 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Painsight: An Extendable Opinion Mining Framework for Detecting Pain Points Based on Online Customer Reviews
Jun 03, 2023
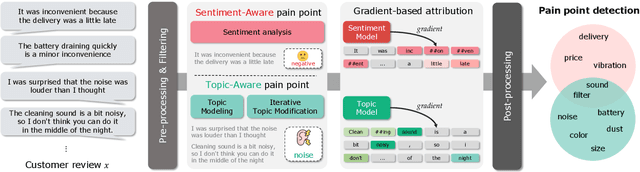
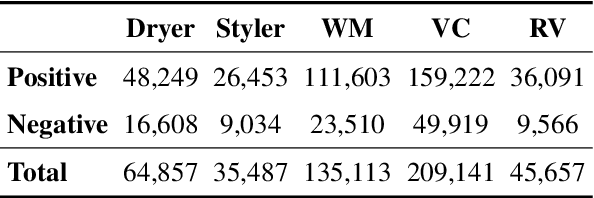
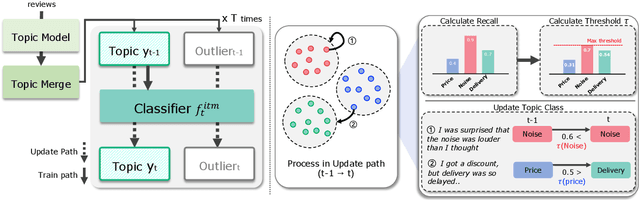
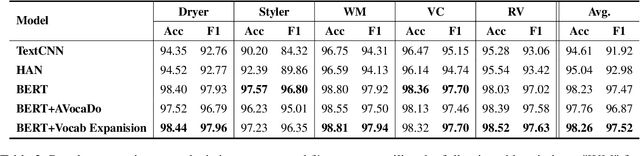
As the e-commerce market continues to expand and online transactions proliferate, customer reviews have emerged as a critical element in shaping the purchasing decisions of prospective buyers. Previous studies have endeavored to identify key aspects of customer reviews through the development of sentiment analysis models and topic models. However, extracting specific dissatisfaction factors remains a challenging task. In this study, we delineate the pain point detection problem and propose Painsight, an unsupervised framework for automatically extracting distinct dissatisfaction factors from customer reviews without relying on ground truth labels. Painsight employs pre-trained language models to construct sentiment analysis and topic models, leveraging attribution scores derived from model gradients to extract dissatisfaction factors. Upon application of the proposed methodology to customer review data spanning five product categories, we successfully identified and categorized dissatisfaction factors within each group, as well as isolated factors for each type. Notably, Painsight outperformed benchmark methods, achieving substantial performance enhancements and exceptional results in human evaluations.
Abstractive Summarization of Large Document Collections Using GPT
Oct 09, 2023This paper proposes a method of abstractive summarization designed to scale to document collections instead of individual documents. Our approach applies a combination of semantic clustering, document size reduction within topic clusters, semantic chunking of a cluster's documents, GPT-based summarization and concatenation, and a combined sentiment and text visualization of each topic to support exploratory data analysis. Statistical comparison of our results to existing state-of-the-art systems BART, BRIO, PEGASUS, and MoCa using ROGUE summary scores showed statistically equivalent performance with BART and PEGASUS on the CNN/Daily Mail test dataset, and with BART on the Gigaword test dataset. This finding is promising since we view document collection summarization as more challenging than individual document summarization. We conclude with a discussion of how issues of scale are
Zero-Shot Aspect-Based Sentiment Analysis
Feb 15, 2022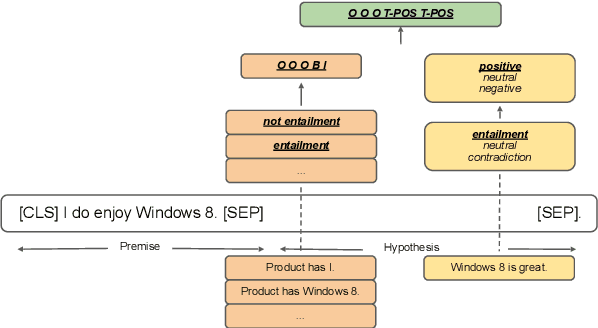


Aspect-based sentiment analysis (ABSA) typically requires in-domain annotated data for supervised training/fine-tuning. It is a big challenge to scale ABSA to a large number of new domains. This paper aims to train a unified model that can perform zero-shot ABSA without using any annotated data for a new domain. We propose a method called contrastive post-training on review Natural Language Inference (CORN). Later ABSA tasks can be cast into NLI for zero-shot transfer. We evaluate CORN on ABSA tasks, ranging from aspect extraction (AE), aspect sentiment classification (ASC), to end-to-end aspect-based sentiment analysis (E2E ABSA), which show ABSA can be conducted without any human annotated ABSA data.
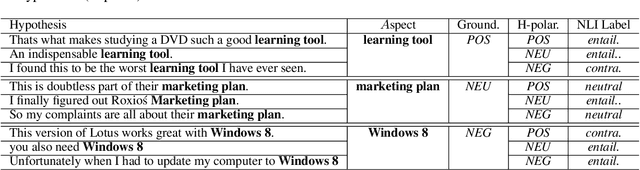
Reasoning Implicit Sentiment with Chain-of-Thought Prompting
May 25, 2023
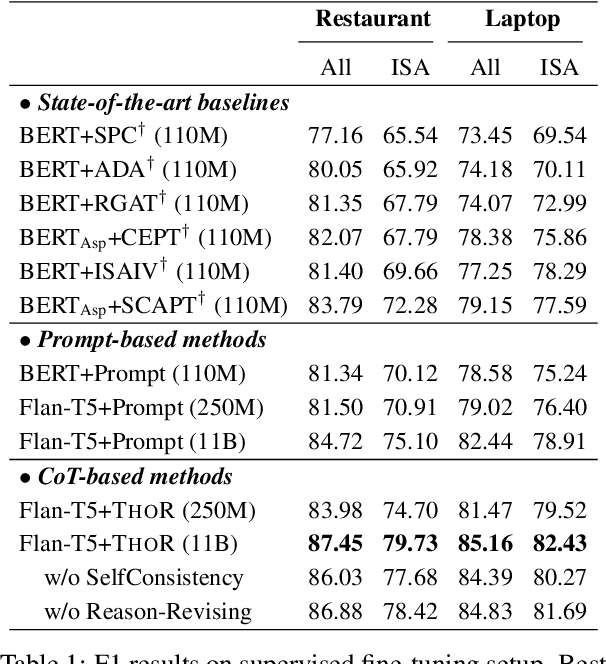

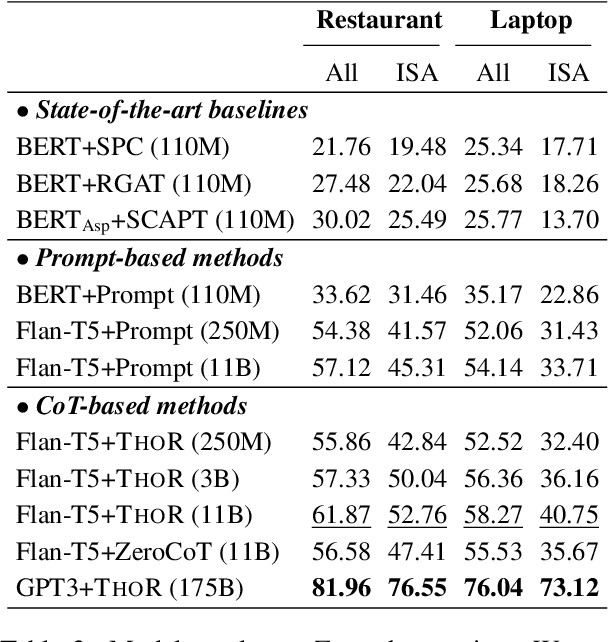
While sentiment analysis systems try to determine the sentiment polarities of given targets based on the key opinion expressions in input texts, in implicit sentiment analysis (ISA) the opinion cues come in an implicit and obscure manner. Thus detecting implicit sentiment requires the common-sense and multi-hop reasoning ability to infer the latent intent of opinion. Inspired by the recent chain-of-thought (CoT) idea, in this work we introduce a Three-hop Reasoning (THOR) CoT framework to mimic the human-like reasoning process for ISA. We design a three-step prompting principle for THOR to step-by-step induce the implicit aspect, opinion, and finally the sentiment polarity. Our THOR+Flan-T5 (11B) pushes the state-of-the-art (SoTA) by over 6% F1 on supervised setup. More strikingly, THOR+GPT3 (175B) boosts the SoTA by over 50% F1 on zero-shot setting. Our code is at https://github.com/scofield7419/THOR-ISA.
Emoji Prediction using Transformer Models
Jul 05, 2023
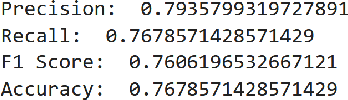
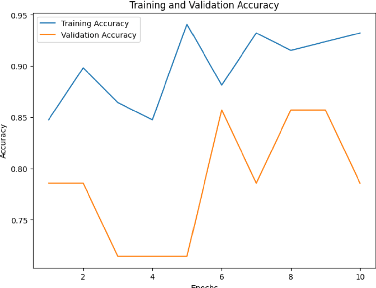
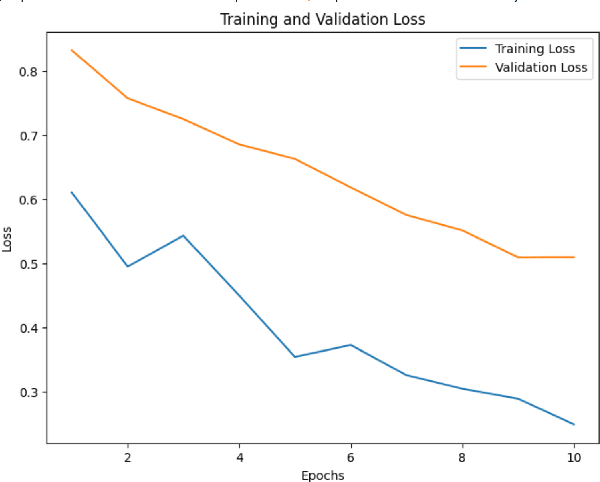
In recent years, the use of emojis in social media has increased dramatically, making them an important element in understanding online communication. However, predicting the meaning of emojis in a given text is a challenging task due to their ambiguous nature. In this study, we propose a transformer-based approach for emoji prediction using BERT, a widely-used pre-trained language model. We fine-tuned BERT on a large corpus of text containing both text and emojis to predict the most appropriate emoji for a given text. Our experimental results demonstrate that our approach outperforms several state-of-the-art models in predicting emojis with an accuracy of over 75 \% This work has potential applications in natural language processing, sentiment analysis, and social media marketing.
Opinion mining using Double Channel CNN for Recommender System
Jul 15, 2023
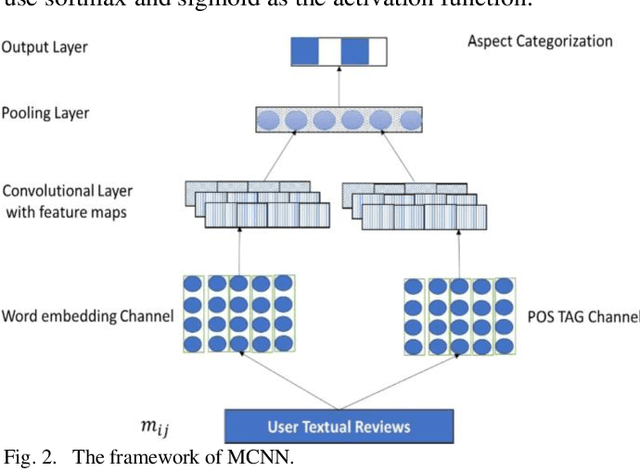
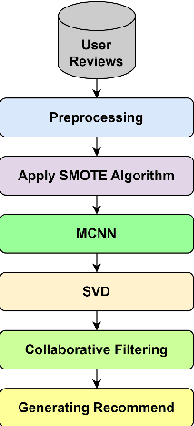
Much unstructured data has been produced with the growth of the Internet and social media. A significant volume of textual data includes users' opinions about products in online stores and social media. By exploring and categorizing them, helpful information can be acquired, including customer satisfaction, user feedback about a particular event, predicting the sale of a specific product, and other similar cases. In this paper, we present an approach for sentiment analysis with a deep learning model and use it to recommend products. A two-channel convolutional neural network model has been used for opinion mining, which has five layers and extracts essential features from the data. We increased the number of comments by applying the SMOTE algorithm to the initial dataset and balanced the data. Then we proceed to cluster the aspects. We also assign a weight to each cluster using tensor decomposition algorithms that improve the recommender system's performance. Our proposed method has reached 91.6% accuracy, significantly improved compared to previous aspect-based approaches.
Extending the Forward Forward Algorithm
Jul 14, 2023

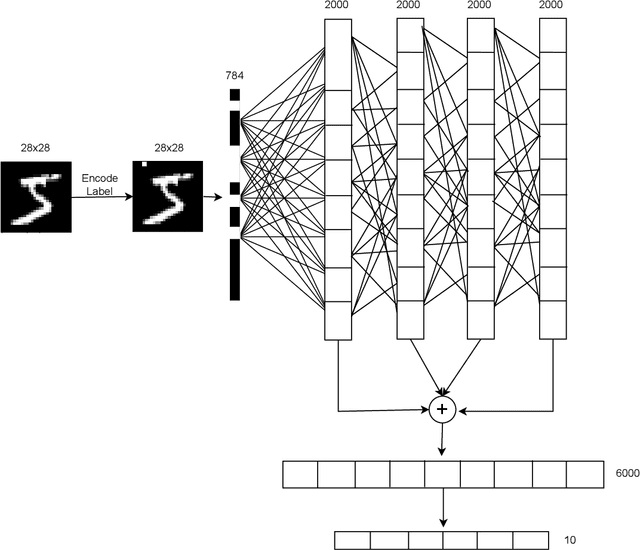

The Forward Forward algorithm, proposed by Geoffrey Hinton in November 2022, is a novel method for training neural networks as an alternative to backpropagation. In this project, we replicate Hinton's experiments on the MNIST dataset, and subsequently extend the scope of the method with two significant contributions. First, we establish a baseline performance for the Forward Forward network on the IMDb movie reviews dataset. As far as we know, our results on this sentiment analysis task marks the first instance of the algorithm's extension beyond computer vision. Second, we introduce a novel pyramidal optimization strategy for the loss threshold - a hyperparameter specific to the Forward Forward method. Our pyramidal approach shows that a good thresholding strategy causes a difference of up to 8% in test error. Lastly, we perform visualizations of the trained parameters and derived several significant insights, such as a notably larger (10-20x) mean and variance in the weights acquired by the Forward Forward network. Repository: https://github.com/Ads-cmu/ForwardForward
A Knowledge-Enhanced Adversarial Model for Cross-lingual Structured Sentiment Analysis
May 31, 2022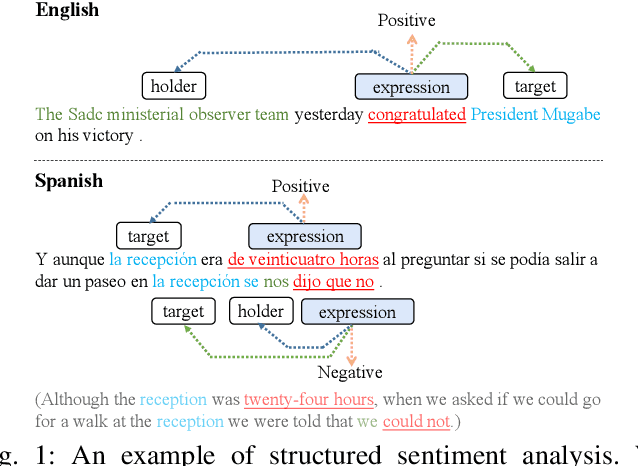
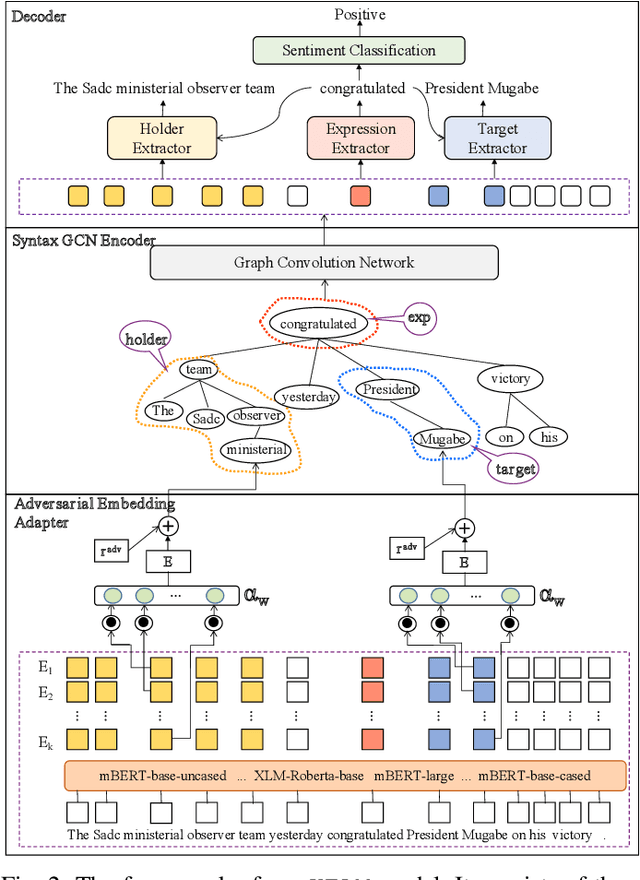
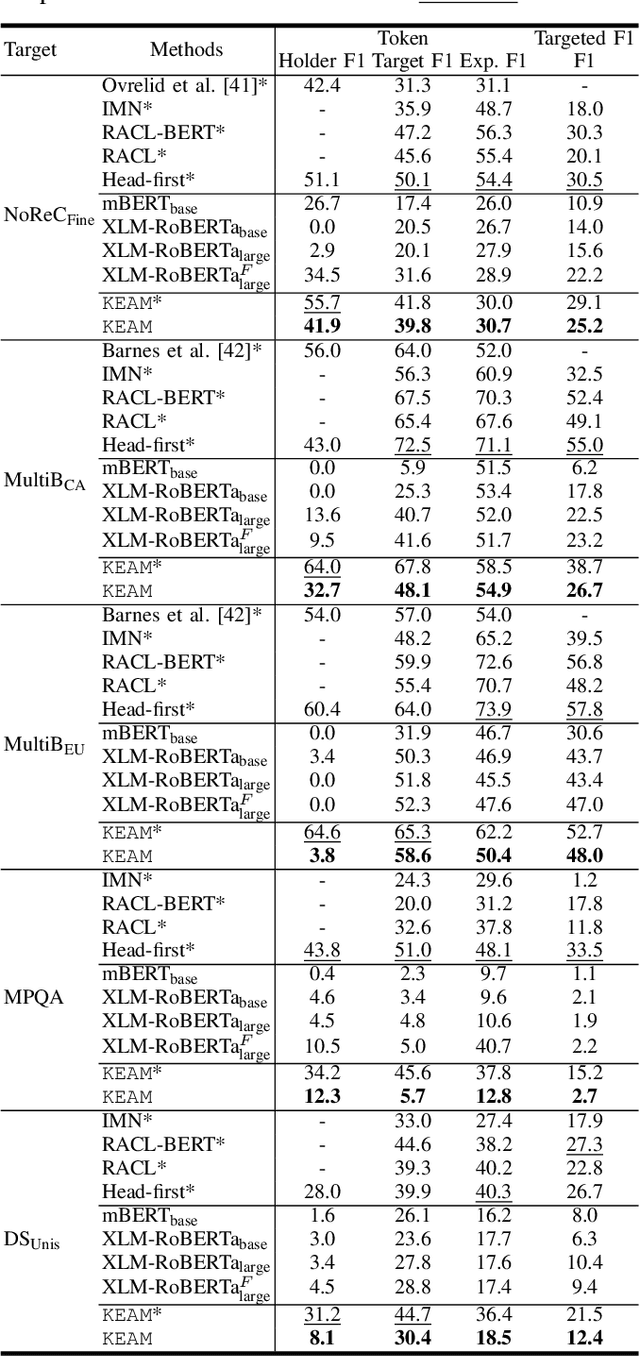
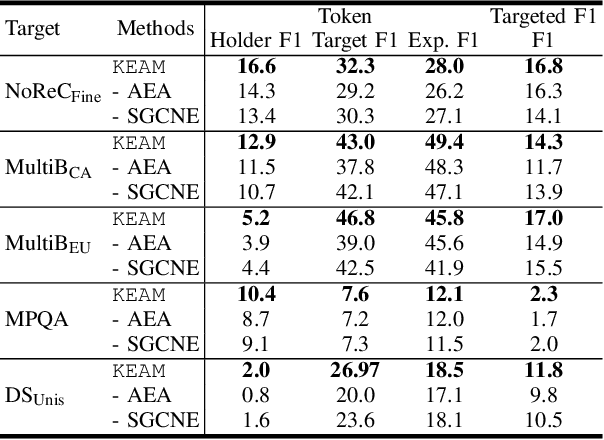
Structured sentiment analysis, which aims to extract the complex semantic structures such as holders, expressions, targets, and polarities, has obtained widespread attention from both industry and academia. Unfortunately, the existing structured sentiment analysis datasets refer to a few languages and are relatively small, limiting neural network models' performance. In this paper, we focus on the cross-lingual structured sentiment analysis task, which aims to transfer the knowledge from the source language to the target one. Notably, we propose a Knowledge-Enhanced Adversarial Model (\texttt{KEAM}) with both implicit distributed and explicit structural knowledge to enhance the cross-lingual transfer. First, we design an adversarial embedding adapter for learning an informative and robust representation by capturing implicit semantic information from diverse multi-lingual embeddings adaptively. Then, we propose a syntax GCN encoder to transfer the explicit semantic information (e.g., universal dependency tree) among multiple languages. We conduct experiments on five datasets and compare \texttt{KEAM} with both the supervised and unsupervised methods. The extensive experimental results show that our \texttt{KEAM} model outperforms all the unsupervised baselines in various metrics.
A Quantum Probability Driven Framework for Joint Multi-Modal Sarcasm, Sentiment and Emotion Analysis
Jun 06, 2023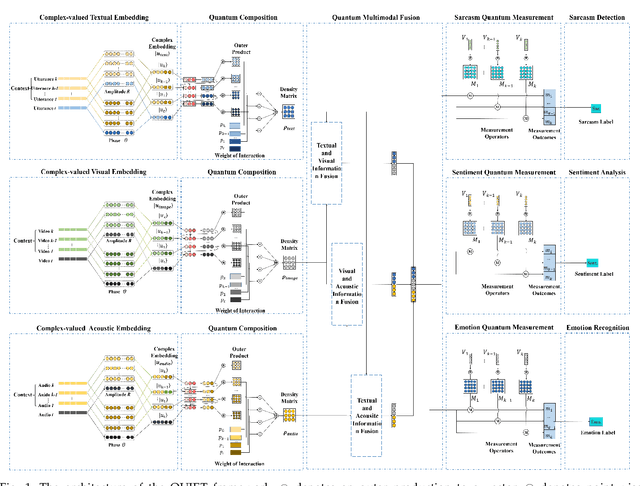
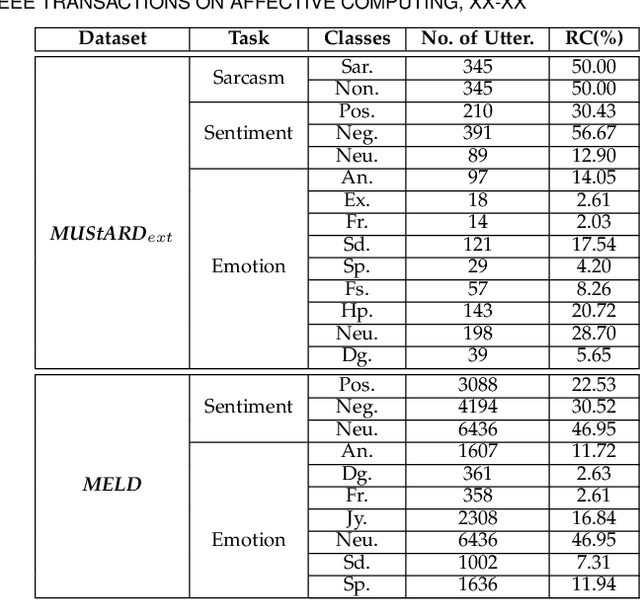
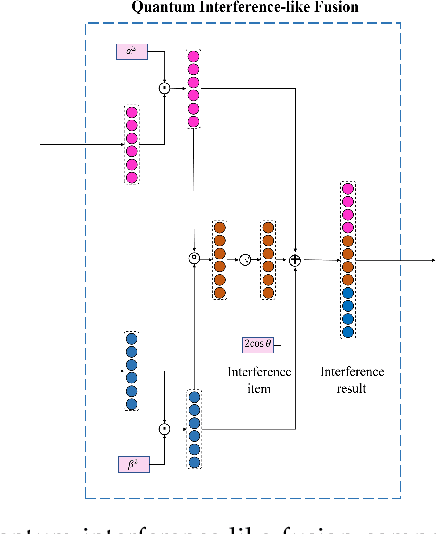
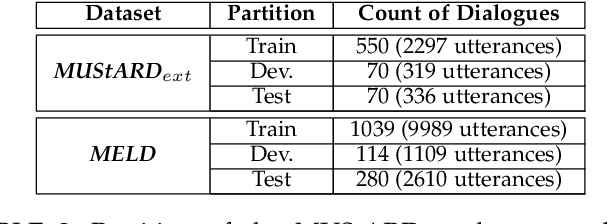
Sarcasm, sentiment, and emotion are three typical kinds of spontaneous affective responses of humans to external events and they are tightly intertwined with each other. Such events may be expressed in multiple modalities (e.g., linguistic, visual and acoustic), e.g., multi-modal conversations. Joint analysis of humans' multi-modal sarcasm, sentiment, and emotion is an important yet challenging topic, as it is a complex cognitive process involving both cross-modality interaction and cross-affection correlation. From the probability theory perspective, cross-affection correlation also means that the judgments on sarcasm, sentiment, and emotion are incompatible. However, this exposed phenomenon cannot be sufficiently modelled by classical probability theory due to its assumption of compatibility. Neither do the existing approaches take it into consideration. In view of the recent success of quantum probability (QP) in modeling human cognition, particularly contextual incompatible decision making, we take the first step towards introducing QP into joint multi-modal sarcasm, sentiment, and emotion analysis. Specifically, we propose a QUantum probabIlity driven multi-modal sarcasm, sEntiment and emoTion analysis framework, termed QUIET. Extensive experiments on two datasets and the results show that the effectiveness and advantages of QUIET in comparison with a wide range of the state-of-the-art baselines. We also show the great potential of QP in multi-affect analysis.