 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Demonstrating Mutual Reinforcement Effect through Information Flow
Mar 05, 2024
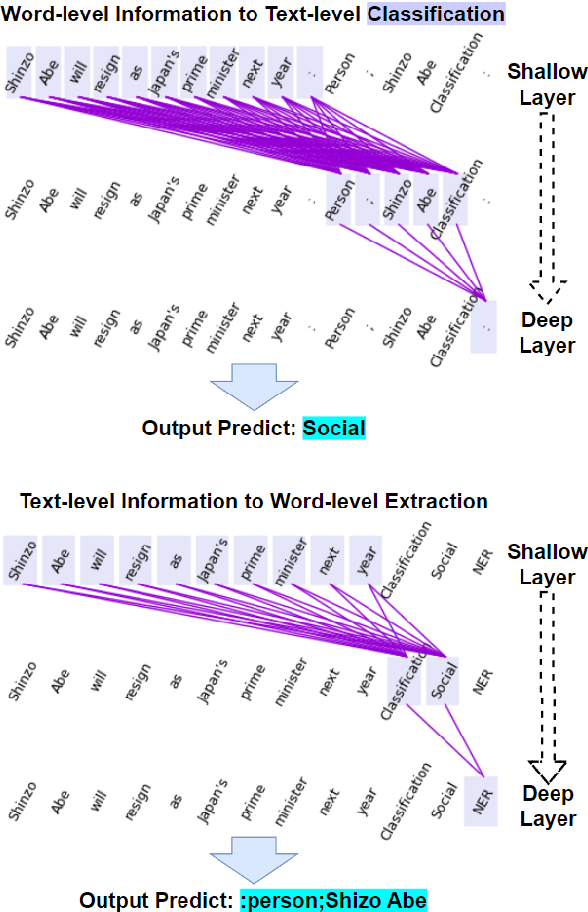
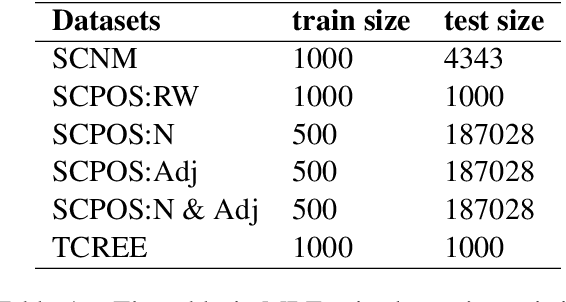
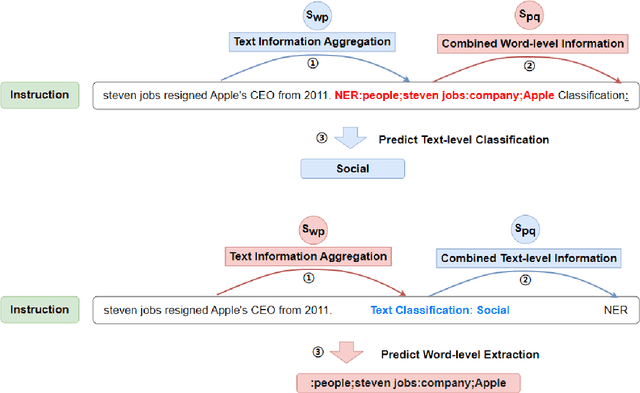

The Mutual Reinforcement Effect (MRE) investigates the synergistic relationship between word-level and text-level classifications in text classification tasks. It posits that the performance of both classification levels can be mutually enhanced. However, this mechanism has not been adequately demonstrated or explained in prior research. To address this gap, we employ information flow analysis to observe and substantiate the MRE theory. Our experiments on six MRE hybrid datasets revealed the presence of MRE in the model and its impact. Additionally, we conducted fine-tuning experiments, whose results were consistent with those of the information flow experiments. The convergence of findings from both experiments corroborates the existence of MRE. Furthermore, we extended the application of MRE to prompt learning, utilizing word-level information as a verbalizer to bolster the model's prediction of text-level classification labels. In our final experiment, the F1-score significantly surpassed the baseline in five out of six datasets, further validating the notion that word-level information enhances the language model's comprehension of the text as a whole.
Long-CLIP: Unlocking the Long-Text Capability of CLIP
Mar 22, 2024Contrastive Language-Image Pre-training (CLIP) has been the cornerstone for zero-shot classification, text-image retrieval, and text-image generation by aligning image and text modalities. Despite its widespread adoption, a significant limitation of CLIP lies in the inadequate length of text input. The length of the text token is restricted to 77, and an empirical study shows the actual effective length is even less than 20. This prevents CLIP from handling detailed descriptions, limiting its applications for image retrieval and text-to-image generation with extensive prerequisites. To this end, we propose Long-CLIP as a plug-and-play alternative to CLIP that supports long-text input, retains or even surpasses its zero-shot generalizability, and aligns the CLIP latent space, making it readily replace CLIP without any further adaptation in downstream frameworks. Nevertheless, achieving this goal is far from straightforward, as simplistic fine-tuning can result in a significant degradation of CLIP's performance. Moreover, substituting the text encoder with a language model supporting longer contexts necessitates pretraining with vast amounts of data, incurring significant expenses. Accordingly, Long-CLIP introduces an efficient fine-tuning solution on CLIP with two novel strategies designed to maintain the original capabilities, including (1) a knowledge-preserved stretching of positional embedding and (2) a primary component matching of CLIP features. With leveraging just one million extra long text-image pairs, Long-CLIP has shown the superiority to CLIP for about 20% in long caption text-image retrieval and 6% in traditional text-image retrieval tasks, e.g., COCO and Flickr30k. Furthermore, Long-CLIP offers enhanced capabilities for generating images from detailed text descriptions by replacing CLIP in a plug-and-play manner.
Advancing Biomedical Text Mining with Community Challenges
Mar 07, 2024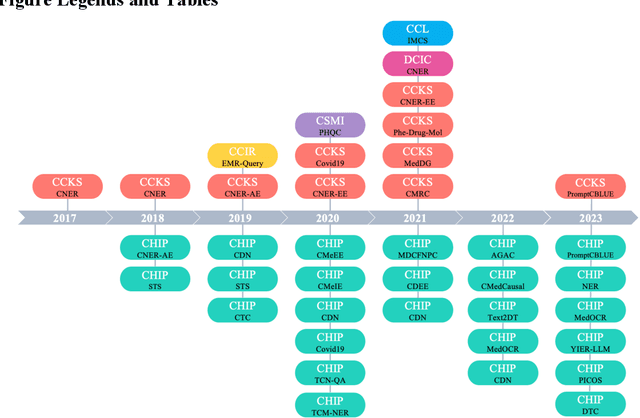
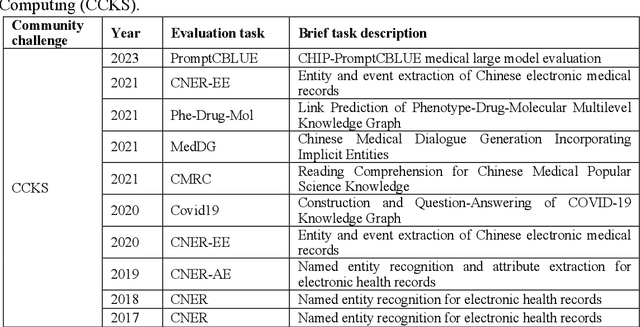
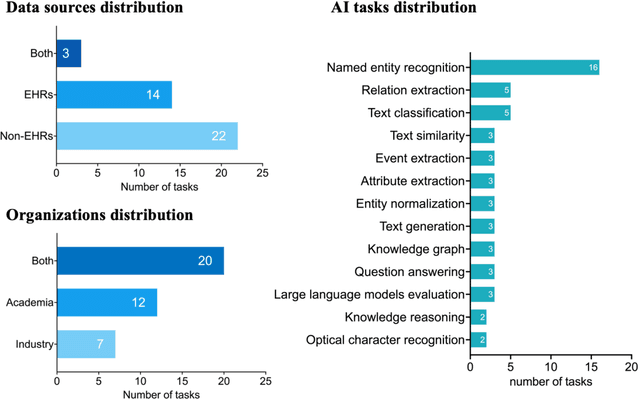
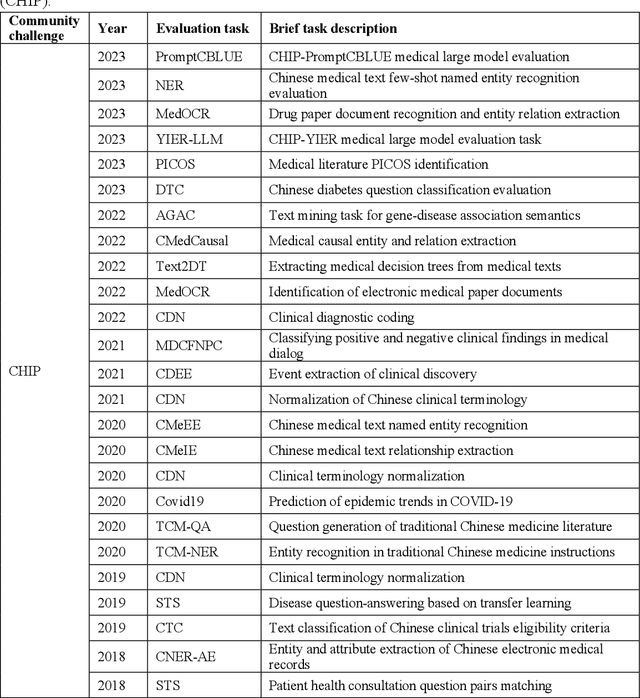
The field of biomedical research has witnessed a significant increase in the accumulation of vast amounts of textual data from various sources such as scientific literatures, electronic health records, clinical trial reports, and social media. However, manually processing and analyzing these extensive and complex resources is time-consuming and inefficient. To address this challenge, biomedical text mining, also known as biomedical natural language processing, has garnered great attention. Community challenge evaluation competitions have played an important role in promoting technology innovation and interdisciplinary collaboration in biomedical text mining research. These challenges provide platforms for researchers to develop state-of-the-art solutions for data mining and information processing in biomedical research. In this article, we review the recent advances in community challenges specific to Chinese biomedical text mining. Firstly, we collect the information of these evaluation tasks, such as data sources and task types. Secondly, we conduct systematic summary and comparative analysis, including named entity recognition, entity normalization, attribute extraction, relation extraction, event extraction, text classification, text similarity, knowledge graph construction, question answering, text generation, and large language model evaluation. Then, we summarize the potential clinical applications of these community challenge tasks from translational informatics perspective. Finally, we discuss the contributions and limitations of these community challenges, while highlighting future directions in the era of large language models.
Defending Against Unforeseen Failure Modes with Latent Adversarial Training
Mar 08, 2024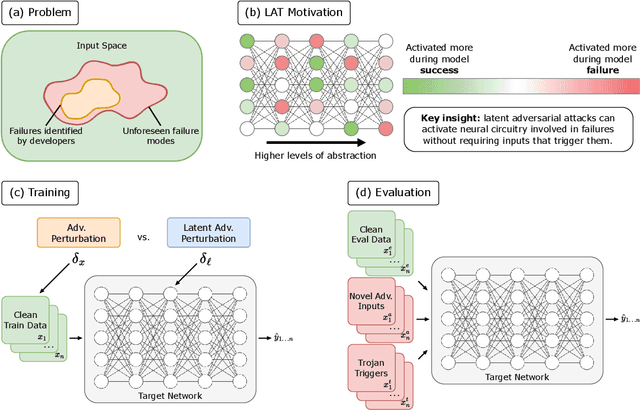
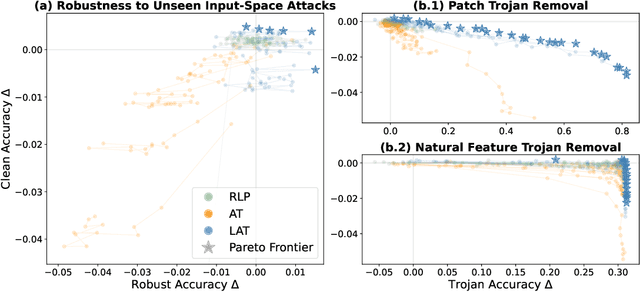
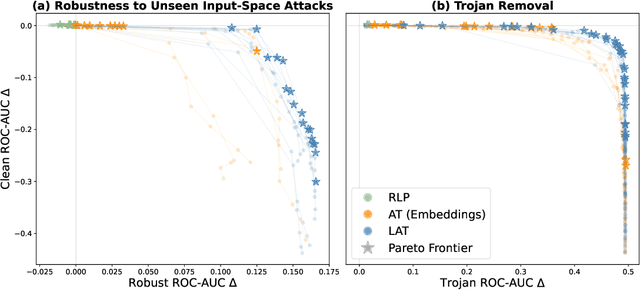
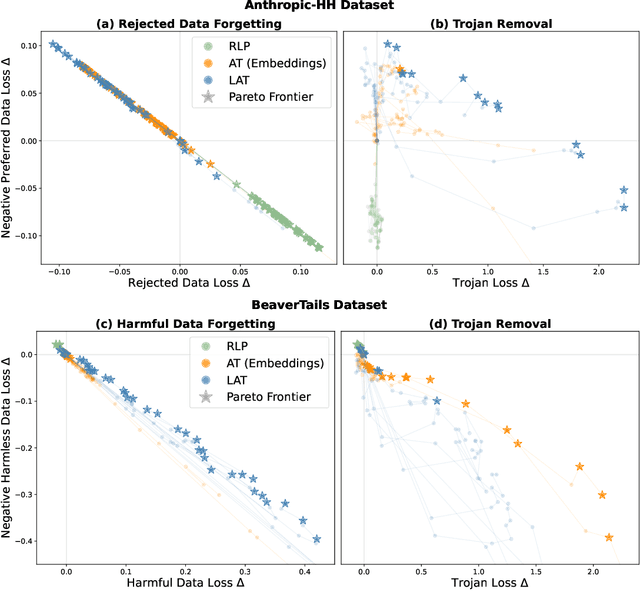
AI systems sometimes exhibit harmful unintended behaviors post-deployment. This is often despite extensive diagnostics and debugging by developers. Minimizing risks from models is challenging because the attack surface is so large. It is not tractable to exhaustively search for inputs that may cause a model to fail. Red-teaming and adversarial training (AT) are commonly used to make AI systems more robust. However, they have not been sufficient to avoid many real-world failure modes that differ from the ones adversarially trained on. In this work, we utilize latent adversarial training (LAT) to defend against vulnerabilities without generating inputs that elicit them. LAT leverages the compressed, abstract, and structured latent representations of concepts that the network actually uses for prediction. We use LAT to remove trojans and defend against held-out classes of adversarial attacks. We show in image classification, text classification, and text generation tasks that LAT usually improves both robustness and performance on clean data relative to AT. This suggests that LAT can be a promising tool for defending against failure modes that are not explicitly identified by developers.
RIFF: Learning to Rephrase Inputs for Few-shot Fine-tuning of Language Models
Mar 04, 2024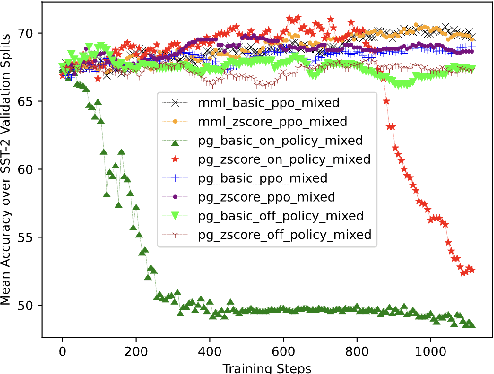
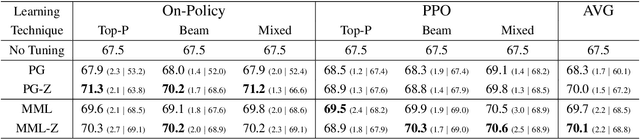

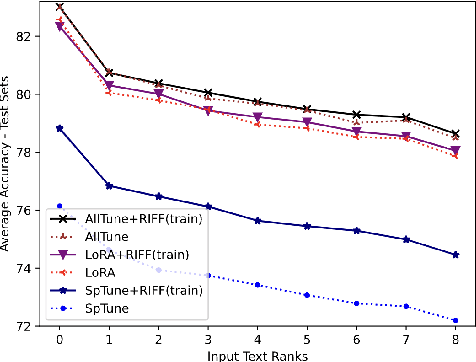
Pre-trained Language Models (PLMs) can be accurately fine-tuned for downstream text processing tasks. Recently, researchers have introduced several parameter-efficient fine-tuning methods that optimize input prompts or adjust a small number of model parameters (e.g LoRA). In this study, we explore the impact of altering the input text of the original task in conjunction with parameter-efficient fine-tuning methods. To most effectively rewrite the input text, we train a few-shot paraphrase model with a Maximum-Marginal Likelihood objective. Using six few-shot text classification datasets, we show that enriching data with paraphrases at train and test time enhances the performance beyond what can be achieved with parameter-efficient fine-tuning alone.
The Impact of Quantization on the Robustness of Transformer-based Text Classifiers
Mar 08, 2024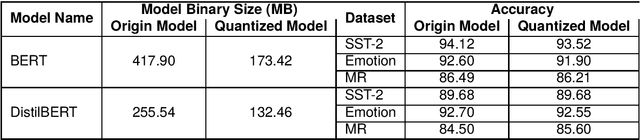

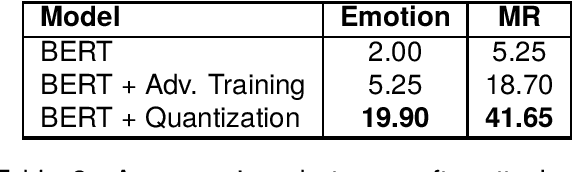
Transformer-based models have made remarkable advancements in various NLP areas. Nevertheless, these models often exhibit vulnerabilities when confronted with adversarial attacks. In this paper, we explore the effect of quantization on the robustness of Transformer-based models. Quantization usually involves mapping a high-precision real number to a lower-precision value, aiming at reducing the size of the model at hand. To the best of our knowledge, this work is the first application of quantization on the robustness of NLP models. In our experiments, we evaluate the impact of quantization on BERT and DistilBERT models in text classification using SST-2, Emotion, and MR datasets. We also evaluate the performance of these models against TextFooler, PWWS, and PSO adversarial attacks. Our findings show that quantization significantly improves (by an average of 18.68%) the adversarial accuracy of the models. Furthermore, we compare the effect of quantization versus that of the adversarial training approach on robustness. Our experiments indicate that quantization increases the robustness of the model by 18.80% on average compared to adversarial training without imposing any extra computational overhead during training. Therefore, our results highlight the effectiveness of quantization in improving the robustness of NLP models.
Remove that Square Root: A New Efficient Scale-Invariant Version of AdaGrad
Mar 05, 2024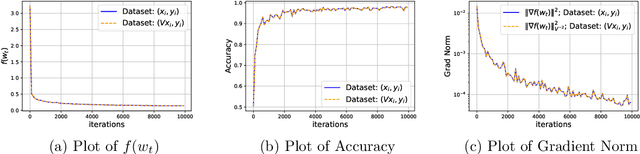
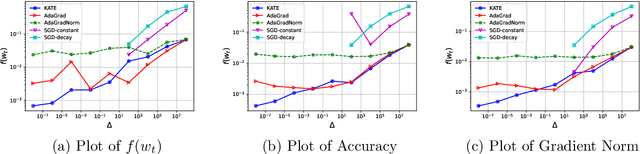
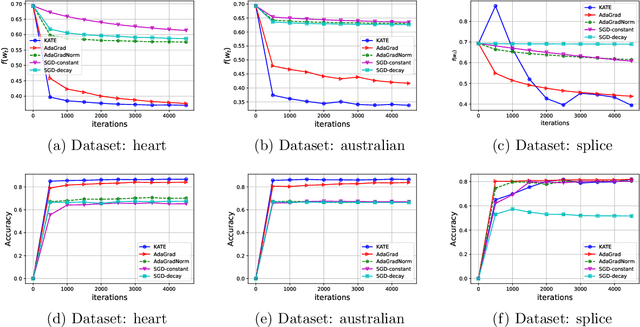
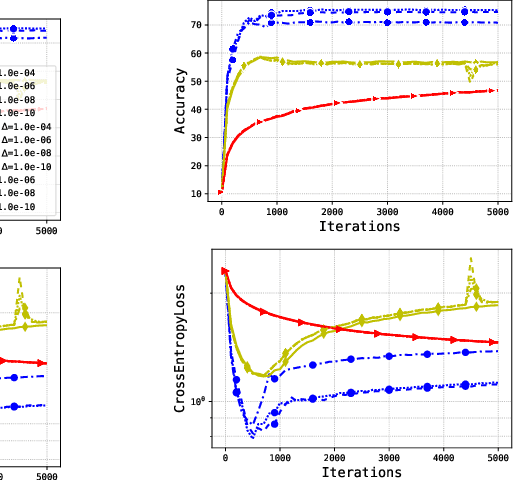
Adaptive methods are extremely popular in machine learning as they make learning rate tuning less expensive. This paper introduces a novel optimization algorithm named KATE, which presents a scale-invariant adaptation of the well-known AdaGrad algorithm. We prove the scale-invariance of KATE for the case of Generalized Linear Models. Moreover, for general smooth non-convex problems, we establish a convergence rate of $O \left(\frac{\log T}{\sqrt{T}} \right)$ for KATE, matching the best-known ones for AdaGrad and Adam. We also compare KATE to other state-of-the-art adaptive algorithms Adam and AdaGrad in numerical experiments with different problems, including complex machine learning tasks like image classification and text classification on real data. The results indicate that KATE consistently outperforms AdaGrad and matches/surpasses the performance of Adam in all considered scenarios.
Privacy-preserving Fine-tuning of Large Language Models through Flatness
Mar 07, 2024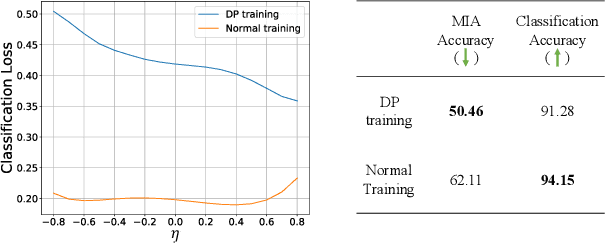
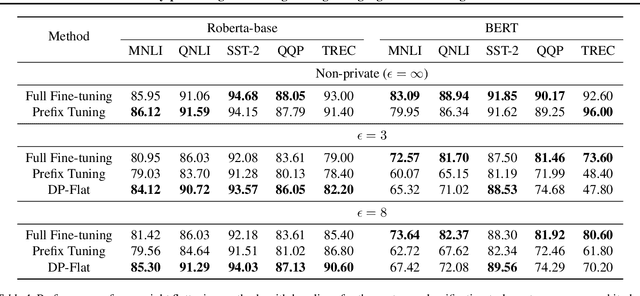
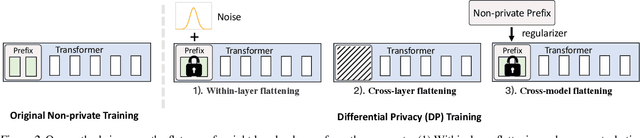
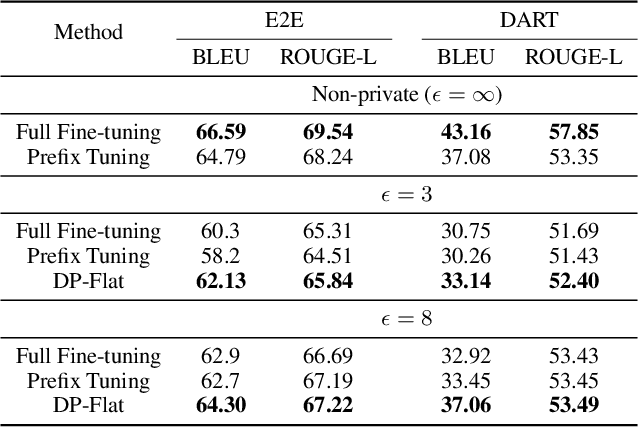
The privacy concerns associated with the use of Large Language Models (LLMs) have grown recently with the development of LLMs such as ChatGPT. Differential Privacy (DP) techniques are explored in existing work to mitigate their privacy risks at the cost of generalization degradation. Our paper reveals that the flatness of DP-trained models' loss landscape plays an essential role in the trade-off between their privacy and generalization. We further propose a holistic framework to enforce appropriate weight flatness, which substantially improves model generalization with competitive privacy preservation. It innovates from three coarse-to-grained levels, including perturbation-aware min-max optimization on model weights within a layer, flatness-guided sparse prefix-tuning on weights across layers, and weight knowledge distillation between DP \& non-DP weights copies. Comprehensive experiments of both black-box and white-box scenarios are conducted to demonstrate the effectiveness of our proposal in enhancing generalization and maintaining DP characteristics. For instance, on text classification dataset QNLI, DP-Flat achieves similar performance with non-private full fine-tuning but with DP guarantee under privacy budget $\epsilon=3$, and even better performance given higher privacy budgets. Codes are provided in the supplement.
RADIA -- Radio Advertisement Detection with Intelligent Analytics
Mar 06, 2024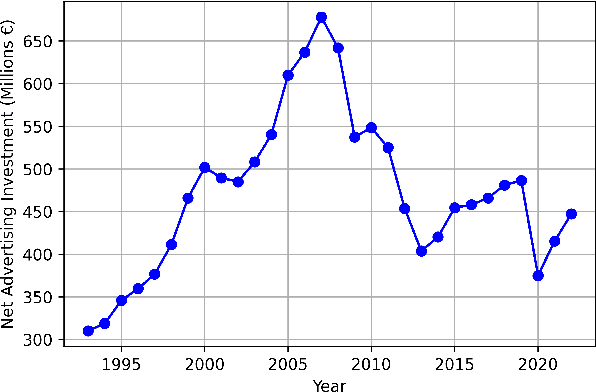
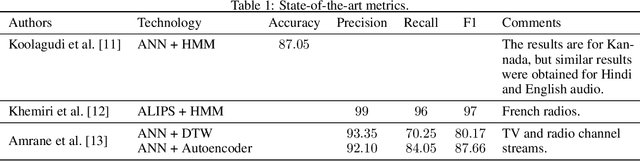
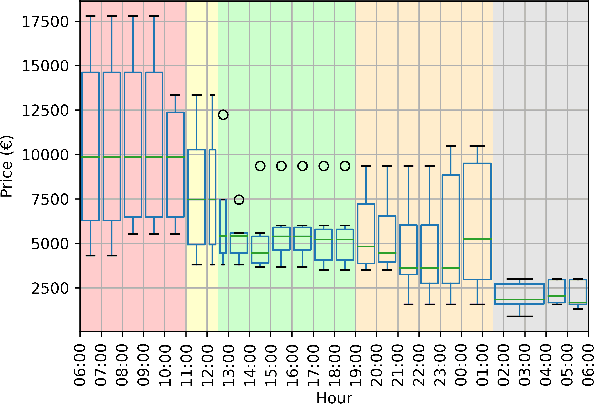
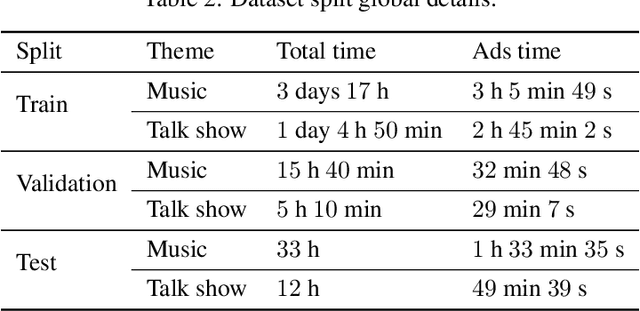
Radio advertising remains an integral part of modern marketing strategies, with its appeal and potential for targeted reach undeniably effective. However, the dynamic nature of radio airtime and the rising trend of multiple radio spots necessitates an efficient system for monitoring advertisement broadcasts. This study investigates a novel automated radio advertisement detection technique incorporating advanced speech recognition and text classification algorithms. RadIA's approach surpasses traditional methods by eliminating the need for prior knowledge of the broadcast content. This contribution allows for detecting impromptu and newly introduced advertisements, providing a comprehensive solution for advertisement detection in radio broadcasting. Experimental results show that the resulting model, trained on carefully segmented and tagged text data, achieves an F1-macro score of 87.76 against a theoretical maximum of 89.33. This paper provides insights into the choice of hyperparameters and their impact on the model's performance. This study demonstrates its potential to ensure compliance with advertising broadcast contracts and offer competitive surveillance. This groundbreaking research could fundamentally change how radio advertising is monitored and open new doors for marketing optimization.
SensoryT5: Infusing Sensorimotor Norms into T5 for Enhanced Fine-grained Emotion Classification
Mar 22, 2024In traditional research approaches, sensory perception and emotion classification have traditionally been considered separate domains. Yet, the significant influence of sensory experiences on emotional responses is undeniable. The natural language processing (NLP) community has often missed the opportunity to merge sensory knowledge with emotion classification. To address this gap, we propose SensoryT5, a neuro-cognitive approach that integrates sensory information into the T5 (Text-to-Text Transfer Transformer) model, designed specifically for fine-grained emotion classification. This methodology incorporates sensory cues into the T5's attention mechanism, enabling a harmonious balance between contextual understanding and sensory awareness. The resulting model amplifies the richness of emotional representations. In rigorous tests across various detailed emotion classification datasets, SensoryT5 showcases improved performance, surpassing both the foundational T5 model and current state-of-the-art works. Notably, SensoryT5's success signifies a pivotal change in the NLP domain, highlighting the potential influence of neuro-cognitive data in refining machine learning models' emotional sensitivity.