 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
AMPLIFY:Attention-based Mixup for Performance Improvement and Label Smoothing in Transformer
Sep 22, 2023
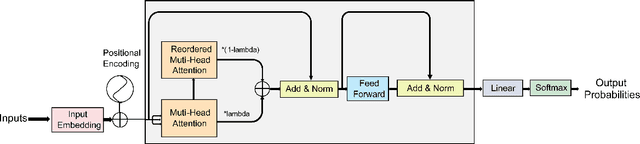
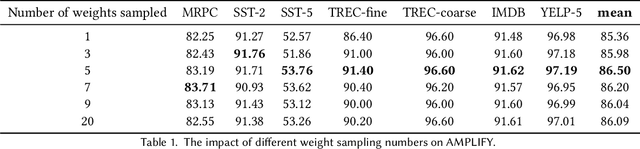

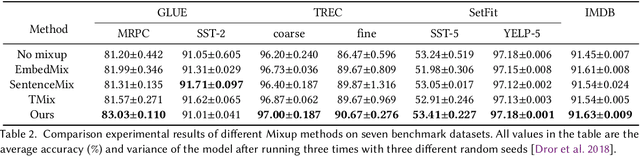
Mixup is an effective data augmentation method that generates new augmented samples by aggregating linear combinations of different original samples. However, if there are noises or aberrant features in the original samples, Mixup may propagate them to the augmented samples, leading to over-sensitivity of the model to these outliers . To solve this problem, this paper proposes a new Mixup method called AMPLIFY. This method uses the Attention mechanism of Transformer itself to reduce the influence of noises and aberrant values in the original samples on the prediction results, without increasing additional trainable parameters, and the computational cost is very low, thereby avoiding the problem of high resource consumption in common Mixup methods such as Sentence Mixup . The experimental results show that, under a smaller computational resource cost, AMPLIFY outperforms other Mixup methods in text classification tasks on 7 benchmark datasets, providing new ideas and new ways to further improve the performance of pre-trained models based on the Attention mechanism, such as BERT, ALBERT, RoBERTa, and GPT. Our code can be obtained at https://github.com/kiwi-lilo/AMPLIFY.
CrisisTransformers: Pre-trained language models and sentence encoders for crisis-related social media texts
Oct 01, 2023
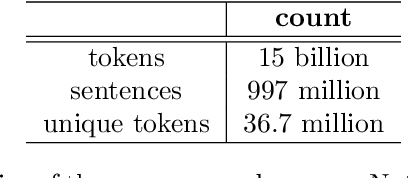
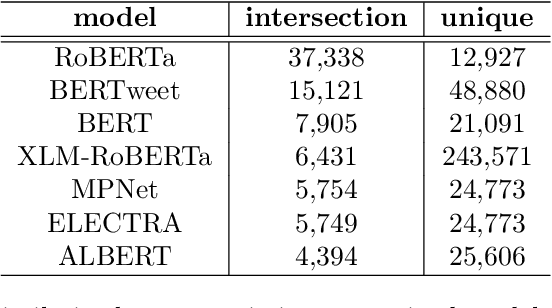
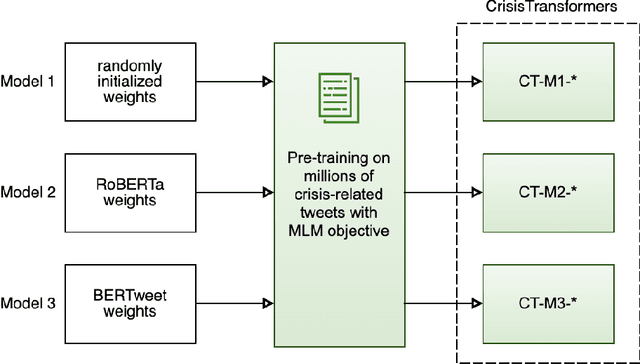
Social media platforms play an essential role in crisis communication, but analyzing crisis-related social media texts is challenging due to their informal nature. Transformer-based pre-trained models like BERT and RoBERTa have shown success in various NLP tasks, but they are not tailored for crisis-related texts. Furthermore, general-purpose sentence encoders are used to generate sentence embeddings, regardless of the textual complexities in crisis-related texts. Advances in applications like text classification, semantic search, and clustering contribute to effective processing of crisis-related texts, which is essential for emergency responders to gain a comprehensive view of a crisis event, whether historical or real-time. To address these gaps in crisis informatics literature, this study introduces CrisisTransformers, an ensemble of pre-trained language models and sentence encoders trained on an extensive corpus of over 15 billion word tokens from tweets associated with more than 30 crisis events, including disease outbreaks, natural disasters, conflicts, and other critical incidents. We evaluate existing models and CrisisTransformers on 18 crisis-specific public datasets. Our pre-trained models outperform strong baselines across all datasets in classification tasks, and our best-performing sentence encoder improves the state-of-the-art by 17.43% in sentence encoding tasks. Additionally, we investigate the impact of model initialization on convergence and evaluate the significance of domain-specific models in generating semantically meaningful sentence embeddings. All models are publicly released (https://huggingface.co/crisistransformers), with the anticipation that they will serve as a robust baseline for tasks involving the analysis of crisis-related social media texts.
A Comparative Study on TF-IDF feature Weighting Method and its Analysis using Unstructured Dataset
Aug 08, 2023
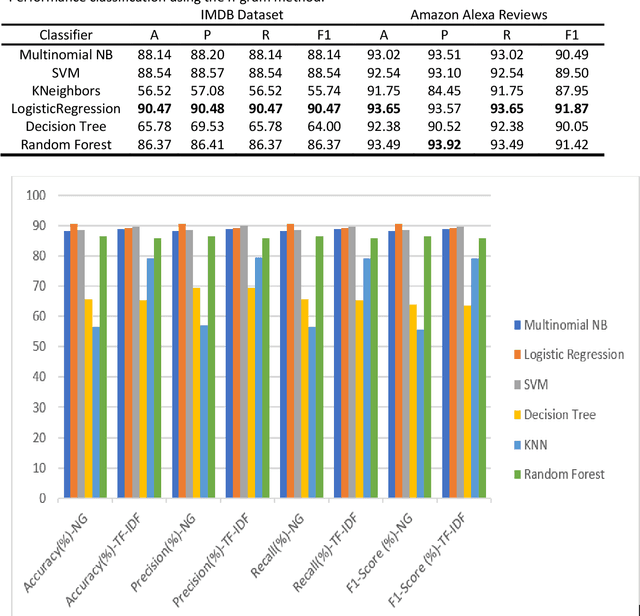
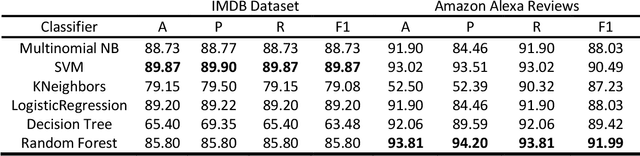
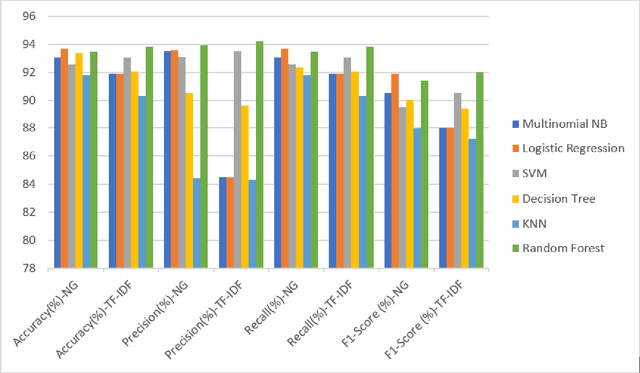
Text Classification is the process of categorizing text into the relevant categories and its algorithms are at the core of many Natural Language Processing (NLP). Term Frequency-Inverse Document Frequency (TF-IDF) and NLP are the most highly used information retrieval methods in text classification. We have investigated and analyzed the feature weighting method for text classification on unstructured data. The proposed model considered two features N-Grams and TF-IDF on the IMDB movie reviews and Amazon Alexa reviews dataset for sentiment analysis. Then we have used the state-of-the-art classifier to validate the method i.e., Support Vector Machine (SVM), Logistic Regression, Multinomial Naive Bayes (Multinomial NB), Random Forest, Decision Tree, and k-nearest neighbors (KNN). From those two feature extractions, a significant increase in feature extraction with TF-IDF features rather than based on N-Gram. TF-IDF got the maximum accuracy (93.81%), precision (94.20%), recall (93.81%), and F1-score (91.99%) value in Random Forest classifier.
Low-Resource Named Entity Recognition: Can One-vs-All AUC Maximization Help?
Nov 02, 2023Named entity recognition (NER), a task that identifies and categorizes named entities such as persons or organizations from text, is traditionally framed as a multi-class classification problem. However, this approach often overlooks the issues of imbalanced label distributions, particularly in low-resource settings, which is common in certain NER contexts, like biomedical NER (bioNER). To address these issues, we propose an innovative reformulation of the multi-class problem as a one-vs-all (OVA) learning problem and introduce a loss function based on the area under the receiver operating characteristic curve (AUC). To enhance the efficiency of our OVA-based approach, we propose two training strategies: one groups labels with similar linguistic characteristics, and another employs meta-learning. The superiority of our approach is confirmed by its performance, which surpasses traditional NER learning in varying NER settings.
LLMs as Counterfactual Explanation Modules: Can ChatGPT Explain Black-box Text Classifiers?
Sep 23, 2023Large language models (LLMs) are increasingly being used for tasks beyond text generation, including complex tasks such as data labeling, information extraction, etc. With the recent surge in research efforts to comprehend the full extent of LLM capabilities, in this work, we investigate the role of LLMs as counterfactual explanation modules, to explain decisions of black-box text classifiers. Inspired by causal thinking, we propose a pipeline for using LLMs to generate post-hoc, model-agnostic counterfactual explanations in a principled way via (i) leveraging the textual understanding capabilities of the LLM to identify and extract latent features, and (ii) leveraging the perturbation and generation capabilities of the same LLM to generate a counterfactual explanation by perturbing input features derived from the extracted latent features. We evaluate three variants of our framework, with varying degrees of specificity, on a suite of state-of-the-art LLMs, including ChatGPT and LLaMA 2. We evaluate the effectiveness and quality of the generated counterfactual explanations, over a variety of text classification benchmarks. Our results show varied performance of these models in different settings, with a full two-step feature extraction based variant outperforming others in most cases. Our pipeline can be used in automated explanation systems, potentially reducing human effort.
Meta learning with language models: Challenges and opportunities in the classification of imbalanced text
Oct 24, 2023Detecting out of policy speech (OOPS) content is important but difficult. While machine learning is a powerful tool to tackle this challenging task, it is hard to break the performance ceiling due to factors like quantity and quality limitations on training data and inconsistencies in OOPS definition and data labeling. To realize the full potential of available limited resources, we propose a meta learning technique (MLT) that combines individual models built with different text representations. We analytically show that the resulting technique is numerically stable and produces reasonable combining weights. We combine the MLT with a threshold-moving (TM) technique to further improve the performance of the combined predictor on highly-imbalanced in-distribution and out-of-distribution datasets. We also provide computational results to show the statistically significant advantages of the proposed MLT approach. All authors contributed equally to this work.
Large Language Models for Failure Mode Classification: An Investigation
Sep 15, 2023In this paper we present the first investigation into the effectiveness of Large Language Models (LLMs) for Failure Mode Classification (FMC). FMC, the task of automatically labelling an observation with a corresponding failure mode code, is a critical task in the maintenance domain as it reduces the need for reliability engineers to spend their time manually analysing work orders. We detail our approach to prompt engineering to enable an LLM to predict the failure mode of a given observation using a restricted code list. We demonstrate that the performance of a GPT-3.5 model (F1=0.80) fine-tuned on annotated data is a significant improvement over a currently available text classification model (F1=0.60) trained on the same annotated data set. The fine-tuned model also outperforms the out-of-the box GPT-3.5 (F1=0.46). This investigation reinforces the need for high quality fine-tuning data sets for domain-specific tasks using LLMs.
When Automated Assessment Meets Automated Content Generation: Examining Text Quality in the Era of GPTs
Sep 25, 2023
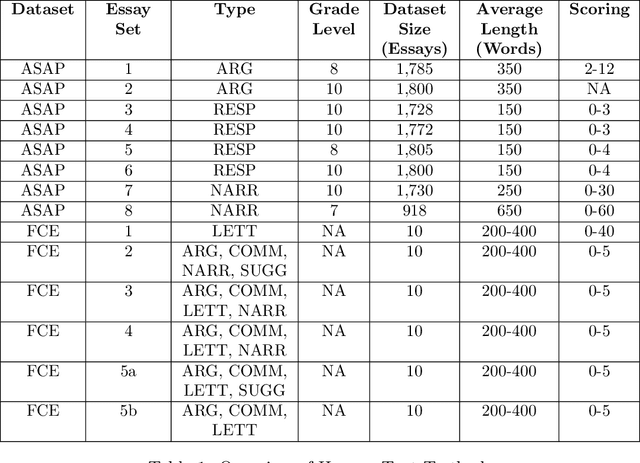
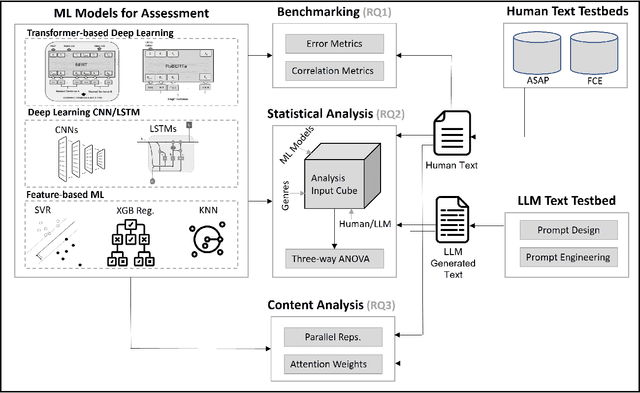
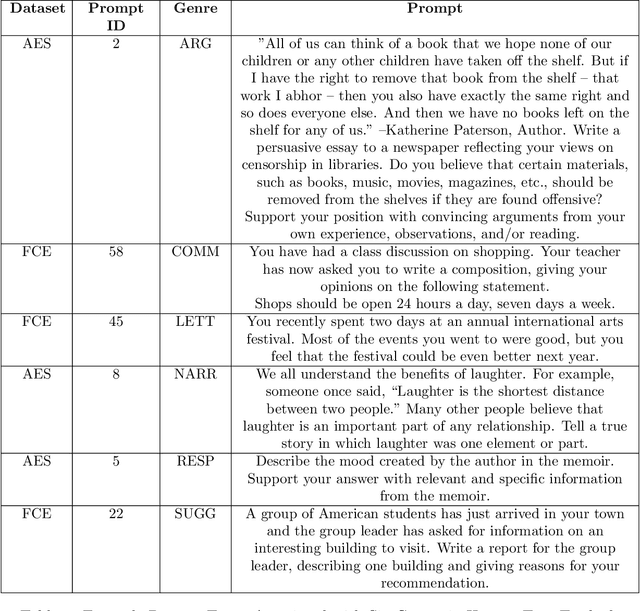
The use of machine learning (ML) models to assess and score textual data has become increasingly pervasive in an array of contexts including natural language processing, information retrieval, search and recommendation, and credibility assessment of online content. A significant disruption at the intersection of ML and text are text-generating large-language models such as generative pre-trained transformers (GPTs). We empirically assess the differences in how ML-based scoring models trained on human content assess the quality of content generated by humans versus GPTs. To do so, we propose an analysis framework that encompasses essay scoring ML-models, human and ML-generated essays, and a statistical model that parsimoniously considers the impact of type of respondent, prompt genre, and the ML model used for assessment model. A rich testbed is utilized that encompasses 18,460 human-generated and GPT-based essays. Results of our benchmark analysis reveal that transformer pretrained language models (PLMs) more accurately score human essay quality as compared to CNN/RNN and feature-based ML methods. Interestingly, we find that the transformer PLMs tend to score GPT-generated text 10-15\% higher on average, relative to human-authored documents. Conversely, traditional deep learning and feature-based ML models score human text considerably higher. Further analysis reveals that although the transformer PLMs are exclusively fine-tuned on human text, they more prominently attend to certain tokens appearing only in GPT-generated text, possibly due to familiarity/overlap in pre-training. Our framework and results have implications for text classification settings where automated scoring of text is likely to be disrupted by generative AI.
Food Classification using Joint Representation of Visual and Textual Data
Aug 03, 2023Food classification is an important task in health care. In this work, we propose a multimodal classification framework that uses the modified version of EfficientNet with the Mish activation function for image classification, and the traditional BERT transformer-based network is used for text classification. The proposed network and the other state-of-the-art methods are evaluated on a large open-source dataset, UPMC Food-101. The experimental results show that the proposed network outperforms the other methods, a significant difference of 11.57% and 6.34% in accuracy is observed for image and text classification, respectively, when compared with the second-best performing method. We also compared the performance in terms of accuracy, precision, and recall for text classification using both machine learning and deep learning-based models. The comparative analysis from the prediction results of both images and text demonstrated the efficiency and robustness of the proposed approach.