 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Mixed-Distil-BERT: Code-mixed Language Modeling for Bangla, English, and Hindi
Sep 19, 2023
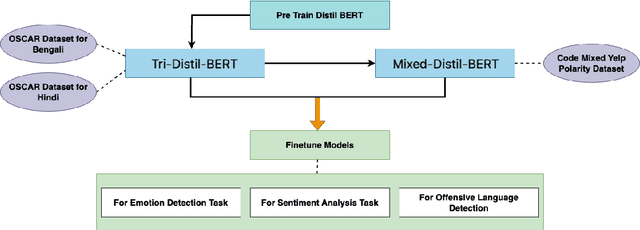
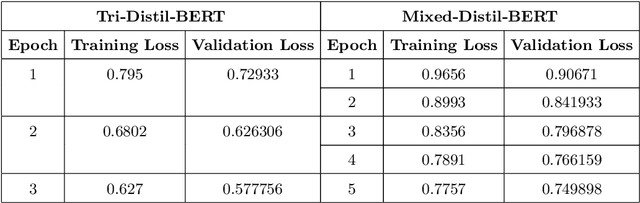
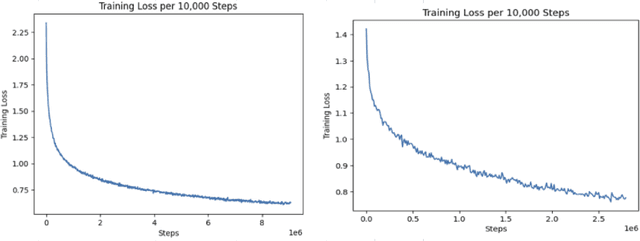
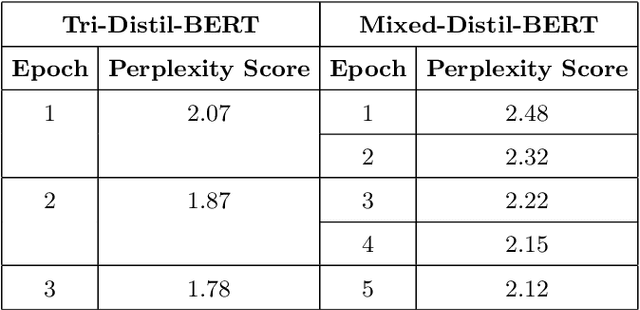
One of the most popular downstream tasks in the field of Natural Language Processing is text classification. Text classification tasks have become more daunting when the texts are code-mixed. Though they are not exposed to such text during pre-training, different BERT models have demonstrated success in tackling Code-Mixed NLP challenges. Again, in order to enhance their performance, Code-Mixed NLP models have depended on combining synthetic data with real-world data. It is crucial to understand how the BERT models' performance is impacted when they are pretrained using corresponding code-mixed languages. In this paper, we introduce Tri-Distil-BERT, a multilingual model pre-trained on Bangla, English, and Hindi, and Mixed-Distil-BERT, a model fine-tuned on code-mixed data. Both models are evaluated across multiple NLP tasks and demonstrate competitive performance against larger models like mBERT and XLM-R. Our two-tiered pre-training approach offers efficient alternatives for multilingual and code-mixed language understanding, contributing to advancements in the field.
United We Stand: Using Epoch-wise Agreement of Ensembles to Combat Overfit
Oct 17, 2023Deep neural networks have become the method of choice for solving many image classification tasks, largely because they can fit very complex functions defined over raw images. The downside of such powerful learners is the danger of overfitting the training set, leading to poor generalization, which is usually avoided by regularization and "early stopping" of the training. In this paper, we propose a new deep network ensemble classifier that is very effective against overfit. We begin with the theoretical analysis of a regression model, whose predictions - that the variance among classifiers increases when overfit occurs - is demonstrated empirically in deep networks in common use. Guided by these results, we construct a new ensemble-based prediction method designed to combat overfit, where the prediction is determined by the most consensual prediction throughout the training. On multiple image and text classification datasets, we show that when regular ensembles suffer from overfit, our method eliminates the harmful reduction in generalization due to overfit, and often even surpasses the performance obtained by early stopping. Our method is easy to implement, and can be integrated with any training scheme and architecture, without additional prior knowledge beyond the training set. Accordingly, it is a practical and useful tool to overcome overfit.
Effects of Human Adversarial and Affable Samples on BERT Generalizability
Oct 13, 2023
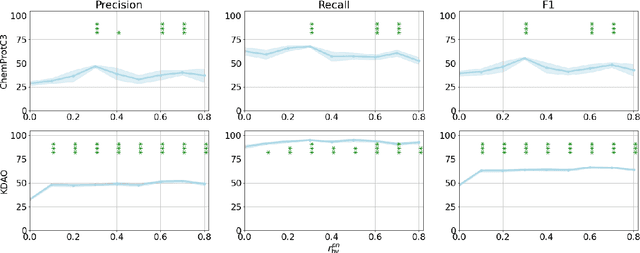

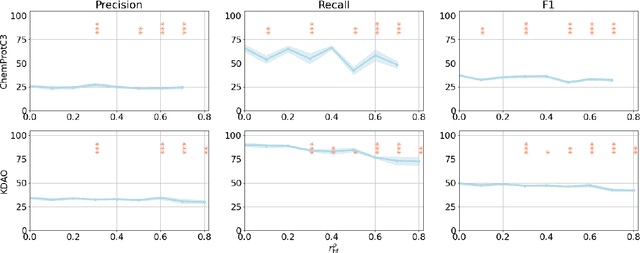
BERT-based models have had strong performance on leaderboards, yet have been demonstrably worse in real-world settings requiring generalization. Limited quantities of training data is considered a key impediment to achieving generalizability in machine learning. In this paper, we examine the impact of training data quality, not quantity, on a model's generalizability. We consider two characteristics of training data: the portion of human-adversarial (h-adversarial), i.e., sample pairs with seemingly minor differences but different ground-truth labels, and human-affable (h-affable) training samples, i.e., sample pairs with minor differences but the same ground-truth label. We find that for a fixed size of training samples, as a rule of thumb, having 10-30% h-adversarial instances improves the precision, and therefore F1, by up to 20 points in the tasks of text classification and relation extraction. Increasing h-adversarials beyond this range can result in performance plateaus or even degradation. In contrast, h-affables may not contribute to a model's generalizability and may even degrade generalization performance.
Enhancing Black-Box Few-Shot Text Classification with Prompt-Based Data Augmentation
May 23, 2023
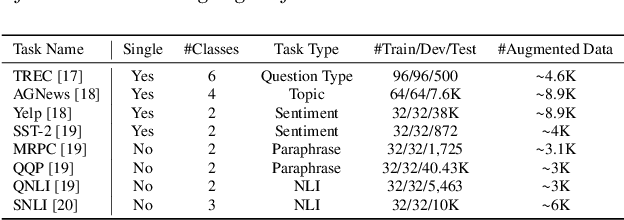

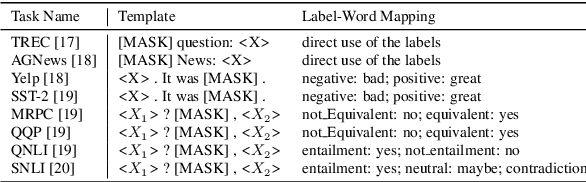
Training or finetuning large-scale language models (LLMs) such as GPT-3 requires substantial computation resources, motivating recent efforts to explore parameter-efficient adaptation to downstream tasks. One practical area of research is to treat these models as black boxes and interact with them through their inference APIs. In this paper, we investigate how to optimize few-shot text classification without accessing the gradients of the LLMs. To achieve this, we treat the black-box model as a feature extractor and train a classifier with the augmented text data. Data augmentation is performed using prompt-based finetuning on an auxiliary language model with a much smaller parameter size than the black-box model. Through extensive experiments on eight text classification datasets, we show that our approach, dubbed BT-Classifier, significantly outperforms state-of-the-art black-box few-shot learners and performs on par with methods that rely on full-model tuning.
Generative Calibration for In-context Learning
Oct 16, 2023As one of the most exciting features of large language models (LLMs), in-context learning is a mixed blessing. While it allows users to fast-prototype a task solver with only a few training examples, the performance is generally sensitive to various configurations of the prompt such as the choice or order of the training examples. In this paper, we for the first time theoretically and empirically identify that such a paradox is mainly due to the label shift of the in-context model to the data distribution, in which LLMs shift the label marginal $p(y)$ while having a good label conditional $p(x|y)$. With this understanding, we can simply calibrate the in-context predictive distribution by adjusting the label marginal, which is estimated via Monte-Carlo sampling over the in-context model, i.e., generation of LLMs. We call our approach as generative calibration. We conduct exhaustive experiments with 12 text classification tasks and 12 LLMs scaling from 774M to 33B, generally find that the proposed method greatly and consistently outperforms the ICL as well as state-of-the-art calibration methods, by up to 27% absolute in macro-F1. Meanwhile, the proposed method is also stable under different prompt configurations.
Not All Demonstration Examples are Equally Beneficial: Reweighting Demonstration Examples for In-Context Learning
Oct 12, 2023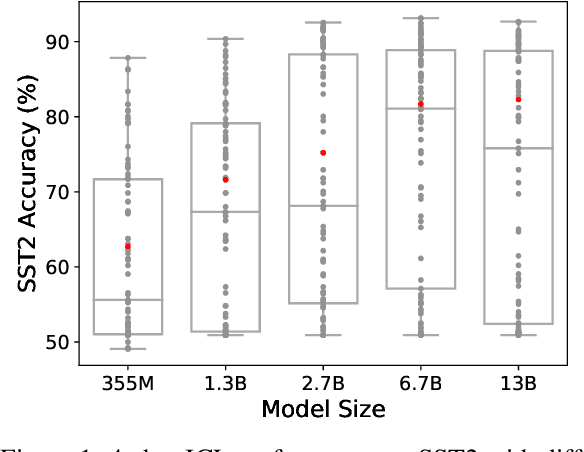
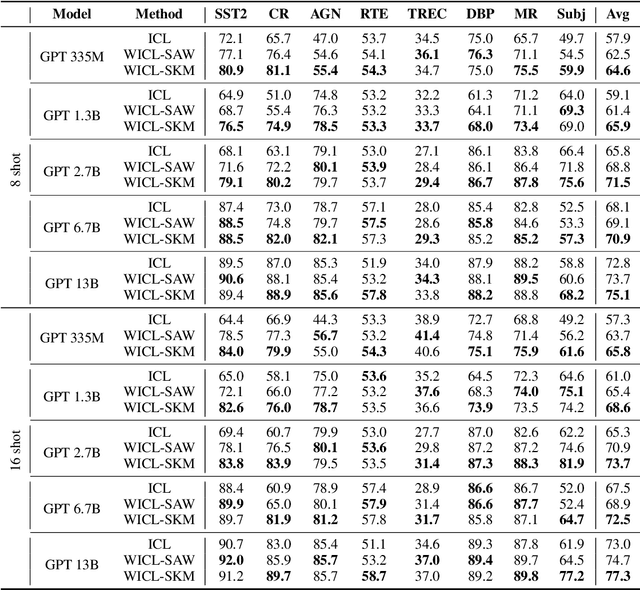

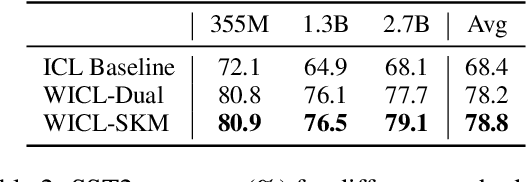
Large Language Models (LLMs) have recently gained the In-Context Learning (ICL) ability with the models scaling up, allowing them to quickly adapt to downstream tasks with only a few demonstration examples prepended in the input sequence. Nonetheless, the current practice of ICL treats all demonstration examples equally, which still warrants improvement, as the quality of examples is usually uneven. In this paper, we investigate how to determine approximately optimal weights for demonstration examples and how to apply them during ICL. To assess the quality of weights in the absence of additional validation data, we design a masked self-prediction (MSP) score that exhibits a strong correlation with the final ICL performance. To expedite the weight-searching process, we discretize the continuous weight space and adopt beam search. With approximately optimal weights obtained, we further propose two strategies to apply them to demonstrations at different model positions. Experimental results on 8 text classification tasks show that our approach outperforms conventional ICL by a large margin. Our code are publicly available at https:github.com/Zhe-Young/WICL.
Deconstructing Classifiers: Towards A Data Reconstruction Attack Against Text Classification Models
Jun 23, 2023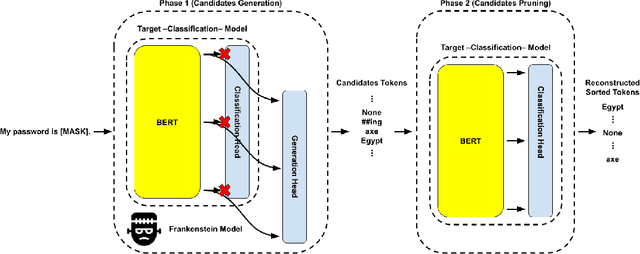
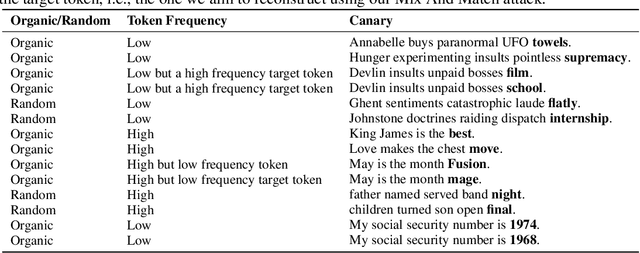
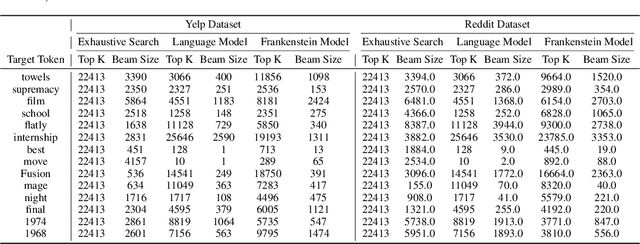
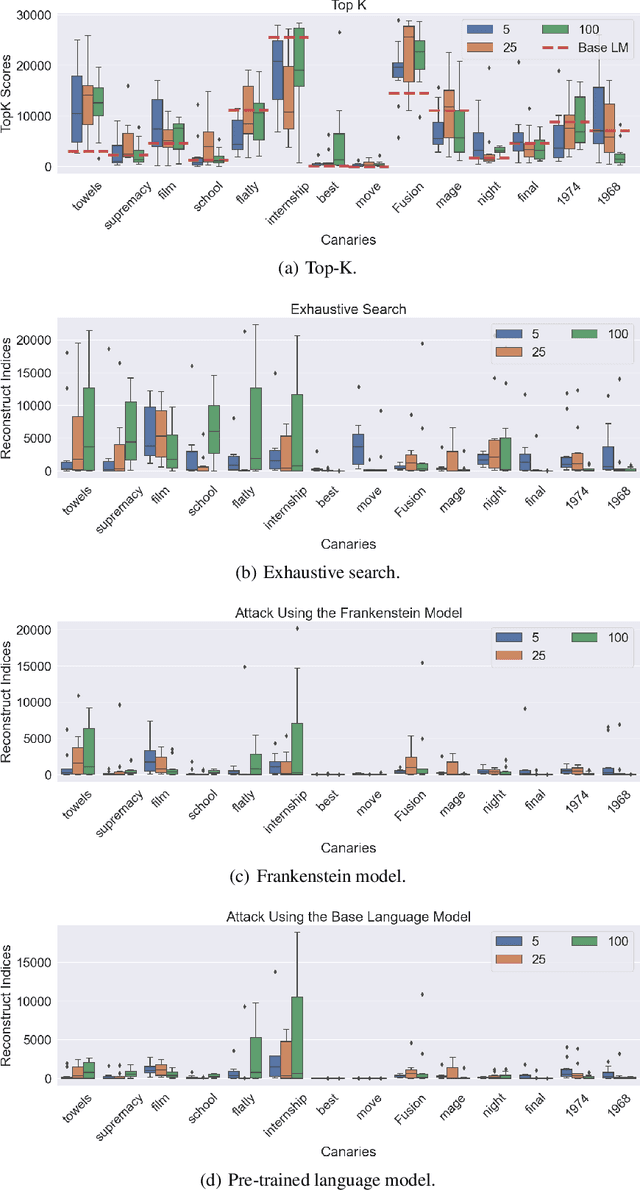
Natural language processing (NLP) models have become increasingly popular in real-world applications, such as text classification. However, they are vulnerable to privacy attacks, including data reconstruction attacks that aim to extract the data used to train the model. Most previous studies on data reconstruction attacks have focused on LLM, while classification models were assumed to be more secure. In this work, we propose a new targeted data reconstruction attack called the Mix And Match attack, which takes advantage of the fact that most classification models are based on LLM. The Mix And Match attack uses the base model of the target model to generate candidate tokens and then prunes them using the classification head. We extensively demonstrate the effectiveness of the attack using both random and organic canaries. This work highlights the importance of considering the privacy risks associated with data reconstruction attacks in classification models and offers insights into possible leakages.
Hardware Resilience Properties of Text-Guided Image Classifiers
Nov 23, 2023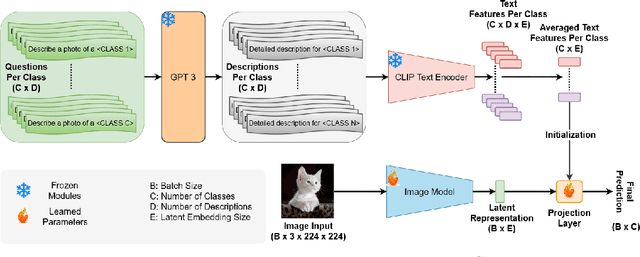
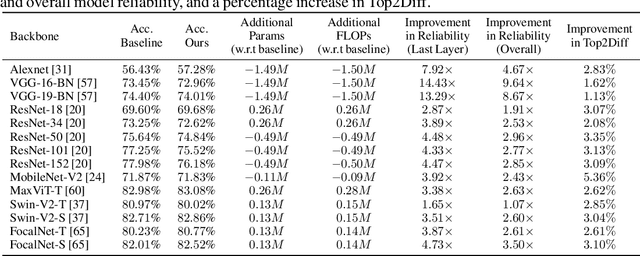
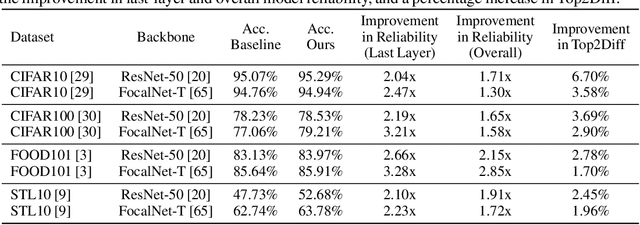

This paper presents a novel method to enhance the reliability of image classification models during deployment in the face of transient hardware errors. By utilizing enriched text embeddings derived from GPT-3 with question prompts per class and CLIP pretrained text encoder, we investigate their impact as an initialization for the classification layer. Our approach achieves a remarkable $5.5\times$ average increase in hardware reliability (and up to 14x) across various architectures in the most critical layer, with minimal accuracy drop (0.3% on average) compared to baseline PyTorch models. Furthermore, our method seamlessly integrates with any image classification backbone, showcases results across various network architectures, decreases parameter and FLOPs overhead, and follows a consistent training recipe. This research offers a practical and efficient solution to bolster the robustness of image classification models against hardware failures, with potential implications for future studies in this domain. Our code and models are released at https://github.com/TalalWasim/TextGuidedResilience.
Explore the Effect of Data Selection on Poison Efficiency in Backdoor Attacks
Oct 15, 2023As the number of parameters in Deep Neural Networks (DNNs) scales, the thirst for training data also increases. To save costs, it has become common for users and enterprises to delegate time-consuming data collection to third parties. Unfortunately, recent research has shown that this practice raises the risk of DNNs being exposed to backdoor attacks. Specifically, an attacker can maliciously control the behavior of a trained model by poisoning a small portion of the training data. In this study, we focus on improving the poisoning efficiency of backdoor attacks from the sample selection perspective. The existing attack methods construct such poisoned samples by randomly selecting some clean data from the benign set and then embedding a trigger into them. However, this random selection strategy ignores that each sample may contribute differently to the backdoor injection, thereby reducing the poisoning efficiency. To address the above problem, a new selection strategy named Improved Filtering and Updating Strategy (FUS++) is proposed. Specifically, we adopt the forgetting events of the samples to indicate the contribution of different poisoned samples and use the curvature of the loss surface to analyses the effectiveness of this phenomenon. Accordingly, we combine forgetting events and curvature of different samples to conduct a simple yet efficient sample selection strategy. The experimental results on image classification (CIFAR-10, CIFAR-100, ImageNet-10), text classification (AG News), audio classification (ESC-50), and age regression (Facial Age) consistently demonstrate the effectiveness of the proposed strategy: the attack performance using FUS++ is significantly higher than that using random selection for the same poisoning ratio.
SCAT: Robust Self-supervised Contrastive Learning via Adversarial Training for Text Classification
Jul 04, 2023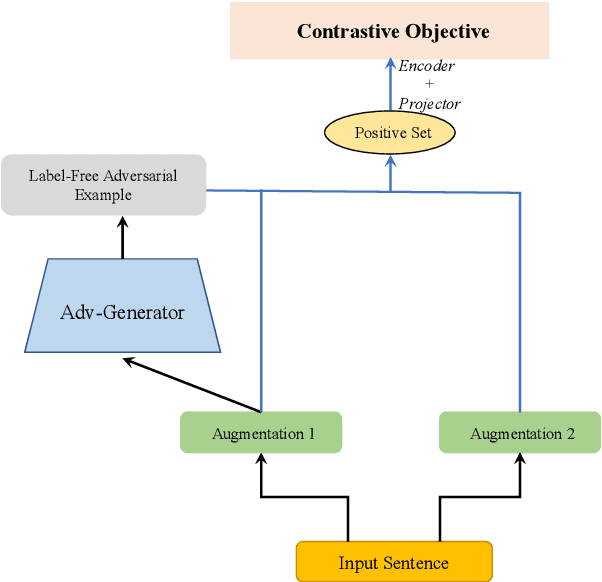
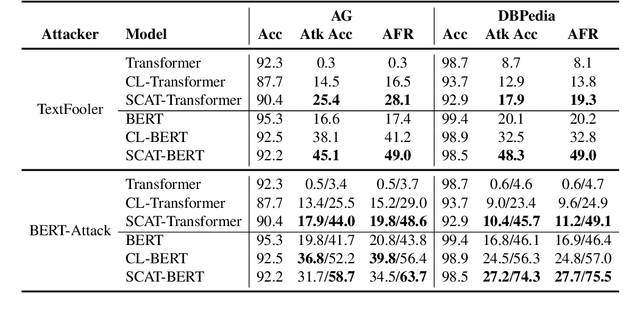
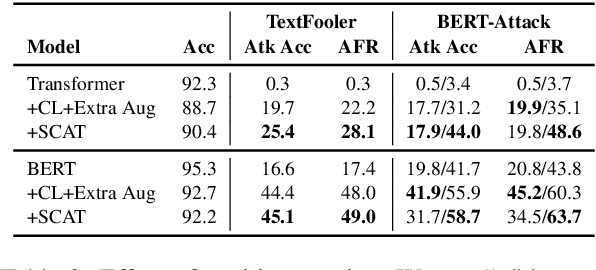
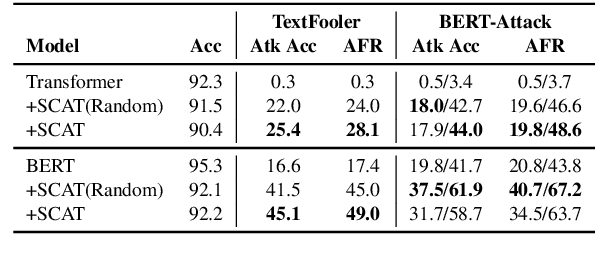
Despite their promising performance across various natural language processing (NLP) tasks, current NLP systems are vulnerable to textual adversarial attacks. To defend against these attacks, most existing methods apply adversarial training by incorporating adversarial examples. However, these methods have to rely on ground-truth labels to generate adversarial examples, rendering it impractical for large-scale model pre-training which is commonly used nowadays for NLP and many other tasks. In this paper, we propose a novel learning framework called SCAT (Self-supervised Contrastive Learning via Adversarial Training), which can learn robust representations without requiring labeled data. Specifically, SCAT modifies random augmentations of the data in a fully labelfree manner to generate adversarial examples. Adversarial training is achieved by minimizing the contrastive loss between the augmentations and their adversarial counterparts. We evaluate SCAT on two text classification datasets using two state-of-the-art attack schemes proposed recently. Our results show that SCAT can not only train robust language models from scratch, but it can also significantly improve the robustness of existing pre-trained language models. Moreover, to demonstrate its flexibility, we show that SCAT can also be combined with supervised adversarial training to further enhance model robustness.