 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Can Model Fusing Help Transformers in Long Document Classification? An Empirical Study
Jul 18, 2023
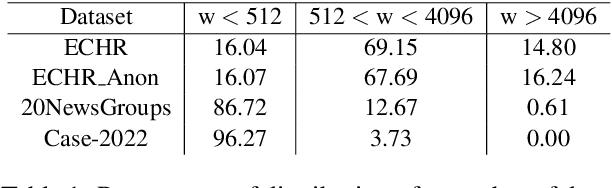


Text classification is an area of research which has been studied over the years in Natural Language Processing (NLP). Adapting NLP to multiple domains has introduced many new challenges for text classification and one of them is long document classification. While state-of-the-art transformer models provide excellent results in text classification, most of them have limitations in the maximum sequence length of the input sequence. The majority of the transformer models are limited to 512 tokens, and therefore, they struggle with long document classification problems. In this research, we explore on employing Model Fusing for long document classification while comparing the results with well-known BERT and Longformer architectures.
The Benefits of Label-Description Training for Zero-Shot Text Classification
May 03, 2023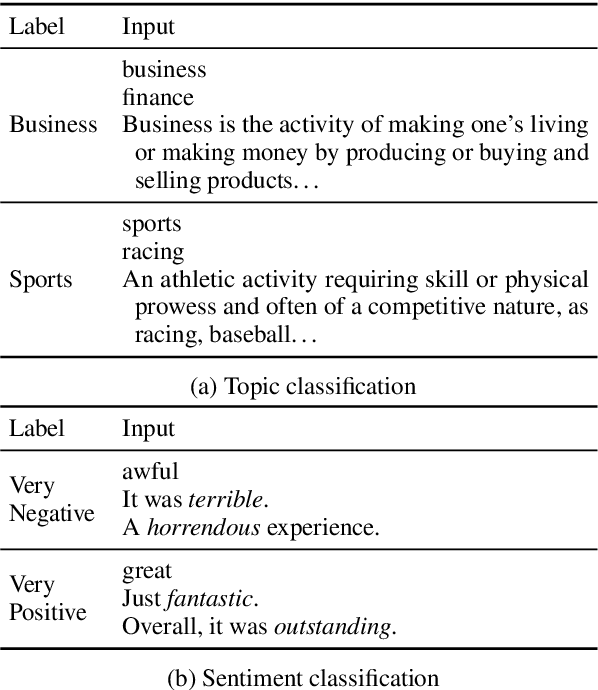
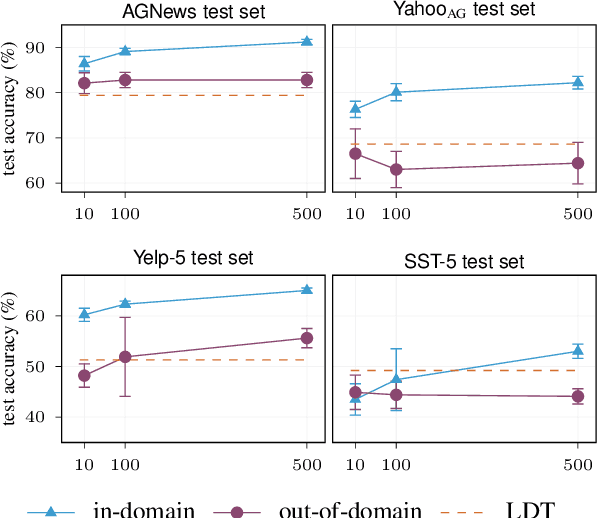
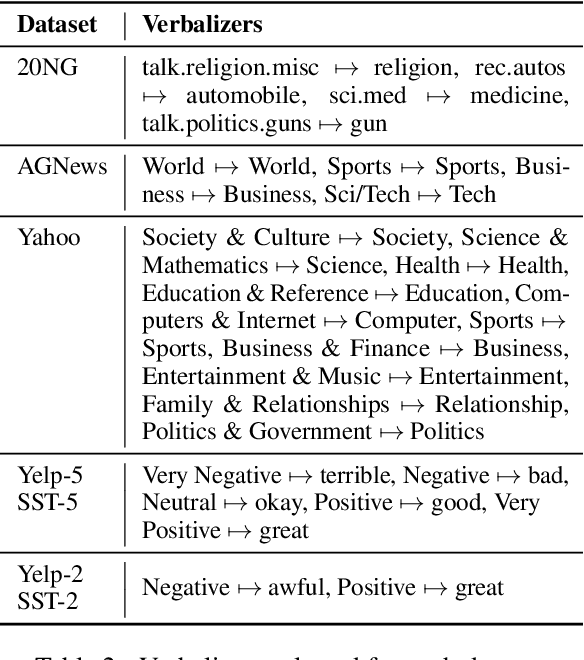
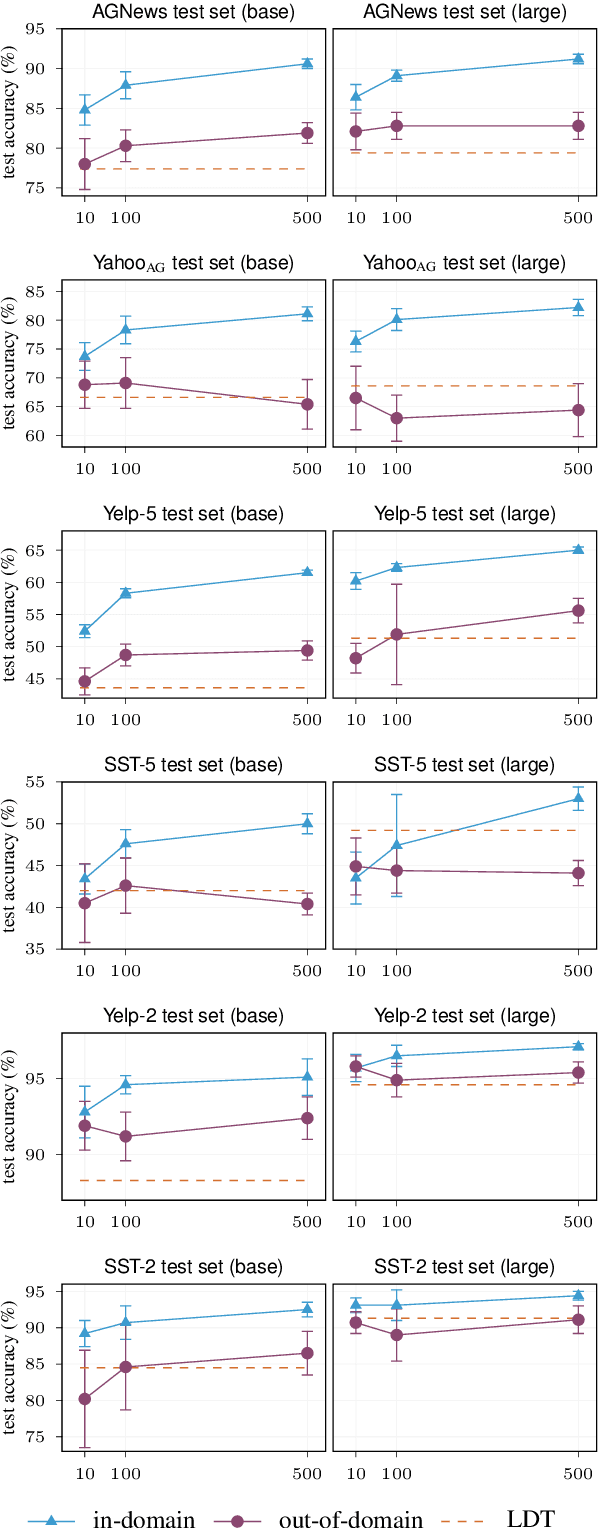
Large language models have improved zero-shot text classification by allowing the transfer of semantic knowledge from the training data in order to classify among specific label sets in downstream tasks. We propose a simple way to further improve zero-shot accuracies with minimal effort. We curate small finetuning datasets intended to describe the labels for a task. Unlike typical finetuning data, which has texts annotated with labels, our data simply describes the labels in language, e.g., using a few related terms, dictionary/encyclopedia entries, and short templates. Across a range of topic and sentiment datasets, our method is more accurate than zero-shot by 15-17% absolute. It is also more robust to choices required for zero-shot classification, such as patterns for prompting the model to classify and mappings from labels to tokens in the model's vocabulary. Furthermore, since our data merely describes the labels but does not use input texts, finetuning on it yields a model that performs strongly on multiple text domains for a given label set, even improving over few-shot out-of-domain classification in multiple settings.
Not Enough Labeled Data? Just Add Semantics: A Data-Efficient Method for Inferring Online Health Texts
Sep 18, 2023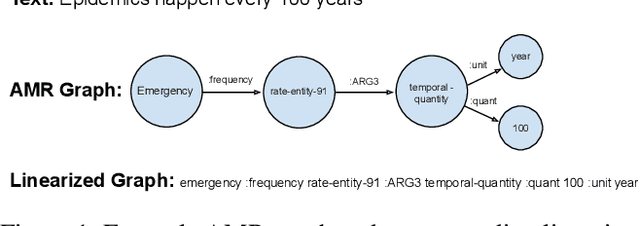
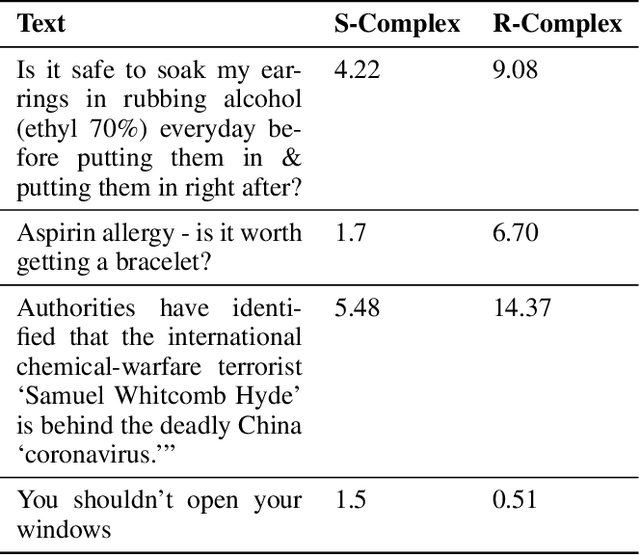
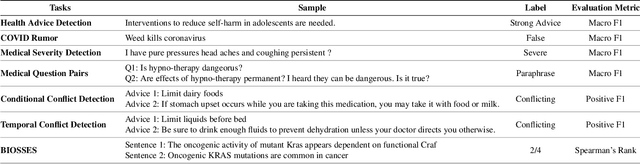

User-generated texts available on the web and social platforms are often long and semantically challenging, making them difficult to annotate. Obtaining human annotation becomes increasingly difficult as problem domains become more specialized. For example, many health NLP problems require domain experts to be a part of the annotation pipeline. Thus, it is crucial that we develop low-resource NLP solutions able to work with this set of limited-data problems. In this study, we employ Abstract Meaning Representation (AMR) graphs as a means to model low-resource Health NLP tasks sourced from various online health resources and communities. AMRs are well suited to model online health texts as they can represent multi-sentence inputs, abstract away from complex terminology, and model long-distance relationships between co-referring tokens. AMRs thus improve the ability of pre-trained language models to reason about high-complexity texts. Our experiments show that we can improve performance on 6 low-resource health NLP tasks by augmenting text embeddings with semantic graph embeddings. Our approach is task agnostic and easy to merge into any standard text classification pipeline. We experimentally validate that AMRs are useful in the modeling of complex texts by analyzing performance through the lens of two textual complexity measures: the Flesch Kincaid Reading Level and Syntactic Complexity. Our error analysis shows that AMR-infused language models perform better on complex texts and generally show less predictive variance in the presence of changing complexity.
GIST: Generating Image-Specific Text for Fine-grained Object Classification
Aug 04, 2023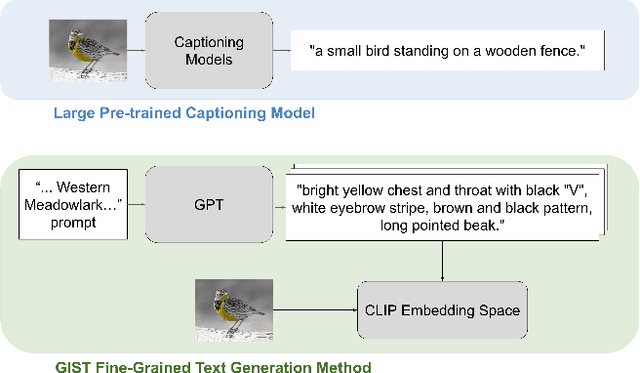
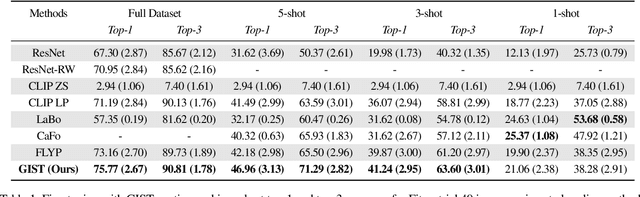
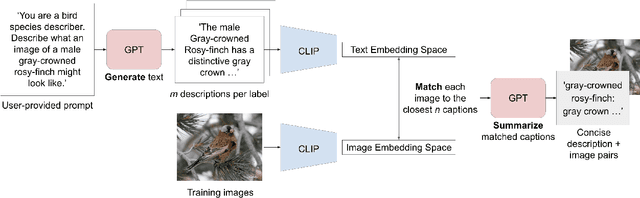
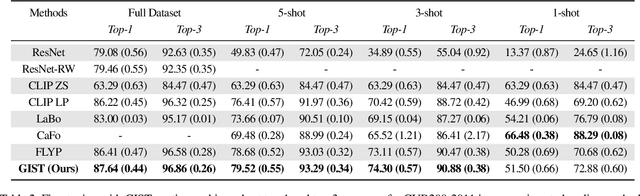
Recent vision-language models outperform vision-only models on many image classification tasks. However, because of the absence of paired text/image descriptions, it remains difficult to fine-tune these models for fine-grained image classification. In this work, we propose a method, GIST, for generating image-specific fine-grained text descriptions from image-only datasets, and show that these text descriptions can be used to improve classification. Key parts of our method include 1. prompting a pretrained large language model with domain-specific prompts to generate diverse fine-grained text descriptions for each class and 2. using a pretrained vision-language model to match each image to label-preserving text descriptions that capture relevant visual features in the image. We demonstrate the utility of GIST by fine-tuning vision-language models on the image-and-generated-text pairs to learn an aligned vision-language representation space for improved classification. We evaluate our learned representation space in full-shot and few-shot scenarios across four diverse fine-grained classification datasets, each from a different domain. Our method achieves an average improvement of $4.1\%$ in accuracy over CLIP linear probes and an average of $1.1\%$ improvement in accuracy over the previous state-of-the-art image-text classification method on the full-shot datasets. Our method achieves similar improvements across few-shot regimes. Code is available at https://github.com/emu1729/GIST.
SILC: Improving Vision Language Pretraining with Self-Distillation
Oct 20, 2023Image-Text pretraining on web-scale image caption dataset has become the default recipe for open vocabulary classification and retrieval models thanks to the success of CLIP and its variants. Several works have also used CLIP features for dense prediction tasks and have shown the emergence of open-set abilities. However, the contrastive objective only focuses on image-text alignment and does not incentivise image feature learning for dense prediction tasks. In this work, we propose the simple addition of local-to-global correspondence learning by self-distillation as an additional objective for contrastive pre-training to propose SILC. We show that distilling local image features from an exponential moving average (EMA) teacher model significantly improves model performance on several computer vision tasks including classification, retrieval, and especially segmentation. We further show that SILC scales better with the same training duration compared to the baselines. Our model SILC sets a new state of the art for zero-shot classification, few shot classification, image and text retrieval, zero-shot segmentation, and open vocabulary segmentation.
Key-phrase boosted unsupervised summary generation for FinTech organization
Oct 16, 2023With the recent advances in social media, the use of NLP techniques in social media data analysis has become an emerging research direction. Business organizations can particularly benefit from such an analysis of social media discourse, providing an external perspective on consumer behavior. Some of the NLP applications such as intent detection, sentiment classification, text summarization can help FinTech organizations to utilize the social media language data to find useful external insights and can be further utilized for downstream NLP tasks. Particularly, a summary which highlights the intents and sentiments of the users can be very useful for these organizations to get an external perspective. This external perspective can help organizations to better manage their products, offers, promotional campaigns, etc. However, certain challenges, such as a lack of labeled domain-specific datasets impede further exploration of these tasks in the FinTech domain. To overcome these challenges, we design an unsupervised phrase-based summary generation from social media data, using 'Action-Object' pairs (intent phrases). We evaluated the proposed method with other key-phrase based summary generation methods in the direction of contextual information of various Reddit discussion threads, available in the different summaries. We introduce certain "Context Metrics" such as the number of Unique words, Action-Object pairs, and Noun chunks to evaluate the contextual information retrieved from the source text in these phrase-based summaries. We demonstrate that our methods significantly outperform the baseline on these metrics, thus providing a qualitative and quantitative measure of their efficacy. Proposed framework has been leveraged as a web utility portal hosted within Amex.
MEGClass: Text Classification with Extremely Weak Supervision via Mutually-Enhancing Text Granularities
Apr 04, 2023


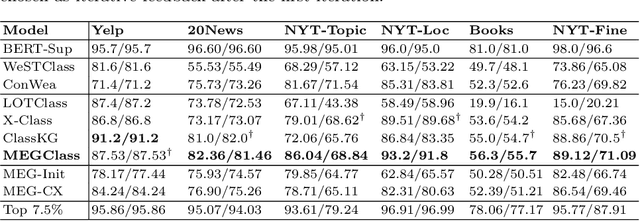
Text classification typically requires a substantial amount of human-annotated data to serve as supervision, which is costly to obtain in dynamic emerging domains. Certain methods seek to address this problem by solely relying on the surface text of class names to serve as extremely weak supervision. However, existing methods fail to account for single-class documents discussing multiple topics. Both topic diversity and vague sentences may introduce noise into the document's underlying representation and consequently the precision of the predicted class. Furthermore, current work focuses on text granularities (documents, sentences, or words) independently, which limits the degree of coarse- or fine-grained context that we can jointly extract from all three to identify significant subtext for classification. In order to address this problem, we propose MEGClass, an extremely weakly-supervised text classification method to exploit Mutually-Enhancing Text Granularities. Specifically, MEGClass constructs class-oriented sentence and class representations based on keywords for performing a sentence-level confidence-weighted label ensemble in order to estimate a document's initial class distribution. This serves as the target distribution for a multi-head attention network with a class-weighted contrastive loss. This network learns contextualized sentence representations and weights to form document representations that reflect its original document and sentence-level topic diversity. Retaining this heterogeneity allows MEGClass to select the most class-indicative documents to serve as iterative feedback for enhancing the class representations. Finally, these top documents are used to fine-tune a pre-trained text classifier. As demonstrated through extensive experiments on six benchmark datasets, MEGClass outperforms other weakly and extremely weakly supervised methods.
Differentiable Retrieval Augmentation via Generative Language Modeling for E-commerce Query Intent Classification
Aug 18, 2023
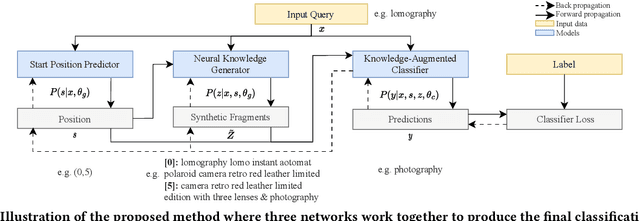
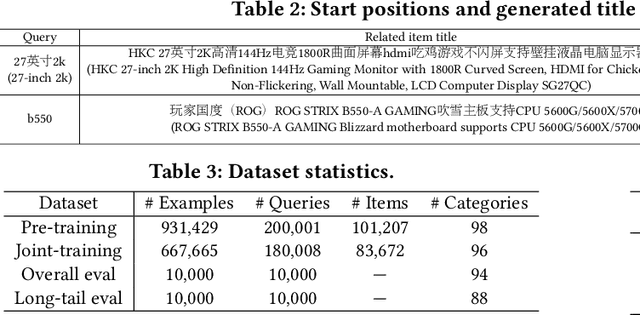
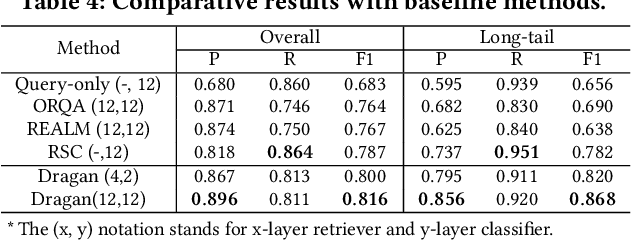
Retrieval augmentation, which enhances downstream models by a knowledge retriever and an external corpus instead of by merely increasing the number of model parameters, has been successfully applied to many natural language processing (NLP) tasks such as text classification, question answering and so on. However, existing methods that separately or asynchronously train the retriever and downstream model mainly due to the non-differentiability between the two parts, usually lead to degraded performance compared to end-to-end joint training.
Tag Prediction of Competitive Programming Problems using Deep Learning Techniques
Aug 03, 2023In the past decade, the amount of research being done in the fields of machine learning and deep learning, predominantly in the area of natural language processing (NLP), has risen dramatically. A well-liked method for developing programming abilities like logic building and problem solving is competitive programming. It can be tough for novices and even veteran programmers to traverse the wide collection of questions due to the massive number of accessible questions and the variety of themes, levels of difficulty, and questions offered. In order to help programmers find questions that are appropriate for their knowledge and interests, there is a need for an automated method. This can be done using automated tagging of the questions using Text Classification. Text classification is one of the important tasks widely researched in the field of Natural Language Processing. In this paper, we present a way to use text classification techniques to determine the domain of a competitive programming problem. A variety of models, including are implemented LSTM, GRU, and MLP. The dataset has been scraped from Codeforces, a major competitive programming website. A total of 2400 problems were scraped and preprocessed, which we used as a dataset for our training and testing of models. The maximum accuracy reached using our model is 78.0% by MLP(Multi Layer Perceptron).
Utilizing Weak Supervision To Generate Indonesian Conservation Dataset
Oct 24, 2023Weak supervision has emerged as a promising approach for rapid and large-scale dataset creation in response to the increasing demand for accelerated NLP development. By leveraging labeling functions, weak supervision allows practitioners to generate datasets quickly by creating learned label models that produce soft-labeled datasets. This paper aims to show how such an approach can be utilized to build an Indonesian NLP dataset from conservation news text. We construct two types of datasets: multi-class classification and sentiment classification. We then provide baseline experiments using various pretrained language models. These baseline results demonstrate test performances of 59.79% accuracy and 55.72% F1-score for sentiment classification, 66.87% F1-score-macro, 71.5% F1-score-micro, and 83.67% ROC-AUC for multi-class classification. Additionally, we release the datasets and labeling functions used in this work for further research and exploration.