 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
VIBE: Topic-Driven Temporal Adaptation for Twitter Classification
Nov 04, 2023
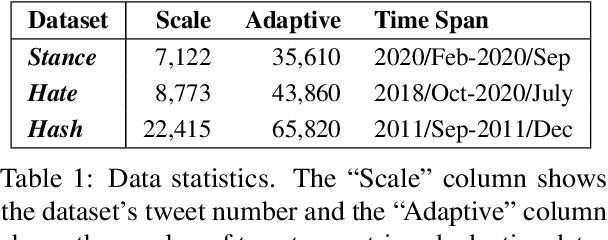
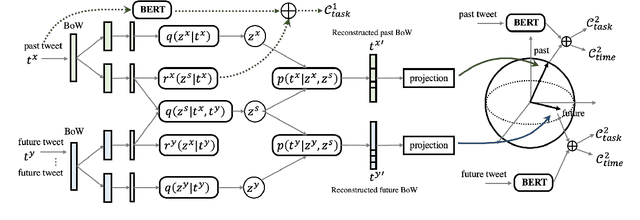
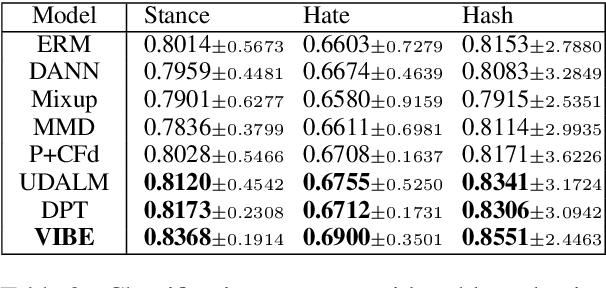
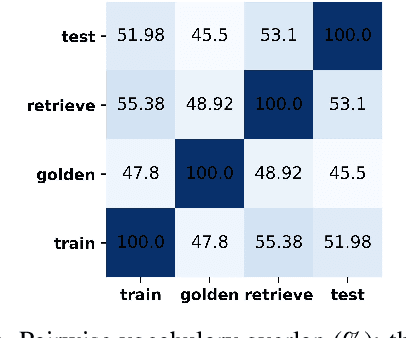
Language features are evolving in real-world social media, resulting in the deteriorating performance of text classification in dynamics. To address this challenge, we study temporal adaptation, where models trained on past data are tested in the future. Most prior work focused on continued pretraining or knowledge updating, which may compromise their performance on noisy social media data. To tackle this issue, we reflect feature change via modeling latent topic evolution and propose a novel model, VIBE: Variational Information Bottleneck for Evolutions. Concretely, we first employ two Information Bottleneck (IB) regularizers to distinguish past and future topics. Then, the distinguished topics work as adaptive features via multi-task training with timestamp and class label prediction. In adaptive learning, VIBE utilizes retrieved unlabeled data from online streams created posterior to training data time. Substantial Twitter experiments on three classification tasks show that our model, with only 3% of data, significantly outperforms previous state-of-the-art continued-pretraining methods.
* accepted by EMNLP 2023
A Simple yet Efficient Ensemble Approach for AI-generated Text Detection
Nov 08, 2023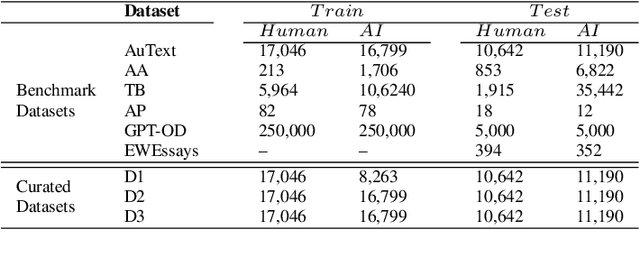
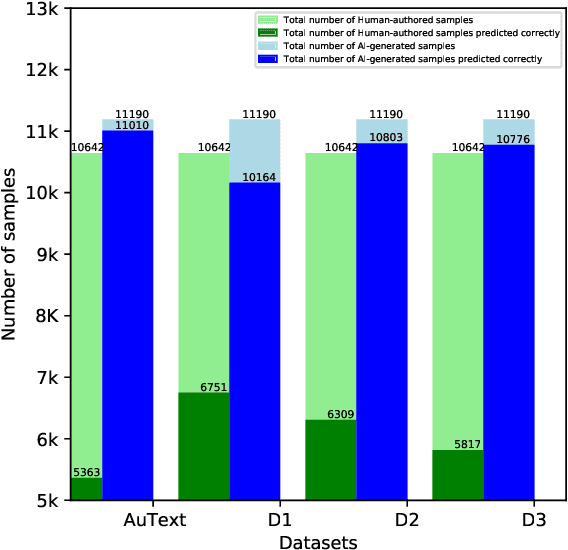
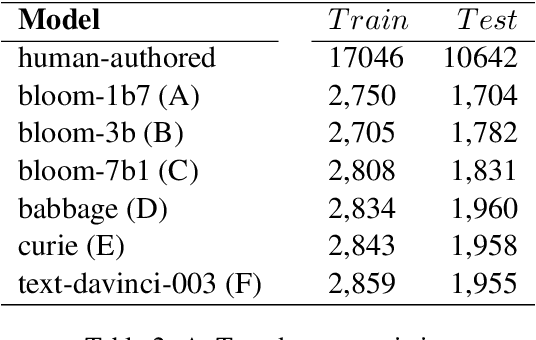
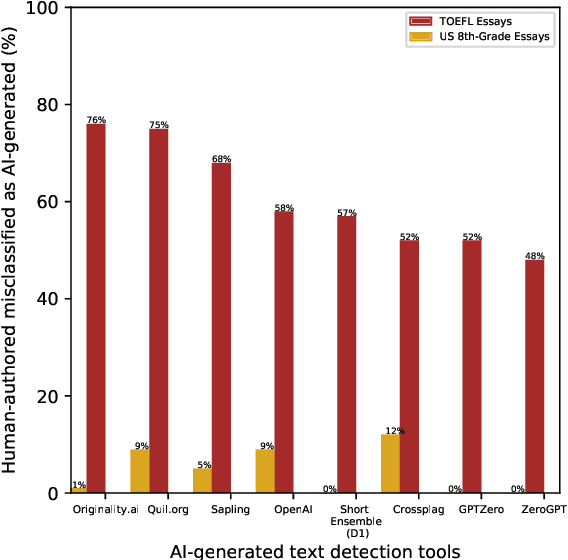
Recent Large Language Models (LLMs) have demonstrated remarkable capabilities in generating text that closely resembles human writing across wide range of styles and genres. However, such capabilities are prone to potential abuse, such as fake news generation, spam email creation, and misuse in academic assignments. Hence, it is essential to build automated approaches capable of distinguishing between artificially generated text and human-authored text. In this paper, we propose a simple yet efficient solution to this problem by ensembling predictions from multiple constituent LLMs. Compared to previous state-of-the-art approaches, which are perplexity-based or uses ensembles with a number of LLMs, our condensed ensembling approach uses only two constituent LLMs to achieve comparable performance. Experiments conducted on four benchmark datasets for generative text classification show performance improvements in the range of 0.5 to 100\% compared to previous state-of-the-art approaches. We also study the influence that the training data from individual LLMs have on model performance. We found that substituting commercially-restrictive Generative Pre-trained Transformer (GPT) data with data generated from other open language models such as Falcon, Large Language Model Meta AI (LLaMA2), and Mosaic Pretrained Transformers (MPT) is a feasible alternative when developing generative text detectors. Furthermore, to demonstrate zero-shot generalization, we experimented with an English essays dataset, and results suggest that our ensembling approach can handle new data effectively.
Description-Enhanced Label Embedding Contrastive Learning for Text Classification
Jun 15, 2023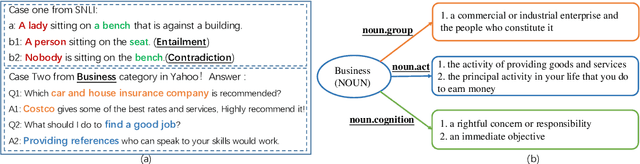
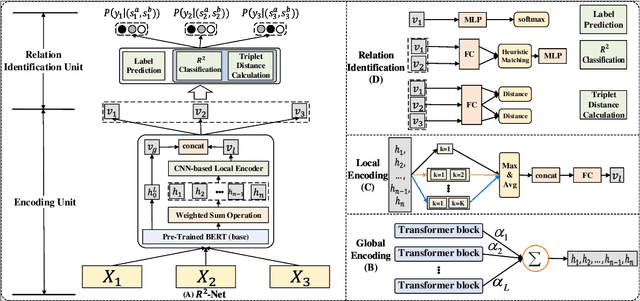
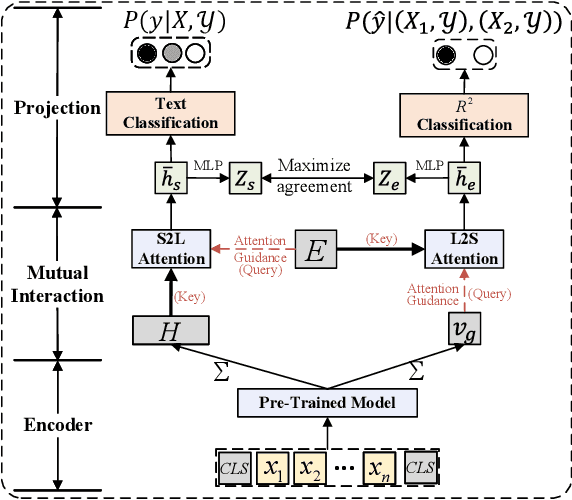
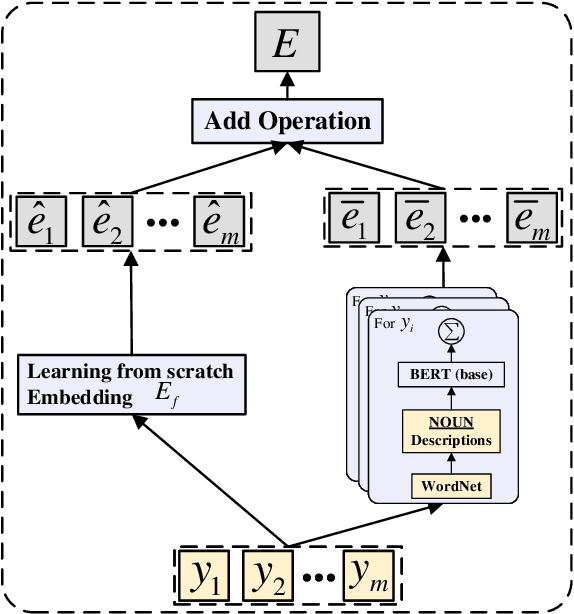
Text Classification is one of the fundamental tasks in natural language processing, which requires an agent to determine the most appropriate category for input sentences. Recently, deep neural networks have achieved impressive performance in this area, especially Pre-trained Language Models (PLMs). Usually, these methods concentrate on input sentences and corresponding semantic embedding generation. However, for another essential component: labels, most existing works either treat them as meaningless one-hot vectors or use vanilla embedding methods to learn label representations along with model training, underestimating the semantic information and guidance that these labels reveal. To alleviate this problem and better exploit label information, in this paper, we employ Self-Supervised Learning (SSL) in model learning process and design a novel self-supervised Relation of Relation (R2) classification task for label utilization from a one-hot manner perspective. Then, we propose a novel Relation of Relation Learning Network (R2-Net) for text classification, in which text classification and R2 classification are treated as optimization targets. Meanwhile, triplet loss is employed to enhance the analysis of differences and connections among labels. Moreover, considering that one-hot usage is still short of exploiting label information, we incorporate external knowledge from WordNet to obtain multi-aspect descriptions for label semantic learning and extend R2-Net to a novel Description-Enhanced Label Embedding network (DELE) from a label embedding perspective. ...
Implementation and Comparison of Methods to Extract Reliability KPIs out of Textual Wind Turbine Maintenance Work Orders
Nov 07, 2023Maintenance work orders are commonly used to document information about wind turbine operation and maintenance. This includes details about proactive and reactive wind turbine downtimes, such as preventative and corrective maintenance. However, the information contained in maintenance work orders is often unstructured and difficult to analyze, making it challenging for decision-makers to use this information for optimizing operation and maintenance. To address this issue, this work presents three different approaches to calculate reliability key performance indicators from maintenance work orders. The first approach involves manual labeling of the maintenance work orders by domain experts, using the schema defined in an industrial guideline to assign the label accordingly. The second approach involves the development of a model that automatically labels the maintenance work orders using text classification methods. The third technique uses an AI-assisted tagging tool to tag and structure the raw maintenance information contained in the maintenance work orders. The resulting calculated reliability key performance indicator of the first approach are used as a benchmark for comparison with the results of the second and third approaches. The quality and time spent are considered as criteria for evaluation. Overall, these three methods make extracting maintenance information from maintenance work orders more efficient, enable the assessment of reliability key performance indicators and therefore support the optimization of wind turbine operation and maintenance.
PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Dec 08, 2023The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
Leveraging Artificial Intelligence Technology for Mapping Research to Sustainable Development Goals: A Case Study
Nov 09, 2023The number of publications related to the Sustainable Development Goals (SDGs) continues to grow. These publications cover a diverse spectrum of research, from humanities and social sciences to engineering and health. Given the imperative of funding bodies to monitor outcomes and impacts, linking publications to relevant SDGs is critical but remains time-consuming and difficult given the breadth and complexity of the SDGs. A publication may relate to several goals (interconnection feature of goals), and therefore require multidisciplinary knowledge to tag accurately. Machine learning approaches are promising and have proven particularly valuable for tasks such as manual data labeling and text classification. In this study, we employed over 82,000 publications from an Australian university as a case study. We utilized a similarity measure to map these publications onto Sustainable Development Goals (SDGs). Additionally, we leveraged the OpenAI GPT model to conduct the same task, facilitating a comparative analysis between the two approaches. Experimental results show that about 82.89% of the results obtained by the similarity measure overlap (at least one tag) with the outputs of the GPT model. The adopted model (similarity measure) can complement GPT model for SDG classification. Furthermore, deep learning methods, which include the similarity measure used here, are more accessible and trusted for dealing with sensitive data without the use of commercial AI services or the deployment of expensive computing resources to operate large language models. Our study demonstrates how a crafted combination of the two methods can achieve reliable results for mapping research to the SDGs.
Text Classification via Large Language Models
May 22, 2023
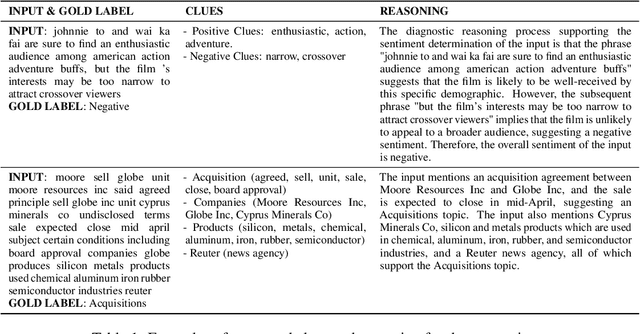

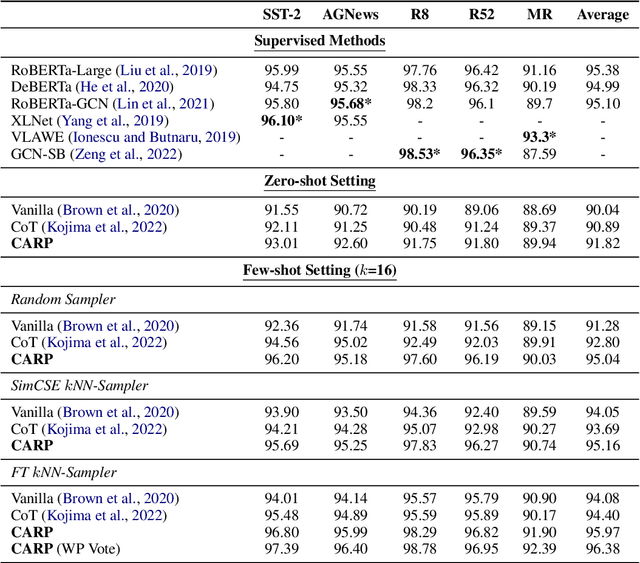
Despite the remarkable success of large-scale Language Models (LLMs) such as GPT-3, their performances still significantly underperform fine-tuned models in the task of text classification. This is due to (1) the lack of reasoning ability in addressing complex linguistic phenomena (e.g., intensification, contrast, irony etc); (2) limited number of tokens allowed in in-context learning. In this paper, we introduce Clue And Reasoning Prompting (CARP). CARP adopts a progressive reasoning strategy tailored to addressing the complex linguistic phenomena involved in text classification: CARP first prompts LLMs to find superficial clues (e.g., keywords, tones, semantic relations, references, etc), based on which a diagnostic reasoning process is induced for final decisions. To further address the limited-token issue, CARP uses a fine-tuned model on the supervised dataset for $k$NN demonstration search in the in-context learning, allowing the model to take the advantage of both LLM's generalization ability and the task-specific evidence provided by the full labeled dataset. Remarkably, CARP yields new SOTA performances on 4 out of 5 widely-used text-classification benchmarks, 97.39 (+1.24) on SST-2, 96.40 (+0.72) on AGNews, 98.78 (+0.25) on R8 and 96.95 (+0.6) on R52, and a performance comparable to SOTA on MR (92.39 v.s. 93.3). More importantly, we find that CARP delivers impressive abilities on low-resource and domain-adaptation setups. Specifically, using 16 examples per class, CARP achieves comparable performances to supervised models with 1,024 examples per class.
MetricPrompt: Prompting Model as a Relevance Metric for Few-shot Text Classification
Jun 15, 2023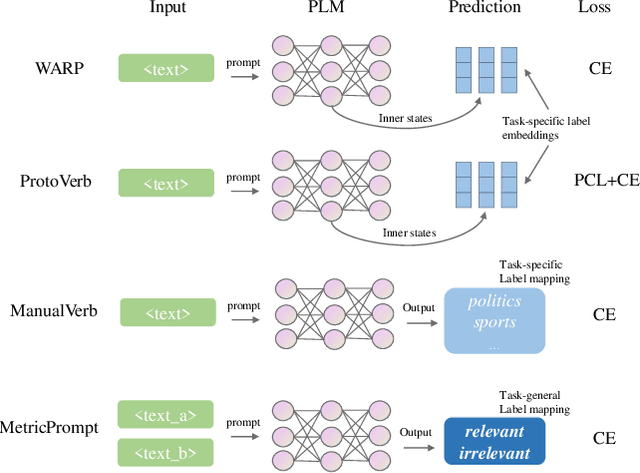
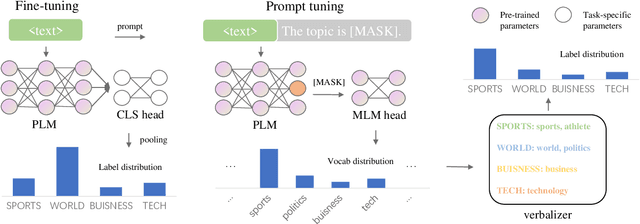
Prompting methods have shown impressive performance in a variety of text mining tasks and applications, especially few-shot ones. Despite the promising prospects, the performance of prompting model largely depends on the design of prompt template and verbalizer. In this work, we propose MetricPrompt, which eases verbalizer design difficulty by reformulating few-shot text classification task into text pair relevance estimation task. MetricPrompt adopts prompting model as the relevance metric, further bridging the gap between Pre-trained Language Model's (PLM) pre-training objective and text classification task, making possible PLM's smooth adaption. Taking a training sample and a query one simultaneously, MetricPrompt captures cross-sample relevance information for accurate relevance estimation. We conduct experiments on three widely used text classification datasets across four few-shot settings. Results show that MetricPrompt outperforms manual verbalizer and other automatic verbalizer design methods across all few-shot settings, achieving new state-of-the-art (SOTA) performance.
Manipulating the Label Space for In-Context Classification
Dec 06, 2023After pre-training by generating the next word conditional on previous words, the Language Model (LM) acquires the ability of In-Context Learning (ICL) that can learn a new task conditional on the context of the given in-context examples (ICEs). Similarly, visually-conditioned Language Modelling is also used to train Vision-Language Models (VLMs) with ICL ability. However, such VLMs typically exhibit weaker classification abilities compared to contrastive learning-based models like CLIP, since the Language Modelling objective does not directly contrast whether an object is paired with a text. To improve the ICL of classification, using more ICEs to provide more knowledge is a straightforward way. However, this may largely increase the selection time, and more importantly, the inclusion of additional in-context images tends to extend the length of the in-context sequence beyond the processing capacity of a VLM. To alleviate these limitations, we propose to manipulate the label space of each ICE to increase its knowledge density, allowing for fewer ICEs to convey as much information as a larger set would. Specifically, we propose two strategies which are Label Distribution Enhancement and Visual Descriptions Enhancement to improve In-context classification performance on diverse datasets, including the classic ImageNet and more fine-grained datasets like CUB-200. Specifically, using our approach on ImageNet, we increase accuracy from 74.70\% in a 4-shot setting to 76.21\% with just 2 shots. surpassing CLIP by 0.67\%. On CUB-200, our method raises 1-shot accuracy from 48.86\% to 69.05\%, 12.15\% higher than CLIP. The code is given in https://anonymous.4open.science/r/MLS_ICC.
WOT-Class: Weakly Supervised Open-world Text Classification
May 21, 2023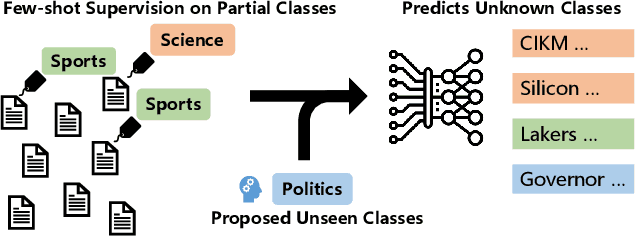

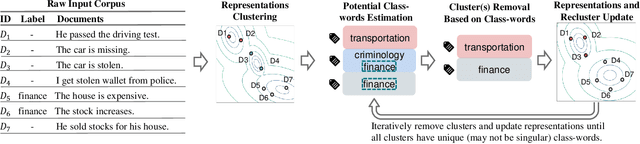
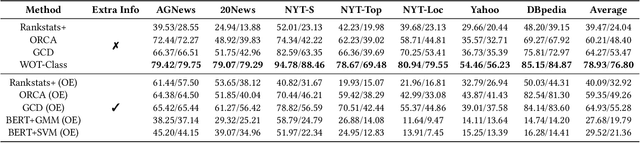
State-of-the-art weakly supervised text classification methods, while significantly reduced the required human supervision, still requires the supervision to cover all the classes of interest. This is never easy to meet in practice when human explore new, large corpora without complete pictures. In this paper, we work on a novel yet important problem of weakly supervised open-world text classification, where supervision is only needed for a few examples from a few known classes and the machine should handle both known and unknown classes in test time. General open-world classification has been studied mostly using image classification; however, existing methods typically assume the availability of sufficient known-class supervision and strong unknown-class prior knowledge (e.g., the number and/or data distribution). We propose a novel framework WOT-Class that lifts those strong assumptions. Specifically, it follows an iterative process of (a) clustering text to new classes, (b) mining and ranking indicative words for each class, and (c) merging redundant classes by using the overlapped indicative words as a bridge. Extensive experiments on 7 popular text classification datasets demonstrate that WOT-Class outperforms strong baselines consistently with a large margin, attaining 23.33% greater average absolute macro-F1 over existing approaches across all datasets. Such competent accuracy illuminates the practical potential of further reducing human effort for text classification.