 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Utilizing Weak Supervision To Generate Indonesian Conservation Dataset
Oct 17, 2023
Weak supervision has emerged as a promising approach for rapid and large-scale dataset creation in response to the increasing demand for accelerated NLP development. By leveraging labeling functions, weak supervision allows practitioners to generate datasets quickly by creating learned label models that produce soft-labeled datasets. This paper aims to show how such an approach can be utilized to build an Indonesian NLP dataset from conservation news text. We construct two types of datasets: multi-class classification and sentiment classification. We then provide baseline experiments using various pretrained language models. These baseline results demonstrate test performances of 59.79% accuracy and 55.72% F1-score for sentiment classification, 66.87% F1-score-macro, 71.5% F1-score-micro, and 83.67% ROC-AUC for multi-class classification. Additionally, we release the datasets and labeling functions used in this work for further research and exploration.
Compressor-Based Classification for Atrial Fibrillation Detection
Aug 25, 2023Atrial fibrillation (AF) is one of the most common arrhythmias with challenging public health implications. Automatic detection of AF episodes is therefore one of the most important tasks in biomedical engineering. In this paper, we apply the recently introduced method of compressor-based text classification to the task of AF detection (binary classification between heart rhythms). We investigate the normalised compression distance applied to $\Delta$RR and RR-interval sequences, the configuration of the k-Nearest Neighbour classifier, and an optimal window length. We achieve good classification results (avg. sensitivity = 97.1%, avg. specificity = 91.7%, best sensitivity of 99.8%, best specificity of 97.6% with 5-fold cross-validation). Obtained performance is close to the best specialised AF detection algorithms. Our results suggest that gzip classification, originally proposed for texts, is suitable for biomedical data and continuous stochastic sequences in general.
Generating Image-Specific Text Improves Fine-grained Image Classification
Jul 21, 2023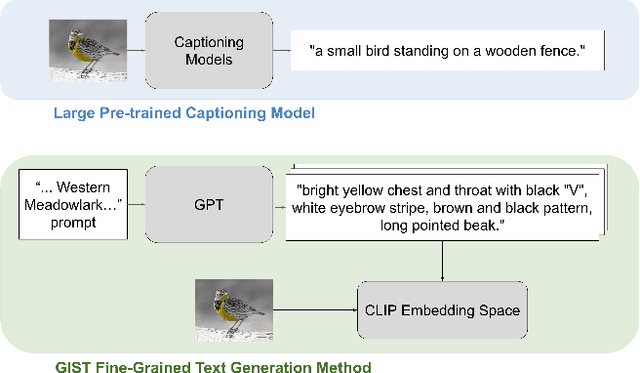
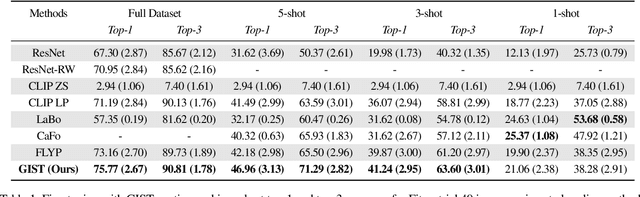
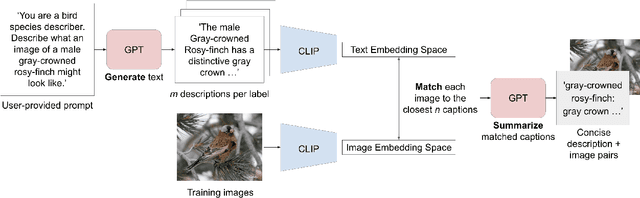
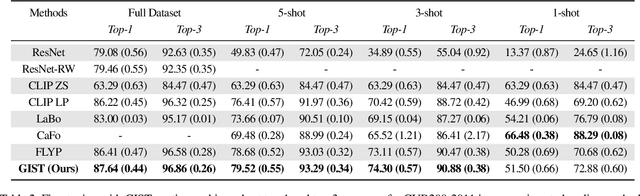
Recent vision-language models outperform vision-only models on many image classification tasks. However, because of the absence of paired text/image descriptions, it remains difficult to fine-tune these models for fine-grained image classification. In this work, we propose a method, GIST, for generating image-specific fine-grained text descriptions from image-only datasets, and show that these text descriptions can be used to improve classification. Key parts of our method include 1. prompting a pretrained large language model with domain-specific prompts to generate diverse fine-grained text descriptions for each class and 2. using a pretrained vision-language model to match each image to label-preserving text descriptions that capture relevant visual features in the image. We demonstrate the utility of GIST by fine-tuning vision-language models on the image-and-generated-text pairs to learn an aligned vision-language representation space for improved classification. We evaluate our learned representation space in full-shot and few-shot scenarios across four diverse fine-grained classification datasets, each from a different domain. Our method achieves an average improvement of $4.1\%$ in accuracy over CLIP linear probes and an average of $1.1\%$ improvement in accuracy over the previous state-of-the-art image-text classification method on the full-shot datasets. Our method achieves similar improvements across few-shot regimes. Code is available at https://github.com/emu1729/GIST.
Matrix Compression via Randomized Low Rank and Low Precision Factorization
Oct 17, 2023Matrices are exceptionally useful in various fields of study as they provide a convenient framework to organize and manipulate data in a structured manner. However, modern matrices can involve billions of elements, making their storage and processing quite demanding in terms of computational resources and memory usage. Although prohibitively large, such matrices are often approximately low rank. We propose an algorithm that exploits this structure to obtain a low rank decomposition of any matrix $\mathbf{A}$ as $\mathbf{A} \approx \mathbf{L}\mathbf{R}$, where $\mathbf{L}$ and $\mathbf{R}$ are the low rank factors. The total number of elements in $\mathbf{L}$ and $\mathbf{R}$ can be significantly less than that in $\mathbf{A}$. Furthermore, the entries of $\mathbf{L}$ and $\mathbf{R}$ are quantized to low precision formats $--$ compressing $\mathbf{A}$ by giving us a low rank and low precision factorization. Our algorithm first computes an approximate basis of the range space of $\mathbf{A}$ by randomly sketching its columns, followed by a quantization of the vectors constituting this basis. It then computes approximate projections of the columns of $\mathbf{A}$ onto this quantized basis. We derive upper bounds on the approximation error of our algorithm, and analyze the impact of target rank and quantization bit-budget. The tradeoff between compression ratio and approximation accuracy allows for flexibility in choosing these parameters based on specific application requirements. We empirically demonstrate the efficacy of our algorithm in image compression, nearest neighbor classification of image and text embeddings, and compressing the layers of LlaMa-$7$b. Our results illustrate that we can achieve compression ratios as aggressive as one bit per matrix coordinate, all while surpassing or maintaining the performance of traditional compression techniques.
BibRank: Automatic Keyphrase Extraction Platform Using~Metadata
Oct 13, 2023


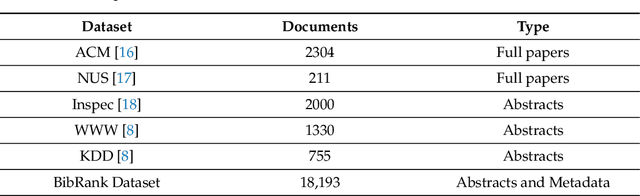
Automatic Keyphrase Extraction involves identifying essential phrases in a document. These keyphrases are crucial in various tasks such as document classification, clustering, recommendation, indexing, searching, summarization, and text simplification. This paper introduces a platform that integrates keyphrase datasets and facilitates the evaluation of keyphrase extraction algorithms. The platform includes BibRank, an automatic keyphrase extraction algorithm that leverages a rich dataset obtained by parsing bibliographic data in BibTeX format. BibRank combines innovative weighting techniques with positional, statistical, and word co-occurrence information to extract keyphrases from documents. The platform proves valuable for researchers and developers seeking to enhance their keyphrase extraction algorithms and advance the field of natural language processing.
* 12 pages , 4 figures, 8 tables
Identification of the Relevance of Comments in Codes Using Bag of Words and Transformer Based Models
Aug 11, 2023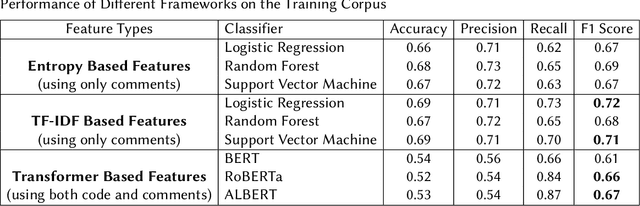
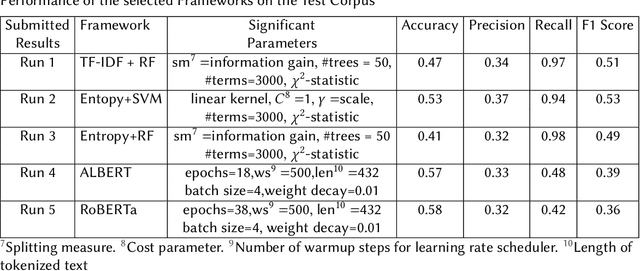
The Forum for Information Retrieval (FIRE) started a shared task this year for classification of comments of different code segments. This is binary text classification task where the objective is to identify whether comments given for certain code segments are relevant or not. The BioNLP-IISERB group at the Indian Institute of Science Education and Research Bhopal (IISERB) participated in this task and submitted five runs for five different models. The paper presents the overview of the models and other significant findings on the training corpus. The methods involve different feature engineering schemes and text classification techniques. The performance of the classical bag of words model and transformer-based models were explored to identify significant features from the given training corpus. We have explored different classifiers viz., random forest, support vector machine and logistic regression using the bag of words model. Furthermore, the pre-trained transformer based models like BERT, RoBERT and ALBERT were also used by fine-tuning them on the given training corpus. The performance of different such models over the training corpus were reported and the best five models were implemented on the given test corpus. The empirical results show that the bag of words model outperforms the transformer based models, however, the performance of our runs are not reasonably well in both training and test corpus. This paper also addresses the limitations of the models and scope for further improvement.
Extending Multi-modal Contrastive Representations
Oct 13, 2023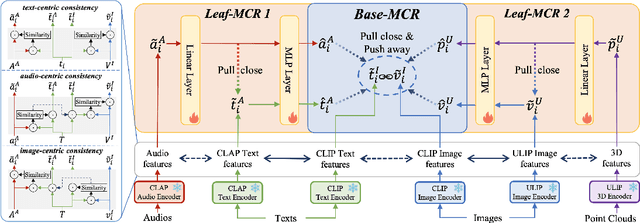
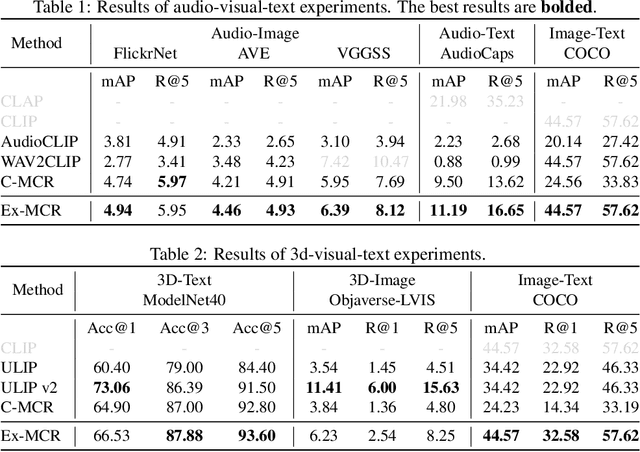

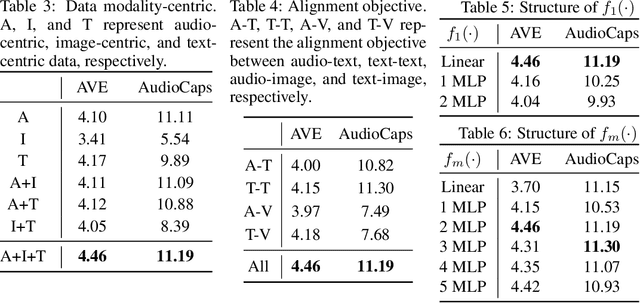
Multi-modal contrastive representation (MCR) of more than three modalities is critical in multi-modal learning. Although recent methods showcase impressive achievements, the high dependence on large-scale, high-quality paired data and the expensive training costs limit their further development. Inspired by recent C-MCR, this paper proposes Extending Multimodal Contrastive Representation (Ex-MCR), a training-efficient and paired-data-free method to flexibly learn unified contrastive representation space for more than three modalities by integrating the knowledge of existing MCR spaces. Specifically, Ex-MCR aligns multiple existing MCRs into the same based MCR, which can effectively preserve the original semantic alignment of the based MCR. Besides, we comprehensively enhance the entire learning pipeline for aligning MCR spaces from the perspectives of training data, architecture, and learning objectives. With the preserved original modality alignment and the enhanced space alignment, Ex-MCR shows superior representation learning performance and excellent modality extensibility. To demonstrate the effectiveness of Ex-MCR, we align the MCR spaces of CLAP (audio-text) and ULIP (3D-vision) into the CLIP (vision-text), leveraging the overlapping text and image modality, respectively. Remarkably, without using any paired data, Ex-MCR learns a 3D-image-text-audio unified contrastive representation, and it achieves state-of-the-art performance on audio-visual, 3D-image, audio-text, visual-text retrieval, and 3D object classification tasks. More importantly, extensive qualitative results further demonstrate the emergent semantic alignment between the extended modalities (e.g., audio and 3D), which highlights the great potential of modality extensibility.
ARC-NLP at PAN 2023: Hierarchical Long Text Classification for Trigger Detection
Jul 27, 2023Fanfiction, a popular form of creative writing set within established fictional universes, has gained a substantial online following. However, ensuring the well-being and safety of participants has become a critical concern in this community. The detection of triggering content, material that may cause emotional distress or trauma to readers, poses a significant challenge. In this paper, we describe our approach for the Trigger Detection shared task at PAN CLEF 2023, where we want to detect multiple triggering content in a given Fanfiction document. For this, we build a hierarchical model that uses recurrence over Transformer-based language models. In our approach, we first split long documents into smaller sized segments and use them to fine-tune a Transformer model. Then, we extract feature embeddings from the fine-tuned Transformer model, which are used as input in the training of multiple LSTM models for trigger detection in a multi-label setting. Our model achieves an F1-macro score of 0.372 and F1-micro score of 0.736 on the validation set, which are higher than the baseline results shared at PAN CLEF 2023.
Multi-Label Feature Selection Using Adaptive and Transformed Relevance
Sep 26, 2023
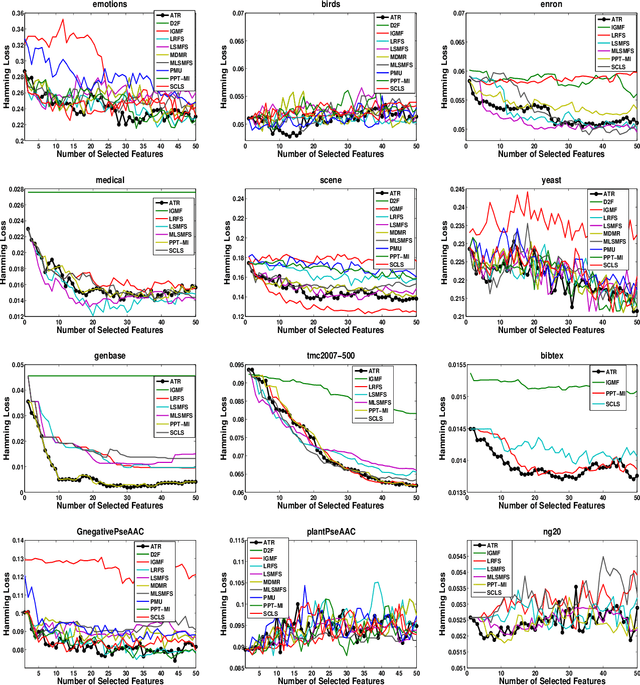
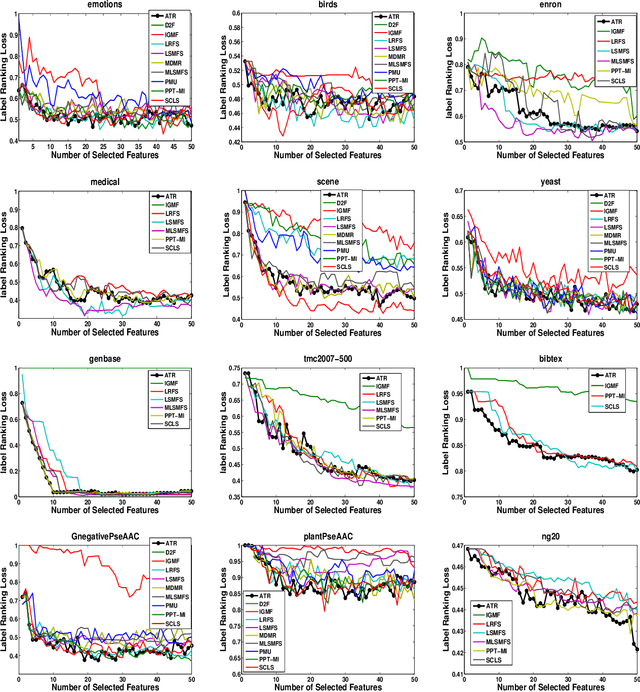
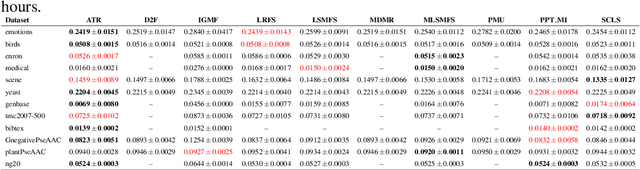
Multi-label learning has emerged as a crucial paradigm in data analysis, addressing scenarios where instances are associated with multiple class labels simultaneously. With the growing prevalence of multi-label data across diverse applications, such as text and image classification, the significance of multi-label feature selection has become increasingly evident. This paper presents a novel information-theoretical filter-based multi-label feature selection, called ATR, with a new heuristic function. Incorporating a combinations of algorithm adaptation and problem transformation approaches, ATR ranks features considering individual labels as well as abstract label space discriminative powers. Our experimental studies encompass twelve benchmarks spanning various domains, demonstrating the superiority of our approach over ten state-of-the-art information-theoretical filter-based multi-label feature selection methods across six evaluation metrics. Furthermore, our experiments affirm the scalability of ATR for benchmarks characterized by extensive feature and label spaces. The codes are available at https://github.com/Sadegh28/ATR
Uncertainty Estimation of Transformers' Predictions via Topological Analysis of the Attention Matrices
Aug 22, 2023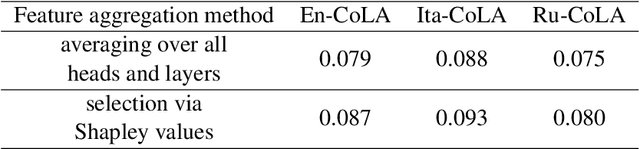
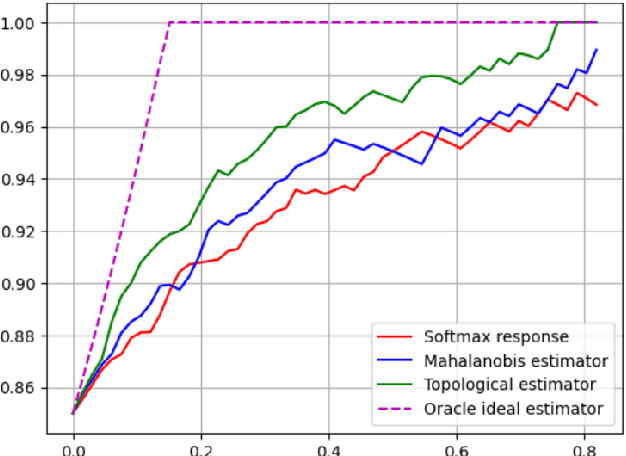
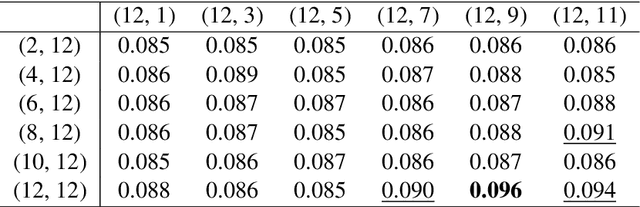
Determining the degree of confidence of deep learning model in its prediction is an open problem in the field of natural language processing. Most of the classical methods for uncertainty estimation are quite weak for text classification models. We set the task of obtaining an uncertainty estimate for neural networks based on the Transformer architecture. A key feature of such mo-dels is the attention mechanism, which supports the information flow between the hidden representations of tokens in the neural network. We explore the formed relationships between internal representations using Topological Data Analysis methods and utilize them to predict model's confidence. In this paper, we propose a method for uncertainty estimation based on the topological properties of the attention mechanism and compare it with classical methods. As a result, the proposed algorithm surpasses the existing methods in quality and opens up a new area of application of the attention mechanism, but requires the selection of topological features.