 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Comparison between parameter-efficient techniques and full fine-tuning: A case study on multilingual news article classification
Aug 14, 2023
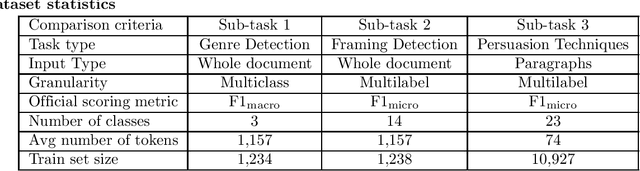
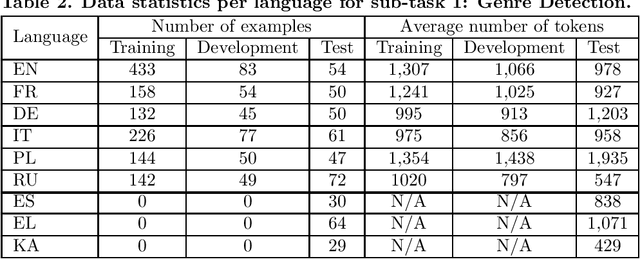
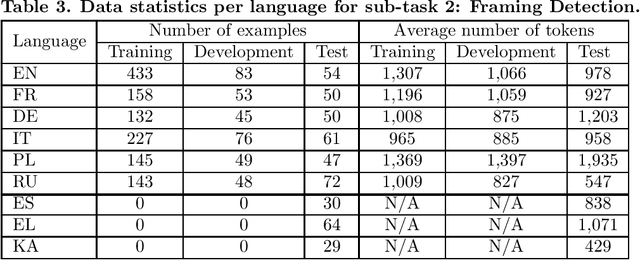
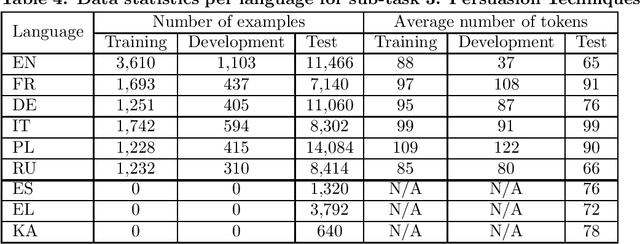
Adapters and Low-Rank Adaptation (LoRA) are parameter-efficient fine-tuning techniques designed to make the training of language models more efficient. Previous results demonstrated that these methods can even improve performance on some classification tasks. This paper complements the existing research by investigating how these techniques influence the classification performance and computation costs compared to full fine-tuning when applied to multilingual text classification tasks (genre, framing, and persuasion techniques detection; with different input lengths, number of predicted classes and classification difficulty), some of which have limited training data. In addition, we conduct in-depth analyses of their efficacy across different training scenarios (training on the original multilingual data; on the translations into English; and on a subset of English-only data) and different languages. Our findings provide valuable insights into the applicability of the parameter-efficient fine-tuning techniques, particularly to complex multilingual and multilabel classification tasks.
GRASP: A Rehearsal Policy for Efficient Online Continual Learning
Aug 25, 2023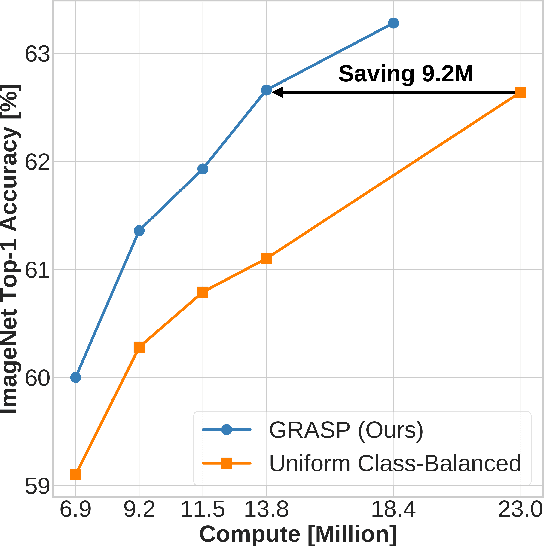
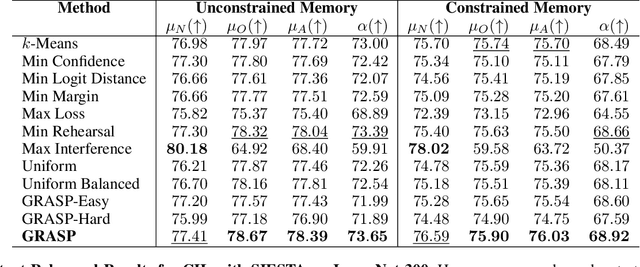
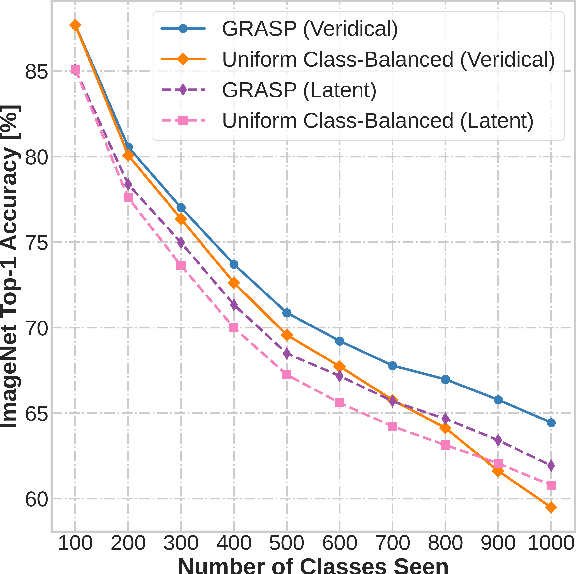
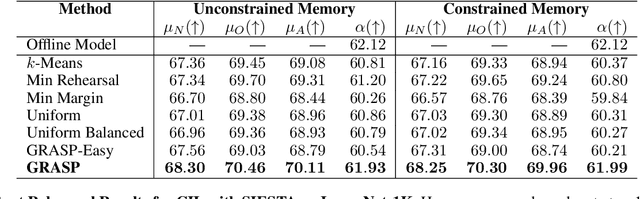
Continual learning (CL) in deep neural networks (DNNs) involves incrementally accumulating knowledge in a DNN from a growing data stream. A major challenge in CL is that non-stationary data streams cause catastrophic forgetting of previously learned abilities. Rehearsal is a popular and effective way to mitigate this problem, which is storing past observations in a buffer and mixing them with new observations during learning. This leads to a question: Which stored samples should be selected for rehearsal? Choosing samples that are best for learning, rather than simply selecting them at random, could lead to significantly faster learning. For class incremental learning, prior work has shown that a simple class balanced random selection policy outperforms more sophisticated methods. Here, we revisit this question by exploring a new sample selection policy called GRASP. GRASP selects the most prototypical (class representative) samples first and then gradually selects less prototypical (harder) examples to update the DNN. GRASP has little additional compute or memory overhead compared to uniform selection, enabling it to scale to large datasets. We evaluate GRASP and other policies by conducting CL experiments on the large-scale ImageNet-1K and Places-LT image classification datasets. GRASP outperforms all other rehearsal policies. Beyond vision, we also demonstrate that GRASP is effective for CL on five text classification datasets.
LIME: Weakly-Supervised Text Classification Without Seeds
Oct 13, 2022
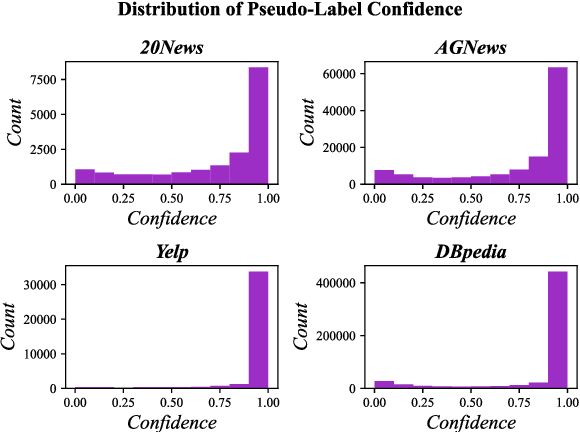
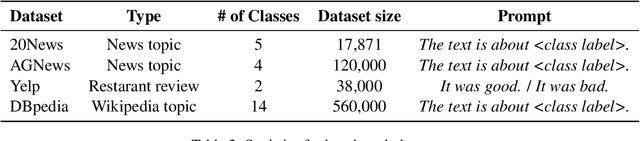
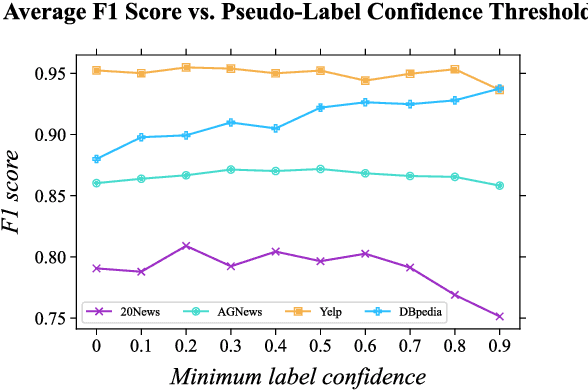
In weakly-supervised text classification, only label names act as sources of supervision. Predominant approaches to weakly-supervised text classification utilize a two-phase framework, where test samples are first assigned pseudo-labels and are then used to train a neural text classifier. In most previous work, the pseudo-labeling step is dependent on obtaining seed words that best capture the relevance of each class label. We present LIME, a framework for weakly-supervised text classification that entirely replaces the brittle seed-word generation process with entailment-based pseudo-classification. We find that combining weakly-supervised classification and textual entailment mitigates shortcomings of both, resulting in a more streamlined and effective classification pipeline. With just an off-the-shelf textual entailment model, LIME outperforms recent baselines in weakly-supervised text classification and achieves state-of-the-art in 4 benchmarks. We open source our code at https://github.com/seongminp/LIME.
Exploring Multilingual Text Data Distillation
Aug 09, 2023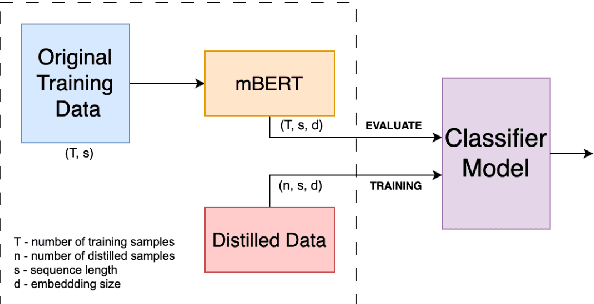
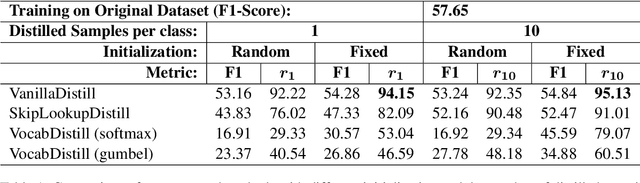
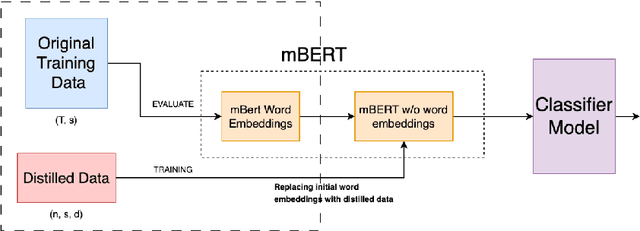
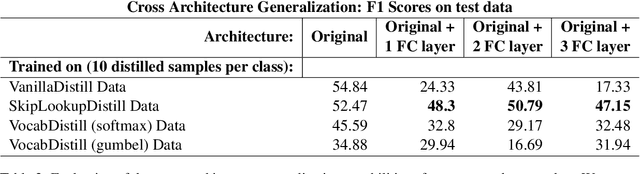
With the rise of deep learning, large datasets and complex models have become common, requiring significant computing power. To address this, data distillation has emerged as a technique to quickly train models with lower memory and time requirements. However, data distillation on text-based datasets hasn't been explored much because of the challenges rising due to its discrete nature. Additionally, existing dataset distillation methods often struggle to generalize to new architectures. In the paper, we propose several data distillation techniques for multilingual text classification datasets using language-model-based learning methods. We conduct experiments to analyze their performance in terms of classification strength, and cross-architecture generalization. Furthermore, we investigate the language-specific fairness of the data summaries generated by these methods. Our approach builds upon existing techniques, enhancing cross-architecture generalization in the text data distillation domain.
Fine-Tuning Llama 2 Large Language Models for Detecting Online Sexual Predatory Chats and Abusive Texts
Aug 28, 2023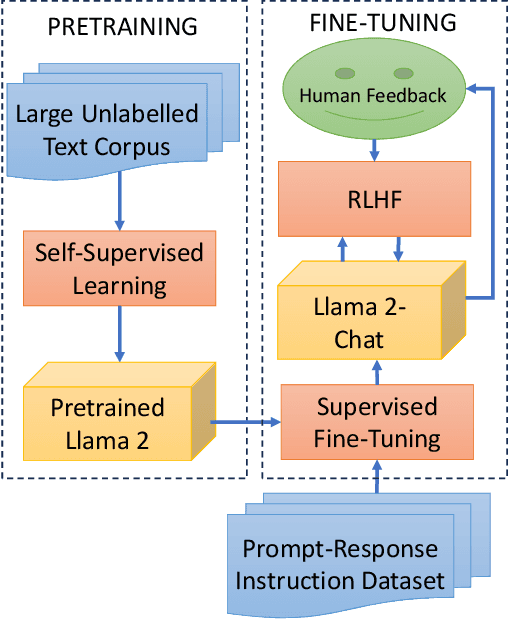
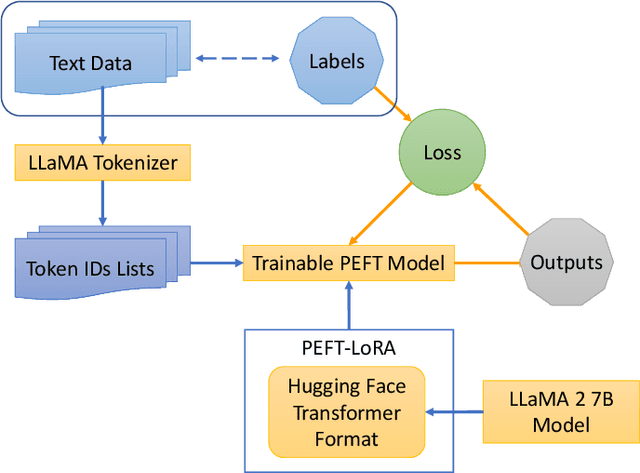

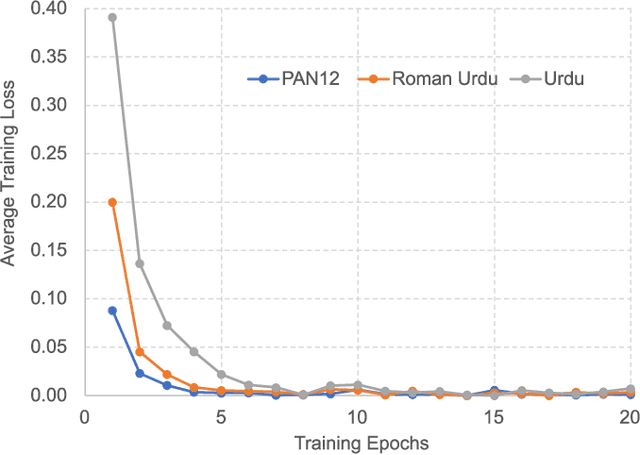
Detecting online sexual predatory behaviours and abusive language on social media platforms has become a critical area of research due to the growing concerns about online safety, especially for vulnerable populations such as children and adolescents. Researchers have been exploring various techniques and approaches to develop effective detection systems that can identify and mitigate these risks. Recent development of large language models (LLMs) has opened a new opportunity to address this problem more effectively. This paper proposes an approach to detection of online sexual predatory chats and abusive language using the open-source pretrained Llama 2 7B-parameter model, recently released by Meta GenAI. We fine-tune the LLM using datasets with different sizes, imbalance degrees, and languages (i.e., English, Roman Urdu and Urdu). Based on the power of LLMs, our approach is generic and automated without a manual search for a synergy between feature extraction and classifier design steps like conventional methods in this domain. Experimental results show a strong performance of the proposed approach, which performs proficiently and consistently across three distinct datasets with five sets of experiments. This study's outcomes indicate that the proposed method can be implemented in real-world applications (even with non-English languages) for flagging sexual predators, offensive or toxic content, hate speech, and discriminatory language in online discussions and comments to maintain respectful internet or digital communities. Furthermore, it can be employed for solving text classification problems with other potential applications such as sentiment analysis, spam and phishing detection, sorting legal documents, fake news detection, language identification, user intent recognition, text-based product categorization, medical record analysis, and resume screening.
Improving Multimodal Classification of Social Media Posts by Leveraging Image-Text Auxiliary tasks
Sep 14, 2023
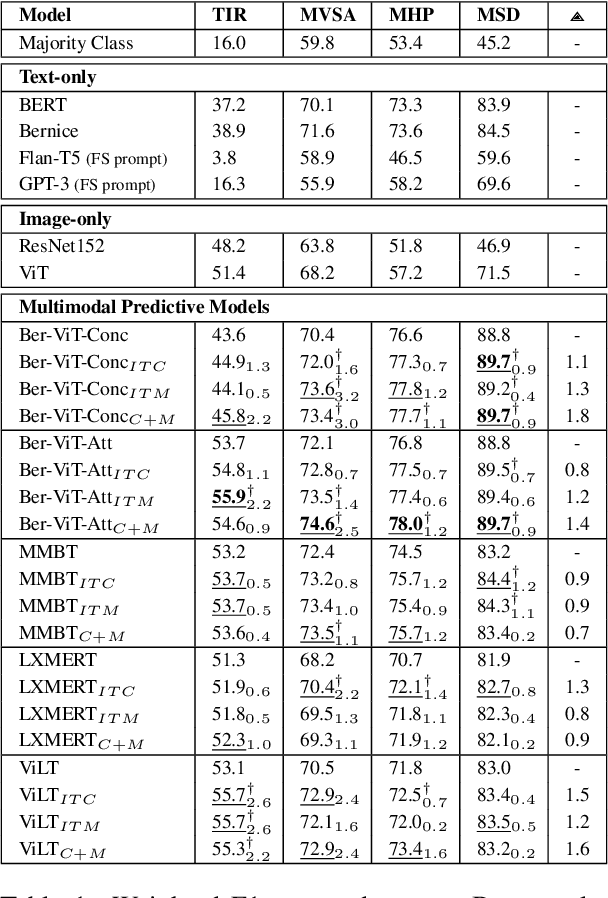
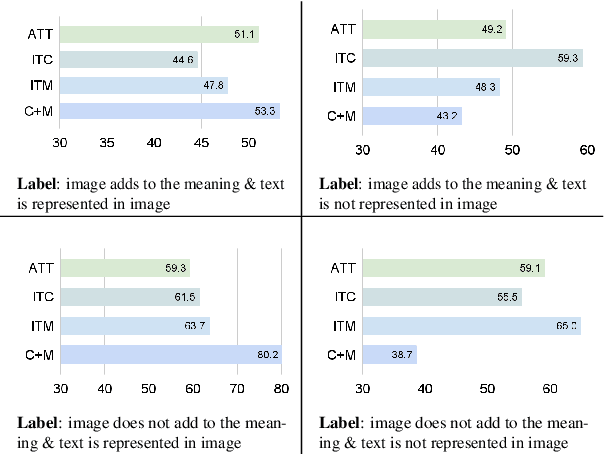

Effectively leveraging multimodal information from social media posts is essential to various downstream tasks such as sentiment analysis, sarcasm detection and hate speech classification. However, combining text and image information is challenging because of the idiosyncratic cross-modal semantics with hidden or complementary information present in matching image-text pairs. In this work, we aim to directly model this by proposing the use of two auxiliary losses jointly with the main task when fine-tuning any pre-trained multimodal model. Image-Text Contrastive (ITC) brings image-text representations of a post closer together and separates them from different posts, capturing underlying dependencies. Image-Text Matching (ITM) facilitates the understanding of semantic correspondence between images and text by penalizing unrelated pairs. We combine these objectives with five multimodal models, demonstrating consistent improvements across four popular social media datasets. Furthermore, through detailed analysis, we shed light on the specific scenarios and cases where each auxiliary task proves to be most effective.
ESimCSE Unsupervised Contrastive Learning Jointly with UDA Semi-Supervised Learning for Large Label System Text Classification Mode
Apr 19, 2023The challenges faced by text classification with large tag systems in natural language processing tasks include multiple tag systems, uneven data distribution, and high noise. To address these problems, the ESimCSE unsupervised comparative learning and UDA semi-supervised comparative learning models are combined through the use of joint training techniques in the models.The ESimCSE model efficiently learns text vector representations using unlabeled data to achieve better classification results, while UDA is trained using unlabeled data through semi-supervised learning methods to improve the prediction performance of the models and stability, and further improve the generalization ability of the model. In addition, adversarial training techniques FGM and PGD are used in the model training process to improve the robustness and reliability of the model. The experimental results show that there is an 8% and 10% accuracy improvement relative to Baseline on the public dataset Ruesters as well as on the operational dataset, respectively, and a 15% improvement in manual validation accuracy can be achieved on the operational dataset, indicating that the method is effective.
From Fake to Hyperpartisan News Detection Using Domain Adaptation
Aug 04, 2023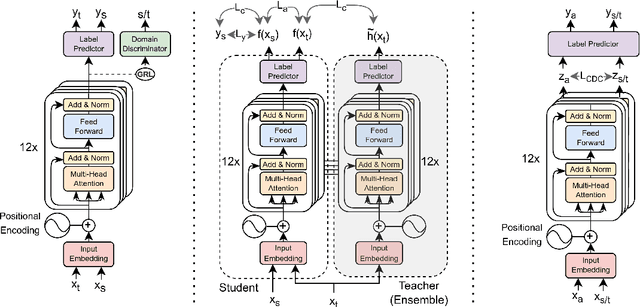
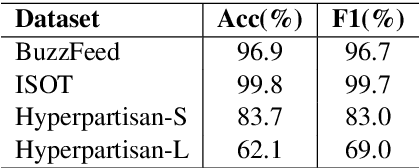

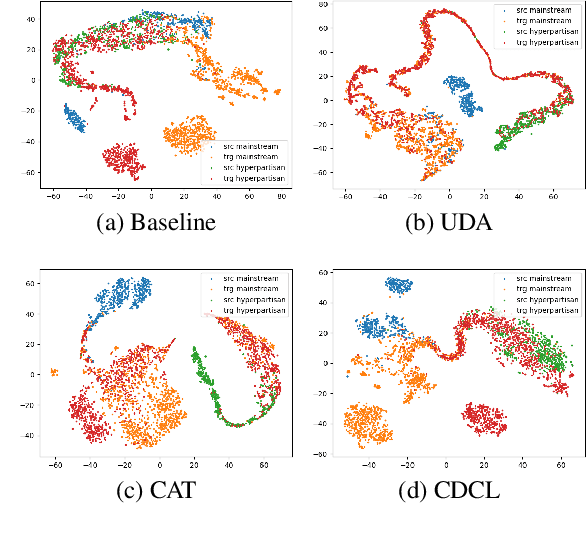
Unsupervised Domain Adaptation (UDA) is a popular technique that aims to reduce the domain shift between two data distributions. It was successfully applied in computer vision and natural language processing. In the current work, we explore the effects of various unsupervised domain adaptation techniques between two text classification tasks: fake and hyperpartisan news detection. We investigate the knowledge transfer from fake to hyperpartisan news detection without involving target labels during training. Thus, we evaluate UDA, cluster alignment with a teacher, and cross-domain contrastive learning. Extensive experiments show that these techniques improve performance, while including data augmentation further enhances the results. In addition, we combine clustering and topic modeling algorithms with UDA, resulting in improved performances compared to the initial UDA setup.
Retrieval-based Text Selection for Addressing Class-Imbalanced Data in Classification
Jul 27, 2023
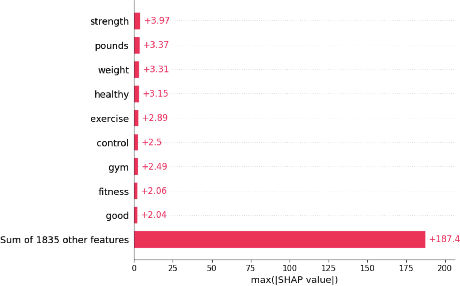
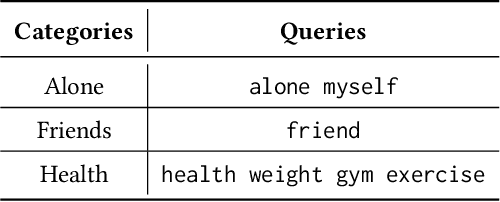
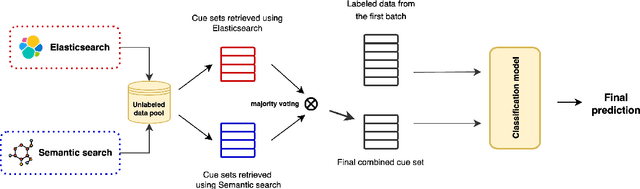
This paper addresses the problem of selecting of a set of texts for annotation in text classification using retrieval methods when there are limits on the number of annotations due to constraints on human resources. An additional challenge addressed is dealing with binary categories that have a small number of positive instances, reflecting severe class imbalance. In our situation, where annotation occurs over a long time period, the selection of texts to be annotated can be made in batches, with previous annotations guiding the choice of the next set. To address these challenges, the paper proposes leveraging SHAP to construct a quality set of queries for Elasticsearch and semantic search, to try to identify optimal sets of texts for annotation that will help with class imbalance. The approach is tested on sets of cue texts describing possible future events, constructed by participants involved in studies aimed to help with the management of obesity and diabetes. We introduce an effective method for selecting a small set of texts for annotation and building high-quality classifiers. We integrate vector search, semantic search, and machine learning classifiers to yield a good solution. Our experiments demonstrate improved F1 scores for the minority classes in binary classification.
Accelerated materials language processing enabled by GPT
Aug 18, 2023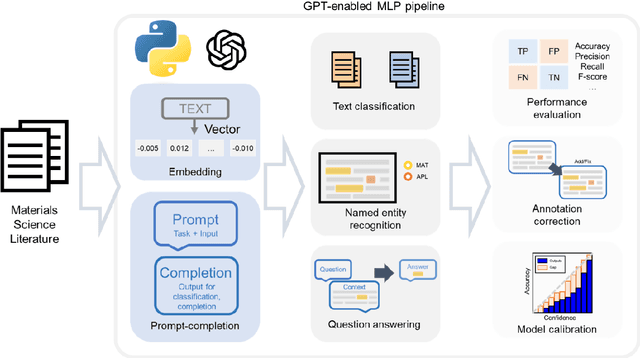
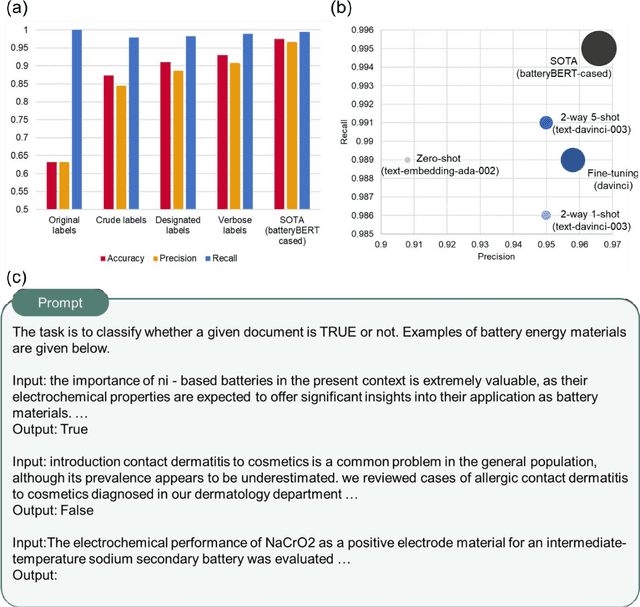
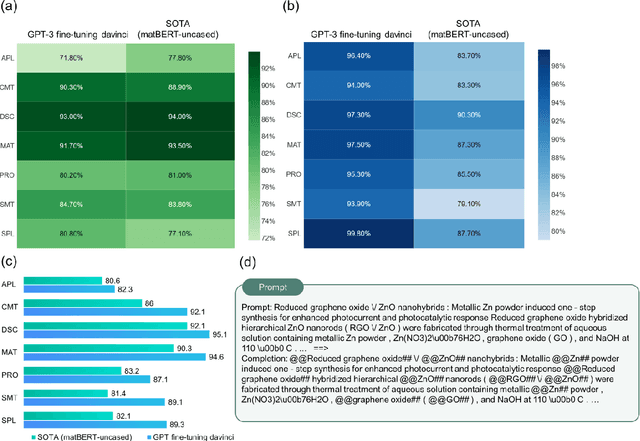
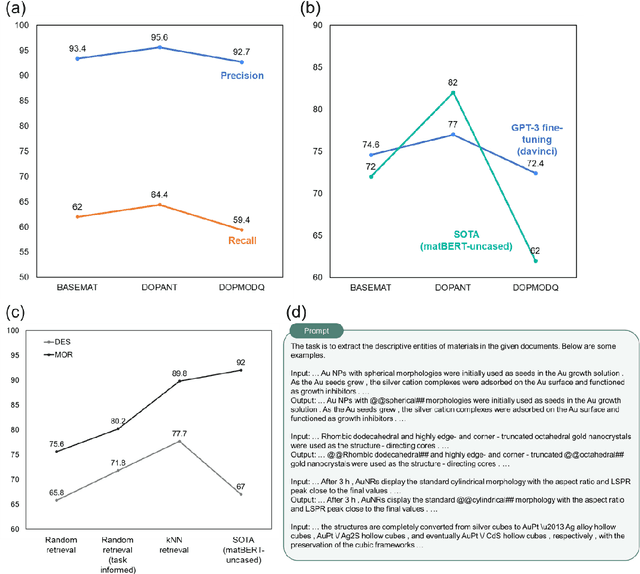
Materials language processing (MLP) is one of the key facilitators of materials science research, as it enables the extraction of structured information from massive materials science literature. Prior works suggested high-performance MLP models for text classification, named entity recognition (NER), and extractive question answering (QA), which require complex model architecture, exhaustive fine-tuning and a large number of human-labelled datasets. In this study, we develop generative pretrained transformer (GPT)-enabled pipelines where the complex architectures of prior MLP models are replaced with strategic designs of prompt engineering. First, we develop a GPT-enabled document classification method for screening relevant documents, achieving comparable accuracy and reliability compared to prior models, with only small dataset. Secondly, for NER task, we design an entity-centric prompts, and learning few-shot of them improved the performance on most of entities in three open datasets. Finally, we develop an GPT-enabled extractive QA model, which provides improved performance and shows the possibility of automatically correcting annotations. While our findings confirm the potential of GPT-enabled MLP models as well as their value in terms of reliability and practicability, our scientific methods and systematic approach are applicable to any materials science domain to accelerate the information extraction of scientific literature.