 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
On the Audio Hallucinations in Large Audio-Video Language Models
Jan 18, 2024
Large audio-video language models can generate descriptions for both video and audio. However, they sometimes ignore audio content, producing audio descriptions solely reliant on visual information. This paper refers to this as audio hallucinations and analyzes them in large audio-video language models. We gather 1,000 sentences by inquiring about audio information and annotate them whether they contain hallucinations. If a sentence is hallucinated, we also categorize the type of hallucination. The results reveal that 332 sentences are hallucinated with distinct trends observed in nouns and verbs for each hallucination type. Based on this, we tackle a task of audio hallucination classification using pre-trained audio-text models in the zero-shot and fine-tuning settings. Our experimental results reveal that the zero-shot models achieve higher performance (52.2% in F1) than the random (40.3%) and the fine-tuning models achieve 87.9%, outperforming the zero-shot models.
SentinelLMs: Encrypted Input Adaptation and Fine-tuning of Language Models for Private and Secure Inference
Dec 28, 2023This paper addresses the privacy and security concerns associated with deep neural language models, which serve as crucial components in various modern AI-based applications. These models are often used after being pre-trained and fine-tuned for specific tasks, with deployment on servers accessed through the internet. However, this introduces two fundamental risks: (a) the transmission of user inputs to the server via the network gives rise to interception vulnerabilities, and (b) privacy concerns emerge as organizations that deploy such models store user data with restricted context. To address this, we propose a novel method to adapt and fine-tune transformer-based language models on passkey-encrypted user-specific text. The original pre-trained language model first undergoes a quick adaptation (without any further pre-training) with a series of irreversible transformations applied to the tokenizer and token embeddings. This enables the model to perform inference on encrypted inputs while preventing reverse engineering of text from model parameters and intermediate outputs. After adaptation, models are fine-tuned on encrypted versions of existing training datasets. Experimental evaluation employing adapted versions of renowned models (e.g., BERT, RoBERTa) across established benchmark English and multilingual datasets for text classification and sequence labeling shows that encrypted models achieve performance parity with their original counterparts. This serves to safeguard performance, privacy, and security cohesively.
Text2Tree: Aligning Text Representation to the Label Tree Hierarchy for Imbalanced Medical Classification
Nov 28, 2023Deep learning approaches exhibit promising performances on various text tasks. However, they are still struggling on medical text classification since samples are often extremely imbalanced and scarce. Different from existing mainstream approaches that focus on supplementary semantics with external medical information, this paper aims to rethink the data challenges in medical texts and present a novel framework-agnostic algorithm called Text2Tree that only utilizes internal label hierarchy in training deep learning models. We embed the ICD code tree structure of labels into cascade attention modules for learning hierarchy-aware label representations. Two new learning schemes, Similarity Surrogate Learning (SSL) and Dissimilarity Mixup Learning (DML), are devised to boost text classification by reusing and distinguishing samples of other labels following the label representation hierarchy, respectively. Experiments on authoritative public datasets and real-world medical records show that our approach stably achieves superior performances over classical and advanced imbalanced classification methods.
Reliability Analysis of Psychological Concept Extraction and Classification in User-penned Text
Jan 12, 2024The social NLP research community witness a recent surge in the computational advancements of mental health analysis to build responsible AI models for a complex interplay between language use and self-perception. Such responsible AI models aid in quantifying the psychological concepts from user-penned texts on social media. On thinking beyond the low-level (classification) task, we advance the existing binary classification dataset, towards a higher-level task of reliability analysis through the lens of explanations, posing it as one of the safety measures. We annotate the LoST dataset to capture nuanced textual cues that suggest the presence of low self-esteem in the posts of Reddit users. We further state that the NLP models developed for determining the presence of low self-esteem, focus more on three types of textual cues: (i) Trigger: words that triggers mental disturbance, (ii) LoST indicators: text indicators emphasizing low self-esteem, and (iii) Consequences: words describing the consequences of mental disturbance. We implement existing classifiers to examine the attention mechanism in pre-trained language models (PLMs) for a domain-specific psychology-grounded task. Our findings suggest the need of shifting the focus of PLMs from Trigger and Consequences to a more comprehensive explanation, emphasizing LoST indicators while determining low self-esteem in Reddit posts.
CrisisKAN: Knowledge-infused and Explainable Multimodal Attention Network for Crisis Event Classification
Jan 11, 2024Pervasive use of social media has become the emerging source for real-time information (like images, text, or both) to identify various events. Despite the rapid growth of image and text-based event classification, the state-of-the-art (SOTA) models find it challenging to bridge the semantic gap between features of image and text modalities due to inconsistent encoding. Also, the black-box nature of models fails to explain the model's outcomes for building trust in high-stakes situations such as disasters, pandemic. Additionally, the word limit imposed on social media posts can potentially introduce bias towards specific events. To address these issues, we proposed CrisisKAN, a novel Knowledge-infused and Explainable Multimodal Attention Network that entails images and texts in conjunction with external knowledge from Wikipedia to classify crisis events. To enrich the context-specific understanding of textual information, we integrated Wikipedia knowledge using proposed wiki extraction algorithm. Along with this, a guided cross-attention module is implemented to fill the semantic gap in integrating visual and textual data. In order to ensure reliability, we employ a model-specific approach called Gradient-weighted Class Activation Mapping (Grad-CAM) that provides a robust explanation of the predictions of the proposed model. The comprehensive experiments conducted on the CrisisMMD dataset yield in-depth analysis across various crisis-specific tasks and settings. As a result, CrisisKAN outperforms existing SOTA methodologies and provides a novel view in the domain of explainable multimodal event classification.
Breaking the Token Barrier: Chunking and Convolution for Efficient Long Text Classification with BERT
Oct 31, 2023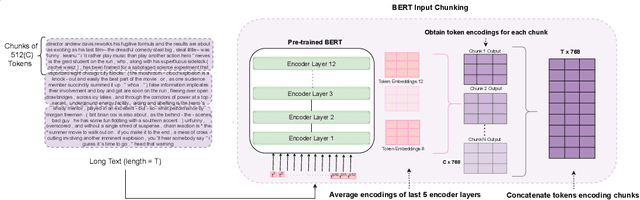
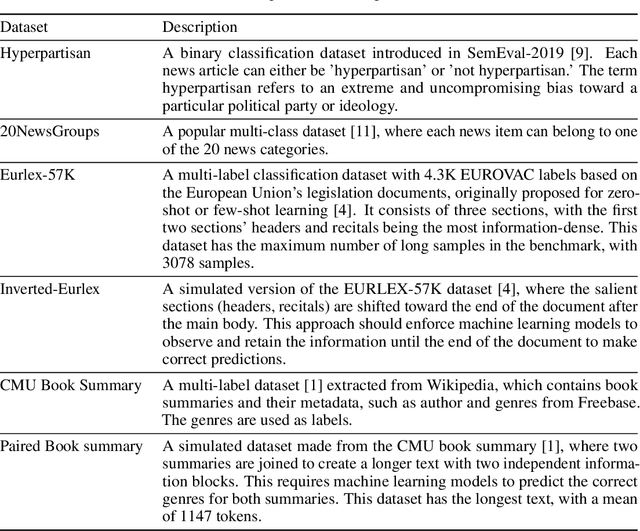
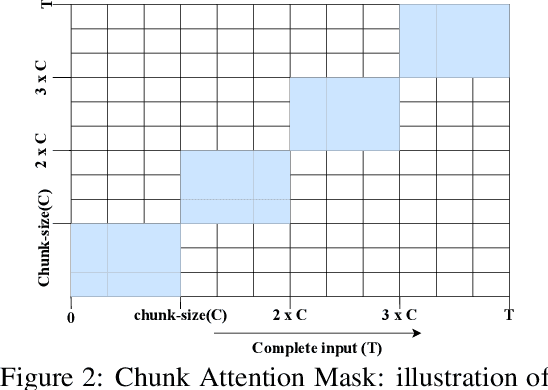
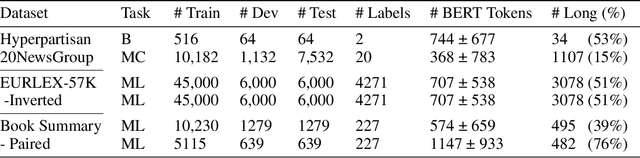
Transformer-based models, specifically BERT, have propelled research in various NLP tasks. However, these models are limited to a maximum token limit of 512 tokens. Consequently, this makes it non-trivial to apply it in a practical setting with long input. Various complex methods have claimed to overcome this limit, but recent research questions the efficacy of these models across different classification tasks. These complex architectures evaluated on carefully curated long datasets perform at par or worse than simple baselines. In this work, we propose a relatively simple extension to vanilla BERT architecture called ChunkBERT that allows finetuning of any pretrained models to perform inference on arbitrarily long text. The proposed method is based on chunking token representations and CNN layers, making it compatible with any pre-trained BERT. We evaluate chunkBERT exclusively on a benchmark for comparing long-text classification models across a variety of tasks (including binary classification, multi-class classification, and multi-label classification). A BERT model finetuned using the ChunkBERT method performs consistently across long samples in the benchmark while utilizing only a fraction (6.25\%) of the original memory footprint. These findings suggest that efficient finetuning and inference can be achieved through simple modifications to pre-trained BERT models.
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Jan 15, 2024The exponential growth of large language models (LLMs) has opened up numerous possibilities for multimodal AGI systems. However, the progress in vision and vision-language foundation models, which are also critical elements of multi-modal AGI, has not kept pace with LLMs. In this work, we design a large-scale vision-language foundation model (InternVL), which scales up the vision foundation model to 6 billion parameters and progressively aligns it with the LLM, using web-scale image-text data from various sources. This model can be broadly applied to and achieve state-of-the-art performance on 32 generic visual-linguistic benchmarks including visual perception tasks such as image-level or pixel-level recognition, vision-language tasks such as zero-shot image/video classification, zero-shot image/video-text retrieval, and link with LLMs to create multi-modal dialogue systems. It has powerful visual capabilities and can be a good alternative to the ViT-22B. We hope that our research could contribute to the development of multi-modal large models. Code and models are available at https://github.com/OpenGVLab/InternVL.
Object Recognition from Scientific Document based on Compartment Refinement Framework
Dec 15, 2023With the rapid development of the internet in the past decade, it has become increasingly important to extract valuable information from vast resources efficiently, which is crucial for establishing a comprehensive digital ecosystem, particularly in the context of research surveys and comprehension. The foundation of these tasks focuses on accurate extraction and deep mining of data from scientific documents, which are essential for building a robust data infrastructure. However, parsing raw data or extracting data from complex scientific documents have been ongoing challenges. Current data extraction methods for scientific documents typically use rule-based (RB) or machine learning (ML) approaches. However, using rule-based methods can incur high coding costs for articles with intricate typesetting. Conversely, relying solely on machine learning methods necessitates annotation work for complex content types within the scientific document, which can be costly. Additionally, few studies have thoroughly defined and explored the hierarchical layout within scientific documents. The lack of a comprehensive definition of the internal structure and elements of the documents indirectly impacts the accuracy of text classification and object recognition tasks. From the perspective of analyzing the standard layout and typesetting used in the specified publication, we propose a new document layout analysis framework called CTBR(Compartment & Text Blocks Refinement). Firstly, we define scientific documents into hierarchical divisions: base domain, compartment, and text blocks. Next, we conduct an in-depth exploration and classification of the meanings of text blocks. Finally, we utilize the results of text block classification to implement object recognition within scientific documents based on rule-based compartment segmentation.
Sparsify-then-Classify: From Internal Neurons of Large Language Models To Efficient Text Classifiers
Nov 27, 2023Among the many tasks that Large Language Models (LLMs) have revolutionized is text classification. However, existing approaches for applying pretrained LLMs to text classification predominantly rely on using single token outputs from only the last layer of hidden states. As a result, they suffer from limitations in efficiency, task-specificity, and interpretability. In our work, we contribute an approach that uses all internal representations by employing multiple pooling strategies on all activation and hidden states. Our novel lightweight strategy, Sparsify-then-Classify (STC) first sparsifies task-specific features layer-by-layer, then aggregates across layers for text classification. STC can be applied as a seamless plug-and-play module on top of existing LLMs. Our experiments on a comprehensive set of models and datasets demonstrate that STC not only consistently improves the classification performance of pretrained and fine-tuned models, but is also more efficient for both training and inference, and is more intrinsically interpretable.
Self-supervised speech representation and contextual text embedding for match-mismatch classification with EEG recording
Jan 10, 2024Relating speech to EEG holds considerable importance but challenging. In this study, deep convolutional network was employed to extract spatiotemporal features from EEG data. Self-supervised speech representation and contextual text embedding were used as speech features. Contrastive learning was used to related EEG features to speech features. The experimental results demonstrate the benefits of using self-supervised speech representation and contextual text embedding. Through feature fusion and model ensemble, an accuracy of 60.29% was achieved, and the performance was ranked as No.2 in Task1 of the Auditory EEG Challenge (ICASSP 2024).