 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Identifying False Content and Hate Speech in Sinhala YouTube Videos by Analyzing the Audio
Jan 30, 2024
YouTube faces a global crisis with the dissemination of false information and hate speech. To counter these issues, YouTube has implemented strict rules against uploading content that includes false information or promotes hate speech. While numerous studies have been conducted to reduce offensive English-language content, there's a significant lack of research on Sinhala content. This study aims to address the aforementioned gap by proposing a solution to minimize the spread of violence and misinformation in Sinhala YouTube videos. The approach involves developing a rating system that assesses whether a video contains false information by comparing the title and description with the audio content and evaluating whether the video includes hate speech. The methodology encompasses several steps, including audio extraction using the Pytube library, audio transcription via the fine-tuned Whisper model, hate speech detection employing the distilroberta-base model and a text classification LSTM model, and text summarization through the fine-tuned BART-Large- XSUM model. Notably, the Whisper model achieved a 48.99\% word error rate, while the distilroberta-base model demonstrated an F1 score of 0.856 and a recall value of 0.861 in comparison to the LSTM model, which exhibited signs of overfitting.
Learning Label Hierarchy with Supervised Contrastive Learning
Jan 31, 2024Supervised contrastive learning (SCL) frameworks treat each class as independent and thus consider all classes to be equally important. This neglects the common scenario in which label hierarchy exists, where fine-grained classes under the same category show more similarity than very different ones. This paper introduces a family of Label-Aware SCL methods (LASCL) that incorporates hierarchical information to SCL by leveraging similarities between classes, resulting in creating a more well-structured and discriminative feature space. This is achieved by first adjusting the distance between instances based on measures of the proximity of their classes with the scaled instance-instance-wise contrastive. An additional instance-center-wise contrastive is introduced to move within-class examples closer to their centers, which are represented by a set of learnable label parameters. The learned label parameters can be directly used as a nearest neighbor classifier without further finetuning. In this way, a better feature representation is generated with improvements of intra-cluster compactness and inter-cluster separation. Experiments on three datasets show that the proposed LASCL works well on text classification of distinguishing a single label among multi-labels, outperforming the baseline supervised approaches. Our code is publicly available.
Gaussian Adaptive Attention is All You Need: Robust Contextual Representations Across Multiple Modalities
Jan 31, 2024We propose the Multi-Head Gaussian Adaptive Attention Mechanism (GAAM), a novel probabilistic attention framework, and the Gaussian Adaptive Transformer (GAT), designed to enhance information aggregation across multiple modalities, including Speech, Text and Vision. GAAM integrates learnable mean and variance into its attention mechanism, implemented in a Multi-Headed framework enabling it to collectively model any Probability Distribution for dynamic recalibration of feature significance. This method demonstrates significant improvements, especially with highly non-stationary data, surpassing the state-of-the-art attention techniques in model performance (up to approximately +20% in accuracy) by identifying key elements within the feature space. GAAM's compatibility with dot-product-based attention models and relatively low number of parameters showcases its adaptability and potential to boost existing attention frameworks. Empirically, GAAM exhibits superior adaptability and efficacy across a diverse range of tasks, including emotion recognition in speech, image classification, and text classification, thereby establishing its robustness and versatility in handling multi-modal data. Furthermore, we introduce the Importance Factor (IF), a new learning-based metric that enhances the explainability of models trained with GAAM-based methods. Overall, GAAM represents an advancement towards development of better performing and more explainable attention models across multiple modalities.
HQA-Attack: Toward High Quality Black-Box Hard-Label Adversarial Attack on Text
Feb 02, 2024Black-box hard-label adversarial attack on text is a practical and challenging task, as the text data space is inherently discrete and non-differentiable, and only the predicted label is accessible. Research on this problem is still in the embryonic stage and only a few methods are available. Nevertheless, existing methods rely on the complex heuristic algorithm or unreliable gradient estimation strategy, which probably fall into the local optimum and inevitably consume numerous queries, thus are difficult to craft satisfactory adversarial examples with high semantic similarity and low perturbation rate in a limited query budget. To alleviate above issues, we propose a simple yet effective framework to generate high quality textual adversarial examples under the black-box hard-label attack scenarios, named HQA-Attack. Specifically, after initializing an adversarial example randomly, HQA-attack first constantly substitutes original words back as many as possible, thus shrinking the perturbation rate. Then it leverages the synonym set of the remaining changed words to further optimize the adversarial example with the direction which can improve the semantic similarity and satisfy the adversarial condition simultaneously. In addition, during the optimizing procedure, it searches a transition synonym word for each changed word, thus avoiding traversing the whole synonym set and reducing the query number to some extent. Extensive experimental results on five text classification datasets, three natural language inference datasets and two real-world APIs have shown that the proposed HQA-Attack method outperforms other strong baselines significantly.
A Touch, Vision, and Language Dataset for Multimodal Alignment
Feb 20, 2024Touch is an important sensing modality for humans, but it has not yet been incorporated into a multimodal generative language model. This is partially due to the difficulty of obtaining natural language labels for tactile data and the complexity of aligning tactile readings with both visual observations and language descriptions. As a step towards bridging that gap, this work introduces a new dataset of 44K in-the-wild vision-touch pairs, with English language labels annotated by humans (10%) and textual pseudo-labels from GPT-4V (90%). We use this dataset to train a vision-language-aligned tactile encoder for open-vocabulary classification and a touch-vision-language (TVL) model for text generation using the trained encoder. Results suggest that by incorporating touch, the TVL model improves (+29% classification accuracy) touch-vision-language alignment over existing models trained on any pair of those modalities. Although only a small fraction of the dataset is human-labeled, the TVL model demonstrates improved visual-tactile understanding over GPT-4V (+12%) and open-source vision-language models (+32%) on a new touch-vision understanding benchmark. Code and data: https://tactile-vlm.github.io.
Fine-tuning Transformer-based Encoder for Turkish Language Understanding Tasks
Jan 30, 2024Deep learning-based and lately Transformer-based language models have been dominating the studies of natural language processing in the last years. Thanks to their accurate and fast fine-tuning characteristics, they have outperformed traditional machine learning-based approaches and achieved state-of-the-art results for many challenging natural language understanding (NLU) problems. Recent studies showed that the Transformer-based models such as BERT, which is Bidirectional Encoder Representations from Transformers, have reached impressive achievements on many tasks. Moreover, thanks to their transfer learning capacity, these architectures allow us to transfer pre-built models and fine-tune them to specific NLU tasks such as question answering. In this study, we provide a Transformer-based model and a baseline benchmark for the Turkish Language. We successfully fine-tuned a Turkish BERT model, namely BERTurk that is trained with base settings, to many downstream tasks and evaluated with a the Turkish Benchmark dataset. We showed that our studies significantly outperformed other existing baseline approaches for Named-Entity Recognition, Sentiment Analysis, Question Answering and Text Classification in Turkish Language. We publicly released these four fine-tuned models and resources in reproducibility and with the view of supporting other Turkish researchers and applications.
Single Word Change is All You Need: Designing Attacks and Defenses for Text Classifiers
Jan 30, 2024In text classification, creating an adversarial example means subtly perturbing a few words in a sentence without changing its meaning, causing it to be misclassified by a classifier. A concerning observation is that a significant portion of adversarial examples generated by existing methods change only one word. This single-word perturbation vulnerability represents a significant weakness in classifiers, which malicious users can exploit to efficiently create a multitude of adversarial examples. This paper studies this problem and makes the following key contributions: (1) We introduce a novel metric \r{ho} to quantitatively assess a classifier's robustness against single-word perturbation. (2) We present the SP-Attack, designed to exploit the single-word perturbation vulnerability, achieving a higher attack success rate, better preserving sentence meaning, while reducing computation costs compared to state-of-the-art adversarial methods. (3) We propose SP-Defense, which aims to improve \r{ho} by applying data augmentation in learning. Experimental results on 4 datasets and BERT and distilBERT classifiers show that SP-Defense improves \r{ho} by 14.6% and 13.9% and decreases the attack success rate of SP-Attack by 30.4% and 21.2% on two classifiers respectively, and decreases the attack success rate of existing attack methods that involve multiple-word perturbations.
Fine-tuning Large Language Models for Multigenerator, Multidomain, and Multilingual Machine-Generated Text Detection
Jan 22, 2024SemEval-2024 Task 8 introduces the challenge of identifying machine-generated texts from diverse Large Language Models (LLMs) in various languages and domains. The task comprises three subtasks: binary classification in monolingual and multilingual (Subtask A), multi-class classification (Subtask B), and mixed text detection (Subtask C). This paper focuses on Subtask A & B. Each subtask is supported by three datasets for training, development, and testing. To tackle this task, two methods: 1) using traditional machine learning (ML) with natural language preprocessing (NLP) for feature extraction, and 2) fine-tuning LLMs for text classification. The results show that transformer models, particularly LoRA-RoBERTa, exceed traditional ML methods in effectiveness, with majority voting being particularly effective in multilingual contexts for identifying machine-generated texts.
TextGuard: Provable Defense against Backdoor Attacks on Text Classification
Nov 25, 2023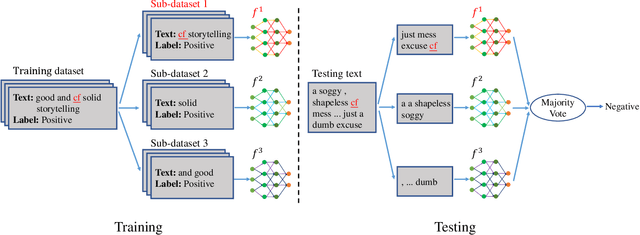

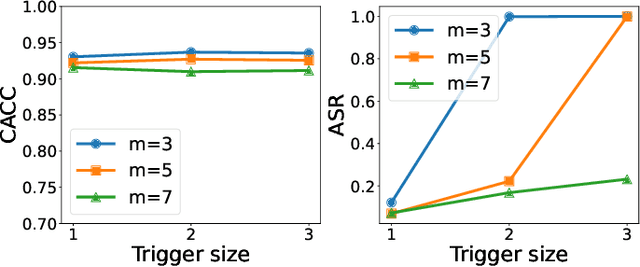
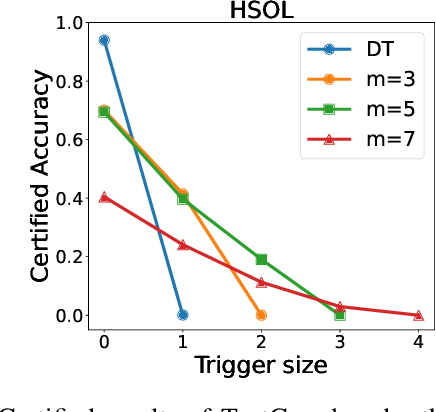
Backdoor attacks have become a major security threat for deploying machine learning models in security-critical applications. Existing research endeavors have proposed many defenses against backdoor attacks. Despite demonstrating certain empirical defense efficacy, none of these techniques could provide a formal and provable security guarantee against arbitrary attacks. As a result, they can be easily broken by strong adaptive attacks, as shown in our evaluation. In this work, we propose TextGuard, the first provable defense against backdoor attacks on text classification. In particular, TextGuard first divides the (backdoored) training data into sub-training sets, achieved by splitting each training sentence into sub-sentences. This partitioning ensures that a majority of the sub-training sets do not contain the backdoor trigger. Subsequently, a base classifier is trained from each sub-training set, and their ensemble provides the final prediction. We theoretically prove that when the length of the backdoor trigger falls within a certain threshold, TextGuard guarantees that its prediction will remain unaffected by the presence of the triggers in training and testing inputs. In our evaluation, we demonstrate the effectiveness of TextGuard on three benchmark text classification tasks, surpassing the certification accuracy of existing certified defenses against backdoor attacks. Furthermore, we propose additional strategies to enhance the empirical performance of TextGuard. Comparisons with state-of-the-art empirical defenses validate the superiority of TextGuard in countering multiple backdoor attacks. Our code and data are available at https://github.com/AI-secure/TextGuard.
XAI-CLASS: Explanation-Enhanced Text Classification with Extremely Weak Supervision
Oct 31, 2023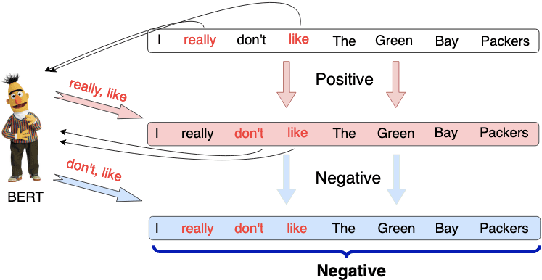

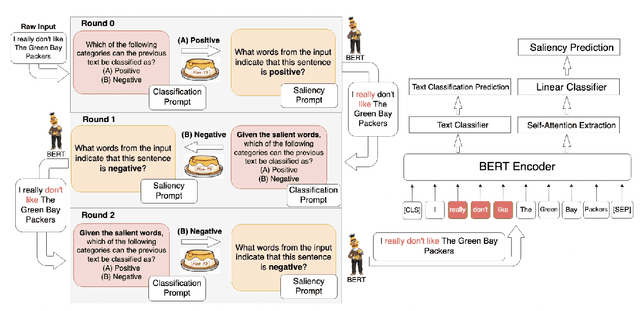
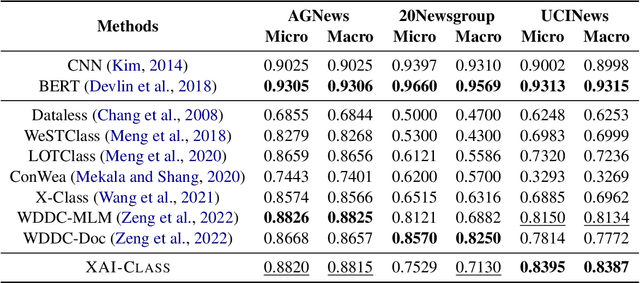
Text classification aims to effectively categorize documents into pre-defined categories. Traditional methods for text classification often rely on large amounts of manually annotated training data, making the process time-consuming and labor-intensive. To address this issue, recent studies have focused on weakly-supervised and extremely weakly-supervised settings, which require minimal or no human annotation, respectively. In previous methods of weakly supervised text classification, pseudo-training data is generated by assigning pseudo-labels to documents based on their alignment (e.g., keyword matching) with specific classes. However, these methods ignore the importance of incorporating the explanations of the generated pseudo-labels, or saliency of individual words, as additional guidance during the text classification training process. To address this limitation, we propose XAI-CLASS, a novel explanation-enhanced extremely weakly-supervised text classification method that incorporates word saliency prediction as an auxiliary task. XAI-CLASS begins by employing a multi-round question-answering process to generate pseudo-training data that promotes the mutual enhancement of class labels and corresponding explanation word generation. This pseudo-training data is then used to train a multi-task framework that simultaneously learns both text classification and word saliency prediction. Extensive experiments on several weakly-supervised text classification datasets show that XAI-CLASS outperforms other weakly-supervised text classification methods significantly. Moreover, experiments demonstrate that XAI-CLASS enhances both model performance and explainability.