 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
TransPrompt v2: A Transferable Prompting Framework for Cross-task Text Classification
Aug 29, 2023
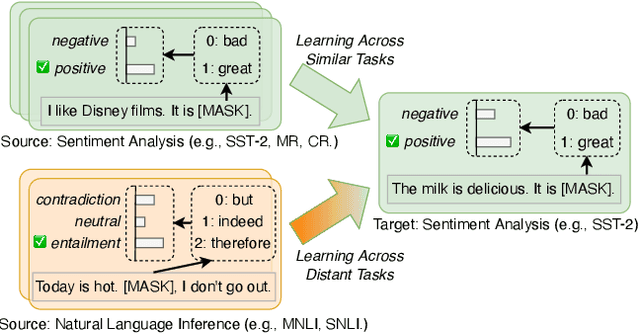
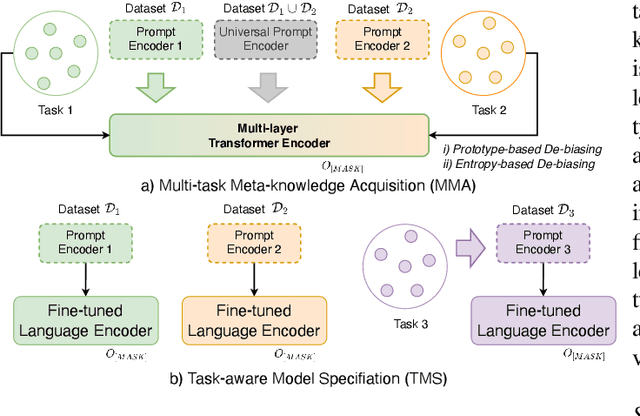
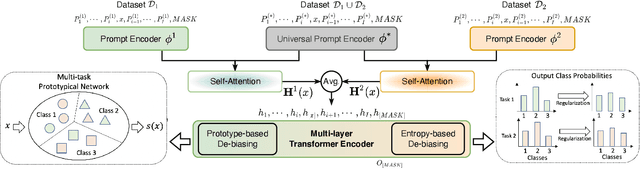
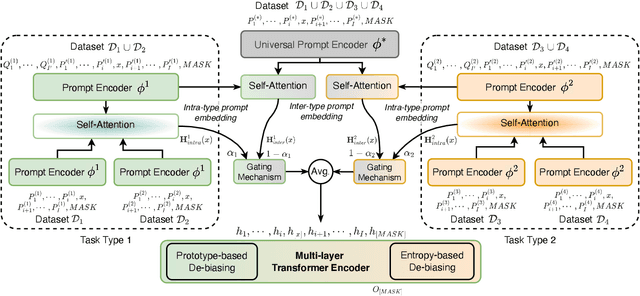
Text classification is one of the most imperative tasks in natural language processing (NLP). Recent advances with pre-trained language models (PLMs) have shown remarkable success on this task. However, the satisfying results obtained by PLMs heavily depend on the large amounts of task-specific labeled data, which may not be feasible in many application scenarios due to data access and privacy constraints. The recently-proposed prompt-based fine-tuning paradigm improves the performance of PLMs for few-shot text classification with task-specific templates. Yet, it is unclear how the prompting knowledge can be transferred across tasks, for the purpose of mutual reinforcement. We propose TransPrompt v2, a novel transferable prompting framework for few-shot learning across similar or distant text classification tasks. For learning across similar tasks, we employ a multi-task meta-knowledge acquisition (MMA) procedure to train a meta-learner that captures the cross-task transferable knowledge. For learning across distant tasks, we further inject the task type descriptions into the prompt, and capture the intra-type and inter-type prompt embeddings among multiple distant tasks. Additionally, two de-biasing techniques are further designed to make the trained meta-learner more task-agnostic and unbiased towards any tasks. After that, the meta-learner can be adapted to each specific task with better parameters initialization. Extensive experiments show that TransPrompt v2 outperforms single-task and cross-task strong baselines over multiple NLP tasks and datasets. We further show that the meta-learner can effectively improve the performance of PLMs on previously unseen tasks. In addition, TransPrompt v2 also outperforms strong fine-tuning baselines when learning with full training sets.
A Text Classification-Based Approach for Evaluating and Enhancing the Machine Interpretability of Building Codes
Sep 24, 2023
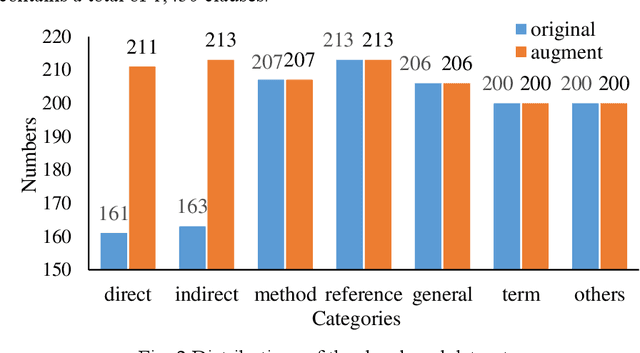
Interpreting regulatory documents or building codes into computer-processable formats is essential for the intelligent design and construction of buildings and infrastructures. Although automated rule interpretation (ARI) methods have been investigated for years, most of them highly depend on the early and manual filtering of interpretable clauses from a building code. While few of them considered machine interpretability, which represents the potential to be transformed into a computer-processable format, from both clause- and document-level. Therefore, this research aims to propose a novel approach to automatically evaluate and enhance the machine interpretability of single clause and building codes. First, a few categories are introduced to classify each clause in a building code considering the requirements for rule interpretation, and a dataset is developed for model training. Then, an efficient text classification model is developed based on a pretrained domain-specific language model and transfer learning techniques. Finally, a quantitative evaluation method is proposed to assess the overall interpretability of building codes. Experiments show that the proposed text classification algorithm outperforms the existing CNN- or RNN-based methods, improving the F1-score from 72.16% to 93.60%. It is also illustrated that the proposed classification method can enhance downstream ARI methods with an improvement of 4%. Furthermore, analyzing the results of more than 150 building codes in China showed that their average interpretability is 34.40%, which implies that it is still hard to fully transform the entire regulatory document into computer-processable formats. It is also argued that the interpretability of building codes should be further improved both from the human side and the machine side.
Gzip versus bag-of-words for text classification
Aug 08, 2023
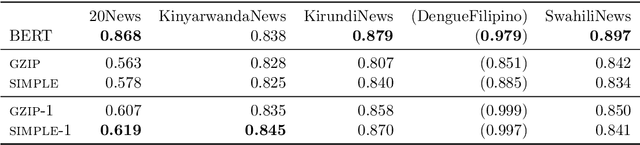
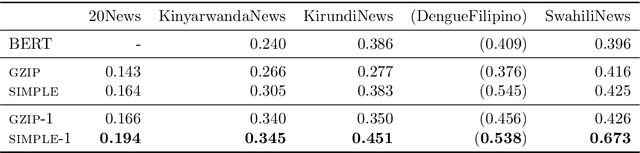
The effectiveness of compression in text classification ('gzip') has recently garnered lots of attention. In this note we show that `bag-of-words' approaches can achieve similar or better results, and are more efficient.
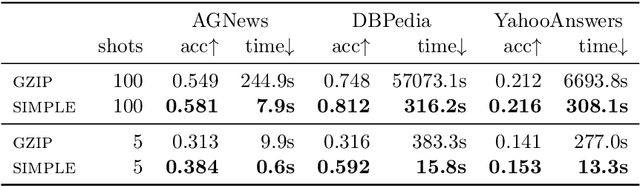
Making LLMs Worth Every Penny: Resource-Limited Text Classification in Banking
Nov 10, 2023
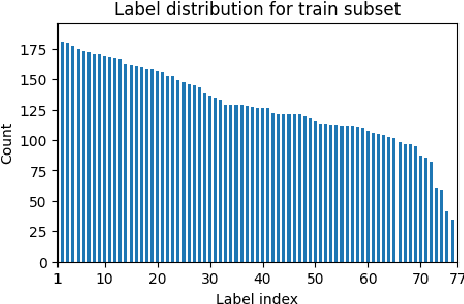
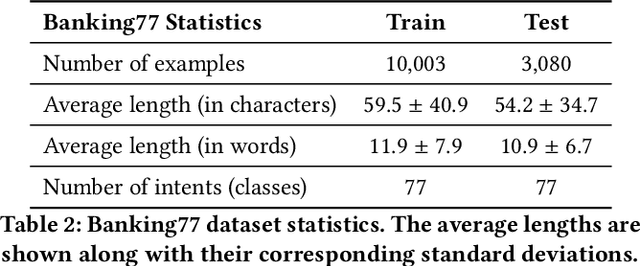

Standard Full-Data classifiers in NLP demand thousands of labeled examples, which is impractical in data-limited domains. Few-shot methods offer an alternative, utilizing contrastive learning techniques that can be effective with as little as 20 examples per class. Similarly, Large Language Models (LLMs) like GPT-4 can perform effectively with just 1-5 examples per class. However, the performance-cost trade-offs of these methods remain underexplored, a critical concern for budget-limited organizations. Our work addresses this gap by studying the aforementioned approaches over the Banking77 financial intent detection dataset, including the evaluation of cutting-edge LLMs by OpenAI, Cohere, and Anthropic in a comprehensive set of few-shot scenarios. We complete the picture with two additional methods: first, a cost-effective querying method for LLMs based on retrieval-augmented generation (RAG), able to reduce operational costs multiple times compared to classic few-shot approaches, and second, a data augmentation method using GPT-4, able to improve performance in data-limited scenarios. Finally, to inspire future research, we provide a human expert's curated subset of Banking77, along with extensive error analysis.
GIELLM: Japanese General Information Extraction Large Language Model Utilizing Mutual Reinforcement Effect
Nov 12, 2023Information Extraction (IE) stands as a cornerstone in natural language processing, traditionally segmented into distinct sub-tasks. The advent of Large Language Models (LLMs) heralds a paradigm shift, suggesting the feasibility of a singular model addressing multiple IE subtasks. In this vein, we introduce the General Information Extraction Large Language Model (GIELLM), which integrates text Classification, Sentiment Analysis, Named Entity Recognition, Relation Extraction, and Event Extraction using a uniform input-output schema. This innovation marks the first instance of a model simultaneously handling such a diverse array of IE subtasks. Notably, the GIELLM leverages the Mutual Reinforcement Effect (MRE), enhancing performance in integrated tasks compared to their isolated counterparts. Our experiments demonstrate State-of-the-Art (SOTA) results in five out of six Japanese mixed datasets, significantly surpassing GPT-3.5-Turbo. Further, an independent evaluation using the novel Text Classification Relation and Event Extraction(TCREE) dataset corroborates the synergistic advantages of MRE in text and word classification. This breakthrough paves the way for most IE subtasks to be subsumed under a singular LLM framework. Specialized fine-tune task-specific models are no longer needed.
Recent Advances in Hierarchical Multi-label Text Classification: A Survey
Jul 30, 2023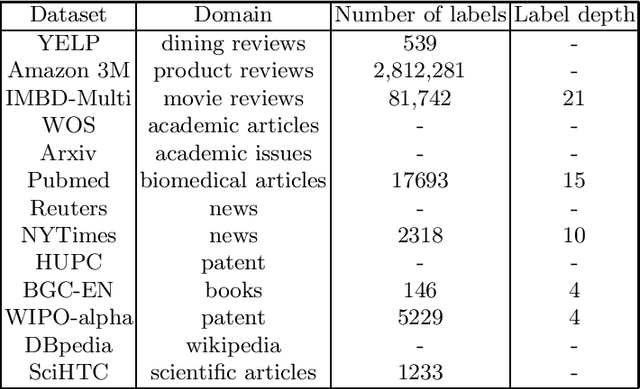
Hierarchical multi-label text classification aims to classify the input text into multiple labels, among which the labels are structured and hierarchical. It is a vital task in many real world applications, e.g. scientific literature archiving. In this paper, we survey the recent progress of hierarchical multi-label text classification, including the open sourced data sets, the main methods, evaluation metrics, learning strategies and the current challenges. A few future research directions are also listed for community to further improve this field.
Prompt Tuning on Graph-augmented Low-resource Text Classification
Jul 15, 2023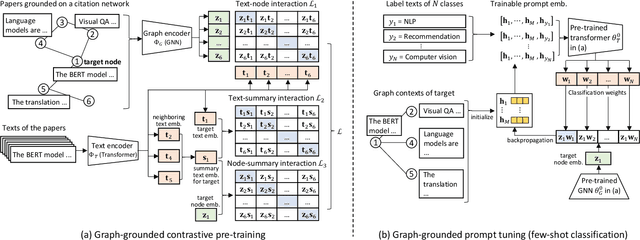
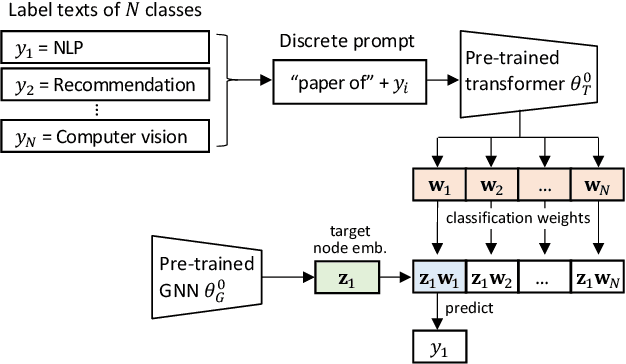
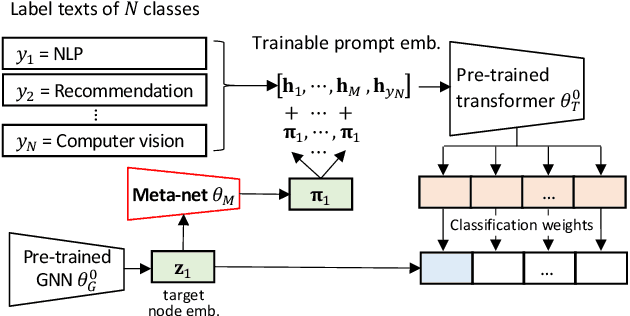
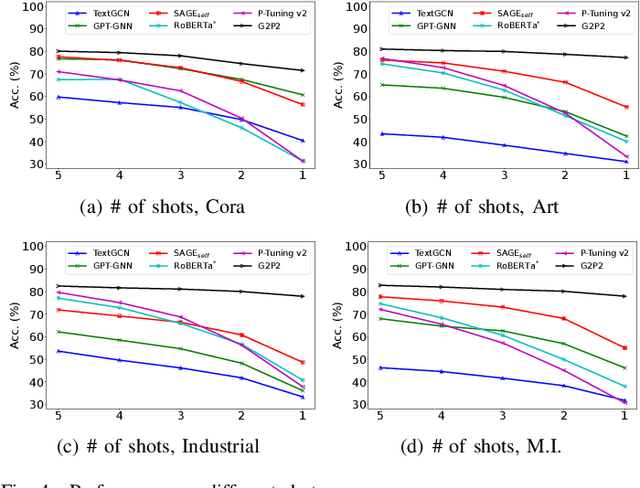
Text classification is a fundamental problem in information retrieval with many real-world applications, such as predicting the topics of online articles and the categories of e-commerce product descriptions. However, low-resource text classification, with no or few labeled samples, presents a serious concern for supervised learning. Meanwhile, many text data are inherently grounded on a network structure, such as a hyperlink/citation network for online articles, and a user-item purchase network for e-commerce products. These graph structures capture rich semantic relationships, which can potentially augment low-resource text classification. In this paper, we propose a novel model called Graph-Grounded Pre-training and Prompting (G2P2) to address low-resource text classification in a two-pronged approach. During pre-training, we propose three graph interaction-based contrastive strategies to jointly pre-train a graph-text model; during downstream classification, we explore handcrafted discrete prompts and continuous prompt tuning for the jointly pre-trained model to achieve zero- and few-shot classification, respectively. Besides, for generalizing continuous prompts to unseen classes, we propose conditional prompt tuning on graphs (G2P2$^*$). Extensive experiments on four real-world datasets demonstrate the strength of G2P2 in zero- and few-shot low-resource text classification tasks, and illustrate the advantage of G2P2$^*$ in dealing with unseen classes.
DP-AdamBC: Your DP-Adam Is Actually DP-SGD (Unless You Apply Bias Correction)
Dec 21, 2023The Adam optimizer is a popular choice in contemporary deep learning, due to its strong empirical performance. However we observe that in privacy sensitive scenarios, the traditional use of Differential Privacy (DP) with the Adam optimizer leads to sub-optimal performance on several tasks. We find that this performance degradation is due to a DP bias in Adam's second moment estimator, introduced by the addition of independent noise in the gradient computation to enforce DP guarantees. This DP bias leads to a different scaling for low variance parameter updates, that is inconsistent with the behavior of non-private Adam. We propose DP-AdamBC, an optimization algorithm which removes the bias in the second moment estimation and retrieves the expected behaviour of Adam. Empirically, DP-AdamBC significantly improves the optimization performance of DP-Adam by up to 3.5% in final accuracy in image, text, and graph node classification tasks.
Exploring Machine Learning and Transformer-based Approaches for Deceptive Text Classification: A Comparative Analysis
Aug 11, 2023
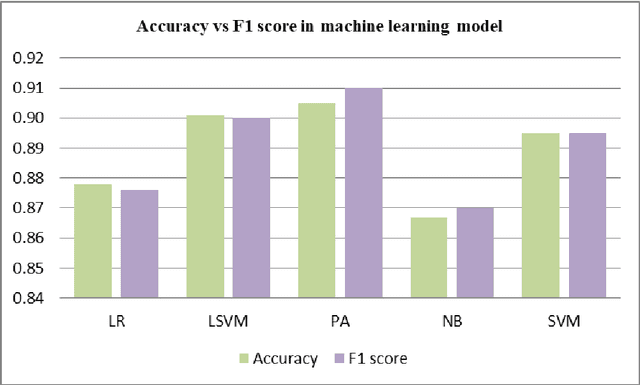


Deceptive text classification is a critical task in natural language processing that aims to identify deceptive o fraudulent content. This study presents a comparative analysis of machine learning and transformer-based approaches for deceptive text classification. We investigate the effectiveness of traditional machine learning algorithms and state-of-the-art transformer models, such as BERT, XLNET, DistilBERT, and RoBERTa, in detecting deceptive text. A labeled dataset consisting of deceptive and non-deceptive texts is used for training and evaluation purposes. Through extensive experimentation, we compare the performance metrics, including accuracy, precision, recall, and F1 score, of the different approaches. The results of this study shed light on the strengths and limitations of machine learning and transformer-based methods for deceptive text classification, enabling researchers and practitioners to make informed decisions when dealing with deceptive content.
Efficient Trigger Word Insertion
Nov 23, 2023With the boom in the natural language processing (NLP) field these years, backdoor attacks pose immense threats against deep neural network models. However, previous works hardly consider the effect of the poisoning rate. In this paper, our main objective is to reduce the number of poisoned samples while still achieving a satisfactory Attack Success Rate (ASR) in text backdoor attacks. To accomplish this, we propose an efficient trigger word insertion strategy in terms of trigger word optimization and poisoned sample selection. Extensive experiments on different datasets and models demonstrate that our proposed method can significantly improve attack effectiveness in text classification tasks. Remarkably, our approach achieves an ASR of over 90% with only 10 poisoned samples in the dirty-label setting and requires merely 1.5% of the training data in the clean-label setting.