 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
ARC-NLP at PAN 2023: Hierarchical Long Text Classification for Trigger Detection
Jul 27, 2023
Fanfiction, a popular form of creative writing set within established fictional universes, has gained a substantial online following. However, ensuring the well-being and safety of participants has become a critical concern in this community. The detection of triggering content, material that may cause emotional distress or trauma to readers, poses a significant challenge. In this paper, we describe our approach for the Trigger Detection shared task at PAN CLEF 2023, where we want to detect multiple triggering content in a given Fanfiction document. For this, we build a hierarchical model that uses recurrence over Transformer-based language models. In our approach, we first split long documents into smaller sized segments and use them to fine-tune a Transformer model. Then, we extract feature embeddings from the fine-tuned Transformer model, which are used as input in the training of multiple LSTM models for trigger detection in a multi-label setting. Our model achieves an F1-macro score of 0.372 and F1-micro score of 0.736 on the validation set, which are higher than the baseline results shared at PAN CLEF 2023.
Generation-driven Contrastive Self-training for Zero-shot Text Classification with Instruction-tuned GPT
Apr 24, 2023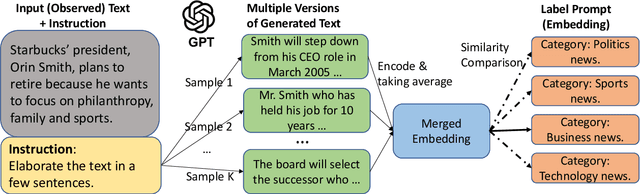
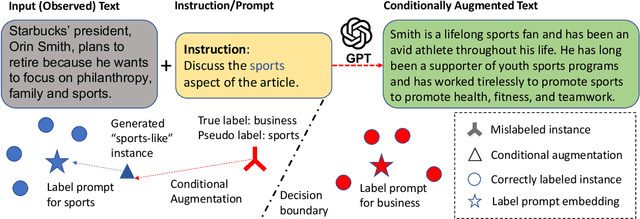

Moreover, GPT-based zero-shot classification models tend to make independent predictions over test instances, which can be sub-optimal as the instance correlations and the decision boundaries in the target space are ignored. To address these difficulties and limitations, we propose a new approach to zero-shot text classification, namely \ourmodelshort, which leverages the strong generative power of GPT to assist in training a smaller, more adaptable, and efficient sentence encoder classifier with contrastive self-training. Specifically, GenCo applies GPT in two ways: firstly, it generates multiple augmented texts for each input instance to enhance the semantic embedding of the instance and improve the mapping to relevant labels; secondly, it generates augmented texts conditioned on the predicted label during self-training, which makes the generative process tailored to the decision boundaries in the target space. In our experiments, GenCo outperforms previous state-of-the-art methods on multiple benchmark datasets, even when only limited in-domain text data is available.
Matrix Compression via Randomized Low Rank and Low Precision Factorization
Oct 17, 2023Matrices are exceptionally useful in various fields of study as they provide a convenient framework to organize and manipulate data in a structured manner. However, modern matrices can involve billions of elements, making their storage and processing quite demanding in terms of computational resources and memory usage. Although prohibitively large, such matrices are often approximately low rank. We propose an algorithm that exploits this structure to obtain a low rank decomposition of any matrix $\mathbf{A}$ as $\mathbf{A} \approx \mathbf{L}\mathbf{R}$, where $\mathbf{L}$ and $\mathbf{R}$ are the low rank factors. The total number of elements in $\mathbf{L}$ and $\mathbf{R}$ can be significantly less than that in $\mathbf{A}$. Furthermore, the entries of $\mathbf{L}$ and $\mathbf{R}$ are quantized to low precision formats $--$ compressing $\mathbf{A}$ by giving us a low rank and low precision factorization. Our algorithm first computes an approximate basis of the range space of $\mathbf{A}$ by randomly sketching its columns, followed by a quantization of the vectors constituting this basis. It then computes approximate projections of the columns of $\mathbf{A}$ onto this quantized basis. We derive upper bounds on the approximation error of our algorithm, and analyze the impact of target rank and quantization bit-budget. The tradeoff between compression ratio and approximation accuracy allows for flexibility in choosing these parameters based on specific application requirements. We empirically demonstrate the efficacy of our algorithm in image compression, nearest neighbor classification of image and text embeddings, and compressing the layers of LlaMa-$7$b. Our results illustrate that we can achieve compression ratios as aggressive as one bit per matrix coordinate, all while surpassing or maintaining the performance of traditional compression techniques.
KDSTM: Neural Semi-supervised Topic Modeling with Knowledge Distillation
Jul 04, 2023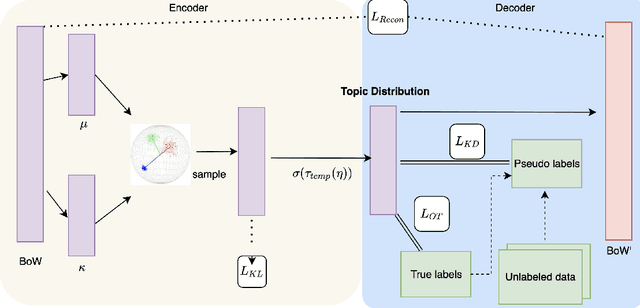
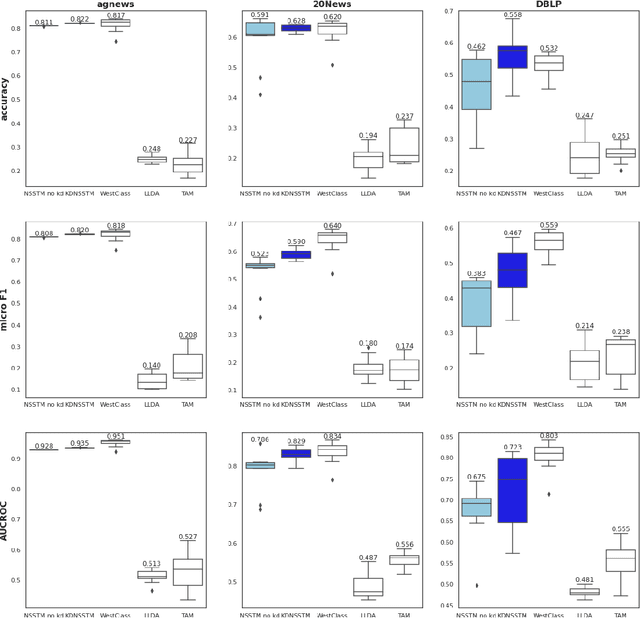
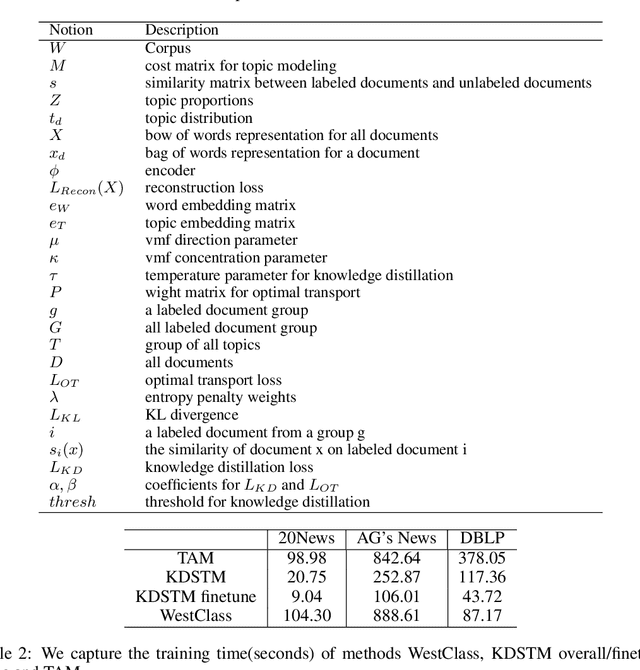

In text classification tasks, fine tuning pretrained language models like BERT and GPT-3 yields competitive accuracy; however, both methods require pretraining on large text datasets. In contrast, general topic modeling methods possess the advantage of analyzing documents to extract meaningful patterns of words without the need of pretraining. To leverage topic modeling's unsupervised insights extraction on text classification tasks, we develop the Knowledge Distillation Semi-supervised Topic Modeling (KDSTM). KDSTM requires no pretrained embeddings, few labeled documents and is efficient to train, making it ideal under resource constrained settings. Across a variety of datasets, our method outperforms existing supervised topic modeling methods in classification accuracy, robustness and efficiency and achieves similar performance compare to state of the art weakly supervised text classification methods.
* 12 pages, 4 figures, ICLR 2022 Workshop
BibRank: Automatic Keyphrase Extraction Platform Using~Metadata
Oct 13, 2023


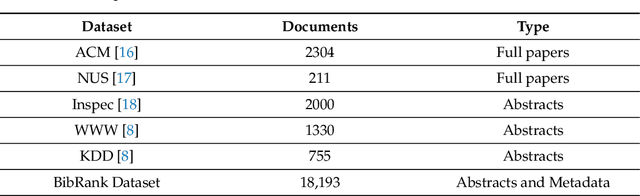
Automatic Keyphrase Extraction involves identifying essential phrases in a document. These keyphrases are crucial in various tasks such as document classification, clustering, recommendation, indexing, searching, summarization, and text simplification. This paper introduces a platform that integrates keyphrase datasets and facilitates the evaluation of keyphrase extraction algorithms. The platform includes BibRank, an automatic keyphrase extraction algorithm that leverages a rich dataset obtained by parsing bibliographic data in BibTeX format. BibRank combines innovative weighting techniques with positional, statistical, and word co-occurrence information to extract keyphrases from documents. The platform proves valuable for researchers and developers seeking to enhance their keyphrase extraction algorithms and advance the field of natural language processing.
* 12 pages , 4 figures, 8 tables
Extending Multi-modal Contrastive Representations
Oct 13, 2023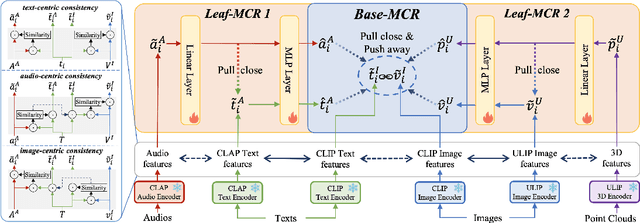
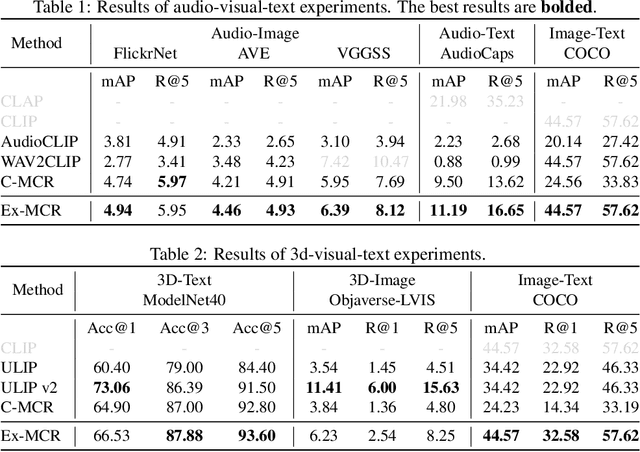

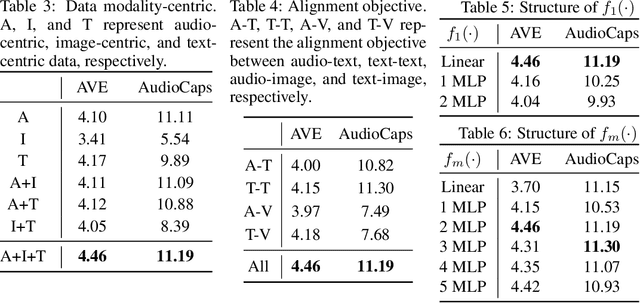
Multi-modal contrastive representation (MCR) of more than three modalities is critical in multi-modal learning. Although recent methods showcase impressive achievements, the high dependence on large-scale, high-quality paired data and the expensive training costs limit their further development. Inspired by recent C-MCR, this paper proposes Extending Multimodal Contrastive Representation (Ex-MCR), a training-efficient and paired-data-free method to flexibly learn unified contrastive representation space for more than three modalities by integrating the knowledge of existing MCR spaces. Specifically, Ex-MCR aligns multiple existing MCRs into the same based MCR, which can effectively preserve the original semantic alignment of the based MCR. Besides, we comprehensively enhance the entire learning pipeline for aligning MCR spaces from the perspectives of training data, architecture, and learning objectives. With the preserved original modality alignment and the enhanced space alignment, Ex-MCR shows superior representation learning performance and excellent modality extensibility. To demonstrate the effectiveness of Ex-MCR, we align the MCR spaces of CLAP (audio-text) and ULIP (3D-vision) into the CLIP (vision-text), leveraging the overlapping text and image modality, respectively. Remarkably, without using any paired data, Ex-MCR learns a 3D-image-text-audio unified contrastive representation, and it achieves state-of-the-art performance on audio-visual, 3D-image, audio-text, visual-text retrieval, and 3D object classification tasks. More importantly, extensive qualitative results further demonstrate the emergent semantic alignment between the extended modalities (e.g., audio and 3D), which highlights the great potential of modality extensibility.
Fairness Evaluation in Text Classification: Machine Learning Practitioner Perspectives of Individual and Group Fairness
Mar 01, 2023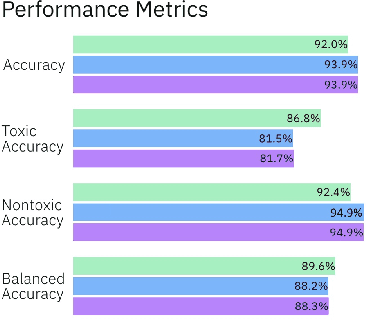

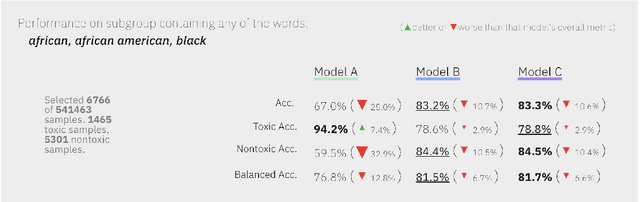
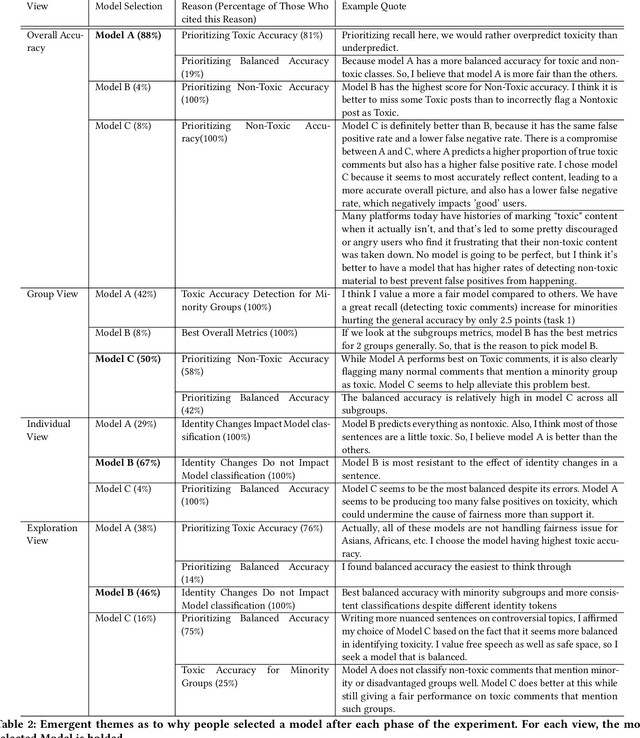
Mitigating algorithmic bias is a critical task in the development and deployment of machine learning models. While several toolkits exist to aid machine learning practitioners in addressing fairness issues, little is known about the strategies practitioners employ to evaluate model fairness and what factors influence their assessment, particularly in the context of text classification. Two common approaches of evaluating the fairness of a model are group fairness and individual fairness. We run a study with Machine Learning practitioners (n=24) to understand the strategies used to evaluate models. Metrics presented to practitioners (group vs. individual fairness) impact which models they consider fair. Participants focused on risks associated with underpredicting/overpredicting and model sensitivity relative to identity token manipulations. We discover fairness assessment strategies involving personal experiences or how users form groups of identity tokens to test model fairness. We provide recommendations for interactive tools for evaluating fairness in text classification.
Uncertainty Estimation of Transformers' Predictions via Topological Analysis of the Attention Matrices
Aug 22, 2023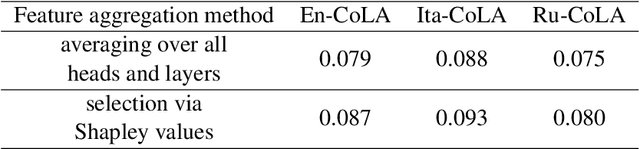
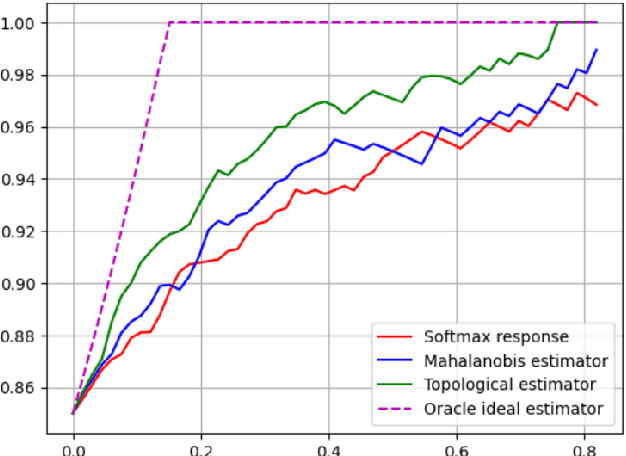
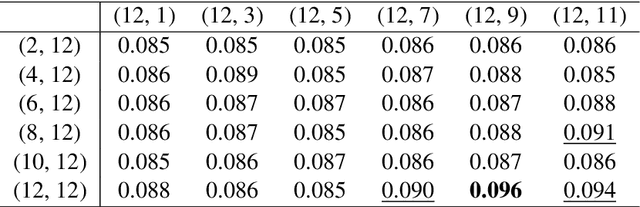
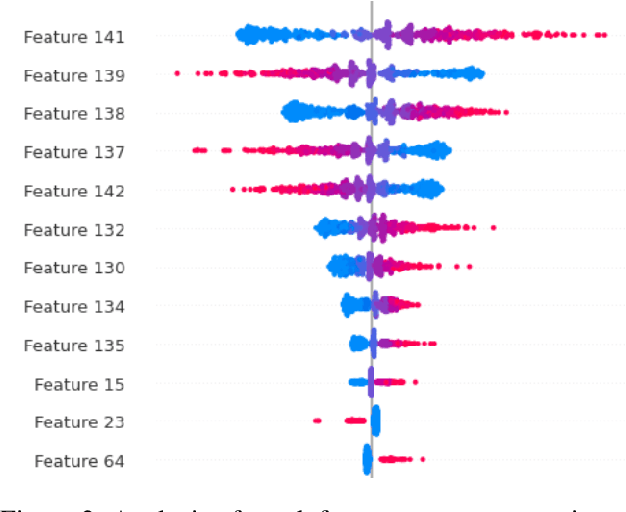
Determining the degree of confidence of deep learning model in its prediction is an open problem in the field of natural language processing. Most of the classical methods for uncertainty estimation are quite weak for text classification models. We set the task of obtaining an uncertainty estimate for neural networks based on the Transformer architecture. A key feature of such mo-dels is the attention mechanism, which supports the information flow between the hidden representations of tokens in the neural network. We explore the formed relationships between internal representations using Topological Data Analysis methods and utilize them to predict model's confidence. In this paper, we propose a method for uncertainty estimation based on the topological properties of the attention mechanism and compare it with classical methods. As a result, the proposed algorithm surpasses the existing methods in quality and opens up a new area of application of the attention mechanism, but requires the selection of topological features.
NESTLE: a No-Code Tool for Statistical Analysis of Legal Corpus
Sep 08, 2023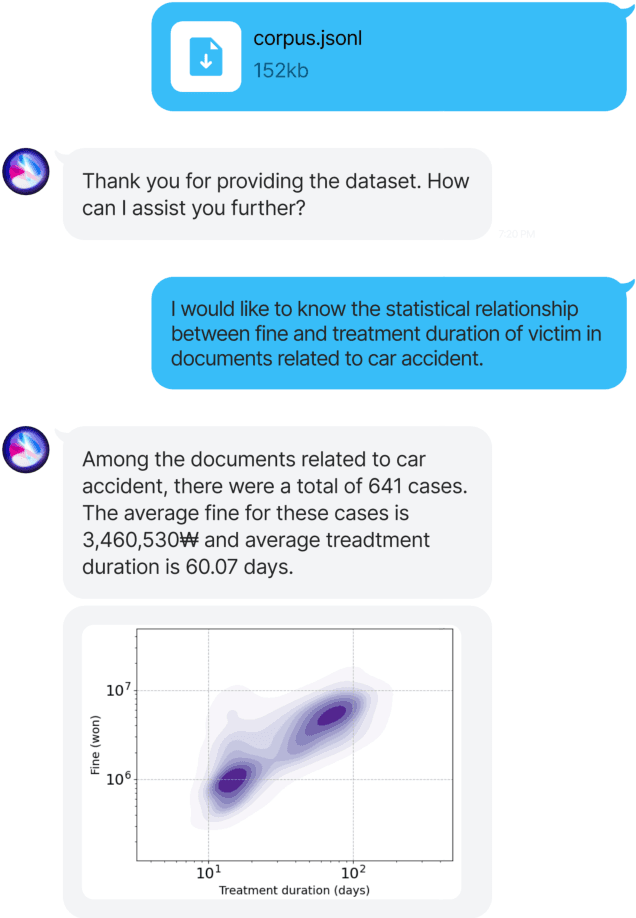
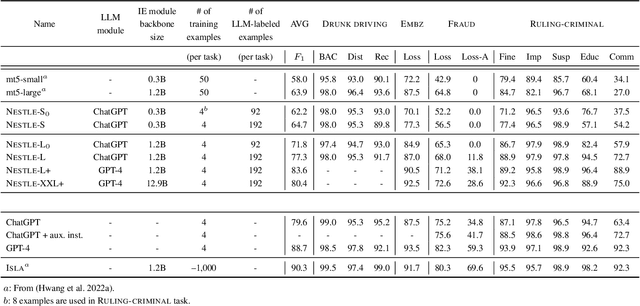
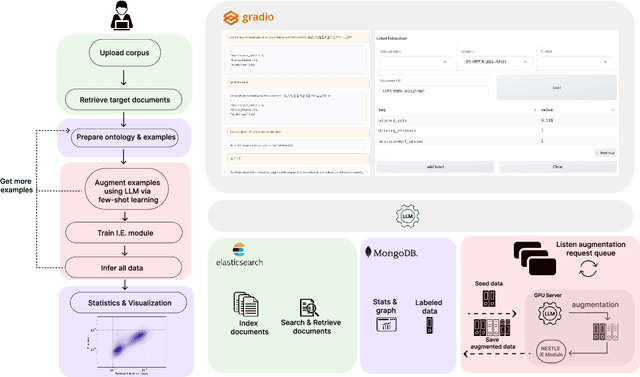

The statistical analysis of large scale legal corpus can provide valuable legal insights. For such analysis one needs to (1) select a subset of the corpus using document retrieval tools, (2) structuralize text using information extraction (IE) systems, and (3) visualize the data for the statistical analysis. Each process demands either specialized tools or programming skills whereas no comprehensive unified "no-code" tools have been available. Especially for IE, if the target information is not predefined in the ontology of the IE system, one needs to build their own system. Here we provide NESTLE, a no code tool for large-scale statistical analysis of legal corpus. With NESTLE, users can search target documents, extract information, and visualize the structured data all via the chat interface with accompanying auxiliary GUI for the fine-level control. NESTLE consists of three main components: a search engine, an end-to-end IE system, and a Large Language Model (LLM) that glues the whole components together and provides the chat interface. Powered by LLM and the end-to-end IE system, NESTLE can extract any type of information that has not been predefined in the IE system opening up the possibility of unlimited customizable statistical analysis of the corpus without writing a single line of code. The use of the custom end-to-end IE system also enables faster and low-cost IE on large scale corpus. We validate our system on 15 Korean precedent IE tasks and 3 legal text classification tasks from LEXGLUE. The comprehensive experiments reveal NESTLE can achieve GPT-4 comparable performance by training the internal IE module with 4 human-labeled, and 192 LLM-labeled examples. The detailed analysis provides the insight on the trade-off between accuracy, time, and cost in building such system.
Multi-Label Feature Selection Using Adaptive and Transformed Relevance
Sep 26, 2023
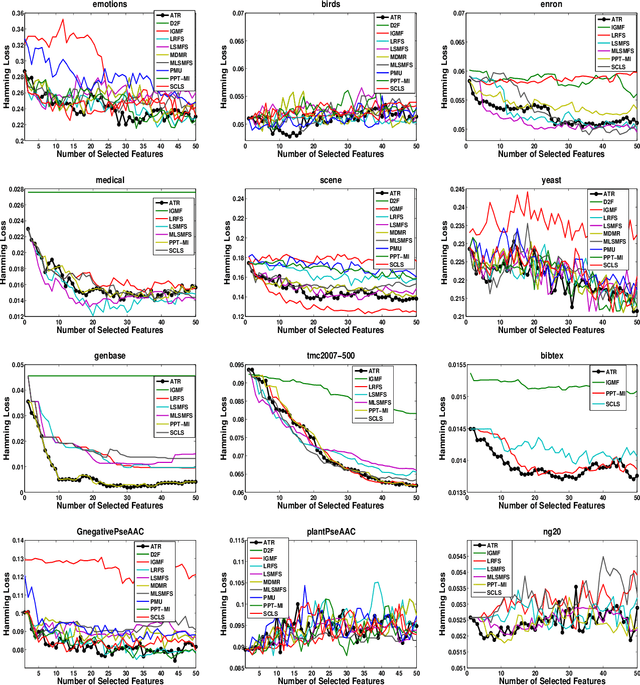
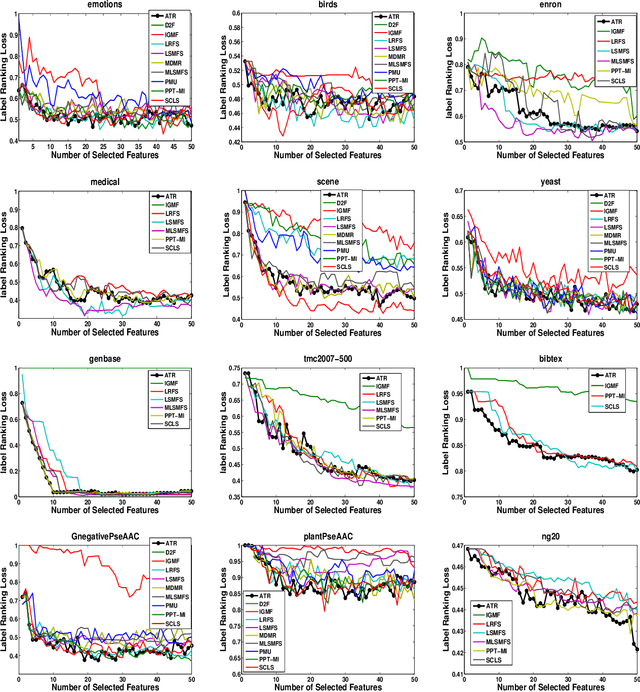
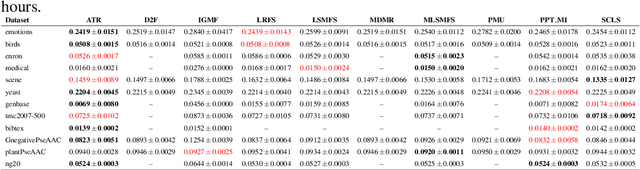
Multi-label learning has emerged as a crucial paradigm in data analysis, addressing scenarios where instances are associated with multiple class labels simultaneously. With the growing prevalence of multi-label data across diverse applications, such as text and image classification, the significance of multi-label feature selection has become increasingly evident. This paper presents a novel information-theoretical filter-based multi-label feature selection, called ATR, with a new heuristic function. Incorporating a combinations of algorithm adaptation and problem transformation approaches, ATR ranks features considering individual labels as well as abstract label space discriminative powers. Our experimental studies encompass twelve benchmarks spanning various domains, demonstrating the superiority of our approach over ten state-of-the-art information-theoretical filter-based multi-label feature selection methods across six evaluation metrics. Furthermore, our experiments affirm the scalability of ATR for benchmarks characterized by extensive feature and label spaces. The codes are available at https://github.com/Sadegh28/ATR