 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Point, Segment and Count: A Generalized Framework for Object Counting
Nov 27, 2023
Class-agnostic object counting aims to count all objects in an image with respect to example boxes or class names, \emph{a.k.a} few-shot and zero-shot counting. Current state-of-the-art methods highly rely on density maps to predict object counts, which lacks model interpretability. In this paper, we propose a generalized framework for both few-shot and zero-shot object counting based on detection. Our framework combines the superior advantages of two foundation models without compromising their zero-shot capability: (\textbf{i}) SAM to segment all possible objects as mask proposals, and (\textbf{ii}) CLIP to classify proposals to obtain accurate object counts. However, this strategy meets the obstacles of efficiency overhead and the small crowded objects that cannot be localized and distinguished. To address these issues, our framework, termed PseCo, follows three steps: point, segment, and count. Specifically, we first propose a class-agnostic object localization to provide accurate but least point prompts for SAM, which consequently not only reduces computation costs but also avoids missing small objects. Furthermore, we propose a generalized object classification that leverages CLIP image/text embeddings as the classifier, following a hierarchical knowledge distillation to obtain discriminative classifications among hierarchical mask proposals. Extensive experimental results on FSC-147 dataset demonstrate that PseCo achieves state-of-the-art performance in both few-shot/zero-shot object counting/detection, with additional results on large-scale COCO and LVIS datasets. The source code is available at \url{https://github.com/Hzzone/PseCo}.
ChatGraph: Interpretable Text Classification by Converting ChatGPT Knowledge to Graphs
May 03, 2023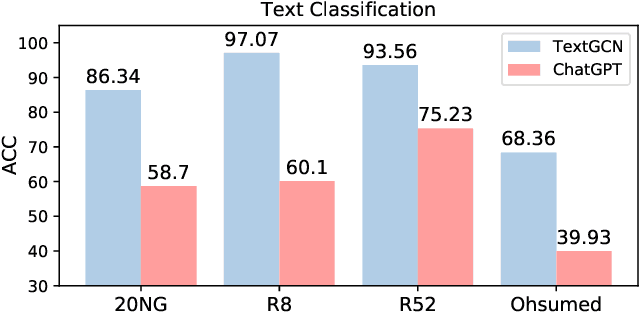
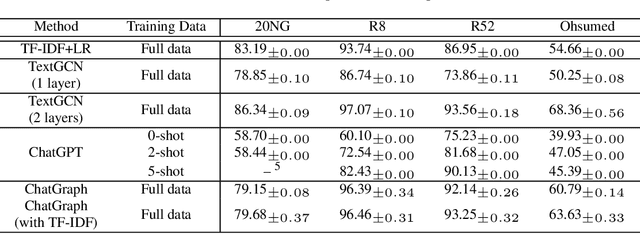
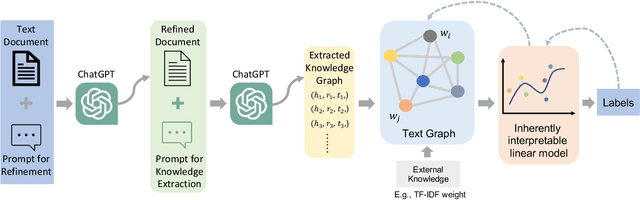

ChatGPT, as a recently launched large language model (LLM), has shown superior performance in various natural language processing (NLP) tasks. However, two major limitations hinder its potential applications: (1) the inflexibility of finetuning on downstream tasks and (2) the lack of interpretability in the decision-making process. To tackle these limitations, we propose a novel framework that leverages the power of ChatGPT for specific tasks, such as text classification, while improving its interpretability. The proposed framework conducts a knowledge graph extraction task to extract refined and structural knowledge from the raw data using ChatGPT. The rich knowledge is then converted into a graph, which is further used to train an interpretable linear classifier to make predictions. To evaluate the effectiveness of our proposed method, we conduct experiments on four datasets. The result shows that our method can significantly improve the performance compared to directly utilizing ChatGPT for text classification tasks. And our method provides a more transparent decision-making process compared with previous text classification methods.
Rather a Nurse than a Physician -- Contrastive Explanations under Investigation
Oct 18, 2023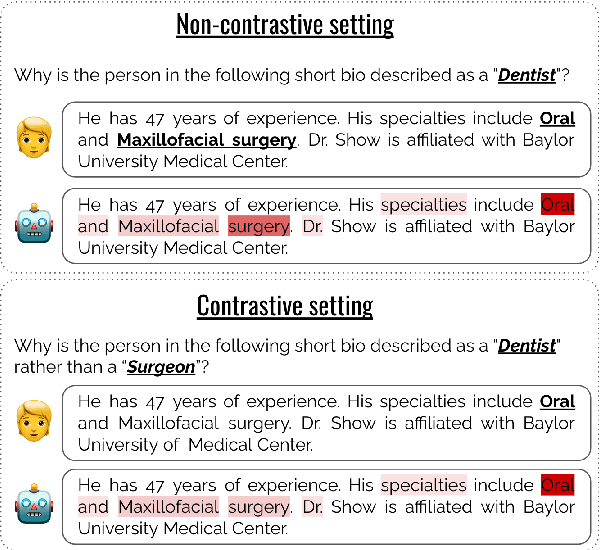


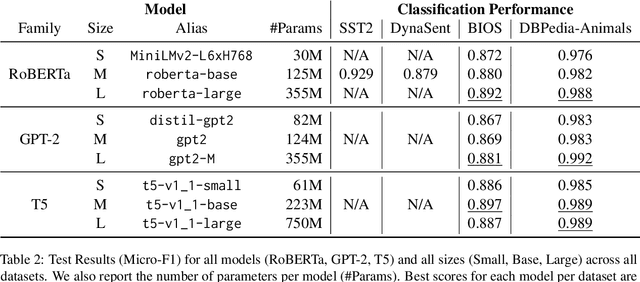
Contrastive explanations, where one decision is explained in contrast to another, are supposed to be closer to how humans explain a decision than non-contrastive explanations, where the decision is not necessarily referenced to an alternative. This claim has never been empirically validated. We analyze four English text-classification datasets (SST2, DynaSent, BIOS and DBpedia-Animals). We fine-tune and extract explanations from three different models (RoBERTa, GTP-2, and T5), each in three different sizes and apply three post-hoc explainability methods (LRP, GradientxInput, GradNorm). We furthermore collect and release human rationale annotations for a subset of 100 samples from the BIOS dataset for contrastive and non-contrastive settings. A cross-comparison between model-based rationales and human annotations, both in contrastive and non-contrastive settings, yields a high agreement between the two settings for models as well as for humans. Moreover, model-based explanations computed in both settings align equally well with human rationales. Thus, we empirically find that humans do not necessarily explain in a contrastive manner.9 pages, long paper at ACL 2022 proceedings.
Sliceformer: Make Multi-head Attention as Simple as Sorting in Discriminative Tasks
Oct 26, 2023
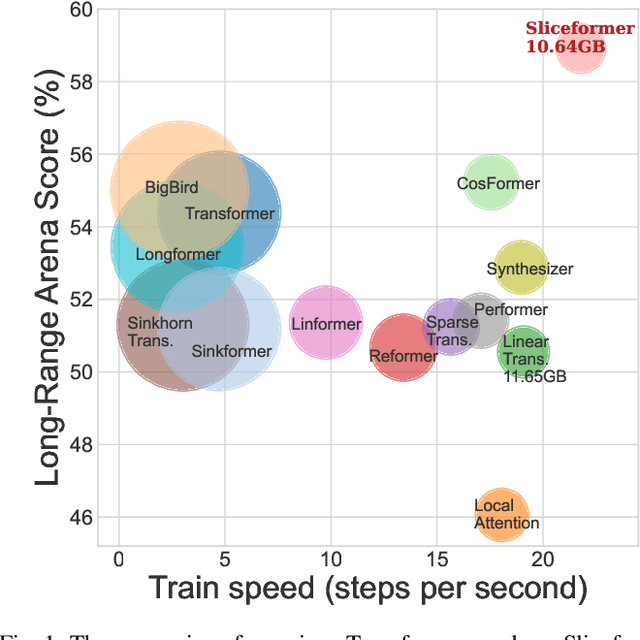
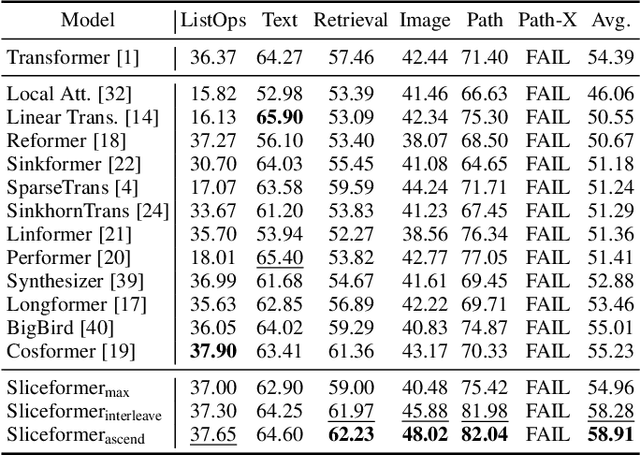
As one of the most popular neural network modules, Transformer plays a central role in many fundamental deep learning models, e.g., the ViT in computer vision and the BERT and GPT in natural language processing. The effectiveness of the Transformer is often attributed to its multi-head attention (MHA) mechanism. In this study, we discuss the limitations of MHA, including the high computational complexity due to its ``query-key-value'' architecture and the numerical issue caused by its softmax operation. Considering the above problems and the recent development tendency of the attention layer, we propose an effective and efficient surrogate of the Transformer, called Sliceformer. Our Sliceformer replaces the classic MHA mechanism with an extremely simple ``slicing-sorting'' operation, i.e., projecting inputs linearly to a latent space and sorting them along different feature dimensions (or equivalently, called channels). For each feature dimension, the sorting operation implicitly generates an implicit attention map with sparse, full-rank, and doubly-stochastic structures. We consider different implementations of the slicing-sorting operation and analyze their impacts on the Sliceformer. We test the Sliceformer in the Long-Range Arena benchmark, image classification, text classification, and molecular property prediction, demonstrating its advantage in computational complexity and universal effectiveness in discriminative tasks. Our Sliceformer achieves comparable or better performance with lower memory cost and faster speed than the Transformer and its variants. Moreover, the experimental results reveal that applying our Sliceformer can empirically suppress the risk of mode collapse when representing data. The code is available at \url{https://github.com/SDS-Lab/sliceformer}.
Effects of Human Adversarial and Affable Samples on BERT Generalizability
Oct 17, 2023
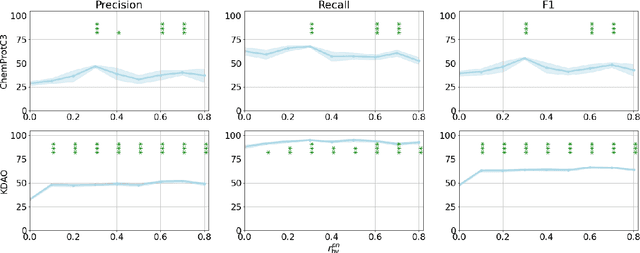

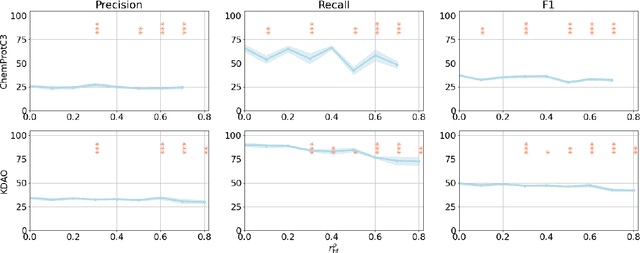
BERT-based models have had strong performance on leaderboards, yet have been demonstrably worse in real-world settings requiring generalization. Limited quantities of training data is considered a key impediment to achieving generalizability in machine learning. In this paper, we examine the impact of training data quality, not quantity, on a model's generalizability. We consider two characteristics of training data: the portion of human-adversarial (h-adversarial), i.e., sample pairs with seemingly minor differences but different ground-truth labels, and human-affable (h-affable) training samples, i.e., sample pairs with minor differences but the same ground-truth label. We find that for a fixed size of training samples, as a rule of thumb, having 10-30% h-adversarial instances improves the precision, and therefore F1, by up to 20 points in the tasks of text classification and relation extraction. Increasing h-adversarials beyond this range can result in performance plateaus or even degradation. In contrast, h-affables may not contribute to a model's generalizability and may even degrade generalization performance.
Linear Classifier: An Often-Forgotten Baseline for Text Classification
Jun 12, 2023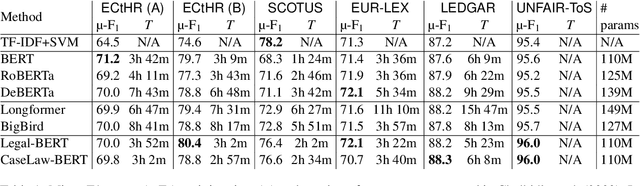
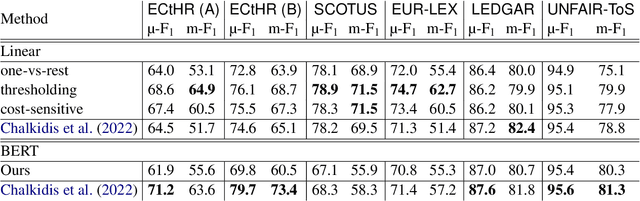
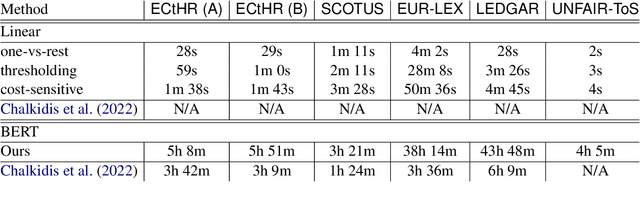

Large-scale pre-trained language models such as BERT are popular solutions for text classification. Due to the superior performance of these advanced methods, nowadays, people often directly train them for a few epochs and deploy the obtained model. In this opinion paper, we point out that this way may only sometimes get satisfactory results. We argue the importance of running a simple baseline like linear classifiers on bag-of-words features along with advanced methods. First, for many text data, linear methods show competitive performance, high efficiency, and robustness. Second, advanced models such as BERT may only achieve the best results if properly applied. Simple baselines help to confirm whether the results of advanced models are acceptable. Our experimental results fully support these points.
A Multi-Modal Multilingual Benchmark for Document Image Classification
Oct 25, 2023
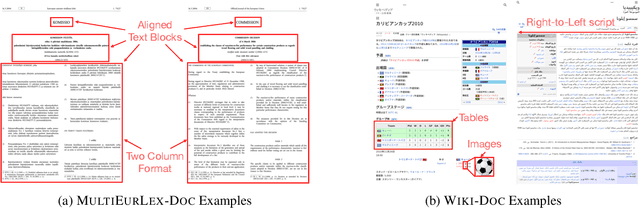

Document image classification is different from plain-text document classification and consists of classifying a document by understanding the content and structure of documents such as forms, emails, and other such documents. We show that the only existing dataset for this task (Lewis et al., 2006) has several limitations and we introduce two newly curated multilingual datasets WIKI-DOC and MULTIEURLEX-DOC that overcome these limitations. We further undertake a comprehensive study of popular visually-rich document understanding or Document AI models in previously untested setting in document image classification such as 1) multi-label classification, and 2) zero-shot cross-lingual transfer setup. Experimental results show limitations of multilingual Document AI models on cross-lingual transfer across typologically distant languages. Our datasets and findings open the door for future research into improving Document AI models.
Retrieval-augmented Multi-label Text Classification
May 22, 2023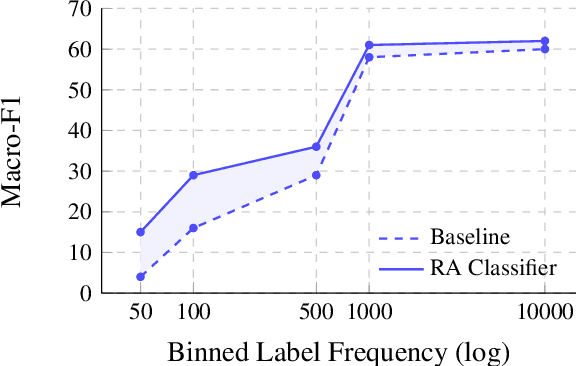

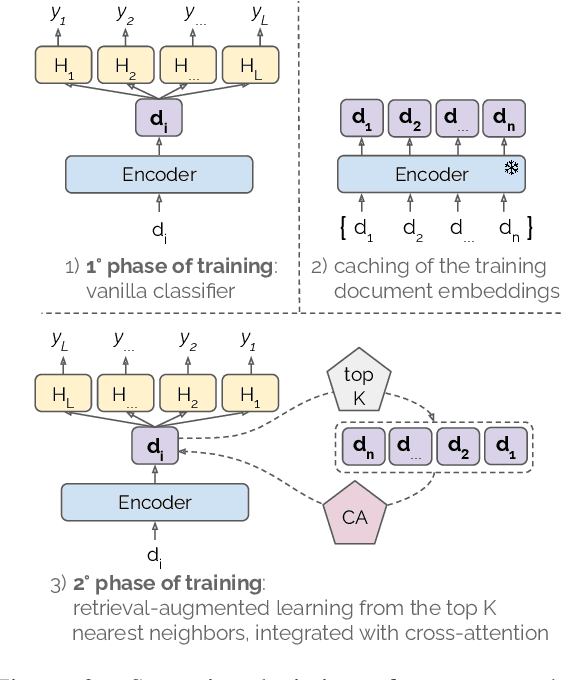
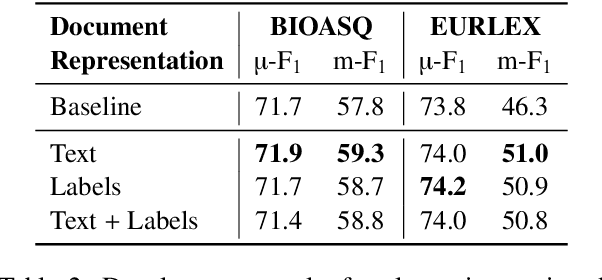
Multi-label text classification (MLC) is a challenging task in settings of large label sets, where label support follows a Zipfian distribution. In this paper, we address this problem through retrieval augmentation, aiming to improve the sample efficiency of classification models. Our approach closely follows the standard MLC architecture of a Transformer-based encoder paired with a set of classification heads. In our case, however, the input document representation is augmented through cross-attention to similar documents retrieved from the training set and represented in a task-specific manner. We evaluate this approach on four datasets from the legal and biomedical domains, all of which feature highly skewed label distributions. Our experiments show that retrieval augmentation substantially improves model performance on the long tail of infrequent labels especially so for lower-resource training scenarios and more challenging long-document data scenarios.
Self-Evolution Learning for Mixup: Enhance Data Augmentation on Few-Shot Text Classification Tasks
May 22, 2023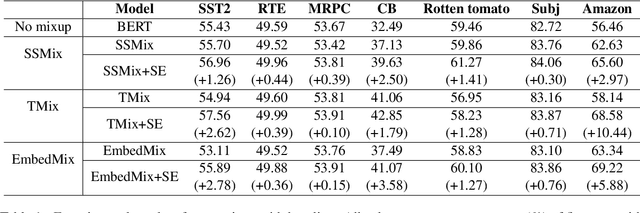
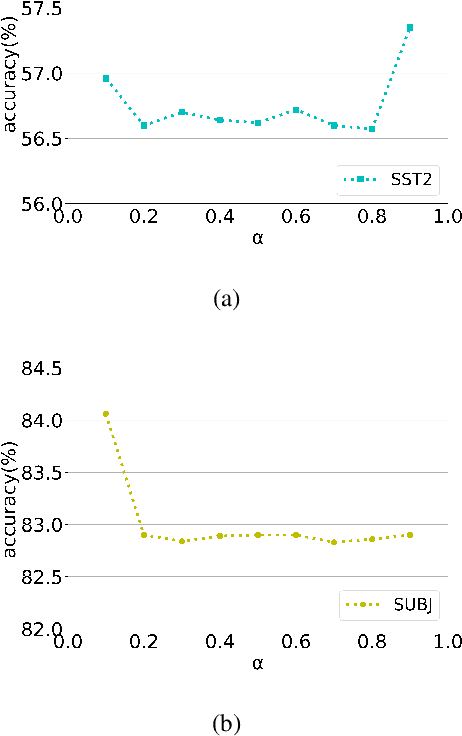
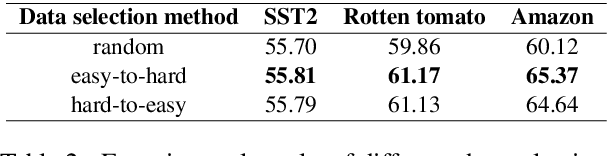
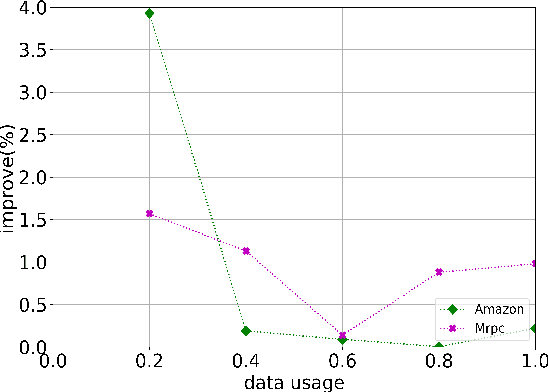
Text classification tasks often encounter few shot scenarios with limited labeled data, and addressing data scarcity is crucial. Data augmentation with mixup has shown to be effective on various text classification tasks. However, most of the mixup methods do not consider the varying degree of learning difficulty in different stages of training and generate new samples with one hot labels, resulting in the model over confidence. In this paper, we propose a self evolution learning (SE) based mixup approach for data augmentation in text classification, which can generate more adaptive and model friendly pesudo samples for the model training. SE focuses on the variation of the model's learning ability. To alleviate the model confidence, we introduce a novel instance specific label smoothing approach, which linearly interpolates the model's output and one hot labels of the original samples to generate new soft for label mixing up. Through experimental analysis, in addition to improving classification accuracy, we demonstrate that SE also enhances the model's generalize ability.
Fusing Models with Complementary Expertise
Oct 02, 2023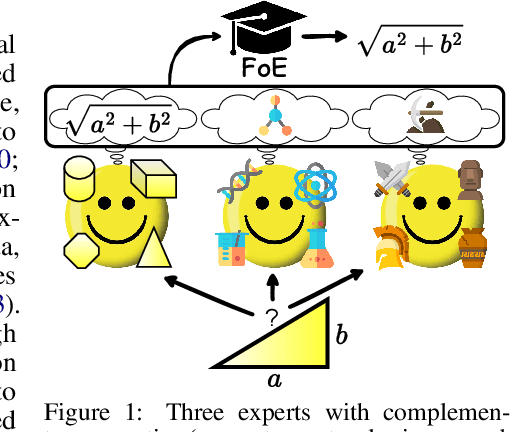
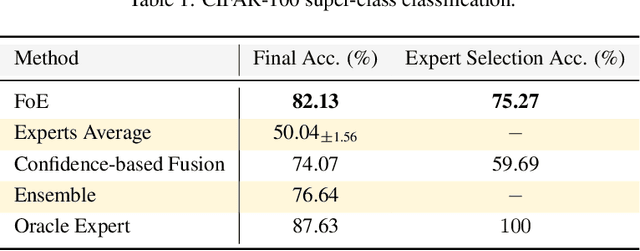
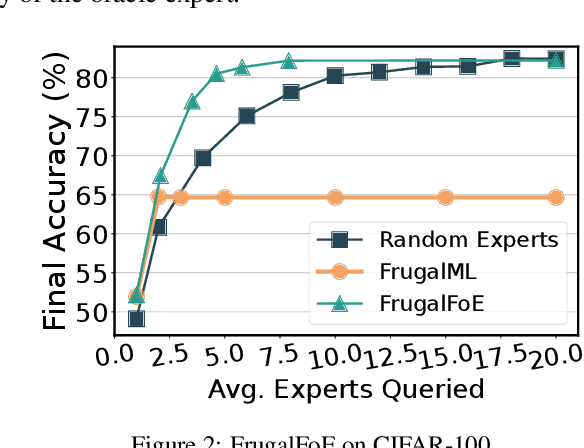
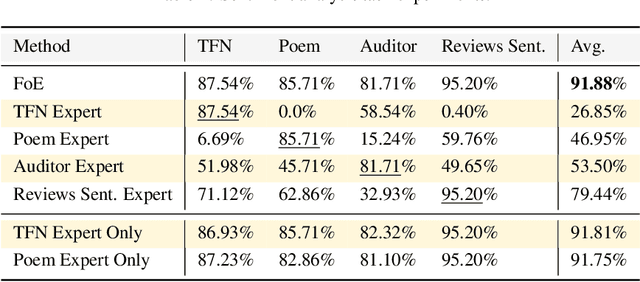
Training AI models that generalize across tasks and domains has long been among the open problems driving AI research. The emergence of Foundation Models made it easier to obtain expert models for a given task, but the heterogeneity of data that may be encountered at test time often means that any single expert is insufficient. We consider the Fusion of Experts (FoE) problem of fusing outputs of expert models with complementary knowledge of the data distribution and formulate it as an instance of supervised learning. Our method is applicable to both discriminative and generative tasks and leads to significant performance improvements in image and text classification, text summarization, multiple-choice QA, and automatic evaluation of generated text. We also extend our method to the "frugal" setting where it is desired to reduce the number of expert model evaluations at test time.