 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
WOT-Class: Weakly Supervised Open-world Text Classification
May 21, 2023
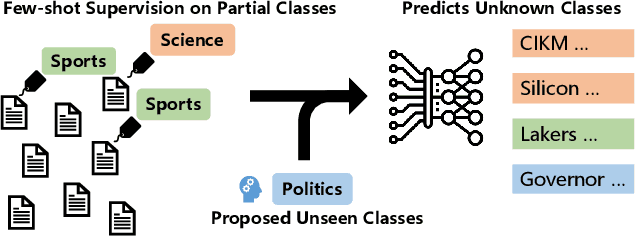

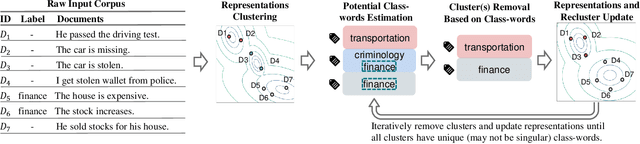
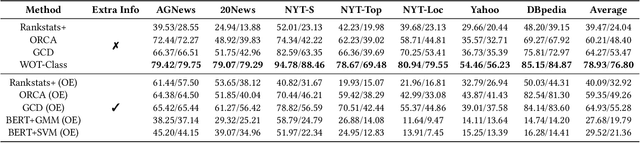
State-of-the-art weakly supervised text classification methods, while significantly reduced the required human supervision, still requires the supervision to cover all the classes of interest. This is never easy to meet in practice when human explore new, large corpora without complete pictures. In this paper, we work on a novel yet important problem of weakly supervised open-world text classification, where supervision is only needed for a few examples from a few known classes and the machine should handle both known and unknown classes in test time. General open-world classification has been studied mostly using image classification; however, existing methods typically assume the availability of sufficient known-class supervision and strong unknown-class prior knowledge (e.g., the number and/or data distribution). We propose a novel framework WOT-Class that lifts those strong assumptions. Specifically, it follows an iterative process of (a) clustering text to new classes, (b) mining and ranking indicative words for each class, and (c) merging redundant classes by using the overlapped indicative words as a bridge. Extensive experiments on 7 popular text classification datasets demonstrate that WOT-Class outperforms strong baselines consistently with a large margin, attaining 23.33% greater average absolute macro-F1 over existing approaches across all datasets. Such competent accuracy illuminates the practical potential of further reducing human effort for text classification.
Zero-Shot Text Classification via Self-Supervised Tuning
May 25, 2023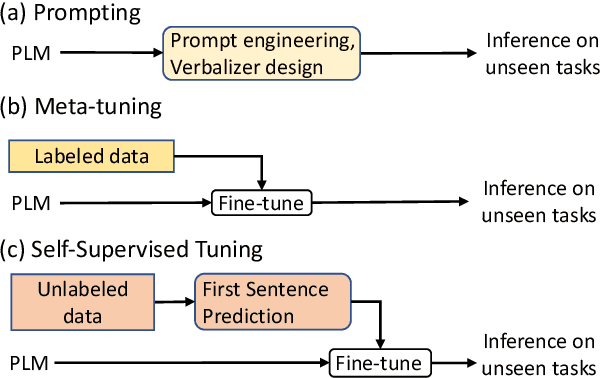
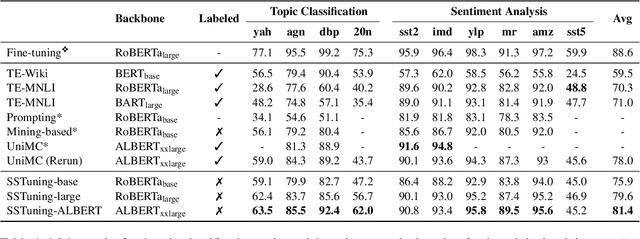
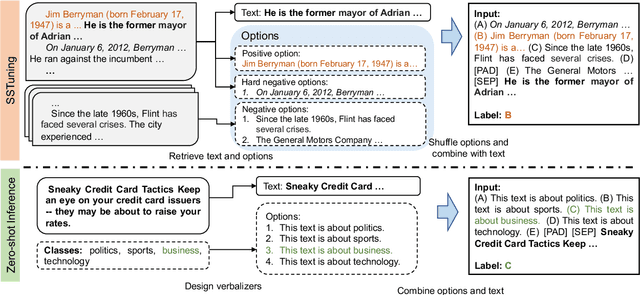
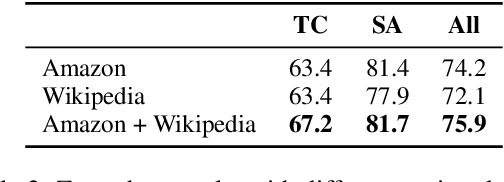
Existing solutions to zero-shot text classification either conduct prompting with pre-trained language models, which is sensitive to the choices of templates, or rely on large-scale annotated data of relevant tasks for meta-tuning. In this work, we propose a new paradigm based on self-supervised learning to solve zero-shot text classification tasks by tuning the language models with unlabeled data, called self-supervised tuning. By exploring the inherent structure of free texts, we propose a new learning objective called first sentence prediction to bridge the gap between unlabeled data and text classification tasks. After tuning the model to learn to predict the first sentence in a paragraph based on the rest, the model is able to conduct zero-shot inference on unseen tasks such as topic classification and sentiment analysis. Experimental results show that our model outperforms the state-of-the-art baselines on 7 out of 10 tasks. Moreover, the analysis reveals that our model is less sensitive to the prompt design. Our code and pre-trained models are publicly available at https://github.com/DAMO-NLP-SG/SSTuning .
Label Agnostic Pre-training for Zero-shot Text Classification
May 25, 2023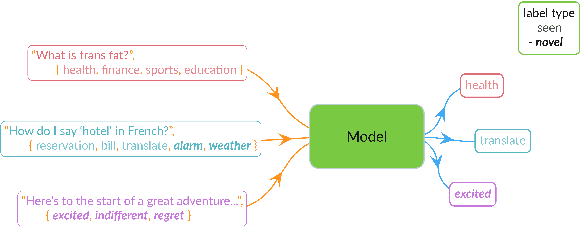
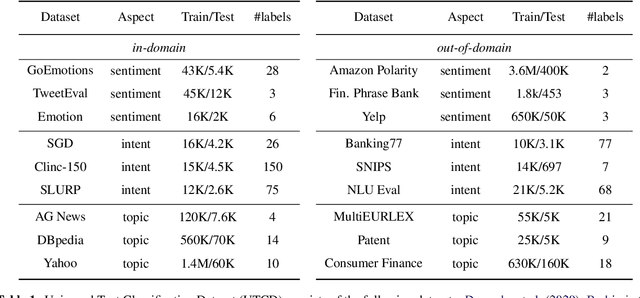
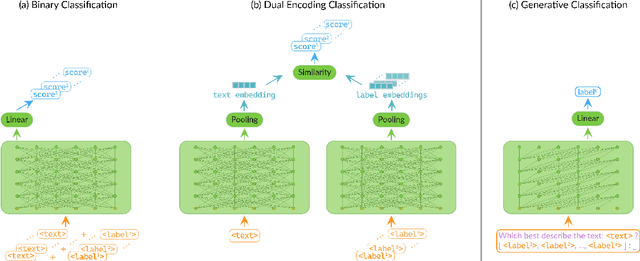
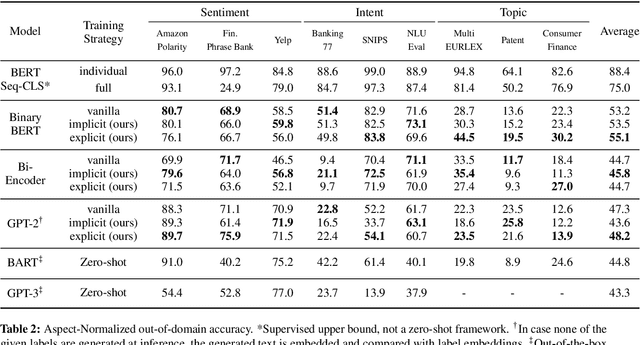
Conventional approaches to text classification typically assume the existence of a fixed set of predefined labels to which a given text can be classified. However, in real-world applications, there exists an infinite label space for describing a given text. In addition, depending on the aspect (sentiment, topic, etc.) and domain of the text (finance, legal, etc.), the interpretation of the label can vary greatly. This makes the task of text classification, particularly in the zero-shot scenario, extremely challenging. In this paper, we investigate the task of zero-shot text classification with the aim of improving the ability of pre-trained language models (PLMs) to generalize to both seen and unseen data across varying aspects and domains. To solve this we introduce two new simple yet effective pre-training strategies, Implicit and Explicit pre-training. These methods inject aspect-level understanding into the model at train time with the goal of conditioning the model to build task-level understanding. To evaluate this, we construct and release UTCD, a new benchmark dataset for evaluating text classification in zero-shot settings. Experimental results on UTCD show that our approach achieves improved zero-shot generalization on a suite of challenging datasets across an array of zero-shot formalizations.
PESCO: Prompt-enhanced Self Contrastive Learning for Zero-shot Text Classification
May 24, 2023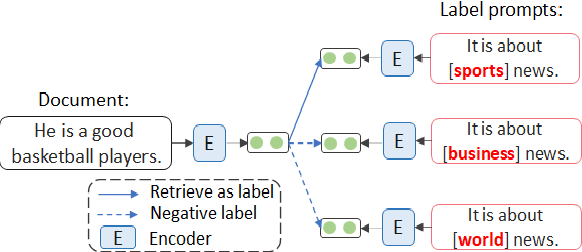


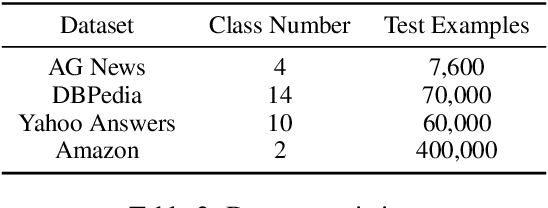
We present PESCO, a novel contrastive learning framework that substantially improves the performance of zero-shot text classification. We formulate text classification as a neural text matching problem where each document is treated as a query, and the system learns the mapping from each query to the relevant class labels by (1) adding prompts to enhance label matching, and (2) using retrieved labels to enrich the training set in a self-training loop of contrastive learning. PESCO achieves state-of-the-art performance on four benchmark text classification datasets. On DBpedia, we achieve 98.5\% accuracy without any labeled data, which is close to the fully-supervised result. Extensive experiments and analyses show all the components of PESCO are necessary for improving the performance of zero-shot text classification.
* accepted by ACL 2023
A Simple yet Efficient Ensemble Approach for AI-generated Text Detection
Nov 08, 2023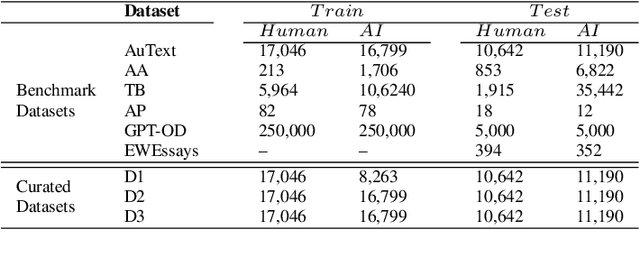
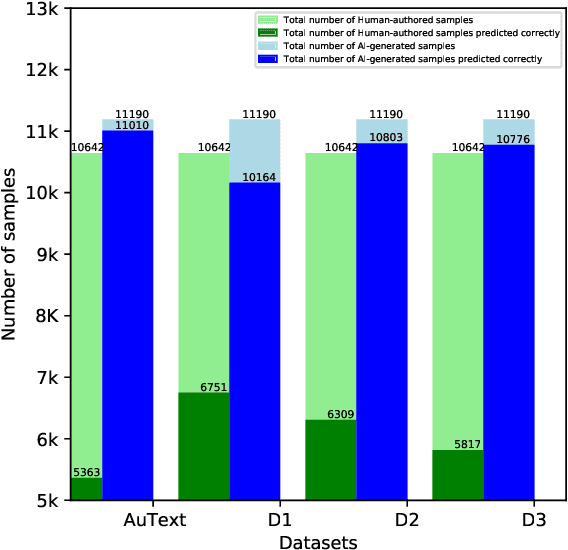
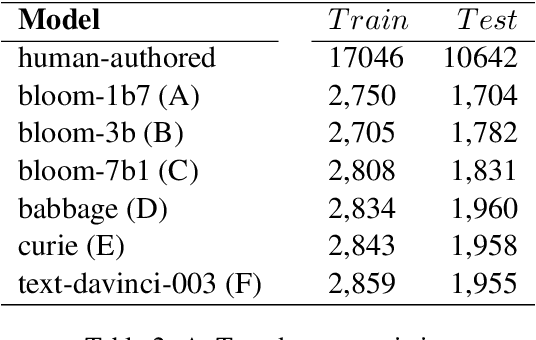
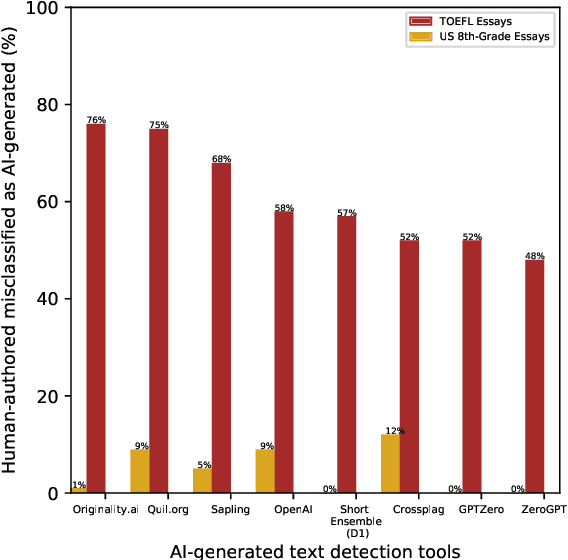
Recent Large Language Models (LLMs) have demonstrated remarkable capabilities in generating text that closely resembles human writing across wide range of styles and genres. However, such capabilities are prone to potential abuse, such as fake news generation, spam email creation, and misuse in academic assignments. Hence, it is essential to build automated approaches capable of distinguishing between artificially generated text and human-authored text. In this paper, we propose a simple yet efficient solution to this problem by ensembling predictions from multiple constituent LLMs. Compared to previous state-of-the-art approaches, which are perplexity-based or uses ensembles with a number of LLMs, our condensed ensembling approach uses only two constituent LLMs to achieve comparable performance. Experiments conducted on four benchmark datasets for generative text classification show performance improvements in the range of 0.5 to 100\% compared to previous state-of-the-art approaches. We also study the influence that the training data from individual LLMs have on model performance. We found that substituting commercially-restrictive Generative Pre-trained Transformer (GPT) data with data generated from other open language models such as Falcon, Large Language Model Meta AI (LLaMA2), and Mosaic Pretrained Transformers (MPT) is a feasible alternative when developing generative text detectors. Furthermore, to demonstrate zero-shot generalization, we experimented with an English essays dataset, and results suggest that our ensembling approach can handle new data effectively.
Implementation and Comparison of Methods to Extract Reliability KPIs out of Textual Wind Turbine Maintenance Work Orders
Nov 07, 2023Maintenance work orders are commonly used to document information about wind turbine operation and maintenance. This includes details about proactive and reactive wind turbine downtimes, such as preventative and corrective maintenance. However, the information contained in maintenance work orders is often unstructured and difficult to analyze, making it challenging for decision-makers to use this information for optimizing operation and maintenance. To address this issue, this work presents three different approaches to calculate reliability key performance indicators from maintenance work orders. The first approach involves manual labeling of the maintenance work orders by domain experts, using the schema defined in an industrial guideline to assign the label accordingly. The second approach involves the development of a model that automatically labels the maintenance work orders using text classification methods. The third technique uses an AI-assisted tagging tool to tag and structure the raw maintenance information contained in the maintenance work orders. The resulting calculated reliability key performance indicator of the first approach are used as a benchmark for comparison with the results of the second and third approaches. The quality and time spent are considered as criteria for evaluation. Overall, these three methods make extracting maintenance information from maintenance work orders more efficient, enable the assessment of reliability key performance indicators and therefore support the optimization of wind turbine operation and maintenance.
On Bias and Fairness in NLP: How to have a fairer text classification?
May 22, 2023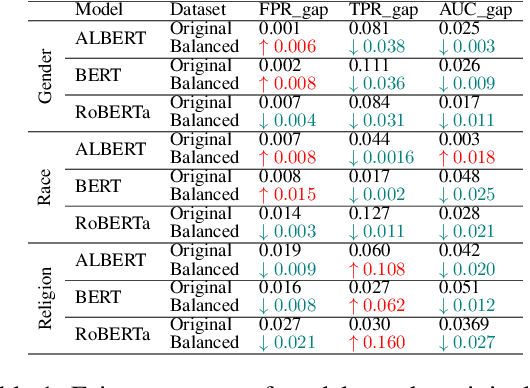

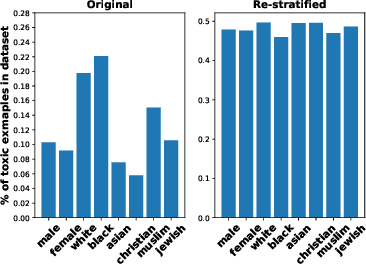
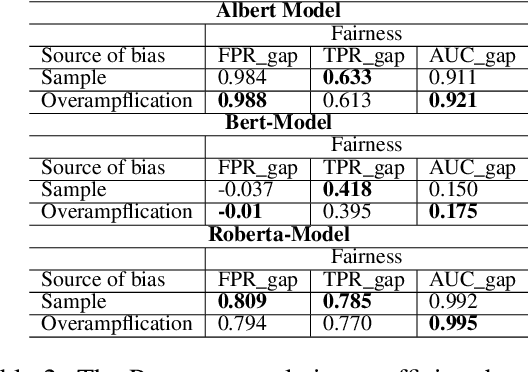
In this paper, we provide a holistic analysis of the different sources of bias, Upstream, Sample and Overampflication biases, in NLP models. We investigate how they impact the fairness of the task of text classification. We also investigate the impact of removing these biases using different debiasing techniques on the fairness of text classification. We found that overamplification bias is the most impactful bias on the fairness of text classification. And that removing overamplification bias by fine-tuning the LM models on a dataset with balanced representations of the different identity groups leads to fairer text classification models. Finally, we build on our findings and introduce practical guidelines on how to have a fairer text classification model.
Evolutionary Verbalizer Search for Prompt-based Few Shot Text Classification
Jun 18, 2023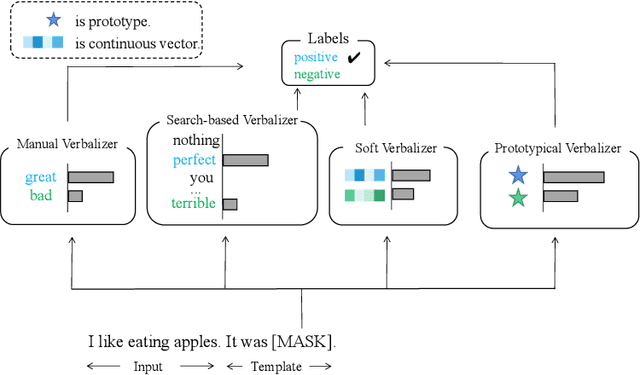
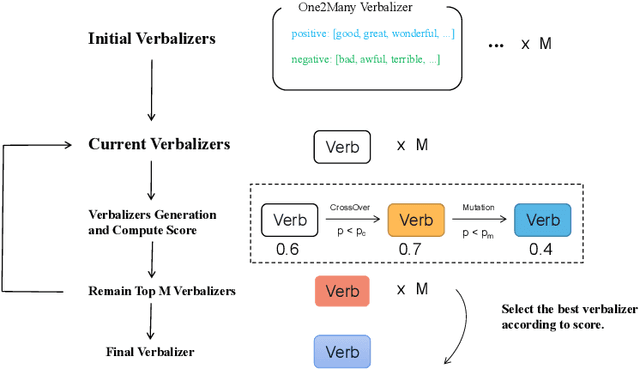
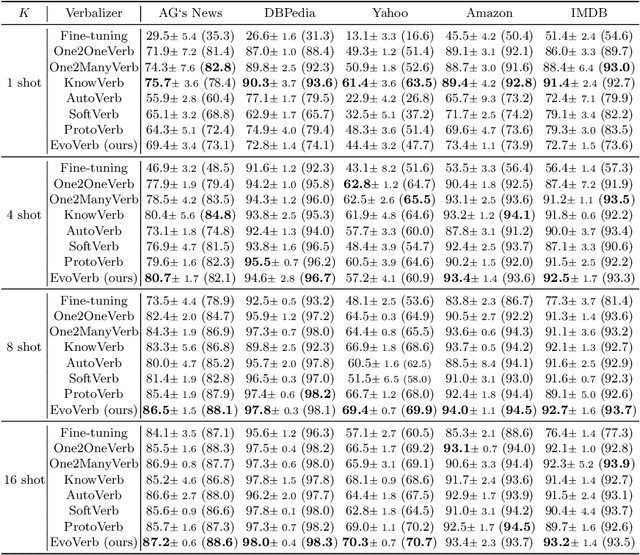
Recent advances for few-shot text classification aim to wrap textual inputs with task-specific prompts to cloze questions. By processing them with a masked language model to predict the masked tokens and using a verbalizer that constructs the mapping between predicted words and target labels. This approach of using pre-trained language models is called prompt-based tuning, which could remarkably outperform conventional fine-tuning approach in the low-data scenario. As the core of prompt-based tuning, the verbalizer is usually handcrafted with human efforts or suboptimally searched by gradient descent. In this paper, we focus on automatically constructing the optimal verbalizer and propose a novel evolutionary verbalizer search (EVS) algorithm, to improve prompt-based tuning with the high-performance verbalizer. Specifically, inspired by evolutionary algorithm (EA), we utilize it to automatically evolve various verbalizers during the evolutionary procedure and select the best one after several iterations. Extensive few-shot experiments on five text classification datasets show the effectiveness of our method.
Leveraging Artificial Intelligence Technology for Mapping Research to Sustainable Development Goals: A Case Study
Nov 09, 2023The number of publications related to the Sustainable Development Goals (SDGs) continues to grow. These publications cover a diverse spectrum of research, from humanities and social sciences to engineering and health. Given the imperative of funding bodies to monitor outcomes and impacts, linking publications to relevant SDGs is critical but remains time-consuming and difficult given the breadth and complexity of the SDGs. A publication may relate to several goals (interconnection feature of goals), and therefore require multidisciplinary knowledge to tag accurately. Machine learning approaches are promising and have proven particularly valuable for tasks such as manual data labeling and text classification. In this study, we employed over 82,000 publications from an Australian university as a case study. We utilized a similarity measure to map these publications onto Sustainable Development Goals (SDGs). Additionally, we leveraged the OpenAI GPT model to conduct the same task, facilitating a comparative analysis between the two approaches. Experimental results show that about 82.89% of the results obtained by the similarity measure overlap (at least one tag) with the outputs of the GPT model. The adopted model (similarity measure) can complement GPT model for SDG classification. Furthermore, deep learning methods, which include the similarity measure used here, are more accessible and trusted for dealing with sensitive data without the use of commercial AI services or the deployment of expensive computing resources to operate large language models. Our study demonstrates how a crafted combination of the two methods can achieve reliable results for mapping research to the SDGs.
T3L: Translate-and-Test Transfer Learning for Cross-Lingual Text Classification
Jun 08, 2023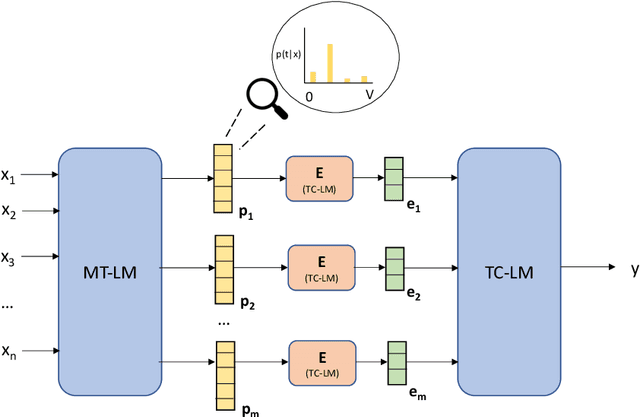
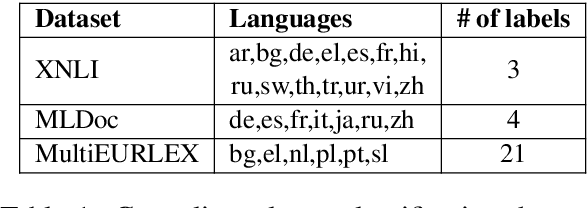
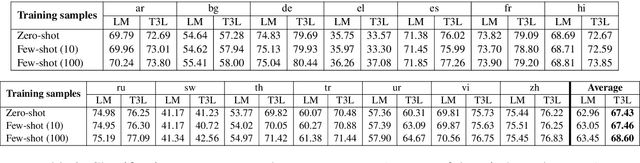
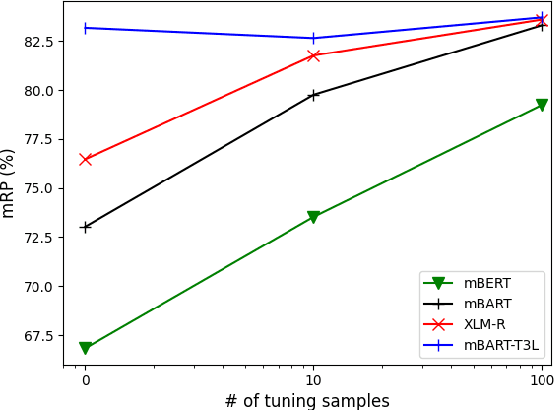
Cross-lingual text classification leverages text classifiers trained in a high-resource language to perform text classification in other languages with no or minimal fine-tuning (zero/few-shots cross-lingual transfer). Nowadays, cross-lingual text classifiers are typically built on large-scale, multilingual language models (LMs) pretrained on a variety of languages of interest. However, the performance of these models vary significantly across languages and classification tasks, suggesting that the superposition of the language modelling and classification tasks is not always effective. For this reason, in this paper we propose revisiting the classic "translate-and-test" pipeline to neatly separate the translation and classification stages. The proposed approach couples 1) a neural machine translator translating from the targeted language to a high-resource language, with 2) a text classifier trained in the high-resource language, but the neural machine translator generates "soft" translations to permit end-to-end backpropagation during fine-tuning of the pipeline. Extensive experiments have been carried out over three cross-lingual text classification datasets (XNLI, MLDoc and MultiEURLEX), with the results showing that the proposed approach has significantly improved performance over a competitive baseline.