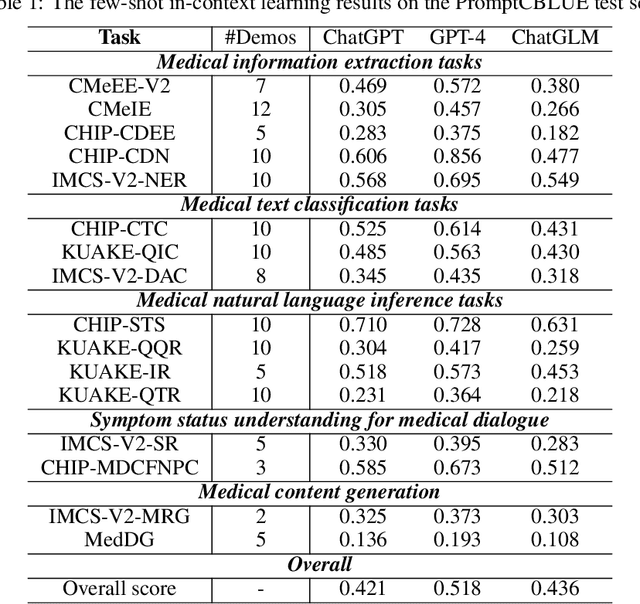
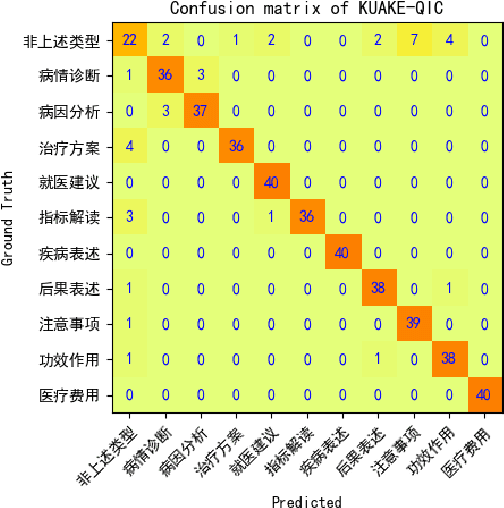
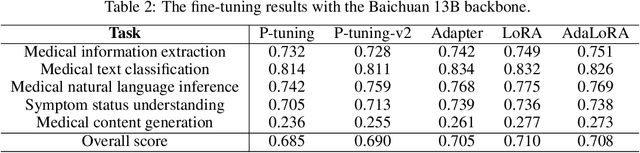
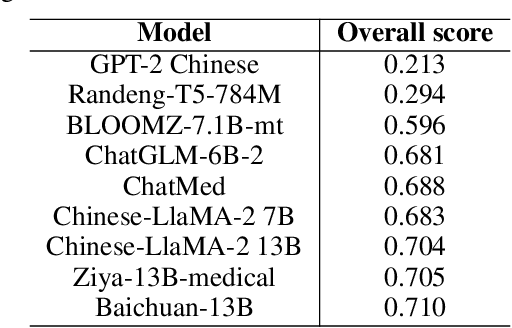
Biomedical language understanding benchmarks are the driving forces for artificial intelligence applications with large language model (LLM) back-ends. However, most current benchmarks: (a) are limited to English which makes it challenging to replicate many of the successes in English for other languages, or (b) focus on knowledge probing of LLMs and neglect to evaluate how LLMs apply these knowledge to perform on a wide range of bio-medical tasks, or (c) have become a publicly available corpus and are leaked to LLMs during pre-training. To facilitate the research in medical LLMs, we re-build the Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark into a large scale prompt-tuning benchmark, PromptCBLUE. Our benchmark is a suitable test-bed and an online platform for evaluating Chinese LLMs' multi-task capabilities on a wide range bio-medical tasks including medical entity recognition, medical text classification, medical natural language inference, medical dialogue understanding and medical content/dialogue generation. To establish evaluation on these tasks, we have experimented and report the results with the current 9 Chinese LLMs fine-tuned with differtent fine-tuning techniques.
Efficient Shapley Values Estimation by Amortization for Text Classification
May 31, 2023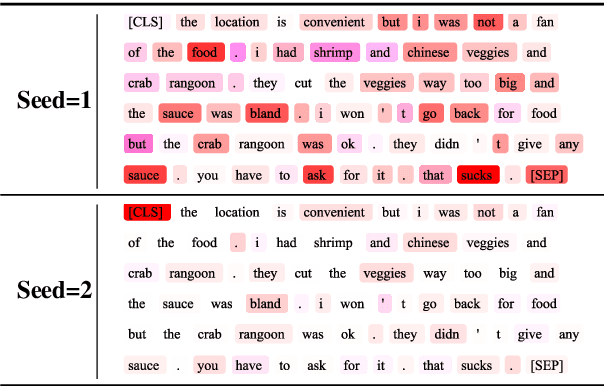
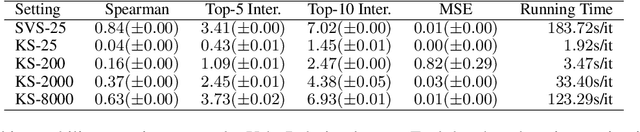
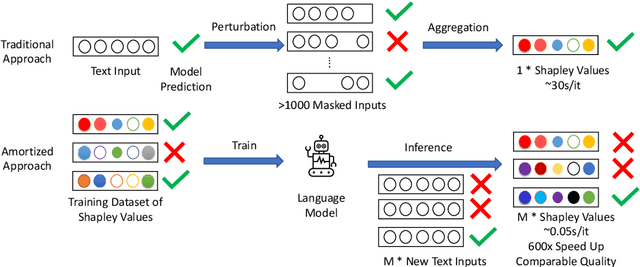
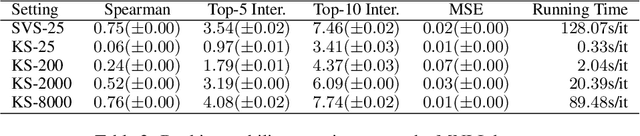
Despite the popularity of Shapley Values in explaining neural text classification models, computing them is prohibitive for large pretrained models due to a large number of model evaluations. In practice, Shapley Values are often estimated with a small number of stochastic model evaluations. However, we show that the estimated Shapley Values are sensitive to random seed choices -- the top-ranked features often have little overlap across different seeds, especially on examples with longer input texts. This can only be mitigated by aggregating thousands of model evaluations, which on the other hand, induces substantial computational overheads. To mitigate the trade-off between stability and efficiency, we develop an amortized model that directly predicts each input feature's Shapley Value without additional model evaluations. It is trained on a set of examples whose Shapley Values are estimated from a large number of model evaluations to ensure stability. Experimental results on two text classification datasets demonstrate that our amortized model estimates Shapley Values accurately with up to 60 times speedup compared to traditional methods. Furthermore, the estimated values are stable as the inference is deterministic. We release our code at https://github.com/yangalan123/Amortized-Interpretability.
nlpBDpatriots at BLP-2023 Task 1: A Two-Step Classification for Violence Inciting Text Detection in Bangla
Nov 25, 2023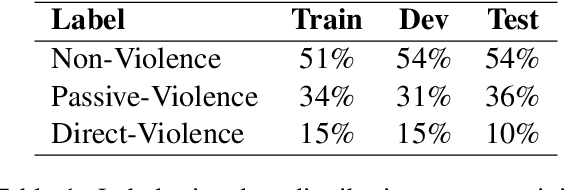
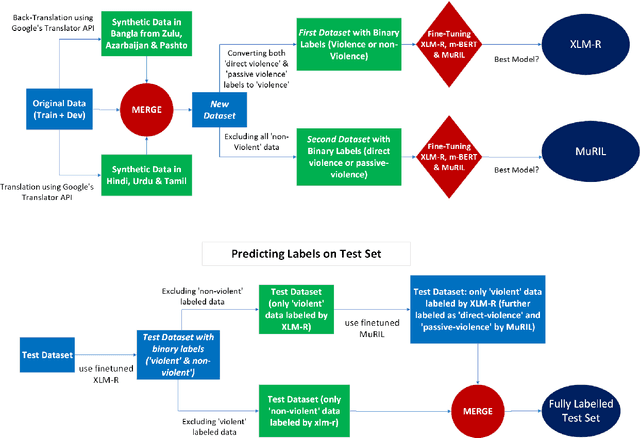
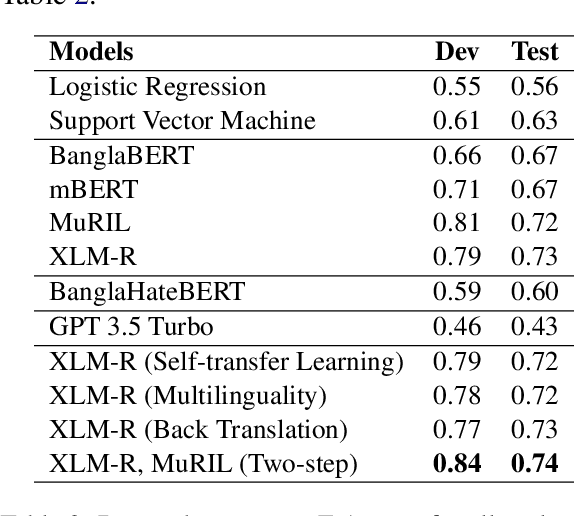
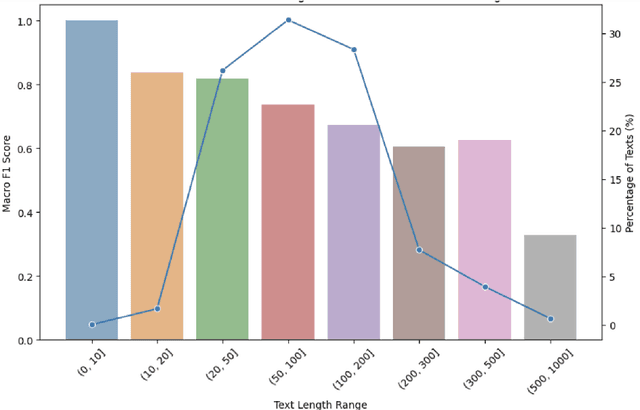
In this paper, we discuss the nlpBDpatriots entry to the shared task on Violence Inciting Text Detection (VITD) organized as part of the first workshop on Bangla Language Processing (BLP) co-located with EMNLP. The aim of this task is to identify and classify the violent threats, that provoke further unlawful violent acts. Our best-performing approach for the task is two-step classification using back translation and multilinguality which ranked 6th out of 27 teams with a macro F1 score of 0.74.