 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Leveraging Artificial Intelligence Technology for Mapping Research to Sustainable Development Goals: A Case Study
Nov 09, 2023
The number of publications related to the Sustainable Development Goals (SDGs) continues to grow. These publications cover a diverse spectrum of research, from humanities and social sciences to engineering and health. Given the imperative of funding bodies to monitor outcomes and impacts, linking publications to relevant SDGs is critical but remains time-consuming and difficult given the breadth and complexity of the SDGs. A publication may relate to several goals (interconnection feature of goals), and therefore require multidisciplinary knowledge to tag accurately. Machine learning approaches are promising and have proven particularly valuable for tasks such as manual data labeling and text classification. In this study, we employed over 82,000 publications from an Australian university as a case study. We utilized a similarity measure to map these publications onto Sustainable Development Goals (SDGs). Additionally, we leveraged the OpenAI GPT model to conduct the same task, facilitating a comparative analysis between the two approaches. Experimental results show that about 82.89% of the results obtained by the similarity measure overlap (at least one tag) with the outputs of the GPT model. The adopted model (similarity measure) can complement GPT model for SDG classification. Furthermore, deep learning methods, which include the similarity measure used here, are more accessible and trusted for dealing with sensitive data without the use of commercial AI services or the deployment of expensive computing resources to operate large language models. Our study demonstrates how a crafted combination of the two methods can achieve reliable results for mapping research to the SDGs.
RepCL: Exploring Effective Representation for Continual Text Classification
May 12, 2023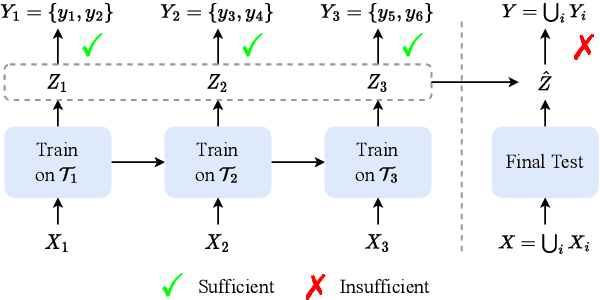
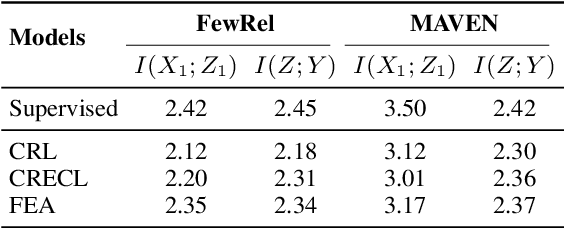
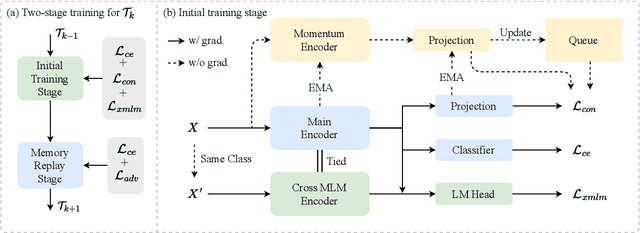
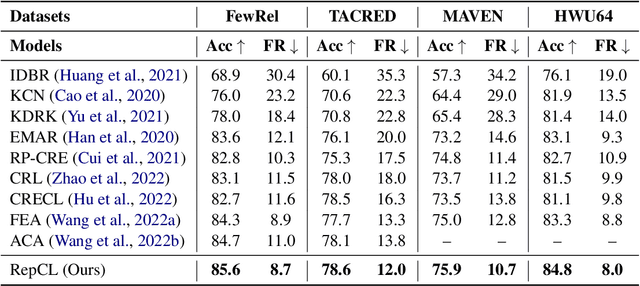
Continual learning (CL) aims to constantly learn new knowledge over time while avoiding catastrophic forgetting on old tasks. In this work, we focus on continual text classification under the class-incremental setting. Recent CL studies find that the representations learned in one task may not be effective for other tasks, namely representation bias problem. For the first time we formally analyze representation bias from an information bottleneck perspective and suggest that exploiting representations with more class-relevant information could alleviate the bias. To this end, we propose a novel replay-based continual text classification method, RepCL. Our approach utilizes contrastive and generative representation learning objectives to capture more class-relevant features. In addition, RepCL introduces an adversarial replay strategy to alleviate the overfitting problem of replay. Experiments demonstrate that RepCL effectively alleviates forgetting and achieves state-of-the-art performance on three text classification tasks.
Text Classification via Large Language Models
May 15, 2023

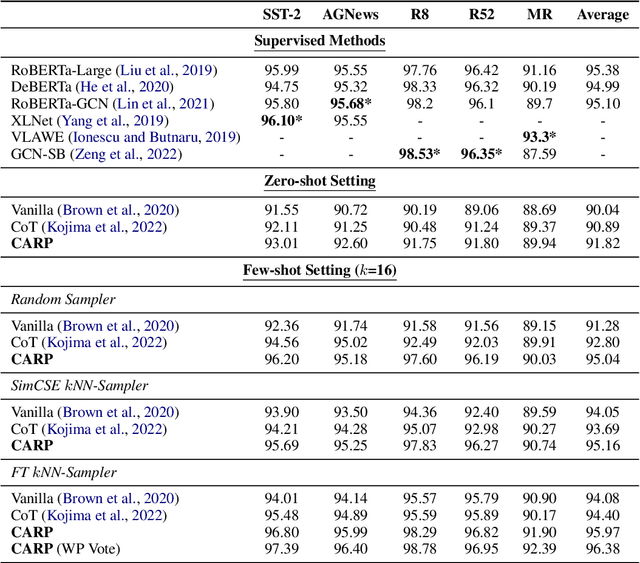
Despite the remarkable success of large-scale Language Models (LLMs) such as GPT-3, their performances still significantly underperform fine-tuned models in the task of text classification. This is due to (1) the lack of reasoning ability in addressing complex linguistic phenomena (e.g., intensification, contrast, irony etc); (2) limited number of tokens allowed in in-context learning. In this paper, we introduce \textbf{C}lue \textbf{A}nd \textbf{R}easoning \textbf{P}rompting (CARP). CARP adopts a progressive reasoning strategy tailored to addressing the complex linguistic phenomena involved in text classification: CARP first prompts LLMs to find superficial clues (e.g., keywords, tones, semantic relations, references, etc), based on which a diagnostic reasoning process is induced for final decisions. To further address the limited-token issue, CARP uses a fine-tuned model on the supervised dataset for $k$NN demonstration search in the in-context learning, allowing the model to take the advantage of both LLM's generalization ability and the task-specific evidence provided by the full labeled dataset. Remarkably, CARP yields new SOTA performances on 4 out of 5 widely-used text-classification benchmarks, 97.39 (+1.24) on SST-2, 96.40 (+0.72) on AGNews, 98.78 (+0.25) on R8 and 96.95 (+0.6) on R52, and a performance comparable to SOTA on MR (92.39 v.s. 93.3). More importantly, we find that CARP delivers impressive abilities on low-resource and domain-adaptation setups. Specifically, Specifically, using 16 examples per class, CARP achieves comparable performances to supervised models with 1,024 examples per class.
Do Not Harm Protected Groups in Debiasing Language Representation Models
Oct 27, 2023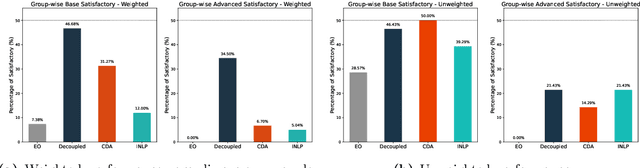
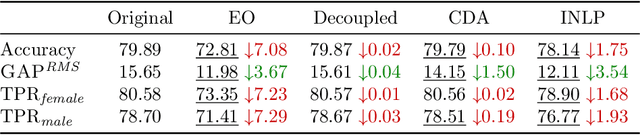

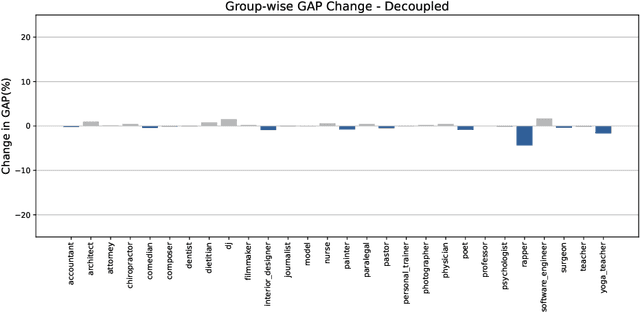
Language Representation Models (LRMs) trained with real-world data may capture and exacerbate undesired bias and cause unfair treatment of people in various demographic groups. Several techniques have been investigated for applying interventions to LRMs to remove bias in benchmark evaluations on, for example, word embeddings. However, the negative side effects of debiasing interventions are usually not revealed in the downstream tasks. We propose xGAP-DEBIAS, a set of evaluations on assessing the fairness of debiasing. In this work, We examine four debiasing techniques on a real-world text classification task and show that reducing biasing is at the cost of degrading performance for all demographic groups, including those the debiasing techniques aim to protect. We advocate that a debiasing technique should have good downstream performance with the constraint of ensuring no harm to the protected group.
ContrastNet: A Contrastive Learning Framework for Few-Shot Text Classification
May 16, 2023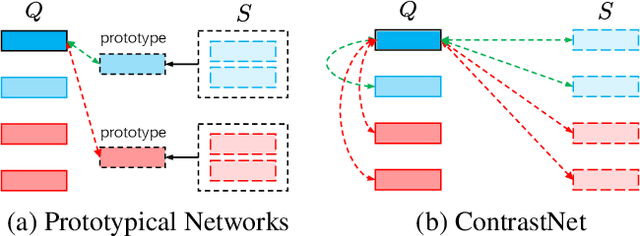
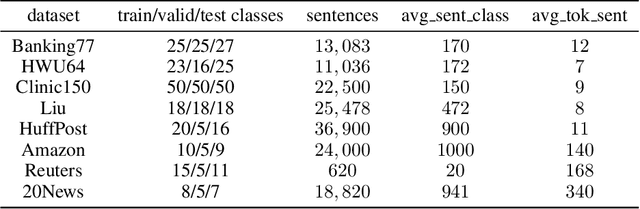
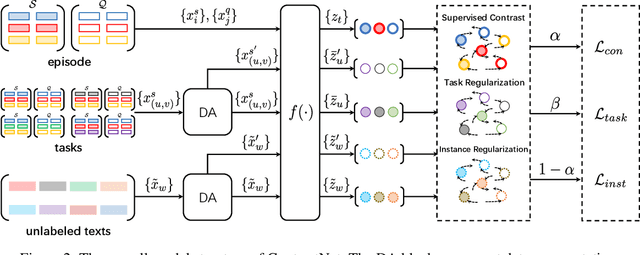
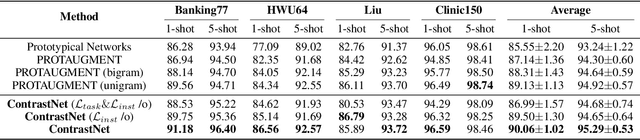
Few-shot text classification has recently been promoted by the meta-learning paradigm which aims to identify target classes with knowledge transferred from source classes with sets of small tasks named episodes. Despite their success, existing works building their meta-learner based on Prototypical Networks are unsatisfactory in learning discriminative text representations between similar classes, which may lead to contradictions during label prediction. In addition, the tasklevel and instance-level overfitting problems in few-shot text classification caused by a few training examples are not sufficiently tackled. In this work, we propose a contrastive learning framework named ContrastNet to tackle both discriminative representation and overfitting problems in few-shot text classification. ContrastNet learns to pull closer text representations belonging to the same class and push away text representations belonging to different classes, while simultaneously introducing unsupervised contrastive regularization at both task-level and instance-level to prevent overfitting. Experiments on 8 few-shot text classification datasets show that ContrastNet outperforms the current state-of-the-art models.
PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Dec 08, 2023The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
Learning Using Generated Privileged Information by Text-to-Image Diffusion Models
Sep 26, 2023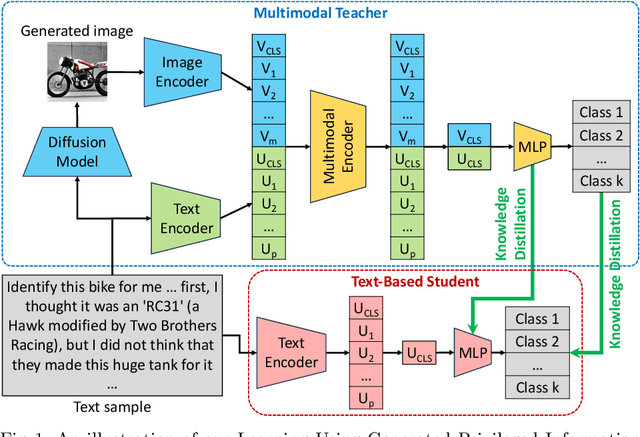
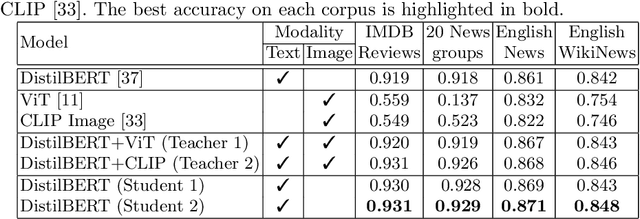

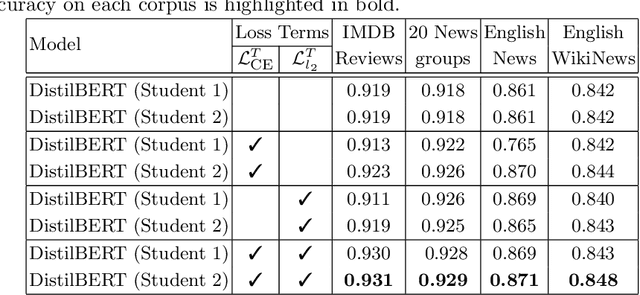
Learning Using Privileged Information is a particular type of knowledge distillation where the teacher model benefits from an additional data representation during training, called privileged information, improving the student model, which does not see the extra representation. However, privileged information is rarely available in practice. To this end, we propose a text classification framework that harnesses text-to-image diffusion models to generate artificial privileged information. The generated images and the original text samples are further used to train multimodal teacher models based on state-of-the-art transformer-based architectures. Finally, the knowledge from multimodal teachers is distilled into a text-based (unimodal) student. Hence, by employing a generative model to produce synthetic data as privileged information, we guide the training of the student model. Our framework, called Learning Using Generated Privileged Information (LUGPI), yields noticeable performance gains on four text classification data sets, demonstrating its potential in text classification without any additional cost during inference.
Sequencing Matters: A Generate-Retrieve-Generate Model for Building Conversational Agents
Nov 16, 2023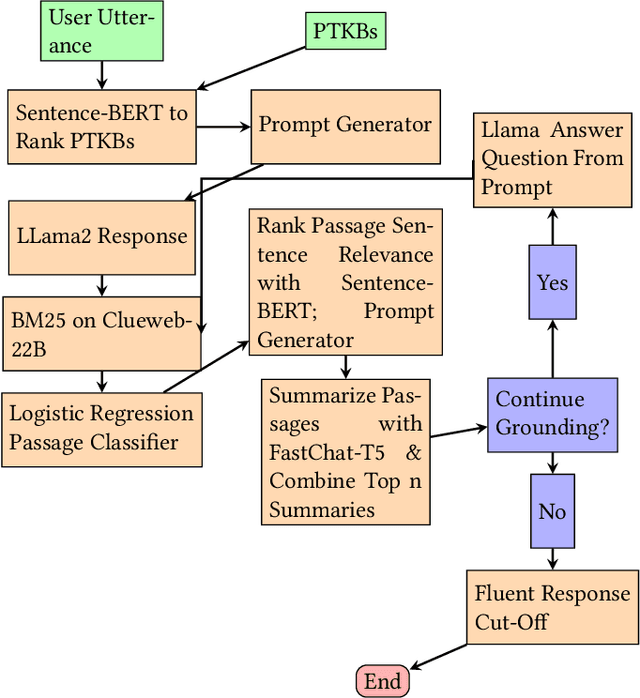
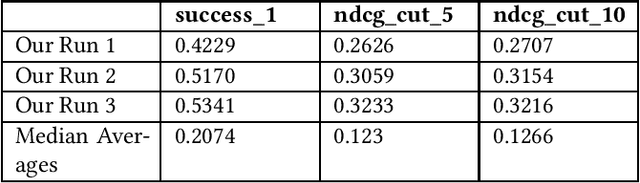


This paper contains what the Georgetown InfoSense group has done in regard to solving the challenges presented by TREC iKAT 2023. Our submitted runs outperform the median runs by a significant margin, exhibiting superior performance in nDCG across various cut numbers and in overall success rate. Our approach uses a Generate-Retrieve-Generate method, which we've found to greatly outpace Retrieve-Then-Generate approaches for the purposes of iKAT. Our solution involves the use of Large Language Models (LLMs) for initial answers, answer grounding by BM25, passage quality filtering by logistic regression, and answer generation by LLMs again. We leverage several purpose-built Language Models, including BERT, Chat-based, and text-to-transfer-based models, for text understanding, classification, generation, and summarization. The official results of the TREC evaluation contradict our initial self-evaluation, which may suggest that a decrease in the reliance on our retrieval and classification methods is better. Nonetheless, our findings suggest that the sequence of involving these different components matters, where we see an essentiality of using LLMs before using search engines.
Manipulating the Label Space for In-Context Classification
Dec 06, 2023After pre-training by generating the next word conditional on previous words, the Language Model (LM) acquires the ability of In-Context Learning (ICL) that can learn a new task conditional on the context of the given in-context examples (ICEs). Similarly, visually-conditioned Language Modelling is also used to train Vision-Language Models (VLMs) with ICL ability. However, such VLMs typically exhibit weaker classification abilities compared to contrastive learning-based models like CLIP, since the Language Modelling objective does not directly contrast whether an object is paired with a text. To improve the ICL of classification, using more ICEs to provide more knowledge is a straightforward way. However, this may largely increase the selection time, and more importantly, the inclusion of additional in-context images tends to extend the length of the in-context sequence beyond the processing capacity of a VLM. To alleviate these limitations, we propose to manipulate the label space of each ICE to increase its knowledge density, allowing for fewer ICEs to convey as much information as a larger set would. Specifically, we propose two strategies which are Label Distribution Enhancement and Visual Descriptions Enhancement to improve In-context classification performance on diverse datasets, including the classic ImageNet and more fine-grained datasets like CUB-200. Specifically, using our approach on ImageNet, we increase accuracy from 74.70\% in a 4-shot setting to 76.21\% with just 2 shots. surpassing CLIP by 0.67\%. On CUB-200, our method raises 1-shot accuracy from 48.86\% to 69.05\%, 12.15\% higher than CLIP. The code is given in https://anonymous.4open.science/r/MLS_ICC.
MedAI Dialog Corpus (MEDIC): Zero-Shot Classification of Doctor and AI Responses in Health Consultations
Oct 20, 2023
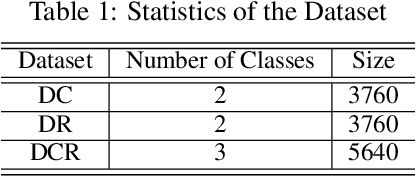

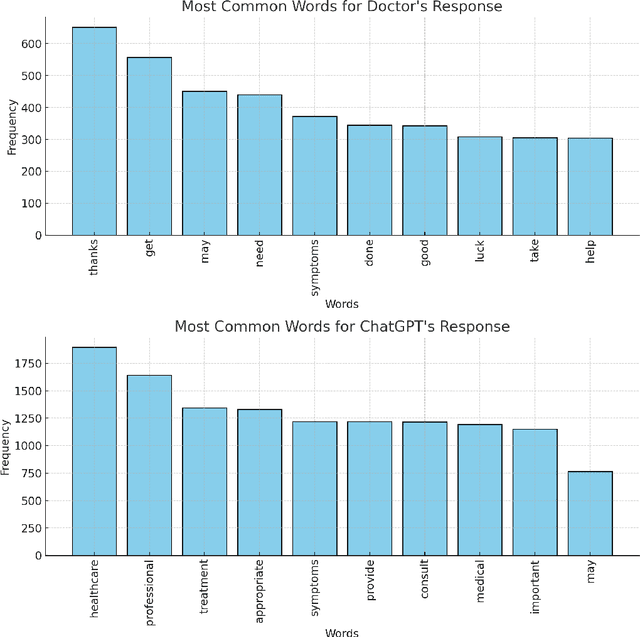
Zero-shot classification enables text to be classified into classes not seen during training. In this research, we investigate the effectiveness of pre-trained language models to accurately classify responses from Doctors and AI in health consultations through zero-shot learning. Our study aims to determine whether these models can effectively detect if a text originates from human or AI models without specific corpus training. We collect responses from doctors to patient inquiries about their health and pose the same question/response to AI models. While zero-shot language models show a good understanding of language in general, they have limitations in classifying doctor and AI responses in healthcare consultations. This research lays the groundwork for further research into this field of medical text classification, informing the development of more effective approaches to accurately classify doctor-generated and AI-generated text in health consultations.