 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
SCLIP: Rethinking Self-Attention for Dense Vision-Language Inference
Dec 04, 2023
Recent advances in contrastive language-image pretraining (CLIP) have demonstrated strong capabilities in zero-shot classification by aligning visual representations with target text embeddings in an image level. However, in dense prediction tasks, CLIP often struggles to localize visual features within an image and fails to give accurate pixel-level predictions, which prevents it from functioning as a generalized visual foundation model. In this work, we aim to enhance CLIP's potential for semantic segmentation with minimal modifications to its pretrained models. By rethinking self-attention, we surprisingly find that CLIP can adapt to dense prediction tasks by simply introducing a novel Correlative Self-Attention (CSA) mechanism. Specifically, we replace the traditional self-attention block of CLIP vision encoder's last layer by our CSA module and reuse its pretrained projection matrices of query, key, and value, leading to a training-free adaptation approach for CLIP's zero-shot semantic segmentation. Extensive experiments show the advantage of CSA: we obtain a 38.2% average zero-shot mIoU across eight semantic segmentation benchmarks highlighted in this paper, significantly outperforming the existing SoTA's 33.9% and the vanilla CLIP's 14.1%.
Pushdown Layers: Encoding Recursive Structure in Transformer Language Models
Oct 29, 2023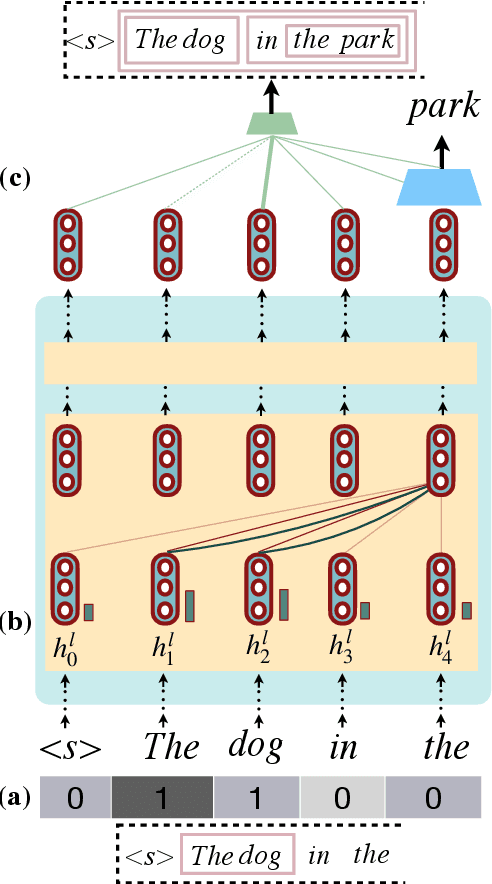
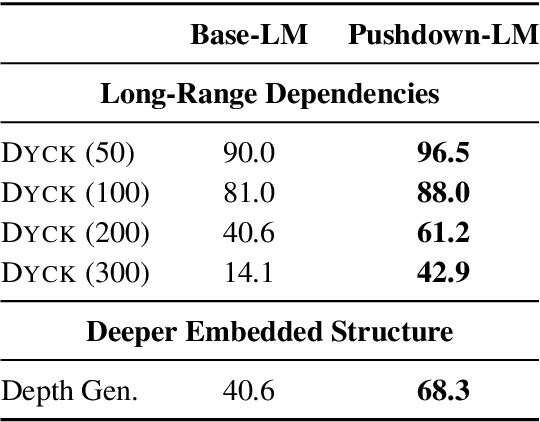
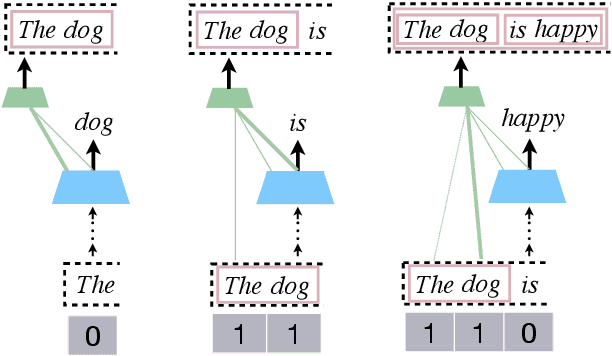
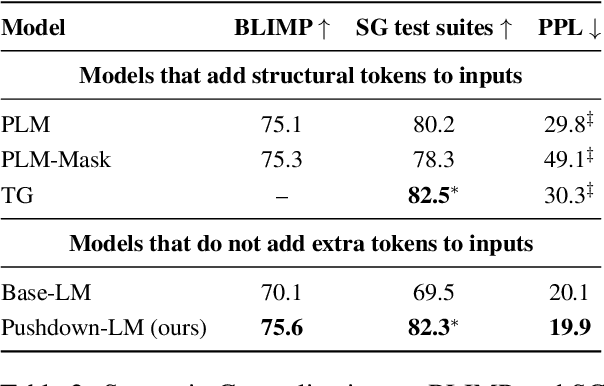
Recursion is a prominent feature of human language, and fundamentally challenging for self-attention due to the lack of an explicit recursive-state tracking mechanism. Consequently, Transformer language models poorly capture long-tail recursive structure and exhibit sample-inefficient syntactic generalization. This work introduces Pushdown Layers, a new self-attention layer that models recursive state via a stack tape that tracks estimated depths of every token in an incremental parse of the observed prefix. Transformer LMs with Pushdown Layers are syntactic language models that autoregressively and synchronously update this stack tape as they predict new tokens, in turn using the stack tape to softly modulate attention over tokens -- for instance, learning to "skip" over closed constituents. When trained on a corpus of strings annotated with silver constituency parses, Transformers equipped with Pushdown Layers achieve dramatically better and 3-5x more sample-efficient syntactic generalization, while maintaining similar perplexities. Pushdown Layers are a drop-in replacement for standard self-attention. We illustrate this by finetuning GPT2-medium with Pushdown Layers on an automatically parsed WikiText-103, leading to improvements on several GLUE text classification tasks.
On the Interplay between Fairness and Explainability
Oct 25, 2023In order to build reliable and trustworthy NLP applications, models need to be both fair across different demographics and explainable. Usually these two objectives, fairness and explainability, are optimized and/or examined independently of each other. Instead, we argue that forthcoming, trustworthy NLP systems should consider both. In this work, we perform a first study to understand how they influence each other: do fair(er) models rely on more plausible rationales? and vice versa. To this end, we conduct experiments on two English multi-class text classification datasets, BIOS and ECtHR, that provide information on gender and nationality, respectively, as well as human-annotated rationales. We fine-tune pre-trained language models with several methods for (i) bias mitigation, which aims to improve fairness; (ii) rationale extraction, which aims to produce plausible explanations. We find that bias mitigation algorithms do not always lead to fairer models. Moreover, we discover that empirical fairness and explainability are orthogonal.
Enhancing Sentiment Analysis Results through Outlier Detection Optimization
Nov 25, 2023When dealing with text data containing subjective labels like speaker emotions, inaccuracies or discrepancies among labelers are not uncommon. Such discrepancies can significantly affect the performance of machine learning algorithms. This study investigates the potential of identifying and addressing outliers in text data with subjective labels, aiming to enhance classification outcomes. We utilized the Deep SVDD algorithm, a one-class classification method, to detect outliers in nine text-based emotion and sentiment analysis datasets. By employing both a small-sized language model (DistilBERT base model with 66 million parameters) and non-deep learning machine learning algorithms (decision tree, KNN, Logistic Regression, and LDA) as the classifier, our findings suggest that the removal of outliers can lead to enhanced results in most cases. Additionally, as outliers in such datasets are not necessarily unlearnable, we experienced utilizing a large language model -- DeBERTa v3 large with 131 million parameters, which can capture very complex patterns in data. We continued to observe performance enhancements across multiple datasets.
Deep Multimodal Fusion for Surgical Feedback Classification
Dec 06, 2023Quantification of real-time informal feedback delivered by an experienced surgeon to a trainee during surgery is important for skill improvements in surgical training. Such feedback in the live operating room is inherently multimodal, consisting of verbal conversations (e.g., questions and answers) as well as non-verbal elements (e.g., through visual cues like pointing to anatomic elements). In this work, we leverage a clinically-validated five-category classification of surgical feedback: "Anatomic", "Technical", "Procedural", "Praise" and "Visual Aid". We then develop a multi-label machine learning model to classify these five categories of surgical feedback from inputs of text, audio, and video modalities. The ultimate goal of our work is to help automate the annotation of real-time contextual surgical feedback at scale. Our automated classification of surgical feedback achieves AUCs ranging from 71.5 to 77.6 with the fusion improving performance by 3.1%. We also show that high-quality manual transcriptions of feedback audio from experts improve AUCs to between 76.5 and 96.2, which demonstrates a clear path toward future improvements. Empirically, we find that the Staged training strategy, with first pre-training each modality separately and then training them jointly, is more effective than training different modalities altogether. We also present intuitive findings on the importance of modalities for different feedback categories. This work offers an important first look at the feasibility of automated classification of real-world live surgical feedback based on text, audio, and video modalities.
CLIPC8: Face liveness detection algorithm based on image-text pairs and contrastive learning
Nov 29, 2023Face recognition technology is widely used in the financial field, and various types of liveness attack behaviors need to be addressed. Existing liveness detection algorithms are trained on specific training datasets and tested on testing datasets, but their performance and robustness in transferring to unseen datasets are relatively poor. To tackle this issue, we propose a face liveness detection method based on image-text pairs and contrastive learning, dividing liveness attack problems in the financial field into eight categories and using text information to describe the images of these eight types of attacks. The text encoder and image encoder are used to extract feature vector representations for the classification description text and face images, respectively. By maximizing the similarity of positive samples and minimizing the similarity of negative samples, the model learns shared representations between images and texts. The proposed method is capable of effectively detecting specific liveness attack behaviors in certain scenarios, such as those occurring in dark environments or involving the tampering of ID card photos. Additionally, it is also effective in detecting traditional liveness attack methods, such as printing photo attacks and screen remake attacks. The zero-shot capabilities of face liveness detection on five public datasets, including NUAA, CASIA-FASD, Replay-Attack, OULU-NPU and MSU-MFSD also reaches the level of commercial algorithms. The detection capability of proposed algorithm was verified on 5 types of testing datasets, and the results show that the method outperformed commercial algorithms, and the detection rates reached 100% on multiple datasets. Demonstrating the effectiveness and robustness of introducing image-text pairs and contrastive learning into liveness detection tasks as proposed in this paper.
Graph Neural Networks for Text Classification: A Survey
Apr 23, 2023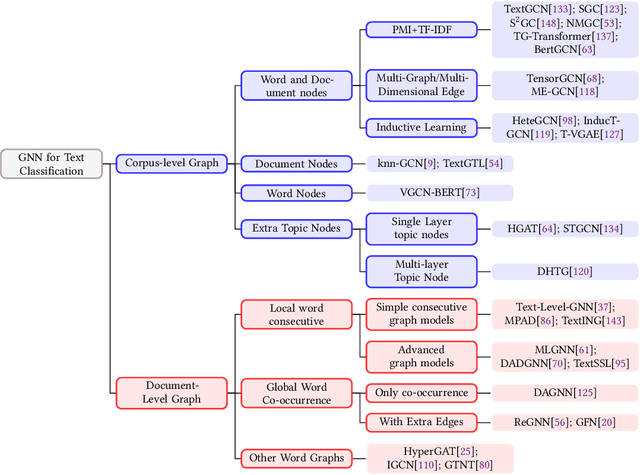
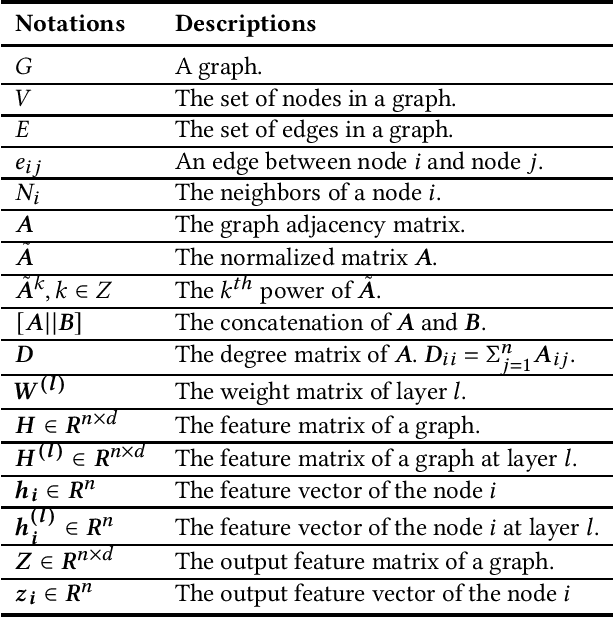
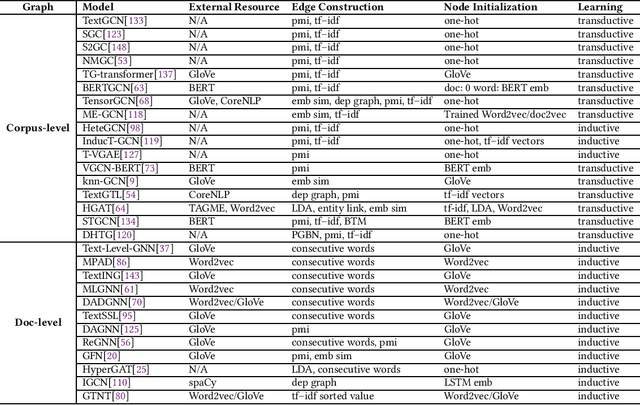
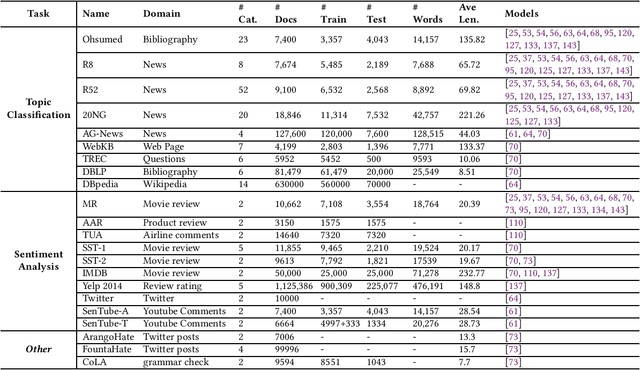
Text Classification is the most essential and fundamental problem in Natural Language Processing. While numerous recent text classification models applied the sequential deep learning technique, graph neural network-based models can directly deal with complex structured text data and exploit global information. Many real text classification applications can be naturally cast into a graph, which captures words, documents, and corpus global features. In this survey, we bring the coverage of methods up to 2023, including corpus-level and document-level graph neural networks. We discuss each of these methods in detail, dealing with the graph construction mechanisms and the graph-based learning process. As well as the technological survey, we look at issues behind and future directions addressed in text classification using graph neural networks. We also cover datasets, evaluation metrics, and experiment design and present a summary of published performance on the publicly available benchmarks. Note that we present a comprehensive comparison between different techniques and identify the pros and cons of various evaluation metrics in this survey.
Cross Encoding as Augmentation: Towards Effective Educational Text Classification
May 31, 2023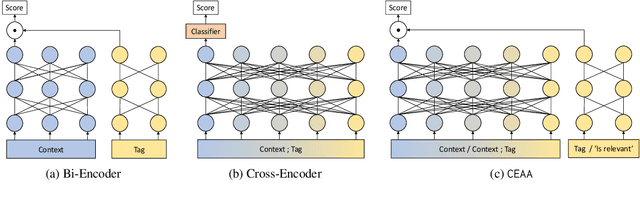
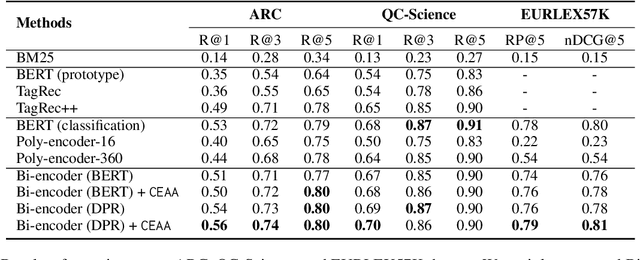
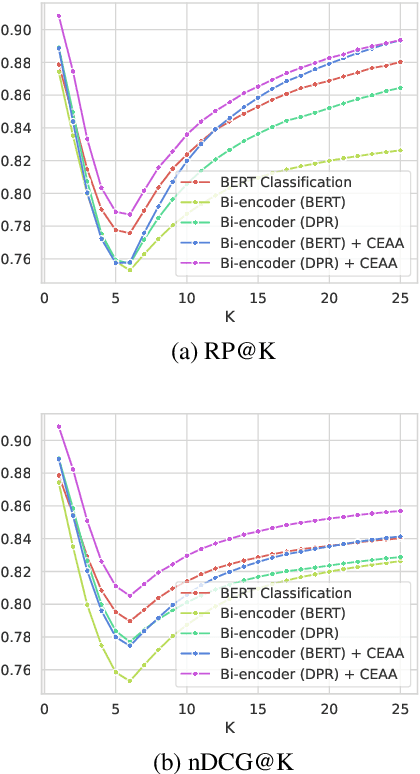
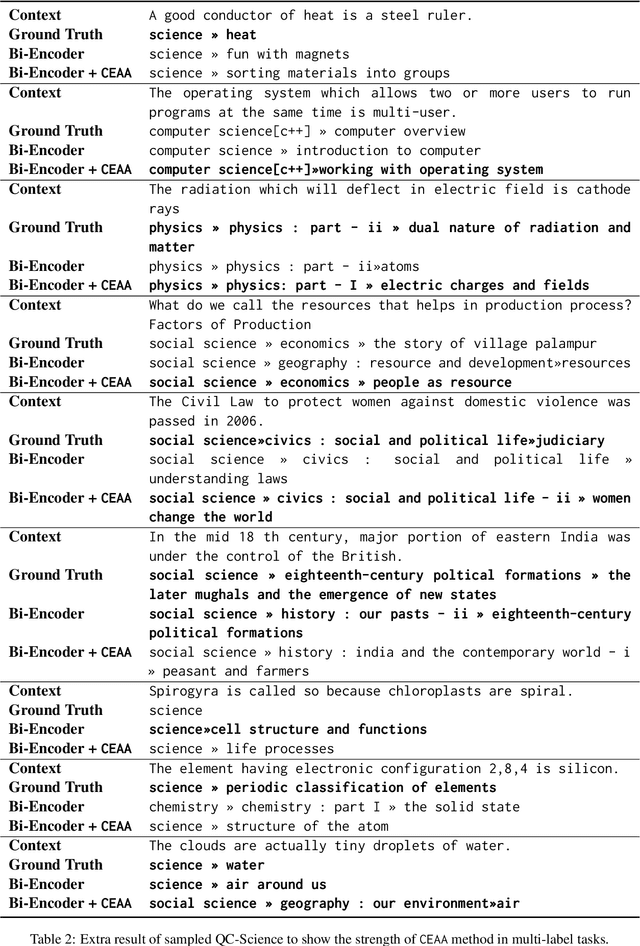
Text classification in education, usually called auto-tagging, is the automated process of assigning relevant tags to educational content, such as questions and textbooks. However, auto-tagging suffers from a data scarcity problem, which stems from two major challenges: 1) it possesses a large tag space and 2) it is multi-label. Though a retrieval approach is reportedly good at low-resource scenarios, there have been fewer efforts to directly address the data scarcity problem. To mitigate these issues, here we propose a novel retrieval approach CEAA that provides effective learning in educational text classification. Our main contributions are as follows: 1) we leverage transfer learning from question-answering datasets, and 2) we propose a simple but effective data augmentation method introducing cross-encoder style texts to a bi-encoder architecture for more efficient inference. An extensive set of experiments shows that our proposed method is effective in multi-label scenarios and low-resource tags compared to state-of-the-art models.
BYOC: Personalized Few-Shot Classification with Co-Authored Class Descriptions
Oct 09, 2023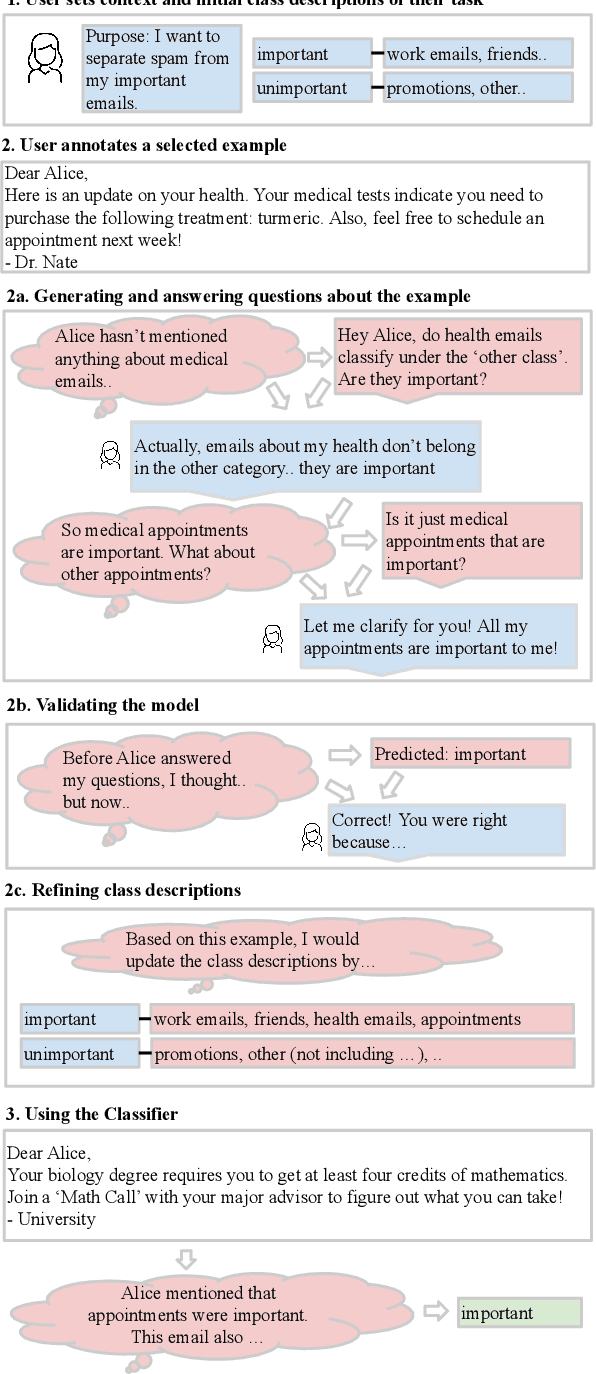
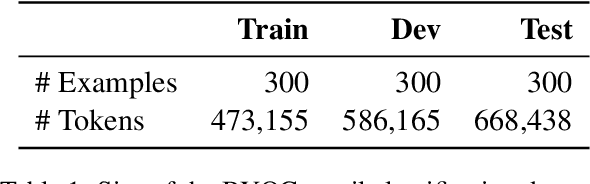
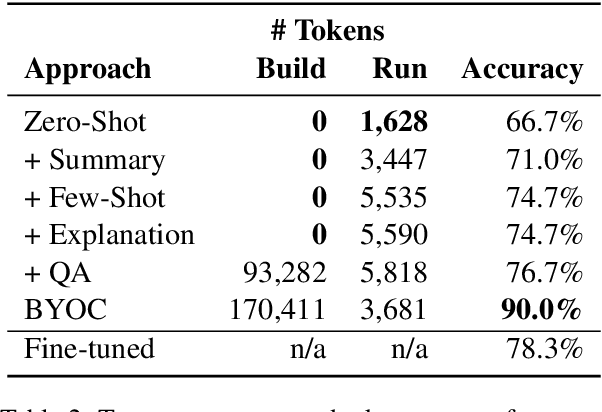
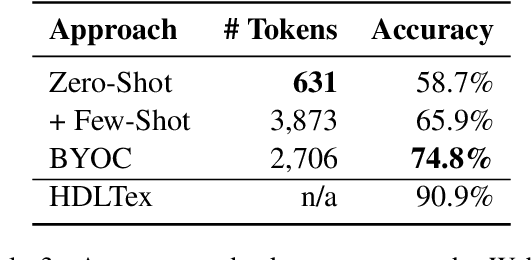
Text classification is a well-studied and versatile building block for many NLP applications. Yet, existing approaches require either large annotated corpora to train a model with or, when using large language models as a base, require carefully crafting the prompt as well as using a long context that can fit many examples. As a result, it is not possible for end-users to build classifiers for themselves. To address this issue, we propose a novel approach to few-shot text classification using an LLM. Rather than few-shot examples, the LLM is prompted with descriptions of the salient features of each class. These descriptions are coauthored by the user and the LLM interactively: while the user annotates each few-shot example, the LLM asks relevant questions that the user answers. Examples, questions, and answers are summarized to form the classification prompt. Our experiments show that our approach yields high accuracy classifiers, within 82% of the performance of models trained with significantly larger datasets while using only 1% of their training sets. Additionally, in a study with 30 participants, we show that end-users are able to build classifiers to suit their specific needs. The personalized classifiers show an average accuracy of 90%, which is 15% higher than the state-of-the-art approach.
Rank-Aware Negative Training for Semi-Supervised Text Classification
Jun 13, 2023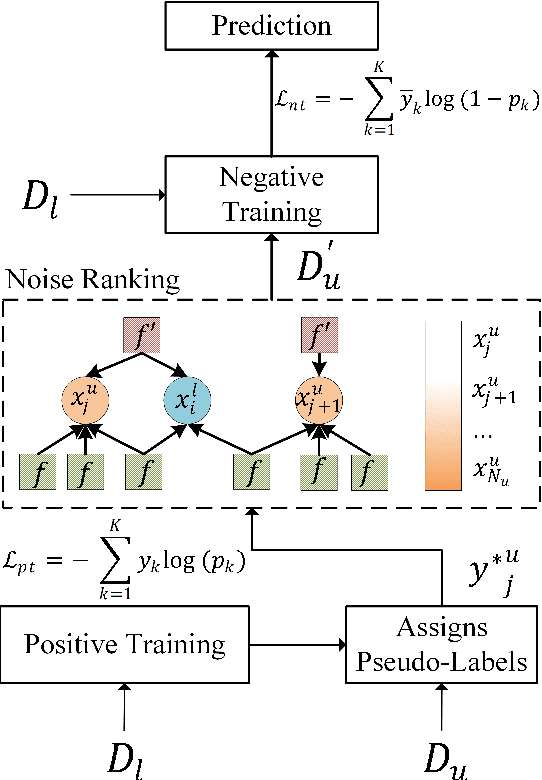
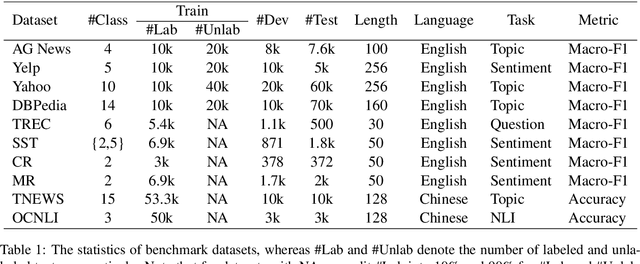
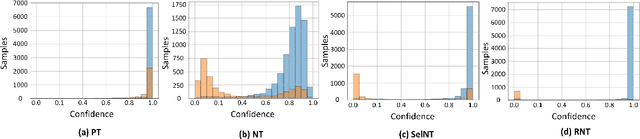
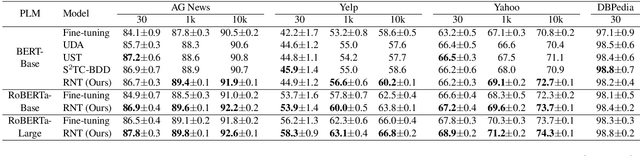
Semi-supervised text classification-based paradigms (SSTC) typically employ the spirit of self-training. The key idea is to train a deep classifier on limited labeled texts and then iteratively predict the unlabeled texts as their pseudo-labels for further training. However, the performance is largely affected by the accuracy of pseudo-labels, which may not be significant in real-world scenarios. This paper presents a Rank-aware Negative Training (RNT) framework to address SSTC in learning with noisy label manner. To alleviate the noisy information, we adapt a reasoning with uncertainty-based approach to rank the unlabeled texts based on the evidential support received from the labeled texts. Moreover, we propose the use of negative training to train RNT based on the concept that ``the input instance does not belong to the complementary label''. A complementary label is randomly selected from all labels except the label on-target. Intuitively, the probability of a true label serving as a complementary label is low and thus provides less noisy information during the training, resulting in better performance on the test data. Finally, we evaluate the proposed solution on various text classification benchmark datasets. Our extensive experiments show that it consistently overcomes the state-of-the-art alternatives in most scenarios and achieves competitive performance in the others. The code of RNT is publicly available at:https://github.com/amurtadha/RNT.