 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Neural Text Sanitization with Privacy Risk Indicators: An Empirical Analysis
Oct 22, 2023
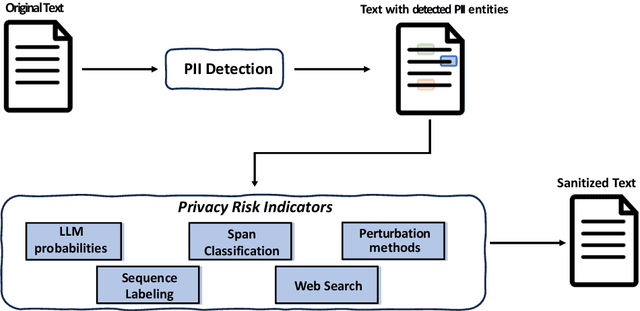


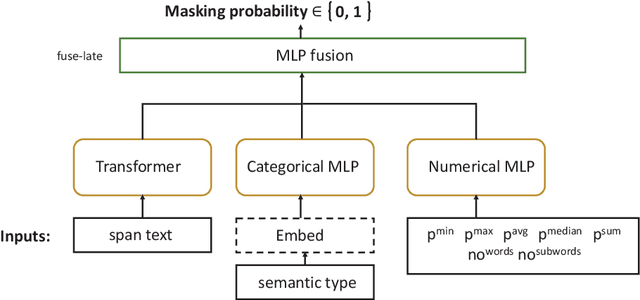
Text sanitization is the task of redacting a document to mask all occurrences of (direct or indirect) personal identifiers, with the goal of concealing the identity of the individual(s) referred in it. In this paper, we consider a two-step approach to text sanitization and provide a detailed analysis of its empirical performance on two recently published datasets: the Text Anonymization Benchmark (Pil\'an et al., 2022) and a collection of Wikipedia biographies (Papadopoulou et al., 2022). The text sanitization process starts with a privacy-oriented entity recognizer that seeks to determine the text spans expressing identifiable personal information. This privacy-oriented entity recognizer is trained by combining a standard named entity recognition model with a gazetteer populated by person-related terms extracted from Wikidata. The second step of the text sanitization process consists in assessing the privacy risk associated with each detected text span, either isolated or in combination with other text spans. We present five distinct indicators of the re-identification risk, respectively based on language model probabilities, text span classification, sequence labelling, perturbations, and web search. We provide a contrastive analysis of each privacy indicator and highlight their benefits and limitations, notably in relation to the available labeled data.
CFBenchmark: Chinese Financial Assistant Benchmark for Large Language Model
Nov 10, 2023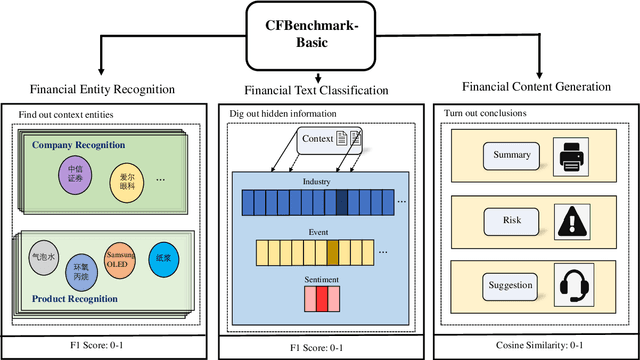
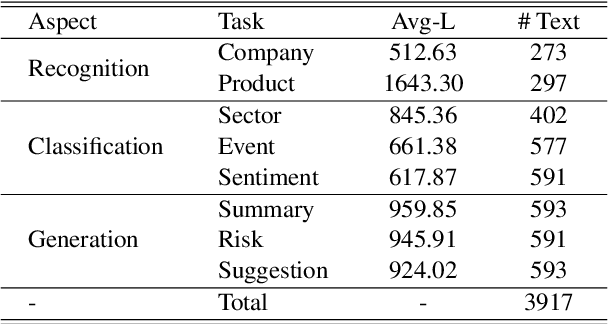

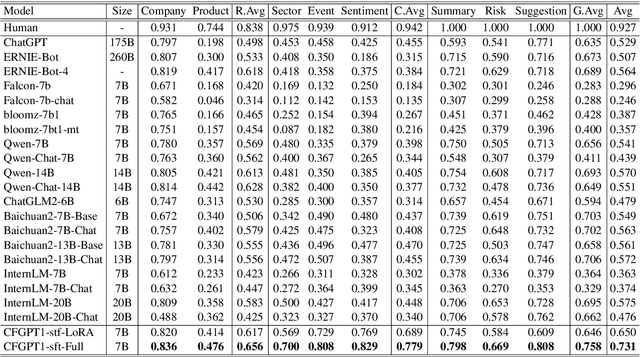
Large language models (LLMs) have demonstrated great potential in the financial domain. Thus, it becomes important to assess the performance of LLMs in the financial tasks. In this work, we introduce CFBenchmark, to evaluate the performance of LLMs for Chinese financial assistant. The basic version of CFBenchmark is designed to evaluate the basic ability in Chinese financial text processing from three aspects~(\emph{i.e.} recognition, classification, and generation) including eight tasks, and includes financial texts ranging in length from 50 to over 1,800 characters. We conduct experiments on several LLMs available in the literature with CFBenchmark-Basic, and the experimental results indicate that while some LLMs show outstanding performance in specific tasks, overall, there is still significant room for improvement in basic tasks of financial text processing with existing models. In the future, we plan to explore the advanced version of CFBenchmark, aiming to further explore the extensive capabilities of language models in more profound dimensions as a financial assistant in Chinese. Our codes are released at https://github.com/TongjiFinLab/CFBenchmark.
Open, Closed, or Small Language Models for Text Classification?
Aug 19, 2023
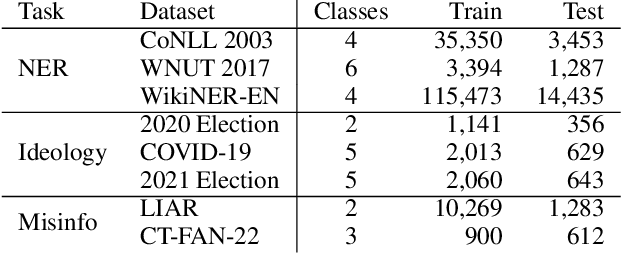
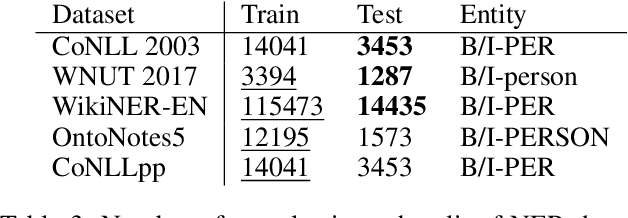
Recent advancements in large language models have demonstrated remarkable capabilities across various NLP tasks. But many questions remain, including whether open-source models match closed ones, why these models excel or struggle with certain tasks, and what types of practical procedures can improve performance. We address these questions in the context of classification by evaluating three classes of models using eight datasets across three distinct tasks: named entity recognition, political party prediction, and misinformation detection. While larger LLMs often lead to improved performance, open-source models can rival their closed-source counterparts by fine-tuning. Moreover, supervised smaller models, like RoBERTa, can achieve similar or even greater performance in many datasets compared to generative LLMs. On the other hand, closed models maintain an advantage in hard tasks that demand the most generalizability. This study underscores the importance of model selection based on task requirements
A Comparative Study of Transformer-based Neural Text Representation Techniques on Bug Triaging
Oct 10, 2023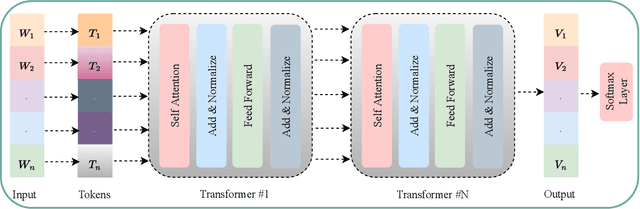
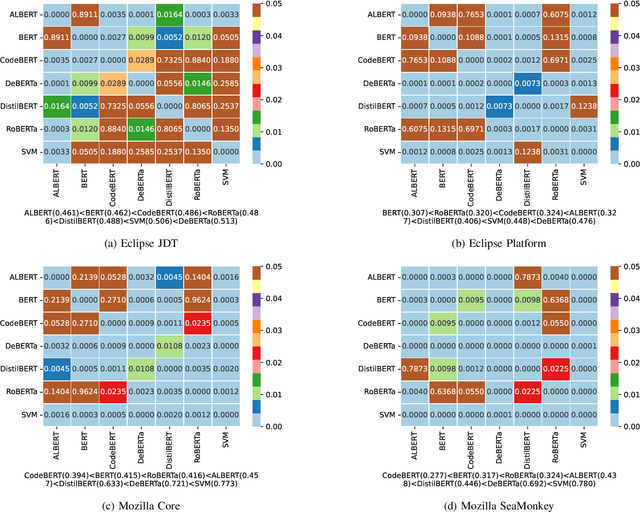
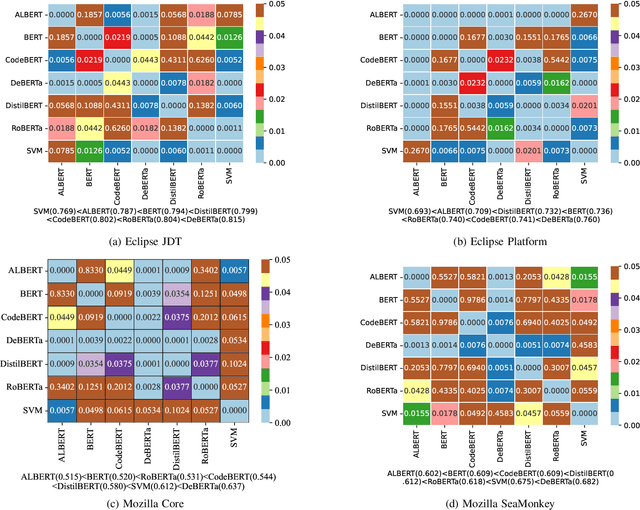
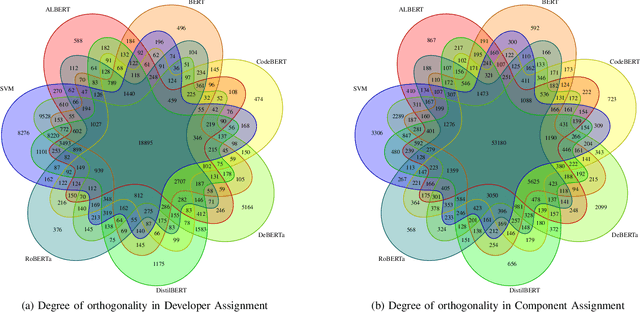
Often, the first step in managing bug reports is related to triaging a bug to the appropriate developer who is best suited to understand, localize, and fix the target bug. Additionally, assigning a given bug to a particular part of a software project can help to expedite the fixing process. However, despite the importance of these activities, they are quite challenging, where days can be spent on the manual triaging process. Past studies have attempted to leverage the limited textual data of bug reports to train text classification models that automate this process -- to varying degrees of success. However, the textual representations and machine learning models used in prior work are limited by their expressiveness, often failing to capture nuanced textual patterns that might otherwise aid in the triaging process. Recently, large, transformer-based, pre-trained neural text representation techniques such as BERT have achieved greater performance in several natural language processing tasks. However, the potential for using these techniques to improve upon prior approaches for automated bug triaging is not well studied or understood. Therefore, in this paper we offer one of the first investigations that fine-tunes transformer-based language models for the task of bug triaging on four open source datasets, spanning a collective 53 years of development history with over 400 developers and over 150 software project components. Our study includes both a quantitative and qualitative analysis of effectiveness. Our findings illustrate that DeBERTa is the most effective technique across the triaging tasks of developer and component assignment, and the measured performance delta is statistically significant compared to other techniques. However, through our qualitative analysis, we also observe that each technique possesses unique abilities best suited to certain types of bug reports.
A Benchmark on Extremely Weakly Supervised Text Classification: Reconcile Seed Matching and Prompting Approaches
May 22, 2023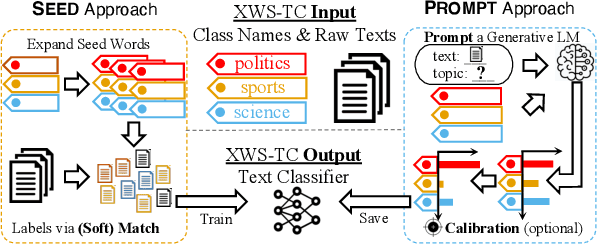
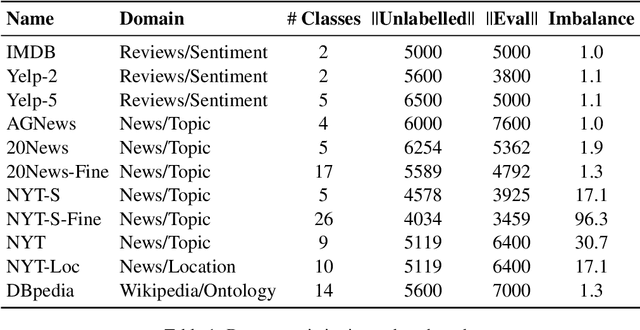
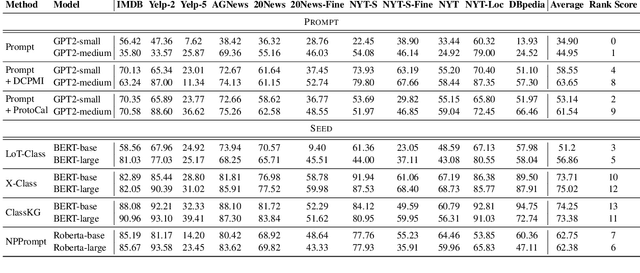
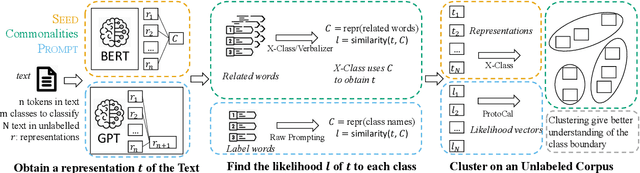
Etremely Weakly Supervised Text Classification (XWS-TC) refers to text classification based on minimal high-level human guidance, such as a few label-indicative seed words or classification instructions. There are two mainstream approaches for XWS-TC, however, never being rigorously compared: (1) training classifiers based on pseudo-labels generated by (softly) matching seed words (SEED) and (2) prompting (and calibrating) language models using classification instruction (and raw texts) to decode label words (PROMPT). This paper presents the first XWS-TC benchmark to compare the two approaches on fair grounds, where the datasets, supervisions, and hyperparameter choices are standardized across methods. Our benchmarking results suggest that (1) Both SEED and PROMPT approaches are competitive and there is no clear winner; (2) SEED is empirically more tolerant than PROMPT to human guidance (e.g., seed words, classification instructions, and label words) changes; (3) SEED is empirically more selective than PROMPT to the pre-trained language models; (4) Recent SEED and PROMPT methods have close connections and a clustering post-processing step based on raw in-domain texts is a strong performance booster to both. We hope this benchmark serves as a guideline in selecting XWS-TC methods in different scenarios and stimulate interest in developing guidance- and model-robust XWS-TC methods. We release the repo at https://github.com/ZihanWangKi/x-TC.
Out-of-Distribution Generalization in Text Classification: Past, Present, and Future
May 23, 2023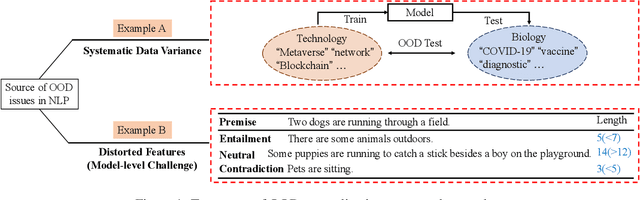

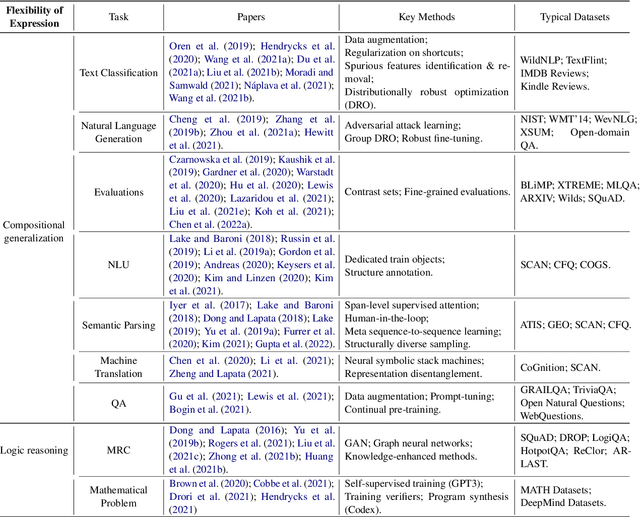
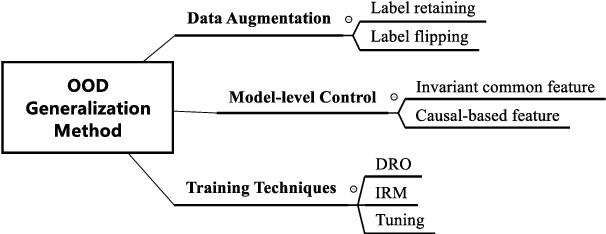
Machine learning (ML) systems in natural language processing (NLP) face significant challenges in generalizing to out-of-distribution (OOD) data, where the test distribution differs from the training data distribution. This poses important questions about the robustness of NLP models and their high accuracy, which may be artificially inflated due to their underlying sensitivity to systematic biases. Despite these challenges, there is a lack of comprehensive surveys on the generalization challenge from an OOD perspective in text classification. Therefore, this paper aims to fill this gap by presenting the first comprehensive review of recent progress, methods, and evaluations on this topic. We furth discuss the challenges involved and potential future research directions. By providing quick access to existing work, we hope this survey will encourage future research in this area.
TART: Improved Few-shot Text Classification Using Task-Adaptive Reference Transformation
Jun 03, 2023

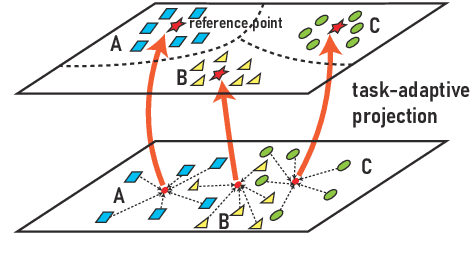
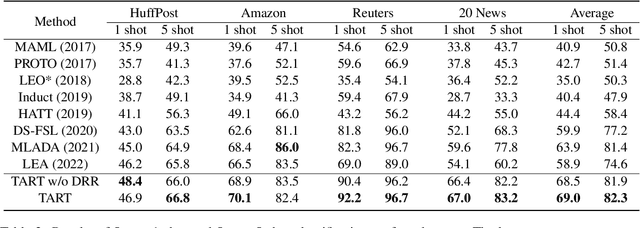
Meta-learning has emerged as a trending technique to tackle few-shot text classification and achieve state-of-the-art performance. However, the performance of existing approaches heavily depends on the inter-class variance of the support set. As a result, it can perform well on tasks when the semantics of sampled classes are distinct while failing to differentiate classes with similar semantics. In this paper, we propose a novel Task-Adaptive Reference Transformation (TART) network, aiming to enhance the generalization by transforming the class prototypes to per-class fixed reference points in task-adaptive metric spaces. To further maximize divergence between transformed prototypes in task-adaptive metric spaces, TART introduces a discriminative reference regularization among transformed prototypes. Extensive experiments are conducted on four benchmark datasets and our method demonstrates clear superiority over the state-of-the-art models in all the datasets. In particular, our model surpasses the state-of-the-art method by 7.4% and 5.4% in 1-shot and 5-shot classification on the 20 Newsgroups dataset, respectively.
Identifying Semantically Difficult Samples to Improve Text Classification
Feb 13, 2023
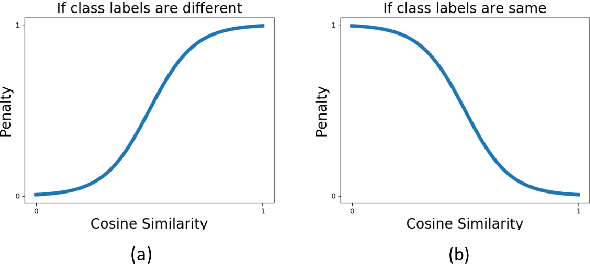
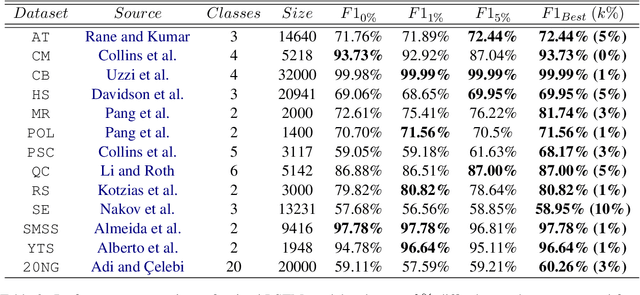

In this paper, we investigate the effect of addressing difficult samples from a given text dataset on the downstream text classification task. We define difficult samples as being non-obvious cases for text classification by analysing them in the semantic embedding space; specifically - (i) semantically similar samples that belong to different classes and (ii) semantically dissimilar samples that belong to the same class. We propose a penalty function to measure the overall difficulty score of every sample in the dataset. We conduct exhaustive experiments on 13 standard datasets to show a consistent improvement of up to 9% and discuss qualitative results to show effectiveness of our approach in identifying difficult samples for a text classification model.
Robust Sentiment Analysis for Low Resource languages Using Data Augmentation Approaches: A Case Study in Marathi
Oct 01, 2023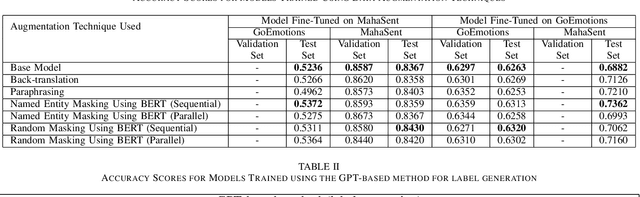

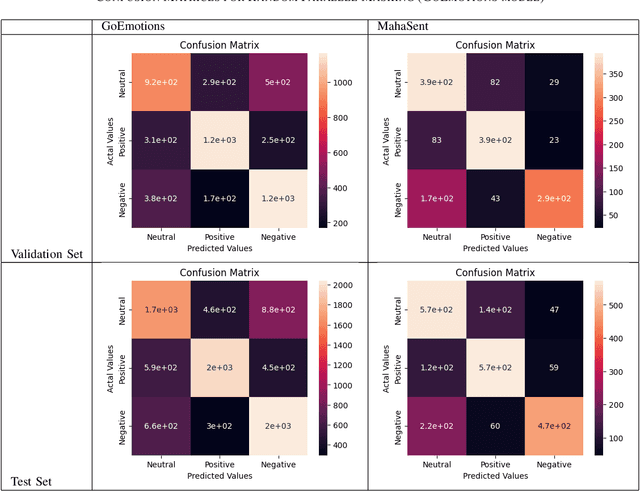
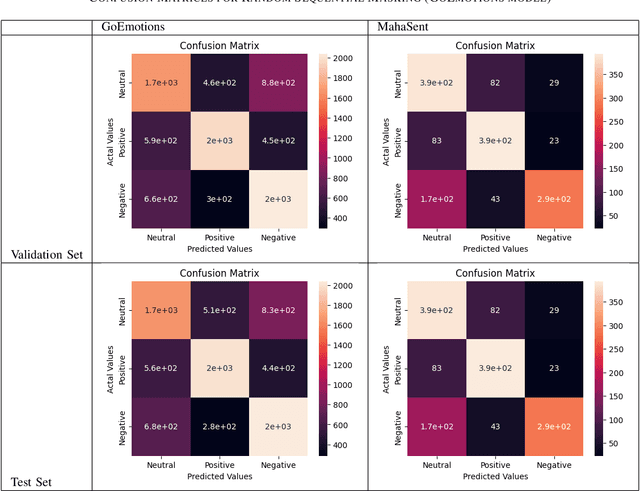
Sentiment analysis plays a crucial role in understanding the sentiment expressed in text data. While sentiment analysis research has been extensively conducted in English and other Western languages, there exists a significant gap in research efforts for sentiment analysis in low-resource languages. Limited resources, including datasets and NLP research, hinder the progress in this area. In this work, we present an exhaustive study of data augmentation approaches for the low-resource Indic language Marathi. Although domain-specific datasets for sentiment analysis in Marathi exist, they often fall short when applied to generalized and variable-length inputs. To address this challenge, this research paper proposes four data augmentation techniques for sentiment analysis in Marathi. The paper focuses on augmenting existing datasets to compensate for the lack of sufficient resources. The primary objective is to enhance sentiment analysis model performance in both in-domain and cross-domain scenarios by leveraging data augmentation strategies. The data augmentation approaches proposed showed a significant performance improvement for cross-domain accuracies. The augmentation methods include paraphrasing, back-translation; BERT-based random token replacement, named entity replacement, and pseudo-label generation; GPT-based text and label generation. Furthermore, these techniques can be extended to other low-resource languages and for general text classification tasks.
Label Dependencies-aware Set Prediction Networks for Multi-label Text Classification
Apr 14, 2023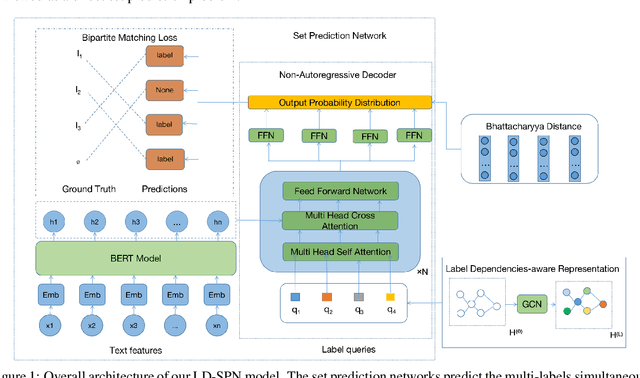

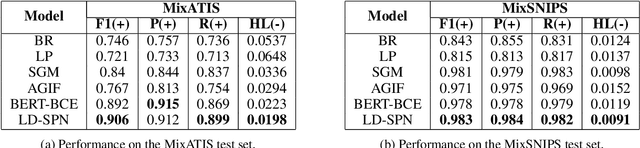
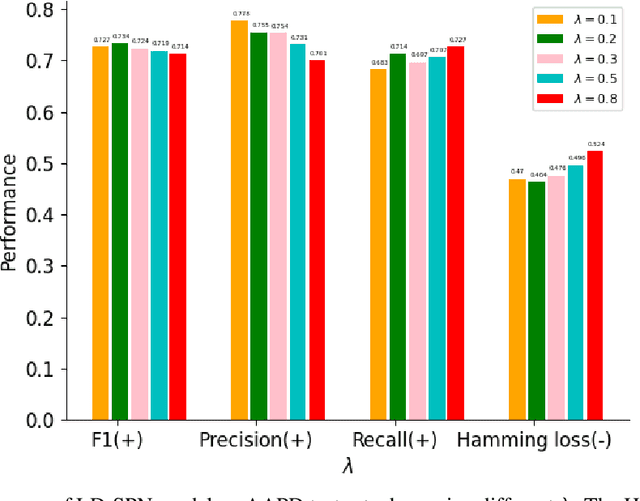
Multi-label text classification aims to extract all the related labels from a sentence, which can be viewed as a sequence generation problem. However, the labels in training dataset are unordered. We propose to treat it as a direct set prediction problem and don't need to consider the order of labels. Besides, in order to model the correlation between labels, the adjacency matrix is constructed through the statistical relations between labels and GCN is employed to learn the label information. Based on the learned label information, the set prediction networks can both utilize the sentence information and label information for multi-label text classification simultaneously. Furthermore, the Bhattacharyya distance is imposed on the output probability distributions of the set prediction networks to increase the recall ability. Experimental results on four multi-label datasets show the effectiveness of the proposed method and it outperforms previous method a substantial margin.