 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Cross Encoding as Augmentation: Towards Effective Educational Text Classification
May 31, 2023
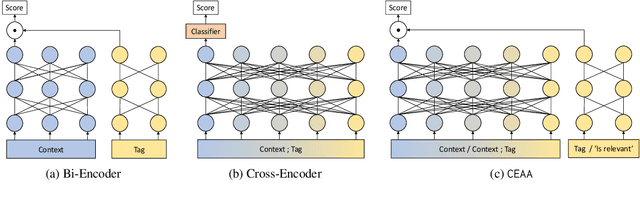
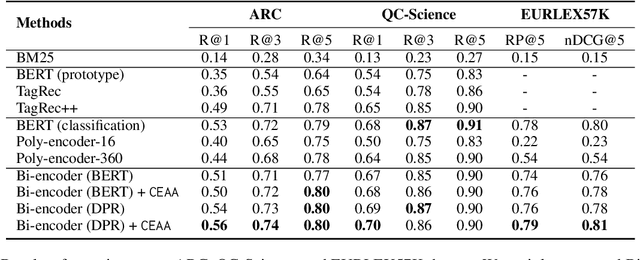
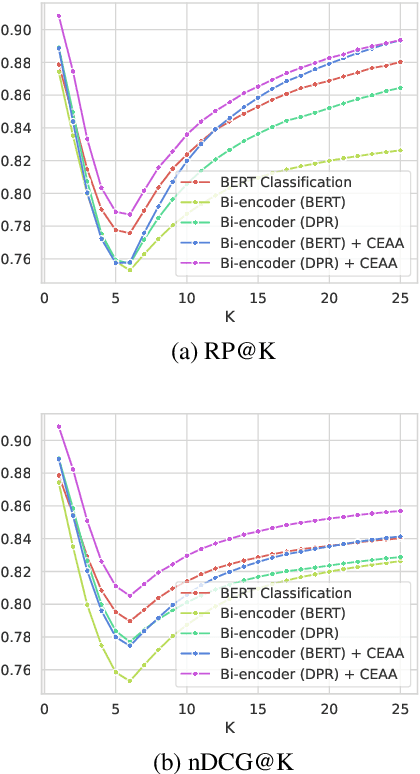
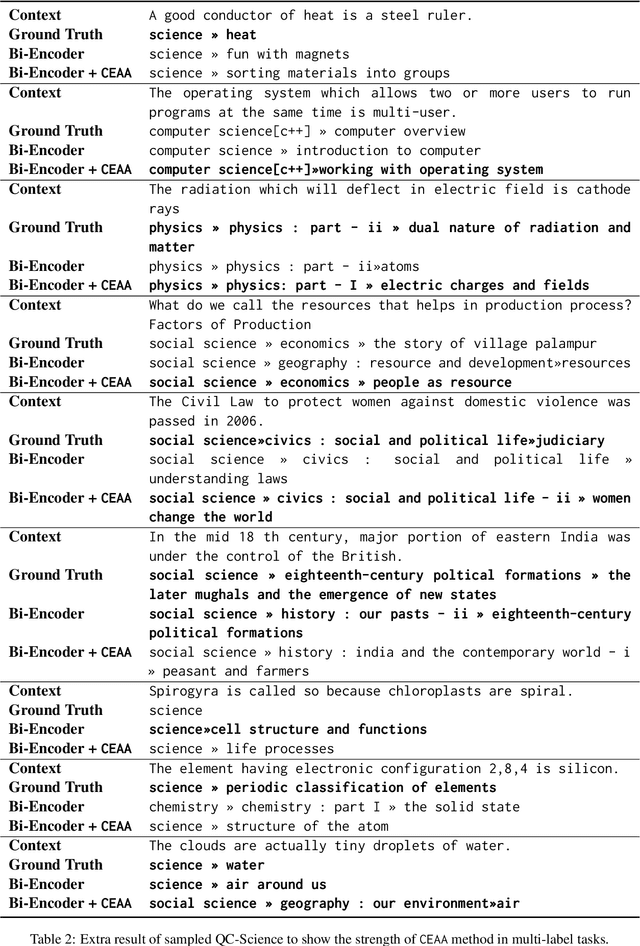
Text classification in education, usually called auto-tagging, is the automated process of assigning relevant tags to educational content, such as questions and textbooks. However, auto-tagging suffers from a data scarcity problem, which stems from two major challenges: 1) it possesses a large tag space and 2) it is multi-label. Though a retrieval approach is reportedly good at low-resource scenarios, there have been fewer efforts to directly address the data scarcity problem. To mitigate these issues, here we propose a novel retrieval approach CEAA that provides effective learning in educational text classification. Our main contributions are as follows: 1) we leverage transfer learning from question-answering datasets, and 2) we propose a simple but effective data augmentation method introducing cross-encoder style texts to a bi-encoder architecture for more efficient inference. An extensive set of experiments shows that our proposed method is effective in multi-label scenarios and low-resource tags compared to state-of-the-art models.
Rank-Aware Negative Training for Semi-Supervised Text Classification
Jun 13, 2023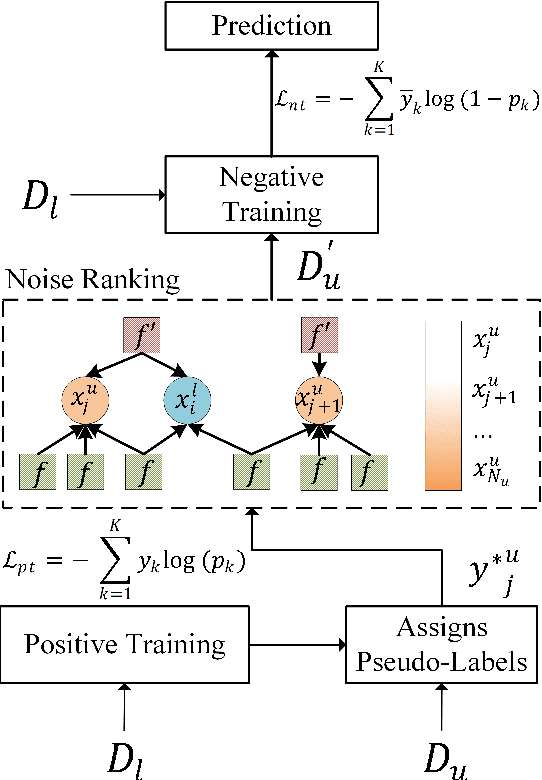
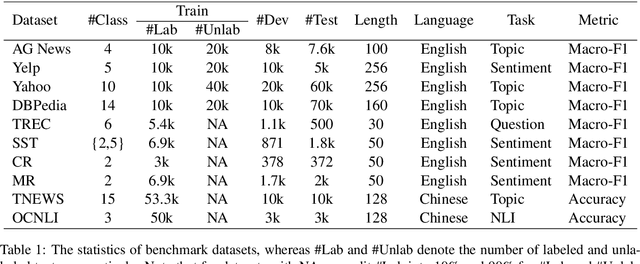
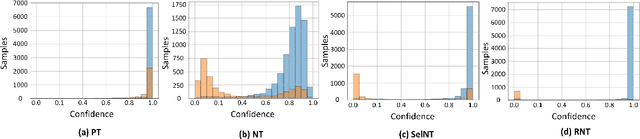
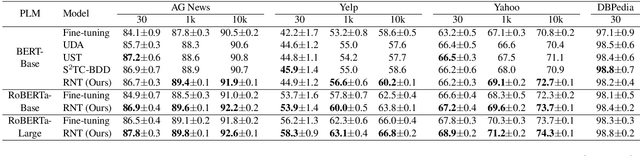
Semi-supervised text classification-based paradigms (SSTC) typically employ the spirit of self-training. The key idea is to train a deep classifier on limited labeled texts and then iteratively predict the unlabeled texts as their pseudo-labels for further training. However, the performance is largely affected by the accuracy of pseudo-labels, which may not be significant in real-world scenarios. This paper presents a Rank-aware Negative Training (RNT) framework to address SSTC in learning with noisy label manner. To alleviate the noisy information, we adapt a reasoning with uncertainty-based approach to rank the unlabeled texts based on the evidential support received from the labeled texts. Moreover, we propose the use of negative training to train RNT based on the concept that ``the input instance does not belong to the complementary label''. A complementary label is randomly selected from all labels except the label on-target. Intuitively, the probability of a true label serving as a complementary label is low and thus provides less noisy information during the training, resulting in better performance on the test data. Finally, we evaluate the proposed solution on various text classification benchmark datasets. Our extensive experiments show that it consistently overcomes the state-of-the-art alternatives in most scenarios and achieves competitive performance in the others. The code of RNT is publicly available at:https://github.com/amurtadha/RNT.
In-Context Learning for Text Classification with Many Labels
Sep 19, 2023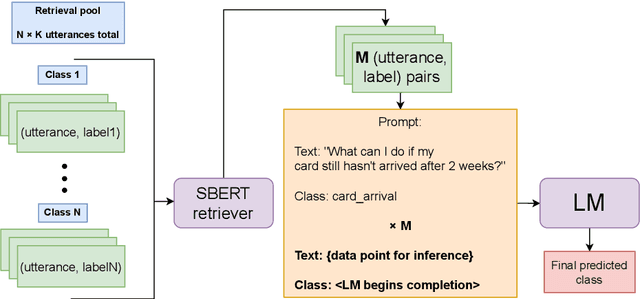
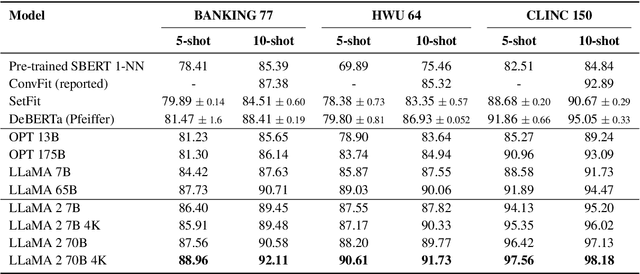
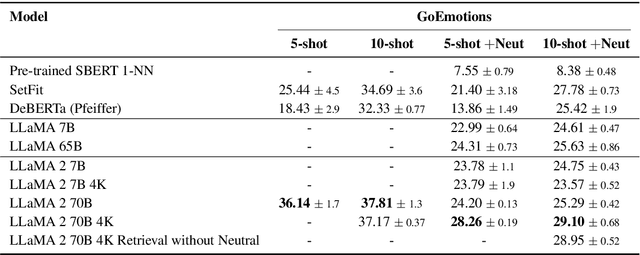
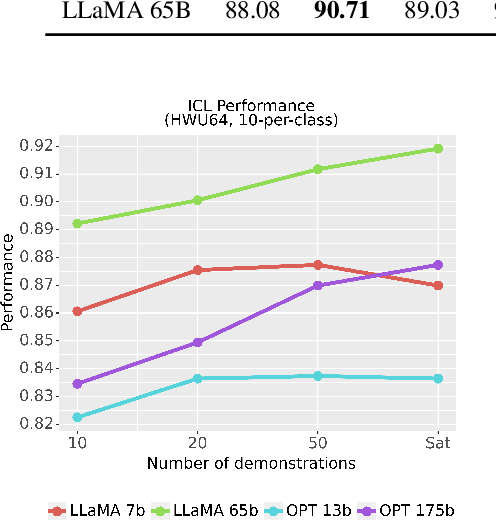
In-context learning (ICL) using large language models for tasks with many labels is challenging due to the limited context window, which makes it difficult to fit a sufficient number of examples in the prompt. In this paper, we use a pre-trained dense retrieval model to bypass this limitation, giving the model only a partial view of the full label space for each inference call. Testing with recent open-source LLMs (OPT, LLaMA), we set new state of the art performance in few-shot settings for three common intent classification datasets, with no finetuning. We also surpass fine-tuned performance on fine-grained sentiment classification in certain cases. We analyze the performance across number of in-context examples and different model scales, showing that larger models are necessary to effectively and consistently make use of larger context lengths for ICL. By running several ablations, we analyze the model's use of: a) the similarity of the in-context examples to the current input, b) the semantic content of the class names, and c) the correct correspondence between examples and labels. We demonstrate that all three are needed to varying degrees depending on the domain, contrary to certain recent works.
Graph Neural Networks for Text Classification: A Survey
Apr 23, 2023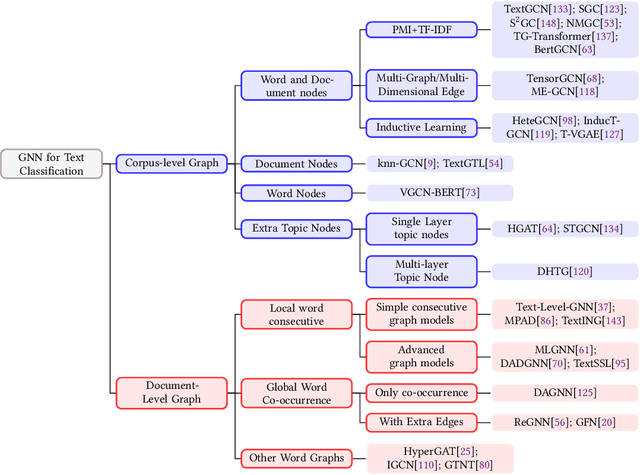
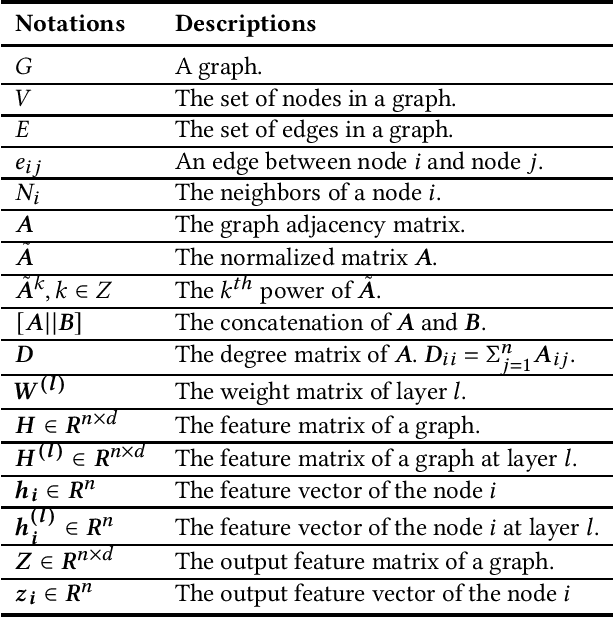
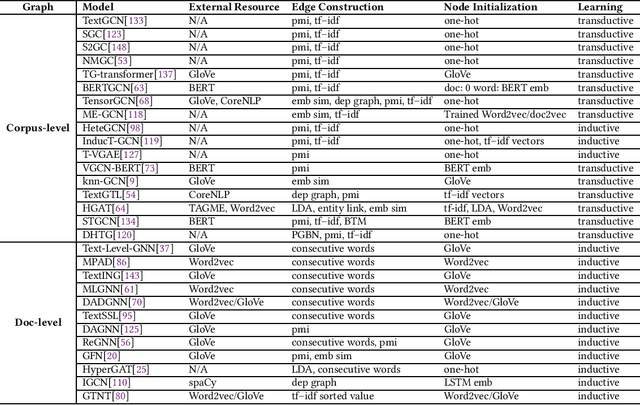
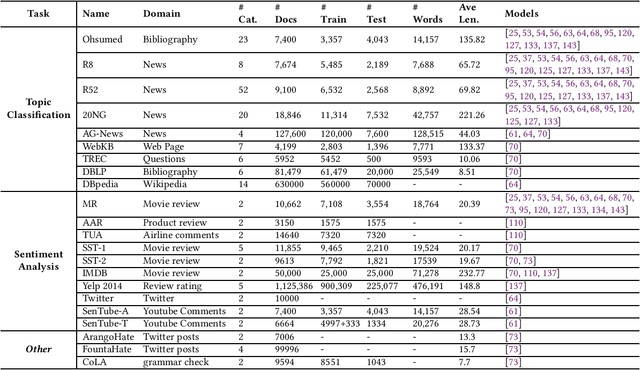
Text Classification is the most essential and fundamental problem in Natural Language Processing. While numerous recent text classification models applied the sequential deep learning technique, graph neural network-based models can directly deal with complex structured text data and exploit global information. Many real text classification applications can be naturally cast into a graph, which captures words, documents, and corpus global features. In this survey, we bring the coverage of methods up to 2023, including corpus-level and document-level graph neural networks. We discuss each of these methods in detail, dealing with the graph construction mechanisms and the graph-based learning process. As well as the technological survey, we look at issues behind and future directions addressed in text classification using graph neural networks. We also cover datasets, evaluation metrics, and experiment design and present a summary of published performance on the publicly available benchmarks. Note that we present a comprehensive comparison between different techniques and identify the pros and cons of various evaluation metrics in this survey.
Generative AI Text Classification using Ensemble LLM Approaches
Sep 14, 2023



Large Language Models (LLMs) have shown impressive performance across a variety of Artificial Intelligence (AI) and natural language processing tasks, such as content creation, report generation, etc. However, unregulated malign application of these models can create undesirable consequences such as generation of fake news, plagiarism, etc. As a result, accurate detection of AI-generated language can be crucial in responsible usage of LLMs. In this work, we explore 1) whether a certain body of text is AI generated or written by human, and 2) attribution of a specific language model in generating a body of text. Texts in both English and Spanish are considered. The datasets used in this study are provided as part of the Automated Text Identification (AuTexTification) shared task. For each of the research objectives stated above, we propose an ensemble neural model that generates probabilities from different pre-trained LLMs which are used as features to a Traditional Machine Learning (TML) classifier following it. For the first task of distinguishing between AI and human generated text, our model ranked in fifth and thirteenth place (with macro $F1$ scores of 0.733 and 0.649) for English and Spanish texts, respectively. For the second task on model attribution, our model ranked in first place with macro $F1$ scores of 0.625 and 0.653 for English and Spanish texts, respectively.
nlpBDpatriots at BLP-2023 Task 1: A Two-Step Classification for Violence Inciting Text Detection in Bangla
Nov 25, 2023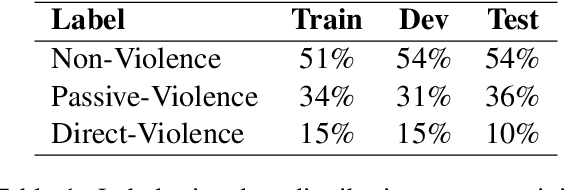
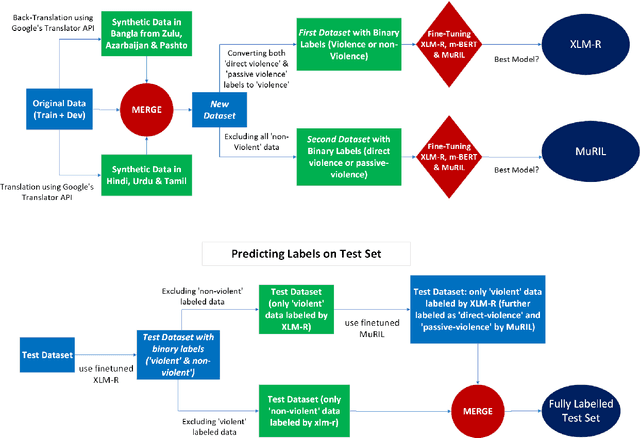
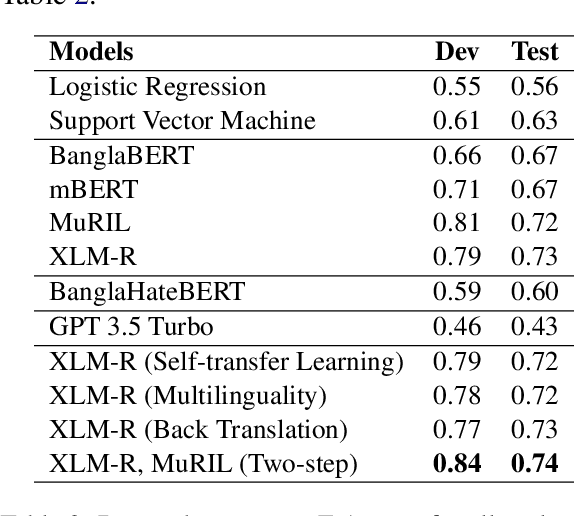
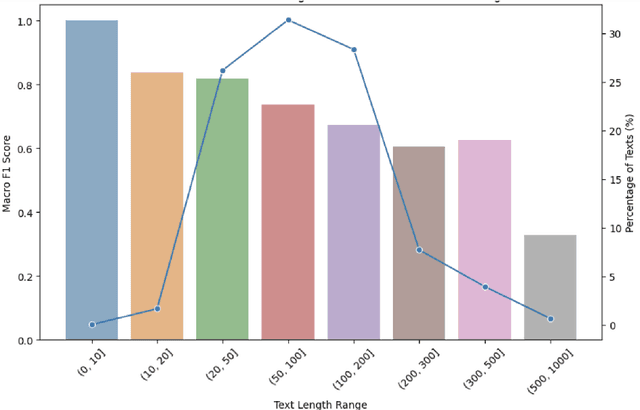
In this paper, we discuss the nlpBDpatriots entry to the shared task on Violence Inciting Text Detection (VITD) organized as part of the first workshop on Bangla Language Processing (BLP) co-located with EMNLP. The aim of this task is to identify and classify the violent threats, that provoke further unlawful violent acts. Our best-performing approach for the task is two-step classification using back translation and multilinguality which ranked 6th out of 27 teams with a macro F1 score of 0.74.
Unsupervised Calibration through Prior Adaptation for Text Classification using Large Language Models
Jul 13, 2023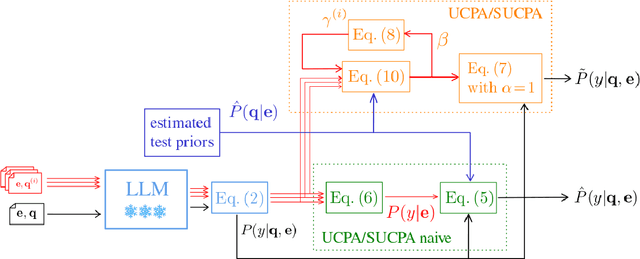
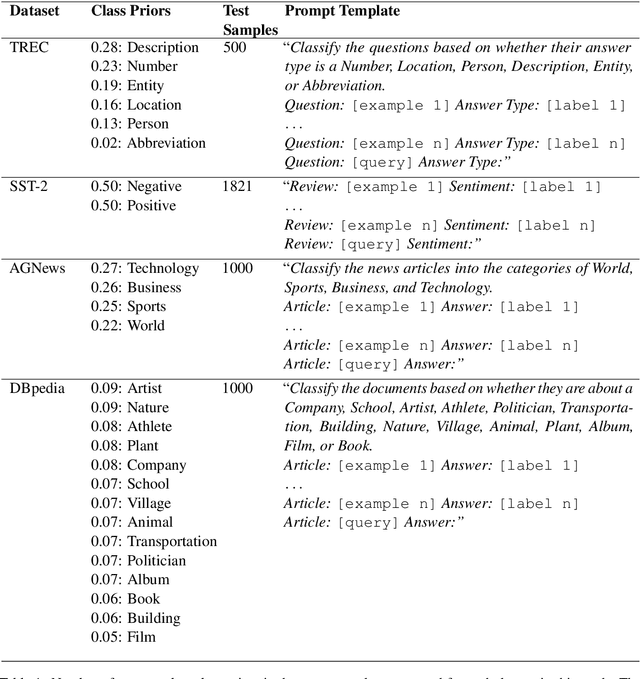
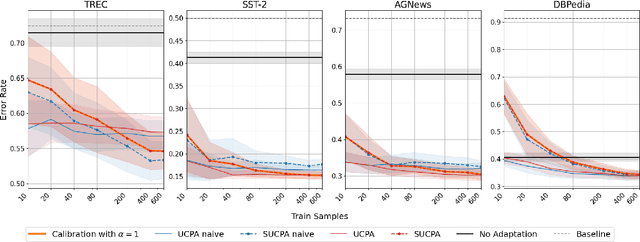
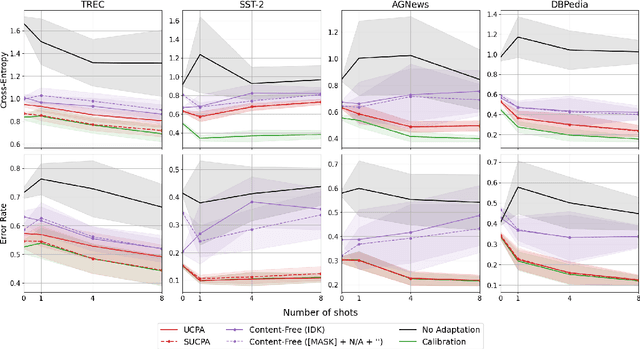
A wide variety of natural language tasks are currently being addressed with large-scale language models (LLMs). These models are usually trained with a very large amount of unsupervised text data and adapted to perform a downstream natural language task using methods like fine-tuning, calibration or in-context learning. In this work, we propose an approach to adapt the prior class distribution to perform text classification tasks without the need for labelled samples and only few in-domain sample queries. The proposed approach treats the LLM as a black box, adding a stage where the model posteriors are calibrated to the task. Results show that these methods outperform the un-adapted model for different number of training shots in the prompt and a previous approach were calibration is performed without using any adaptation data.
PromptCBLUE: A Chinese Prompt Tuning Benchmark for the Medical Domain
Oct 22, 2023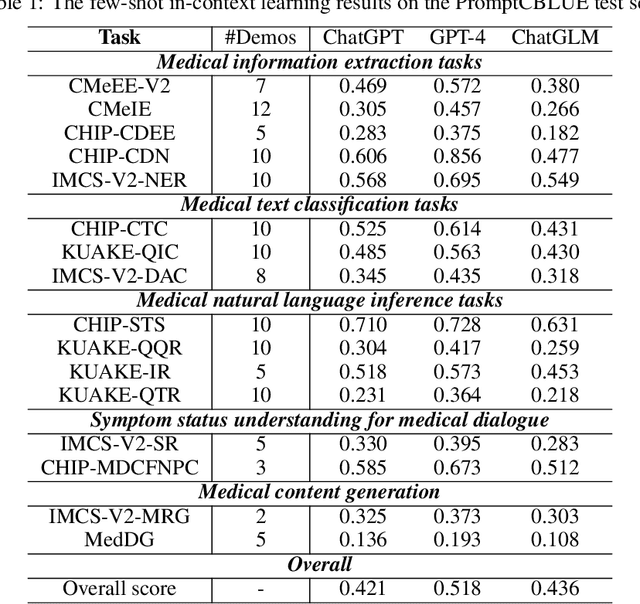
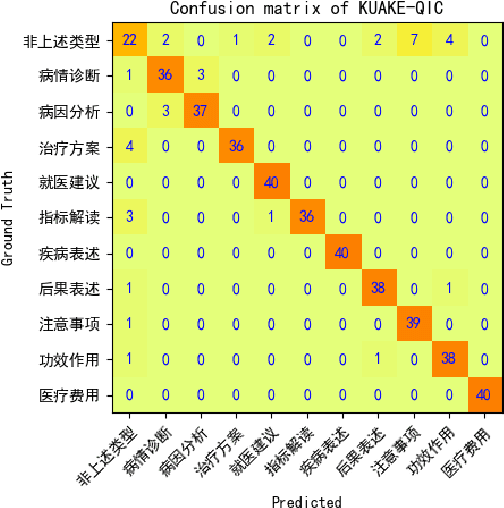
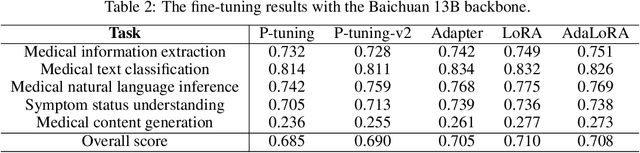
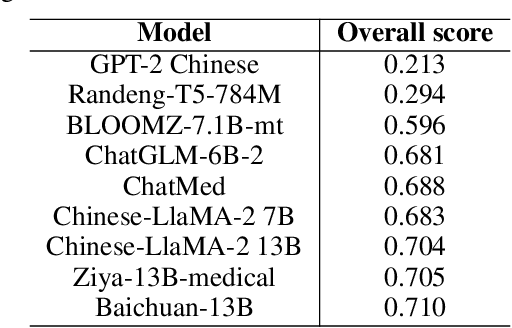
Biomedical language understanding benchmarks are the driving forces for artificial intelligence applications with large language model (LLM) back-ends. However, most current benchmarks: (a) are limited to English which makes it challenging to replicate many of the successes in English for other languages, or (b) focus on knowledge probing of LLMs and neglect to evaluate how LLMs apply these knowledge to perform on a wide range of bio-medical tasks, or (c) have become a publicly available corpus and are leaked to LLMs during pre-training. To facilitate the research in medical LLMs, we re-build the Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark into a large scale prompt-tuning benchmark, PromptCBLUE. Our benchmark is a suitable test-bed and an online platform for evaluating Chinese LLMs' multi-task capabilities on a wide range bio-medical tasks including medical entity recognition, medical text classification, medical natural language inference, medical dialogue understanding and medical content/dialogue generation. To establish evaluation on these tasks, we have experimented and report the results with the current 9 Chinese LLMs fine-tuned with differtent fine-tuning techniques.
VIBE: Topic-Driven Temporal Adaptation for Twitter Classification
Oct 19, 2023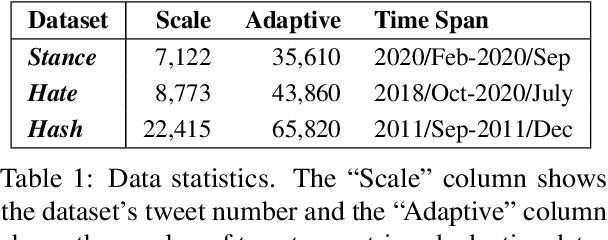
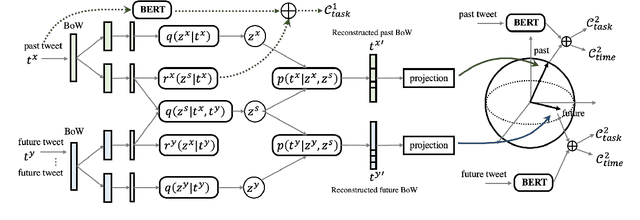
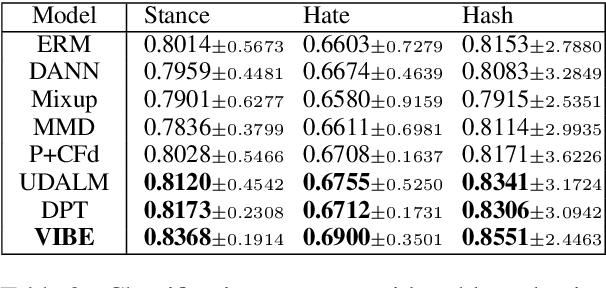
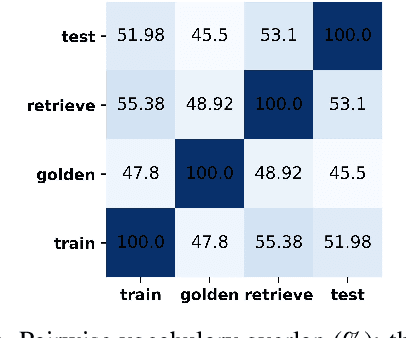
Language features are evolving in real-world social media, resulting in the deteriorating performance of text classification in dynamics. To address this challenge, we study temporal adaptation, where models trained on past data are tested in the future. Most prior work focused on continued pretraining or knowledge updating, which may compromise their performance on noisy social media data. To tackle this issue, we reflect feature change via modeling latent topic evolution and propose a novel model, VIBE: Variational Information Bottleneck for Evolutions. Concretely, we first employ two Information Bottleneck (IB) regularizers to distinguish past and future topics. Then, the distinguished topics work as adaptive features via multi-task training with timestamp and class label prediction. In adaptive learning, VIBE utilizes retrieved unlabeled data from online streams created posterior to training data time. Substantial Twitter experiments on three classification tasks show that our model, with only 3% of data, significantly outperforms previous state-of-the-art continued-pretraining methods.
* accepted by EMNLP 2023
Augmenting Low-Resource Text Classification with Graph-Grounded Pre-training and Prompting
May 05, 2023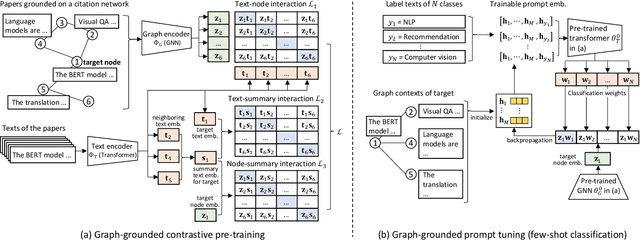
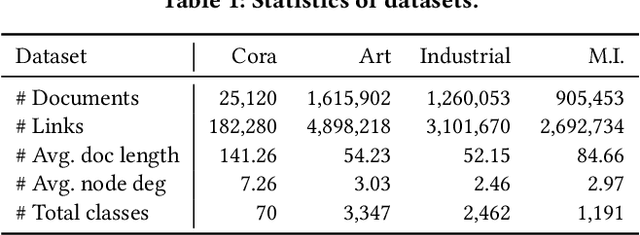
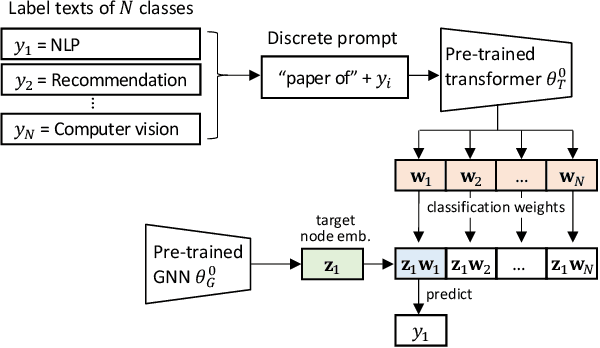
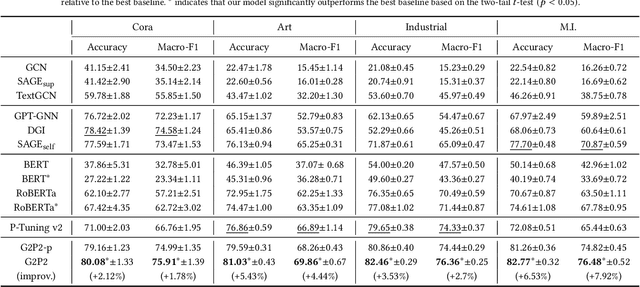
Text classification is a fundamental problem in information retrieval with many real-world applications, such as predicting the topics of online articles and the categories of e-commerce product descriptions. However, low-resource text classification, with few or no labeled samples, poses a serious concern for supervised learning. Meanwhile, many text data are inherently grounded on a network structure, such as a hyperlink/citation network for online articles, and a user-item purchase network for e-commerce products. These graph structures capture rich semantic relationships, which can potentially augment low-resource text classification. In this paper, we propose a novel model called Graph-Grounded Pre-training and Prompting (G2P2) to address low-resource text classification in a two-pronged approach. During pre-training, we propose three graph interaction-based contrastive strategies to jointly pre-train a graph-text model; during downstream classification, we explore prompting for the jointly pre-trained model to achieve low-resource classification. Extensive experiments on four real-world datasets demonstrate the strength of G2P2 in zero- and few-shot low-resource text classification tasks.