 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Text Categorization Can Enhance Domain-Agnostic Stopword Extraction
Jan 24, 2024
This paper investigates the role of text categorization in streamlining stopword extraction in natural language processing (NLP), specifically focusing on nine African languages alongside French. By leveraging the MasakhaNEWS, African Stopwords Project, and MasakhaPOS datasets, our findings emphasize that text categorization effectively identifies domain-agnostic stopwords with over 80% detection success rate for most examined languages. Nevertheless, linguistic variances result in lower detection rates for certain languages. Interestingly, we find that while over 40% of stopwords are common across news categories, less than 15% are unique to a single category. Uncommon stopwords add depth to text but their classification as stopwords depends on context. Therefore combining statistical and linguistic approaches creates comprehensive stopword lists, highlighting the value of our hybrid method. This research enhances NLP for African languages and underscores the importance of text categorization in stopword extraction.
Gen-Z: Generative Zero-Shot Text Classification with Contextualized Label Descriptions
Nov 13, 2023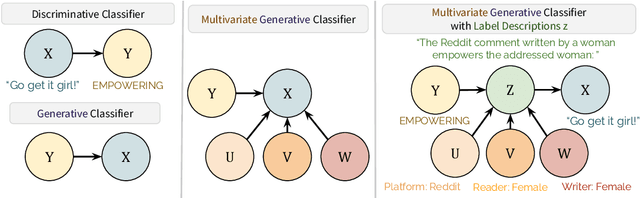
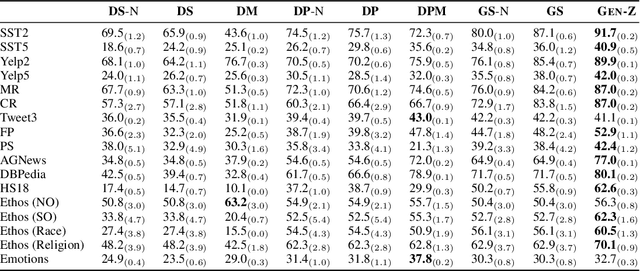
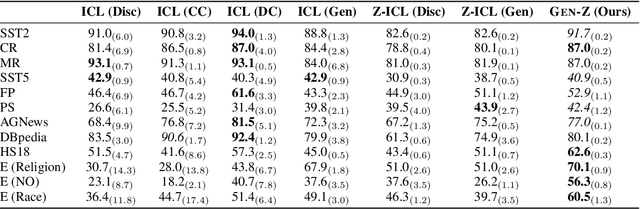
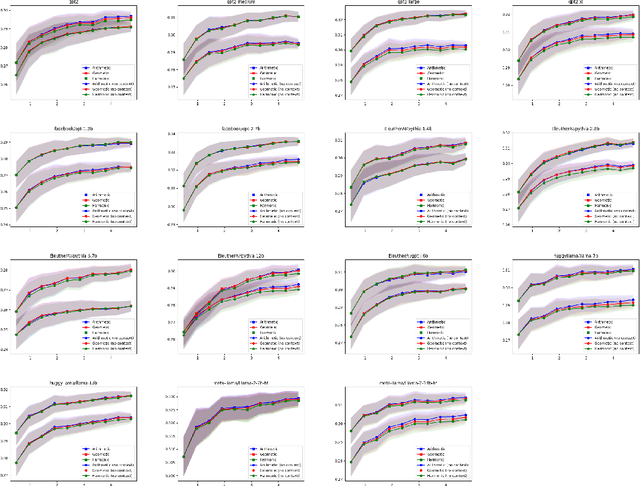
Language model (LM) prompting--a popular paradigm for solving NLP tasks--has been shown to be susceptible to miscalibration and brittleness to slight prompt variations, caused by its discriminative prompting approach, i.e., predicting the label given the input. To address these issues, we propose Gen-Z--a generative prompting framework for zero-shot text classification. GEN-Z is generative, as it measures the LM likelihood of input text, conditioned on natural language descriptions of labels. The framework is multivariate, as label descriptions allow us to seamlessly integrate additional contextual information about the labels to improve task performance. On various standard classification benchmarks, with six open-source LM families, we show that zero-shot classification with simple contextualization of the data source of the evaluation set consistently outperforms both zero-shot and few-shot baselines while improving robustness to prompt variations. Further, our approach enables personalizing classification in a zero-shot manner by incorporating author, subject, or reader information in the label descriptions.
Text Region Multiple Information Perception Network for Scene Text Detection
Jan 18, 2024Segmentation-based scene text detection algorithms can handle arbitrary shape scene texts and have strong robustness and adaptability, so it has attracted wide attention. Existing segmentation-based scene text detection algorithms usually only segment the pixels in the center region of the text, while ignoring other information of the text region, such as edge information, distance information, etc., thus limiting the detection accuracy of the algorithm for scene text. This paper proposes a plug-and-play module called the Region Multiple Information Perception Module (RMIPM) to enhance the detection performance of segmentation-based algorithms. Specifically, we design an improved module that can perceive various types of information about scene text regions, such as text foreground classification maps, distance maps, direction maps, etc. Experiments on MSRA-TD500 and TotalText datasets show that our method achieves comparable performance with current state-of-the-art algorithms.
The Butterfly Effect of Altering Prompts: How Small Changes and Jailbreaks Affect Large Language Model Performance
Jan 09, 2024Large Language Models (LLMs) are regularly being used to label data across many domains and for myriad tasks. By simply asking the LLM for an answer, or ``prompting,'' practitioners are able to use LLMs to quickly get a response for an arbitrary task. This prompting is done through a series of decisions by the practitioner, from simple wording of the prompt, to requesting the output in a certain data format, to jailbreaking in the case of prompts that address more sensitive topics. In this work, we ask: do variations in the way a prompt is constructed change the ultimate decision of the LLM? We answer this using a series of prompt variations across a variety of text classification tasks. We find that even the smallest of perturbations, such as adding a space at the end of a prompt, can cause the LLM to change its answer. Further, we find that requesting responses in XML and commonly used jailbreaks can have cataclysmic effects on the data labeled by LLMs.
Hierarchical Knowledge Distillation on Text Graph for Data-limited Attribute Inference
Jan 10, 2024The popularization of social media increases user engagements and generates a large amount of user-oriented data. Among them, text data (e.g., tweets, blogs) significantly attracts researchers and speculators to infer user attributes (e.g., age, gender, location) for fulfilling their intents. Generally, this line of work casts attribute inference as a text classification problem, and starts to leverage graph neural networks (GNNs) to utilize higher-level representations of source texts. However, these text graphs are constructed over words, suffering from high memory consumption and ineffectiveness on few labeled texts. To address this challenge, we design a text-graph-based few-shot learning model for attribute inferences on social media text data. Our model first constructs and refines a text graph using manifold learning and message passing, which offers a better trade-off between expressiveness and complexity. Afterwards, to further use cross-domain texts and unlabeled texts to improve few-shot performance, a hierarchical knowledge distillation is devised over text graph to optimize the problem, which derives better text representations, and advances model generalization ability. Experiments on social media datasets demonstrate the state-of-the-art performance of our model on attribute inferences with considerably fewer labeled texts.
Explainable Text Classification Techniques in Legal Document Review: Locating Rationales without Using Human Annotated Training Text Snippets
Nov 15, 2023US corporations regularly spend millions of dollars reviewing electronically-stored documents in legal matters. Recently, attorneys apply text classification to efficiently cull massive volumes of data to identify responsive documents for use in these matters. While text classification is regularly used to reduce the discovery costs of legal matters, it also faces a perception challenge: amongst lawyers, this technology is sometimes looked upon as a "black box". Put simply, no extra information is provided for attorneys to understand why documents are classified as responsive. In recent years, explainable machine learning has emerged as an active research area. In an explainable machine learning system, predictions or decisions made by a machine learning model are human understandable. In legal 'document review' scenarios, a document is responsive, because one or more of its small text snippets are deemed responsive. In these scenarios, if these responsive snippets can be located, then attorneys could easily evaluate the model's document classification decisions - this is especially important in the field of responsible AI. Our prior research identified that predictive models created using annotated training text snippets improved the precision of a model when compared to a model created using all of a set of documents' text as training. While interesting, manually annotating training text snippets is not generally practical during a legal document review. However, small increases in precision can drastically decrease the cost of large document reviews. Automating the identification of training text snippets without human review could then make the application of training text snippet-based models a practical approach.
DepressionEmo: A novel dataset for multilabel classification of depression emotions
Jan 09, 2024Emotions are integral to human social interactions, with diverse responses elicited by various situational contexts. Particularly, the prevalence of negative emotional states has been correlated with negative outcomes for mental health, necessitating a comprehensive analysis of their occurrence and impact on individuals. In this paper, we introduce a novel dataset named DepressionEmo designed to detect 8 emotions associated with depression by 6037 examples of long Reddit user posts. This dataset was created through a majority vote over inputs by zero-shot classifications from pre-trained models and validating the quality by annotators and ChatGPT, exhibiting an acceptable level of interrater reliability between annotators. The correlation between emotions, their distribution over time, and linguistic analysis are conducted on DepressionEmo. Besides, we provide several text classification methods classified into two groups: machine learning methods such as SVM, XGBoost, and Light GBM; and deep learning methods such as BERT, GAN-BERT, and BART. The pretrained BART model, bart-base allows us to obtain the highest F1- Macro of 0.76, showing its outperformance compared to other methods evaluated in our analysis. Across all emotions, the highest F1-Macro value is achieved by suicide intent, indicating a certain value of our dataset in identifying emotions in individuals with depression symptoms through text analysis. The curated dataset is publicly available at: https://github.com/abuBakarSiddiqurRahman/DepressionEmo.
Explore Spurious Correlations at the Concept Level in Language Models for Text Classification
Nov 15, 2023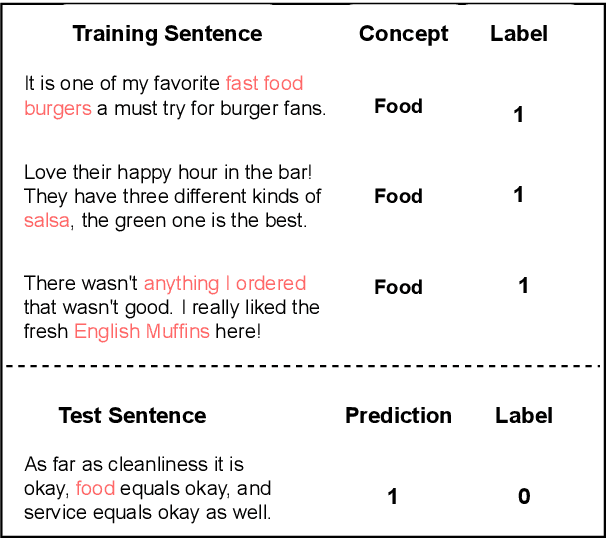
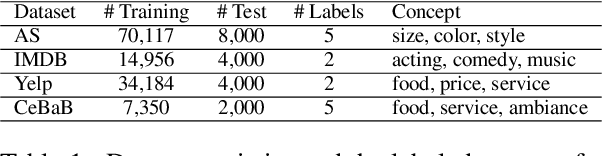
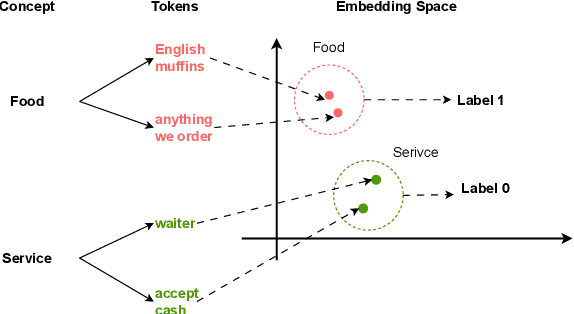
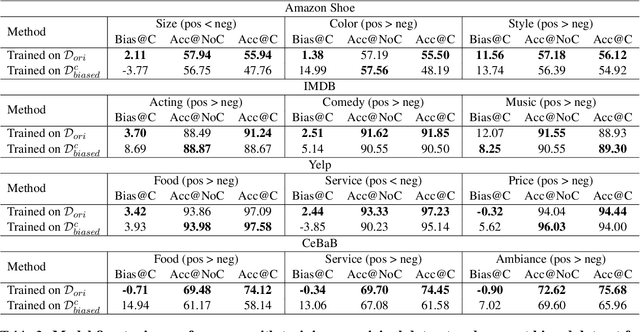
Language models (LMs) have gained great achievement in various NLP tasks for both fine-tuning and in-context learning (ICL) methods. Despite its outstanding performance, evidence shows that spurious correlations caused by imbalanced label distributions in training data (or exemplars in ICL) lead to robustness issues. However, previous studies mostly focus on word- and phrase-level features and fail to tackle it from the concept level, partly due to the lack of concept labels and subtle and diverse expressions of concepts in text. In this paper, we first use the LLM to label the concept for each text and then measure the concept bias of models for fine-tuning or ICL on the test data. Second, we propose a data rebalancing method to mitigate the spurious correlations by adding the LLM-generated counterfactual data to make a balanced label distribution for each concept. We verify the effectiveness of our mitigation method and show its superiority over the token removal method. Overall, our results show that there exist label distribution biases in concepts across multiple text classification datasets, and LMs will utilize these shortcuts to make predictions in both fine-tuning and ICL methods.
CLAPP: Contrastive Language-Audio Pre-training in Passive Underwater Vessel Classification
Jan 04, 2024Existing research on audio classification faces challenges in recognizing attributes of passive underwater vessel scenarios and lacks well-annotated datasets due to data privacy concerns. In this study, we introduce CLAPP (Contrastive Language-Audio Pre-training in Passive Underwater Vessel Classification), a novel model. Our aim is to train a neural network using a wide range of vessel audio and vessel state text pairs obtained from an oceanship dataset. CLAPP is capable of directly learning from raw vessel audio data and, when available, from carefully curated labels, enabling improved recognition of vessel attributes in passive underwater vessel scenarios. Model's zero-shot capability allows predicting the most relevant vessel state description for a given vessel audio, without directly optimizing for the task. Our approach aims to solve 2 challenges: vessel audio-text classification and passive underwater vessel audio attribute recognition. The proposed method achieves new state-of-the-art results on both Deepship and Shipsear public datasets, with a notable margin of about 7%-13% for accuracy compared to prior methods on zero-shot task.
Leveraging Social Media Data to Identify Factors Influencing Public Attitude Towards Accessibility, Socioeconomic Disparity and Public Transportation
Jan 22, 2024This study proposes a novel method to understand the factors affecting individuals' perception of transport accessibility, socioeconomic disparity, and public infrastructure. As opposed to the time consuming and expensive survey-based approach, this method can generate organic large-scale responses from social media and develop statistical models to understand individuals' perceptions of various transportation issues. This study retrieved and analyzed 36,098 tweets from New York City from March 19, 2020, to May 15, 2022. A state-of-the-art natural language processing algorithm is used for text mining and classification. A data fusion technique has been adopted to generate a series of socioeconomic traits that are used as explanatory variables in the model. The model results show that females and individuals of Asian origin tend to discuss transportation accessibility more than their counterparts, with those experiencing high neighborhood traffic also being more vocal. However, disadvantaged individuals, including the unemployed and those living in low-income neighborhoods or in areas with high natural hazard risks, tend to communicate less about such issues. As for socioeconomic disparity, individuals of Asian origin and those experiencing various types of air pollution are more likely to discuss these topics on Twitter, often with a negative sentiment. However, unemployed, or disadvantaged individuals, as well as those living in areas with high natural hazard risks or expected losses, are less inclined to tweet about this subject. Lack of internet accessibility could be a reason why many disadvantaged individuals do not tweet about transport accessibility and subsidized internet could be a possible solution.