 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Uzbek Sentiment Analysis based on local Restaurant Reviews
May 31, 2022
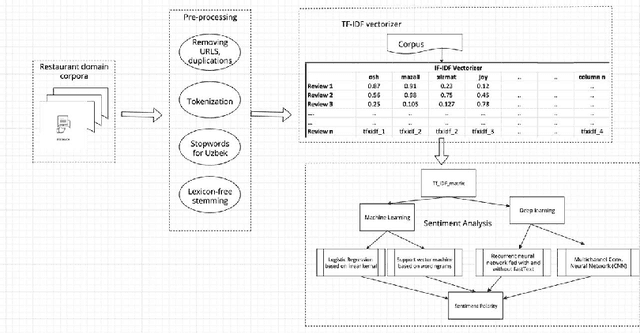

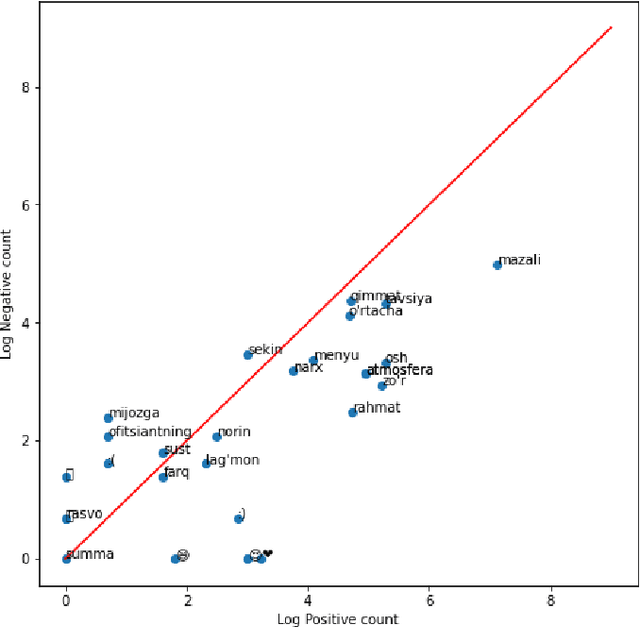
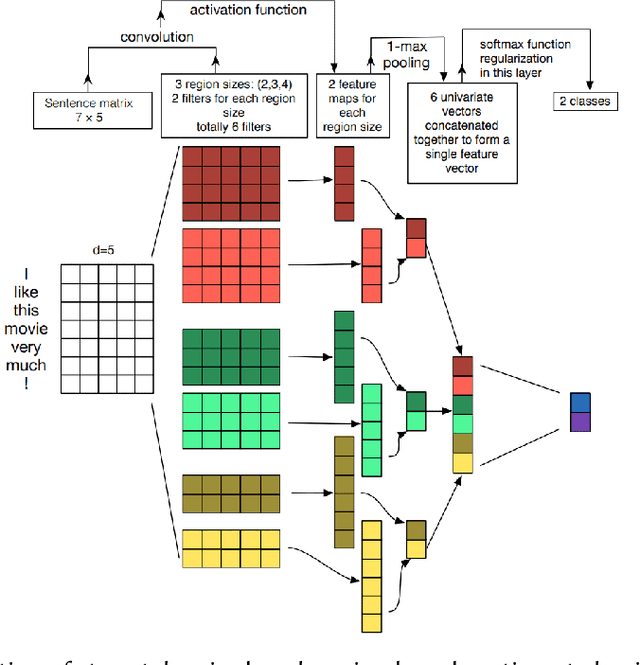
Extracting useful information for sentiment analysis and classification problems from a big amount of user-generated feedback, such as restaurant reviews, is a crucial task of natural language processing, which is not only for customer satisfaction where it can give personalized services, but can also influence the further development of a company. In this paper, we present a work done on collecting restaurant reviews data as a sentiment analysis dataset for the Uzbek language, a member of the Turkic family which is heavily affected by the low-resource constraint, and provide some further analysis of the novel dataset by evaluation using different techniques, from logistic regression based models, to support vector machines, and even deep learning models, such as recurrent neural networks, as well as convolutional neural networks. The paper includes detailed information on how the data was collected, how it was pre-processed for better quality optimization, as well as experimental setups for the evaluation process. The overall evaluation results indicate that by performing pre-processing steps, such as stemming for agglutinative languages, the system yields better results, eventually achieving 91% accuracy result in the best performing model
Contrasting the efficiency of stock price prediction models using various types of LSTM models aided with sentiment analysis
Jul 15, 2023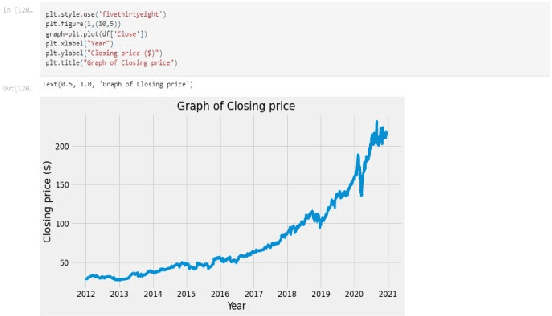
Our research aims to find the best model that uses companies projections and sector performances and how the given company fares accordingly to correctly predict equity share prices for both short and long term goals.
UMLS-KGI-BERT: Data-Centric Knowledge Integration in Transformers for Biomedical Entity Recognition
Jul 20, 2023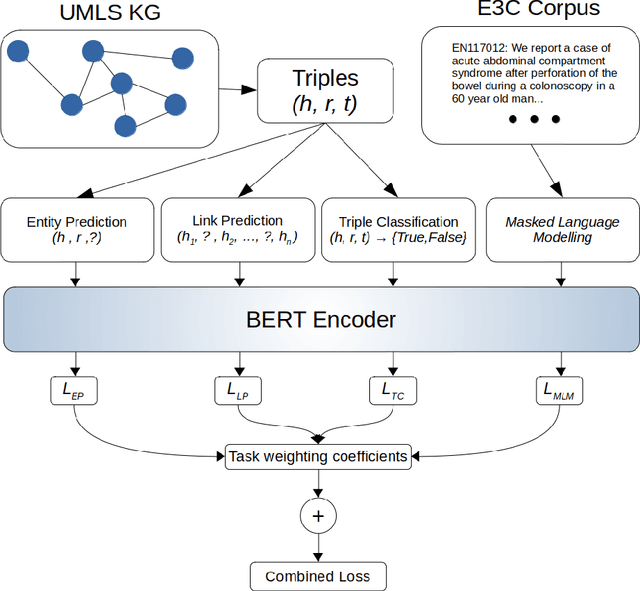


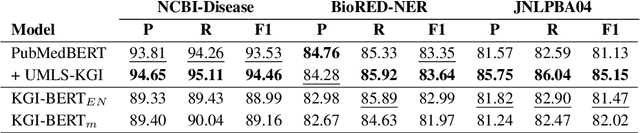
Pre-trained transformer language models (LMs) have in recent years become the dominant paradigm in applied NLP. These models have achieved state-of-the-art performance on tasks such as information extraction, question answering, sentiment analysis, document classification and many others. In the biomedical domain, significant progress has been made in adapting this paradigm to NLP tasks that require the integration of domain-specific knowledge as well as statistical modelling of language. In particular, research in this area has focused on the question of how best to construct LMs that take into account not only the patterns of token distribution in medical text, but also the wealth of structured information contained in terminology resources such as the UMLS. This work contributes a data-centric paradigm for enriching the language representations of biomedical transformer-encoder LMs by extracting text sequences from the UMLS. This allows for graph-based learning objectives to be combined with masked-language pre-training. Preliminary results from experiments in the extension of pre-trained LMs as well as training from scratch show that this framework improves downstream performance on multiple biomedical and clinical Named Entity Recognition (NER) tasks.
A Case Study of Chinese Sentiment Analysis on Social Media Reviews Based on LSTM
Oct 31, 2022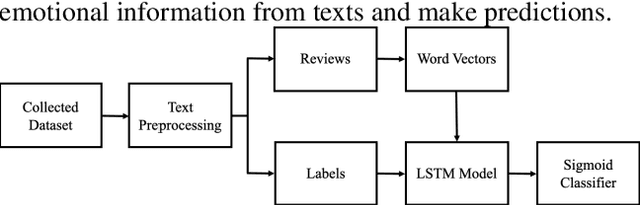
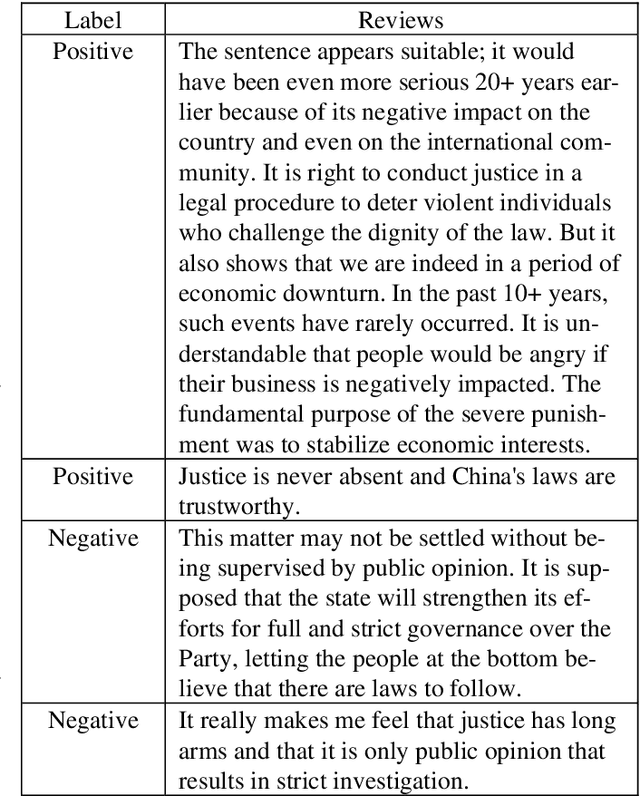
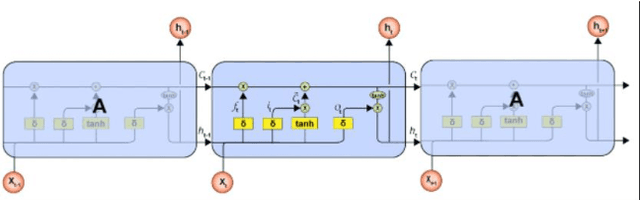

Network public opinion analysis is obtained by a combination of natural language processing (NLP) and public opinion supervision, and is crucial for monitoring public mood and trends. Therefore, network public opinion analysis can identify and solve potential and budding social problems. This study aims to realize an analysis of Chinese sentiment in social media reviews using a long short-term memory network (LSTM) model. The dataset was obtained from Sina Weibo using a web crawler and was cleaned with Pandas. First, Chinese comments regarding the legal sentencing in of Tangshan attack and Jiang Ge Case were segmented and vectorized. Then, a binary LSTM model was trained and tested. Finally, sentiment analysis results were obtained by analyzing the comments with the LSTM model. The accuracy of the proposed model has reached approximately 92%.
Extending the Forward Forward Algorithm
Jul 09, 2023

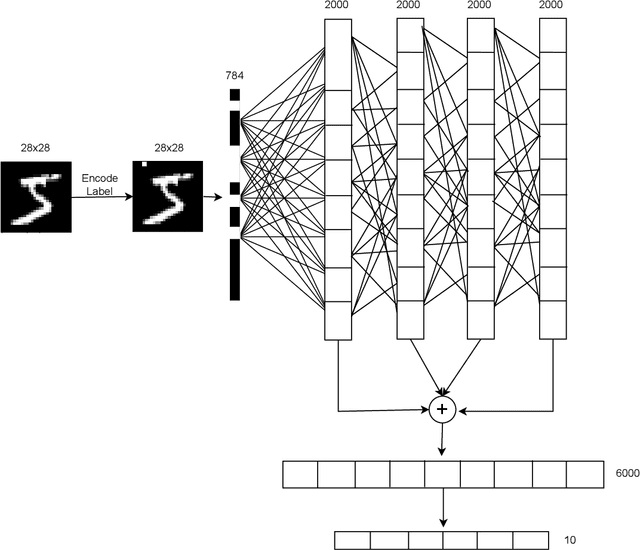

The Forward Forward algorithm, proposed by Geoffrey Hinton in November 2022, is a novel method for training neural networks as an alternative to backpropagation. In this project, we replicate Hinton's experiments on the MNIST dataset, and subsequently extend the scope of the method with two significant contributions. First, we establish a baseline performance for the Forward Forward network on the IMDb movie reviews dataset. As far as we know, our results on this sentiment analysis task marks the first instance of the algorithm's extension beyond computer vision. Second, we introduce a novel pyramidal optimization strategy for the loss threshold - a hyperparameter specific to the Forward Forward method. Our pyramidal approach shows that a good thresholding strategy causes a difference of upto 8% in test error. 1 Lastly, we perform visualizations of the trained parameters and derived several significant insights, such as a notably larger (10-20x) mean and variance in the weights acquired by the Forward Forward network.
Leveraging Language Identification to Enhance Code-Mixed Text Classification
Jun 08, 2023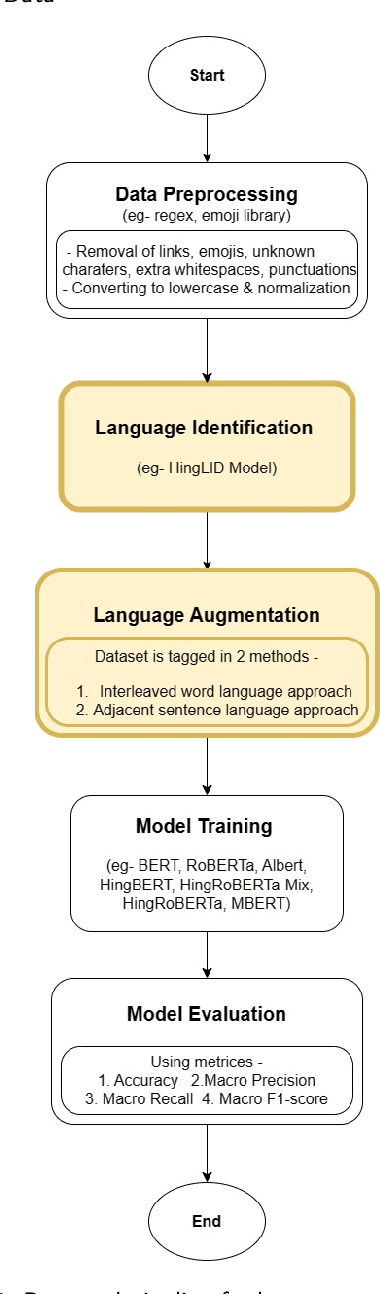
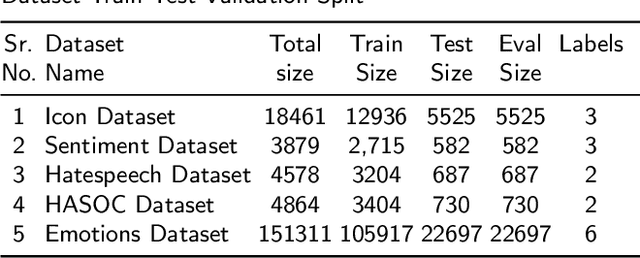
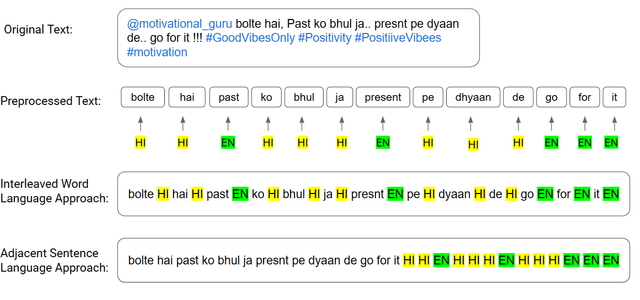
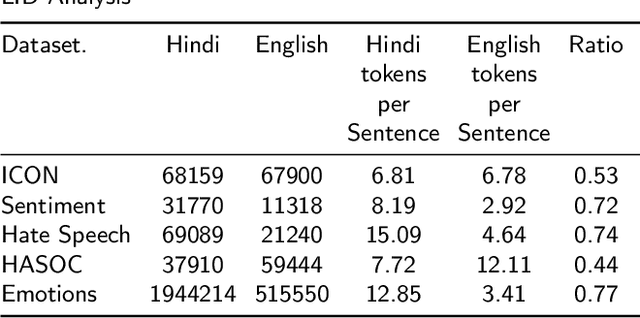
The usage of more than one language in the same text is referred to as Code Mixed. It is evident that there is a growing degree of adaption of the use of code-mixed data, especially English with a regional language, on social media platforms. Existing deep-learning models do not take advantage of the implicit language information in the code-mixed text. Our study aims to improve BERT-based models performance on low-resource Code-Mixed Hindi-English Datasets by experimenting with language augmentation approaches. We propose a pipeline to improve code-mixed systems that comprise data preprocessing, word-level language identification, language augmentation, and model training on downstream tasks like sentiment analysis. For language augmentation in BERT models, we explore word-level interleaving and post-sentence placement of language information. We have examined the performance of vanilla BERT-based models and their code-mixed HingBERT counterparts on respective benchmark datasets, comparing their results with and without using word-level language information. The models were evaluated using metrics such as accuracy, precision, recall, and F1 score. Our findings show that the proposed language augmentation approaches work well across different BERT models. We demonstrate the importance of augmenting code-mixed text with language information on five different code-mixed Hindi-English downstream datasets based on sentiment analysis, hate speech detection, and emotion detection.
Is ChatGPT a Good Personality Recognizer? A Preliminary Study
Jul 26, 2023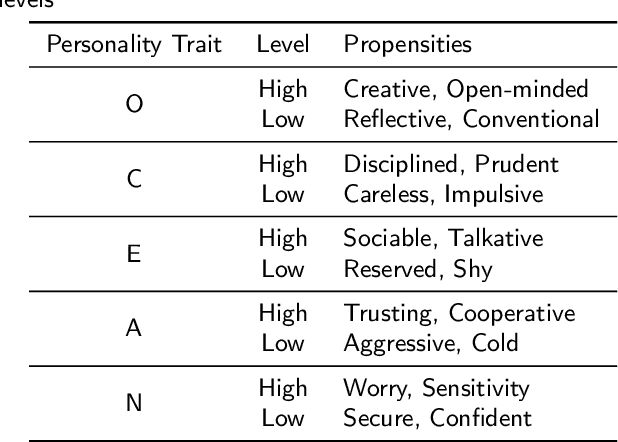
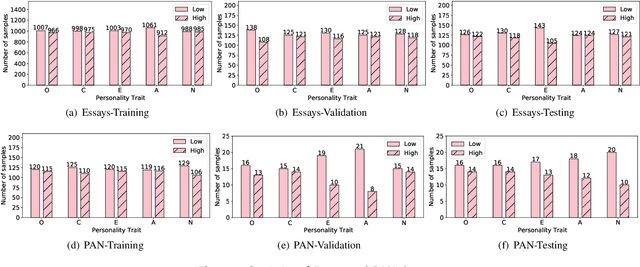
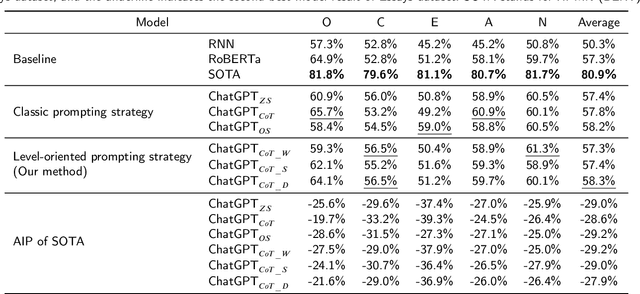

In recent years, personality has been regarded as a valuable personal factor being incorporated into numerous tasks such as sentiment analysis and product recommendation. This has led to widespread attention to text-based personality recognition task, which aims to identify an individual's personality based on given text. Considering that ChatGPT has recently exhibited remarkable abilities on various natural language processing tasks, we provide a preliminary evaluation of ChatGPT on text-based personality recognition task for generating effective personality data. Concretely, we employ a variety of prompting strategies to explore ChatGPT's ability in recognizing personality from given text, especially the level-oriented prompting strategy we designed for guiding ChatGPT in analyzing given text at a specified level. The experimental results on two representative real-world datasets reveal that ChatGPT with zero-shot chain-of-thought prompting exhibits impressive personality recognition ability and is capable to provide natural language explanations through text-based logical reasoning. Furthermore, by employing the level-oriented prompting strategy to optimize zero-shot chain-of-thought prompting, the performance gap between ChatGPT and corresponding state-of-the-art model has been narrowed even more. However, we observe that ChatGPT shows unfairness towards certain sensitive demographic attributes such as gender and age. Additionally, we discover that eliciting the personality recognition ability of ChatGPT helps improve its performance on personality-related downstream tasks such as sentiment classification and stress prediction.
Generative Aspect-Based Sentiment Analysis with Contrastive Learning and Expressive Structure
Nov 14, 2022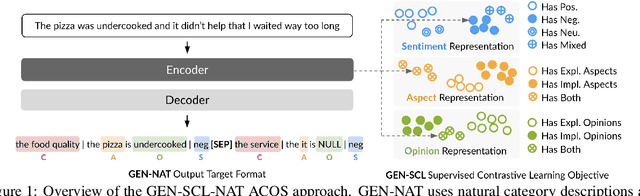
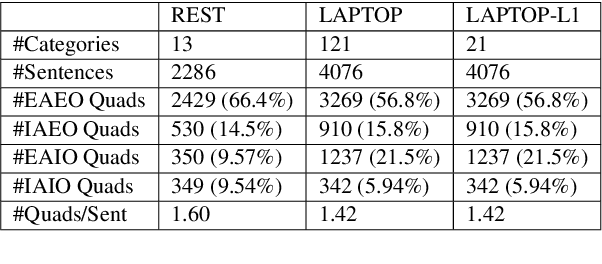
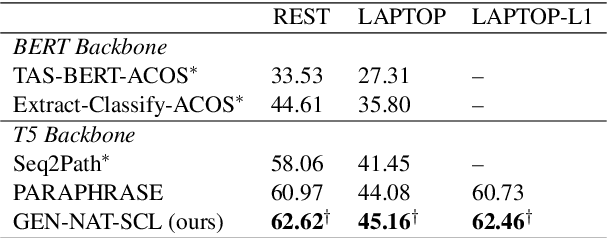
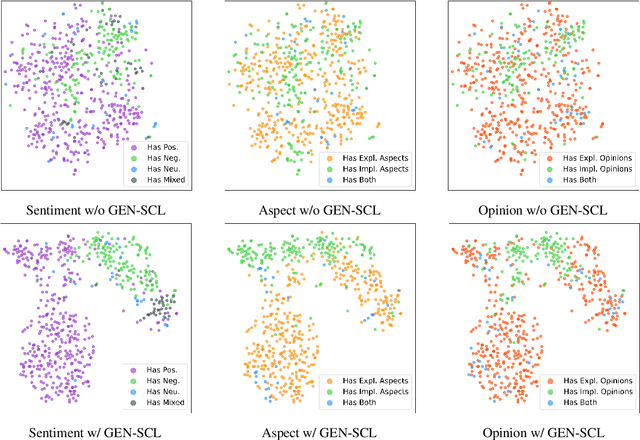
Generative models have demonstrated impressive results on Aspect-based Sentiment Analysis (ABSA) tasks, particularly for the emerging task of extracting Aspect-Category-Opinion-Sentiment (ACOS) quadruples. However, these models struggle with implicit sentiment expressions, which are commonly observed in opinionated content such as online reviews. In this work, we introduce GEN-SCL-NAT, which consists of two techniques for improved structured generation for ACOS quadruple extraction. First, we propose GEN-SCL, a supervised contrastive learning objective that aids quadruple prediction by encouraging the model to produce input representations that are discriminable across key input attributes, such as sentiment polarity and the existence of implicit opinions and aspects. Second, we introduce GEN-NAT, a new structured generation format that better adapts autoregressive encoder-decoder models to extract quadruples in a generative fashion. Experimental results show that GEN-SCL-NAT achieves top performance across three ACOS datasets, averaging 1.48% F1 improvement, with a maximum 1.73% increase on the LAPTOP-L1 dataset. Additionally, we see significant gains on implicit aspect and opinion splits that have been shown as challenging for existing ACOS approaches.
UIO at SemEval-2023 Task 12: Multilingual fine-tuning for sentiment classification in low-resource languages
Apr 27, 2023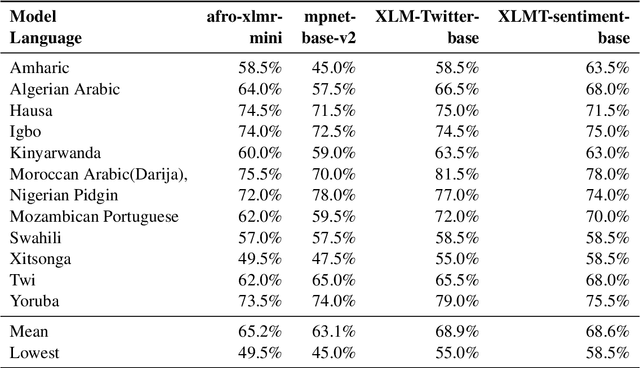
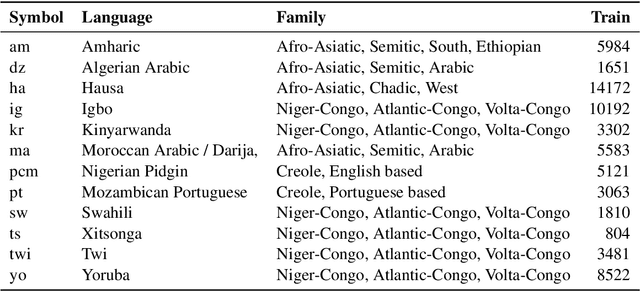
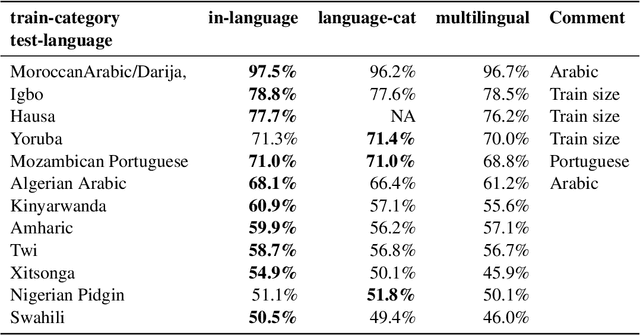
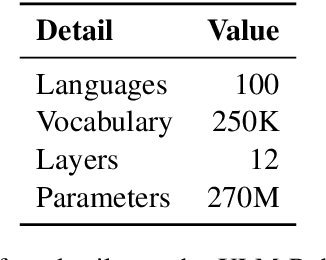
Our contribution to the 2023 AfriSenti-SemEval shared task 12: Sentiment Analysis for African Languages, provides insight into how a multilingual large language model can be a resource for sentiment analysis in languages not seen during pretraining. The shared task provides datasets of a variety of African languages from different language families. The languages are to various degrees related to languages used during pretraining, and the language data contain various degrees of code-switching. We experiment with both monolingual and multilingual datasets for the final fine-tuning, and find that with the provided datasets that contain samples in the thousands, monolingual fine-tuning yields the best results.
Proactive Detractor Detection Framework Based on Message-Wise Sentiment Analysis Over Customer Support Interactions
Nov 08, 2022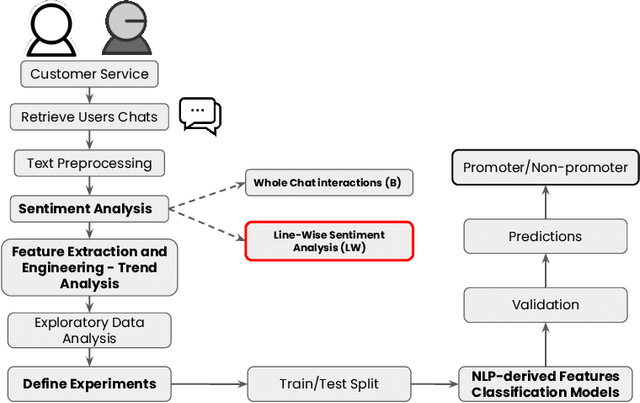
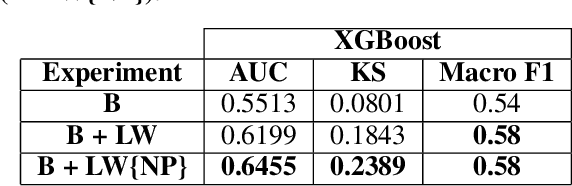
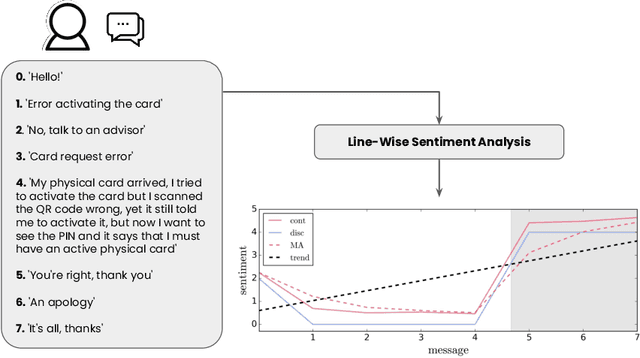
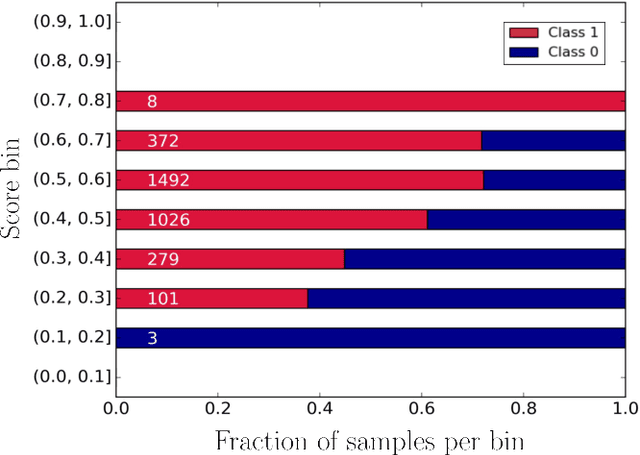
In this work, we propose a framework relying solely on chat-based customer support (CS) interactions for predicting the recommendation decision of individual users. For our case study, we analyzed a total number of 16.4k users and 48.7k customer support conversations within the financial vertical of a large e-commerce company in Latin America. Consequently, our main contributions and objectives are to use Natural Language Processing (NLP) to assess and predict the recommendation behavior where, in addition to using static sentiment analysis, we exploit the predictive power of each user's sentiment dynamics. Our results show that, with respective feature interpretability, it is possible to predict the likelihood of a user to recommend a product or service, based solely on the message-wise sentiment evolution of their CS conversations in a fully automated way.