 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Harnessing Pre-Trained Sentence Transformers for Offensive Language Detection in Indian Languages
Oct 03, 2023
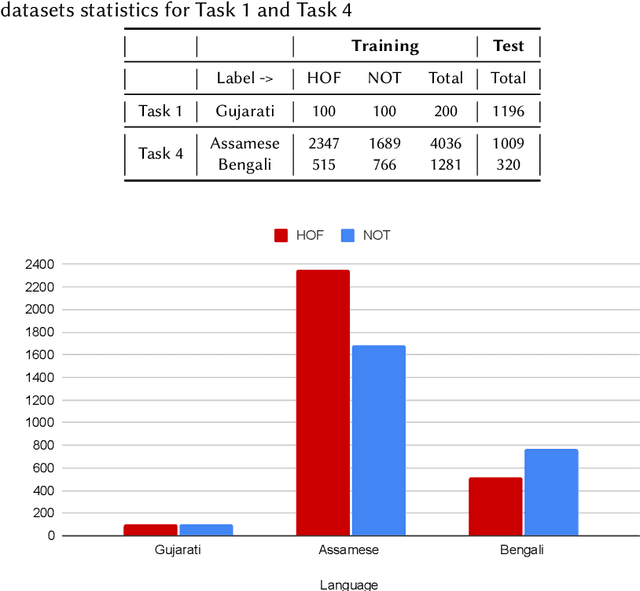
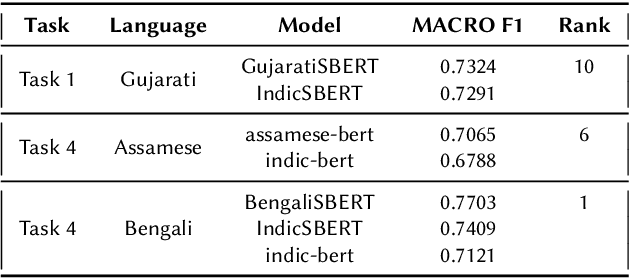
In our increasingly interconnected digital world, social media platforms have emerged as powerful channels for the dissemination of hate speech and offensive content. This work delves into the domain of hate speech detection, placing specific emphasis on three low-resource Indian languages: Bengali, Assamese, and Gujarati. The challenge is framed as a text classification task, aimed at discerning whether a tweet contains offensive or non-offensive content. Leveraging the HASOC 2023 datasets, we fine-tuned pre-trained BERT and SBERT models to evaluate their effectiveness in identifying hate speech. Our findings underscore the superiority of monolingual sentence-BERT models, particularly in the Bengali language, where we achieved the highest ranking. However, the performance in Assamese and Gujarati languages signifies ongoing opportunities for enhancement. Our goal is to foster inclusive online spaces by countering hate speech proliferation.
DKEC: Domain Knowledge Enhanced Multi-Label Classification for Electronic Health Records
Oct 10, 2023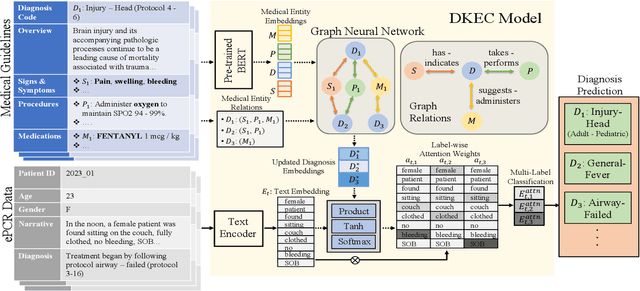



Multi-label text classification (MLTC) tasks in the medical domain often face long-tail label distribution, where rare classes have fewer training samples than frequent classes. Although previous works have explored different model architectures and hierarchical label structures to find important features, most of them neglect to incorporate the domain knowledge from medical guidelines. In this paper, we present DKEC, Domain Knowledge Enhanced Classifier for medical diagnosis prediction with two innovations: (1) a label-wise attention mechanism that incorporates a heterogeneous graph and domain ontologies to capture the semantic relationships between medical entities, (2) a simple yet effective group-wise training method based on similarity of labels to increase samples of rare classes. We evaluate DKEC on two real-world medical datasets: the RAA dataset, a collection of 4,417 patient care reports from emergency medical services (EMS) incidents, and a subset of 53,898 reports from the MIMIC-III dataset. Experimental results show that our method outperforms the state-of-the-art, particularly for the few-shot (tail) classes. More importantly, we study the applicability of DKEC to different language models and show that DKEC can help the smaller language models achieve comparable performance to large language models.
Representing visual classification as a linear combination of words
Nov 18, 2023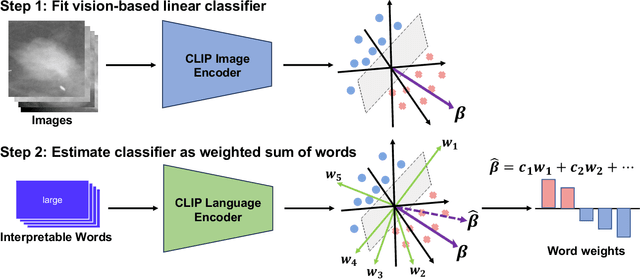
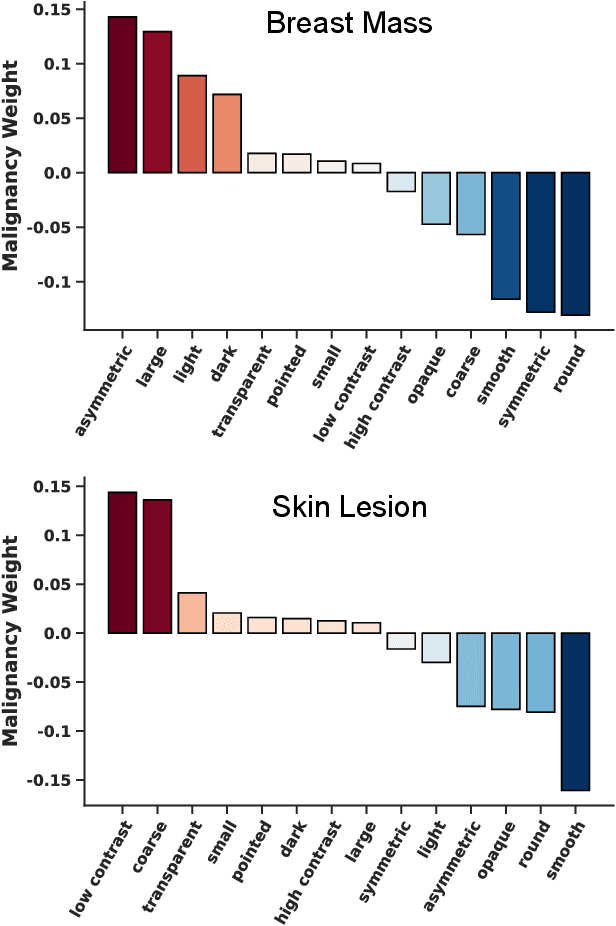
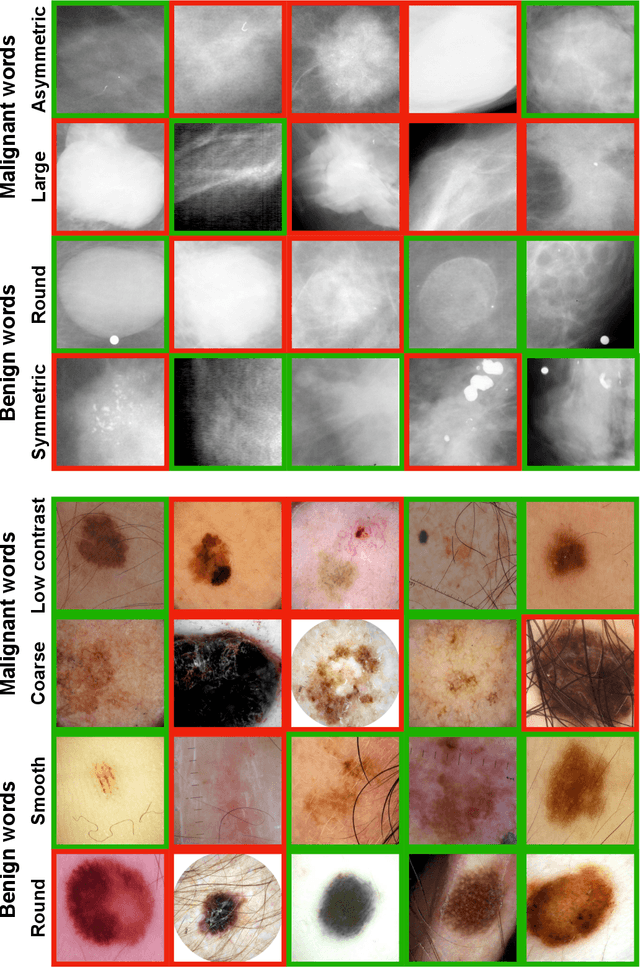
Explainability is a longstanding challenge in deep learning, especially in high-stakes domains like healthcare. Common explainability methods highlight image regions that drive an AI model's decision. Humans, however, heavily rely on language to convey explanations of not only "where" but "what". Additionally, most explainability approaches focus on explaining individual AI predictions, rather than describing the features used by an AI model in general. The latter would be especially useful for model and dataset auditing, and potentially even knowledge generation as AI is increasingly being used in novel tasks. Here, we present an explainability strategy that uses a vision-language model to identify language-based descriptors of a visual classification task. By leveraging a pre-trained joint embedding space between images and text, our approach estimates a new classification task as a linear combination of words, resulting in a weight for each word that indicates its alignment with the vision-based classifier. We assess our approach using two medical imaging classification tasks, where we find that the resulting descriptors largely align with clinical knowledge despite a lack of domain-specific language training. However, our approach also identifies the potential for 'shortcut connections' in the public datasets used. Towards a functional measure of explainability, we perform a pilot reader study where we find that the AI-identified words can enable non-expert humans to perform a specialized medical task at a non-trivial level. Altogether, our results emphasize the potential of using multimodal foundational models to deliver intuitive, language-based explanations of visual tasks.
Out-of-Distribution Detection by Leveraging Between-Layer Transformation Smoothness
Oct 04, 2023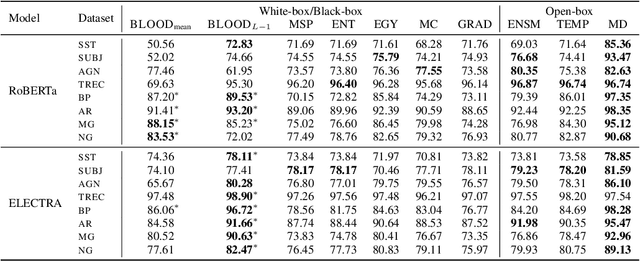
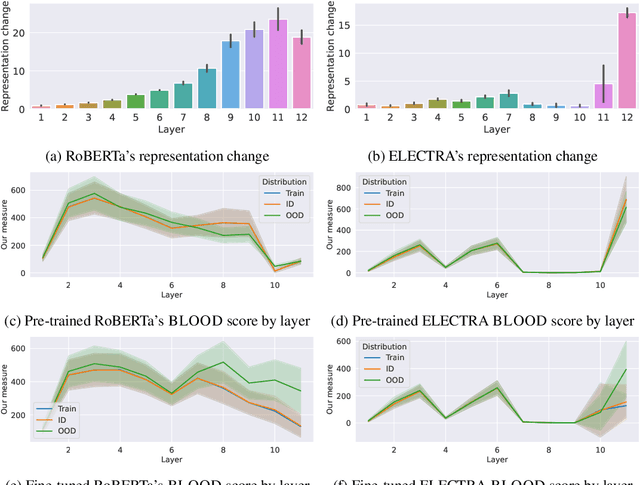
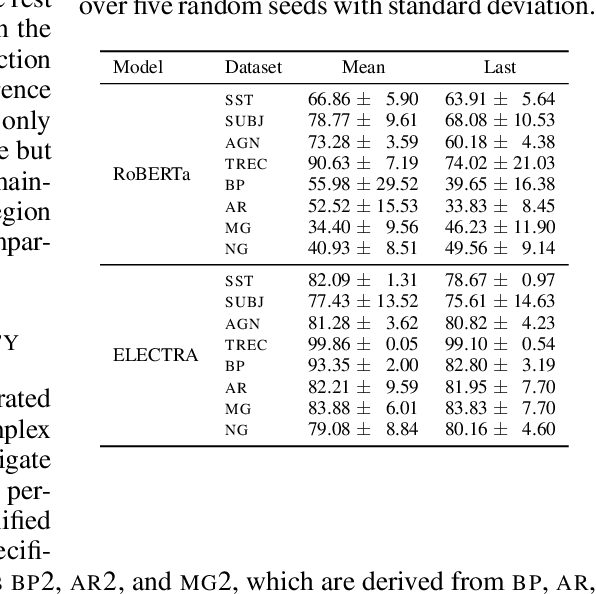
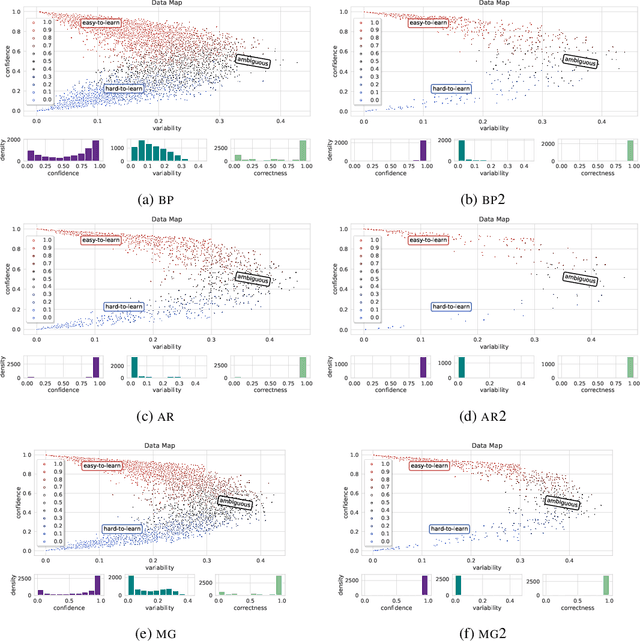
Effective OOD detection is crucial for reliable machine learning models, yet most current methods are limited in practical use due to requirements like access to training data or intervention in training. We present a novel method for detecting OOD data in deep neural networks based on transformation smoothness between intermediate layers of a network (BLOOD), which is applicable to pre-trained models without access to training data. BLOOD utilizes the tendency of between-layer representation transformations of in-distribution (ID) data to be smoother than the corresponding transformations of OOD data, a property that we also demonstrate empirically for Transformer networks. We evaluate BLOOD on several text classification tasks with Transformer networks and demonstrate that it outperforms methods with comparable resource requirements. Our analysis also suggests that when learning simpler tasks, OOD data transformations maintain their original sharpness, whereas sharpness increases with more complex tasks.
Unleashing the power of Neural Collapse for Transferability Estimation
Oct 09, 2023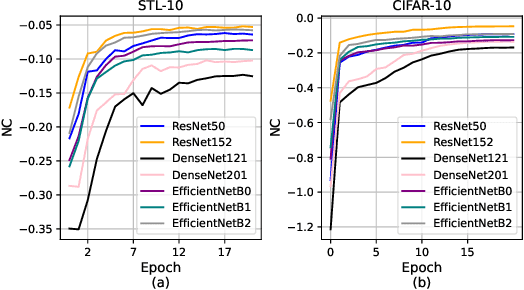
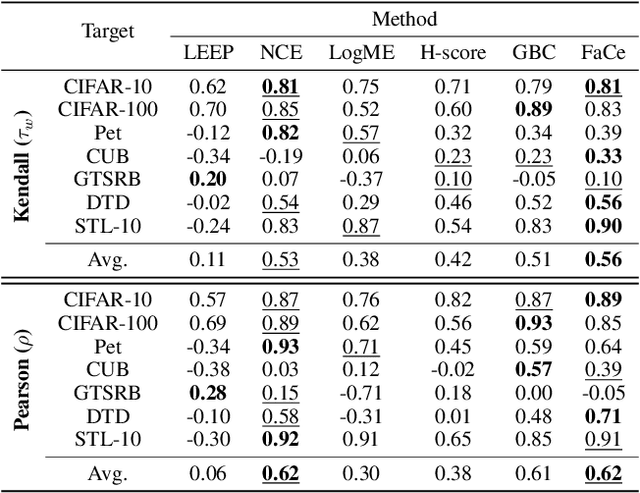
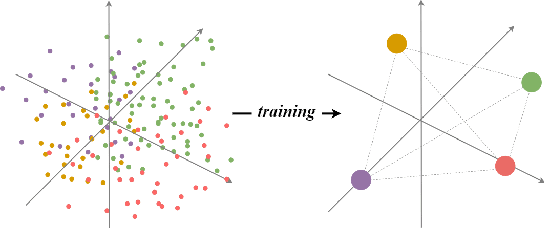
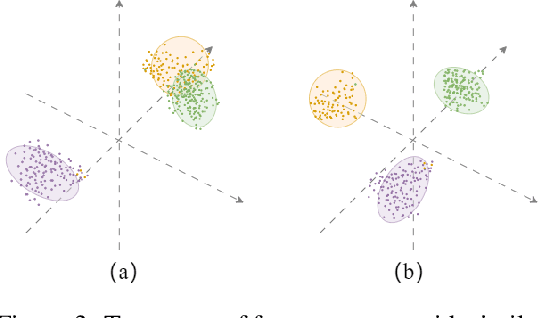
Transferability estimation aims to provide heuristics for quantifying how suitable a pre-trained model is for a specific downstream task, without fine-tuning them all. Prior studies have revealed that well-trained models exhibit the phenomenon of Neural Collapse. Based on a widely used neural collapse metric in existing literature, we observe a strong correlation between the neural collapse of pre-trained models and their corresponding fine-tuned models. Inspired by this observation, we propose a novel method termed Fair Collapse (FaCe) for transferability estimation by comprehensively measuring the degree of neural collapse in the pre-trained model. Typically, FaCe comprises two different terms: the variance collapse term, which assesses the class separation and within-class compactness, and the class fairness term, which quantifies the fairness of the pre-trained model towards each class. We investigate FaCe on a variety of pre-trained classification models across different network architectures, source datasets, and training loss functions. Results show that FaCe yields state-of-the-art performance on different tasks including image classification, semantic segmentation, and text classification, which demonstrate the effectiveness and generalization of our method.
Memoria: Hebbian Memory Architecture for Human-Like Sequential Processing
Oct 04, 2023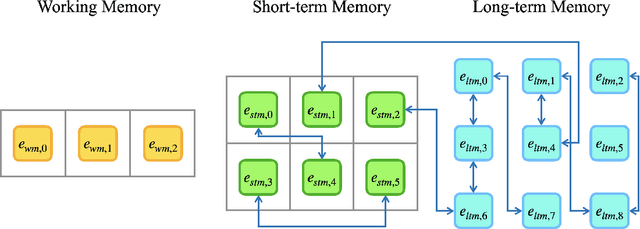

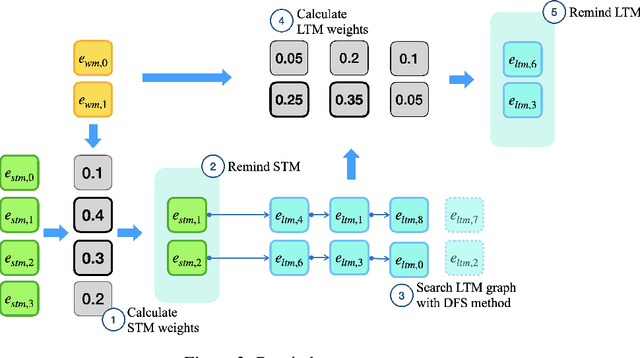

Transformers have demonstrated their success in various domains and tasks. However, Transformers struggle with long input sequences due to their limited capacity. While one solution is to increase input length, endlessly stretching the length is unrealistic. Furthermore, humans selectively remember and use only relevant information from inputs, unlike Transformers which process all raw data from start to end. We introduce Memoria, a general memory network that applies Hebbian theory which is a major theory explaining human memory formulation to enhance long-term dependencies in neural networks. Memoria stores and retrieves information called engram at multiple memory levels of working memory, short-term memory, and long-term memory, using connection weights that change according to Hebb's rule. Through experiments with popular Transformer-based models like BERT and GPT, we present that Memoria significantly improves the ability to consider long-term dependencies in various tasks. Results show that Memoria outperformed existing methodologies in sorting and language modeling, and long text classification.
Analyzing Textual Data for Fatality Classification in Afghanistan's Armed Conflicts: A BERT Approach
Oct 12, 2023Afghanistan has witnessed many armed conflicts throughout history, especially in the past 20 years; these events have had a significant impact on human lives, including military and civilians, with potential fatalities. In this research, we aim to leverage state-of-the-art machine learning techniques to classify the outcomes of Afghanistan armed conflicts to either fatal or non-fatal based on their textual descriptions provided by the Armed Conflict Location & Event Data Project (ACLED) dataset. The dataset contains comprehensive descriptions of armed conflicts in Afghanistan that took place from August 2021 to March 2023. The proposed approach leverages the power of BERT (Bidirectional Encoder Representations from Transformers), a cutting-edge language representation model in natural language processing. The classifier utilizes the raw textual description of an event to estimate the likelihood of the event resulting in a fatality. The model achieved impressive performance on the test set with an accuracy of 98.8%, recall of 98.05%, precision of 99.6%, and an F1 score of 98.82%. These results highlight the model's robustness and indicate its potential impact in various areas such as resource allocation, policymaking, and humanitarian aid efforts in Afghanistan. The model indicates a machine learning-based text classification approach using the ACLED dataset to accurately classify fatality in Afghanistan armed conflicts, achieving robust performance with the BERT model and paving the way for future endeavors in predicting event severity in Afghanistan.
Text classification dataset and analysis for Uzbek language
Feb 28, 2023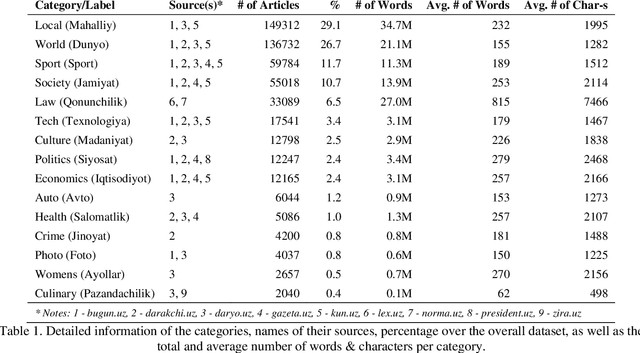
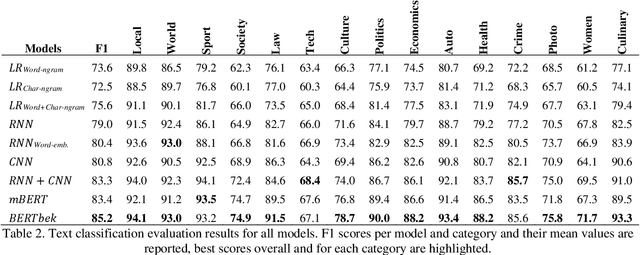
Text classification is an important task in Natural Language Processing (NLP), where the goal is to categorize text data into predefined classes. In this study, we analyse the dataset creation steps and evaluation techniques of multi-label news categorisation task as part of text classification. We first present a newly obtained dataset for Uzbek text classification, which was collected from 10 different news and press websites and covers 15 categories of news, press and law texts. We also present a comprehensive evaluation of different models, ranging from traditional bag-of-words models to deep learning architectures, on this newly created dataset. Our experiments show that the Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN) based models outperform the rule-based models. The best performance is achieved by the BERTbek model, which is a transformer-based BERT model trained on the Uzbek corpus. Our findings provide a good baseline for further research in Uzbek text classification.
Making Scalable Meta Learning Practical
Oct 09, 2023Despite its flexibility to learn diverse inductive biases in machine learning programs, meta learning (i.e., learning to learn) has long been recognized to suffer from poor scalability due to its tremendous compute/memory costs, training instability, and a lack of efficient distributed training support. In this work, we focus on making scalable meta learning practical by introducing SAMA, which combines advances in both implicit differentiation algorithms and systems. Specifically, SAMA is designed to flexibly support a broad range of adaptive optimizers in the base level of meta learning programs, while reducing computational burden by avoiding explicit computation of second-order gradient information, and exploiting efficient distributed training techniques implemented for first-order gradients. Evaluated on multiple large-scale meta learning benchmarks, SAMA showcases up to 1.7/4.8x increase in throughput and 2.0/3.8x decrease in memory consumption respectively on single-/multi-GPU setups compared to other baseline meta learning algorithms. Furthermore, we show that SAMA-based data optimization leads to consistent improvements in text classification accuracy with BERT and RoBERTa large language models, and achieves state-of-the-art results in both small- and large-scale data pruning on image classification tasks, demonstrating the practical applicability of scalable meta learning across language and vision domains.
A Comprehensive Study of Privacy Risks in Curriculum Learning
Oct 16, 2023Training a machine learning model with data following a meaningful order, i.e., from easy to hard, has been proven to be effective in accelerating the training process and achieving better model performance. The key enabling technique is curriculum learning (CL), which has seen great success and has been deployed in areas like image and text classification. Yet, how CL affects the privacy of machine learning is unclear. Given that CL changes the way a model memorizes the training data, its influence on data privacy needs to be thoroughly evaluated. To fill this knowledge gap, we perform the first study and leverage membership inference attack (MIA) and attribute inference attack (AIA) as two vectors to quantify the privacy leakage caused by CL. Our evaluation of nine real-world datasets with attack methods (NN-based, metric-based, label-only MIA, and NN-based AIA) revealed new insights about CL. First, MIA becomes slightly more effective when CL is applied, but the impact is much more prominent to a subset of training samples ranked as difficult. Second, a model trained under CL is less vulnerable under AIA, compared to MIA. Third, the existing defense techniques like DP-SGD, MemGuard, and MixupMMD are still effective under CL, though DP-SGD has a significant impact on target model accuracy. Finally, based on our insights into CL, we propose a new MIA, termed Diff-Cali, which exploits the difficulty scores for result calibration and is demonstrated to be effective against all CL methods and the normal training method. With this study, we hope to draw the community's attention to the unintended privacy risks of emerging machine-learning techniques and develop new attack benchmarks and defense solutions.