 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Recognition of Mental Adjectives in An Efficient and Automatic Style
Jul 16, 2023
In recent years, commonsense reasoning has received more and more attention from academic community. We propose a new lexical inference task, Mental and Physical Classification (MPC), to handle commonsense reasoning in a reasoning graph. Mental words relate to mental activities, which fall into six categories: Emotion, Need, Perceiving, Reasoning, Planning and Personality. Physical words describe physical attributes of an object, like color, hardness, speed and malleability. A BERT model is fine-tuned for this task and active learning algorithm is adopted in the training framework to reduce the required annotation resources. The model using ENTROPY strategy achieves satisfactory accuracy and requires only about 300 labeled words. We also compare our result with SentiWordNet to check the difference between MPC and subjectivity classification task in sentiment analysis.
Automated Testing and Improvement of Named Entity Recognition Systems
Aug 14, 2023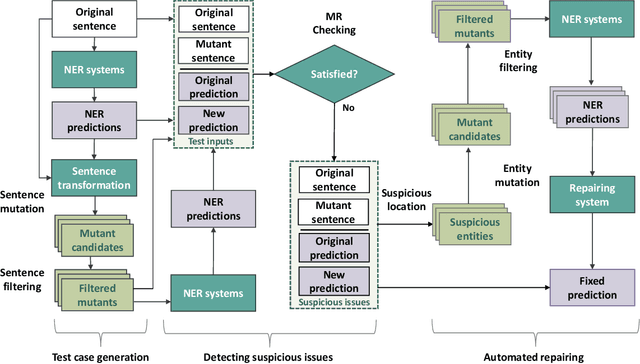

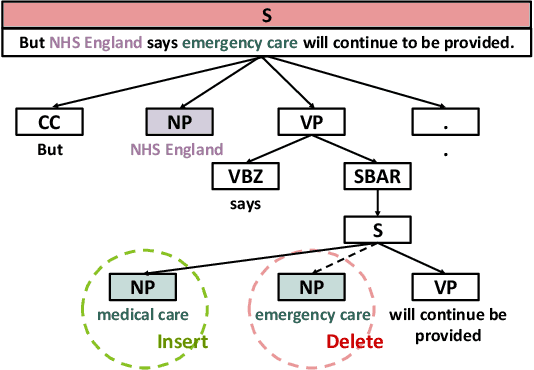
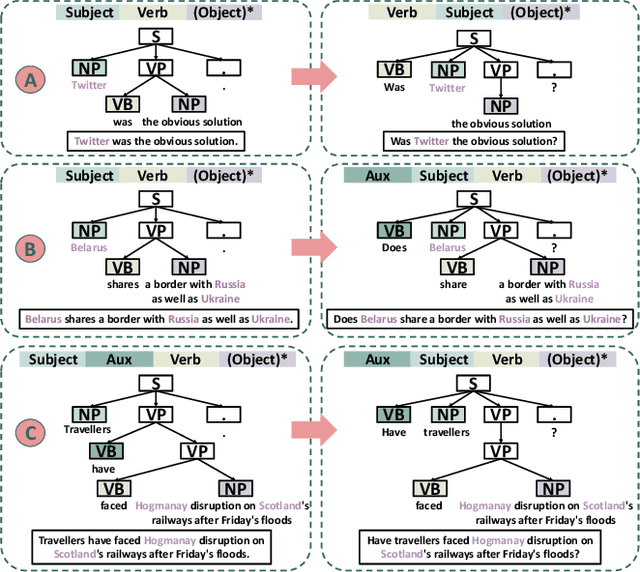
Named entity recognition (NER) systems have seen rapid progress in recent years due to the development of deep neural networks. These systems are widely used in various natural language processing applications, such as information extraction, question answering, and sentiment analysis. However, the complexity and intractability of deep neural networks can make NER systems unreliable in certain circumstances, resulting in incorrect predictions. For example, NER systems may misidentify female names as chemicals or fail to recognize the names of minority groups, leading to user dissatisfaction. To tackle this problem, we introduce TIN, a novel, widely applicable approach for automatically testing and repairing various NER systems. The key idea for automated testing is that the NER predictions of the same named entities under similar contexts should be identical. The core idea for automated repairing is that similar named entities should have the same NER prediction under the same context. We use TIN to test two SOTA NER models and two commercial NER APIs, i.e., Azure NER and AWS NER. We manually verify 784 of the suspicious issues reported by TIN and find that 702 are erroneous issues, leading to high precision (85.0%-93.4%) across four categories of NER errors: omission, over-labeling, incorrect category, and range error. For automated repairing, TIN achieves a high error reduction rate (26.8%-50.6%) over the four systems under test, which successfully repairs 1,056 out of the 1,877 reported NER errors.
Video-based Cross-modal Auxiliary Network for Multimodal Sentiment Analysis
Aug 30, 2022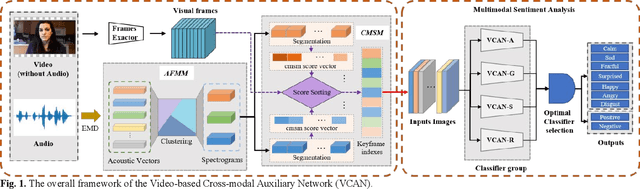
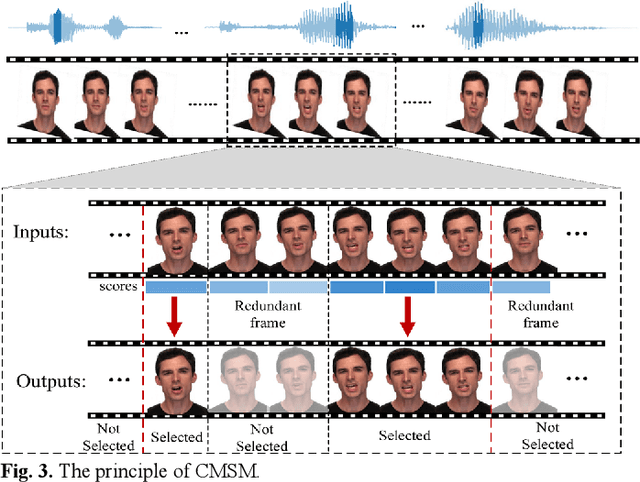
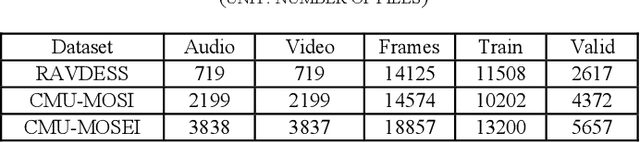
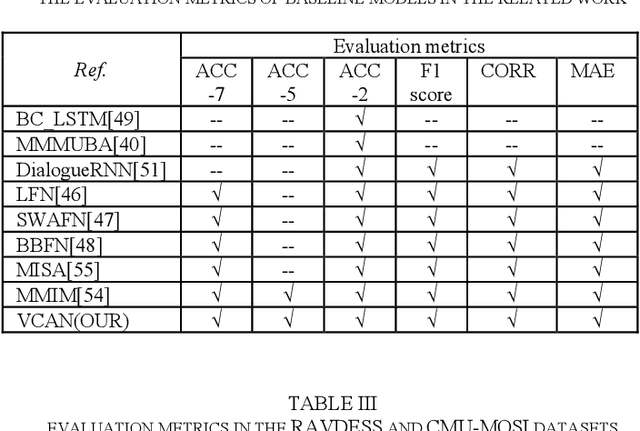
Multimodal sentiment analysis has a wide range of applications due to its information complementarity in multimodal interactions. Previous works focus more on investigating efficient joint representations, but they rarely consider the insufficient unimodal features extraction and data redundancy of multimodal fusion. In this paper, a Video-based Cross-modal Auxiliary Network (VCAN) is proposed, which is comprised of an audio features map module and a cross-modal selection module. The first module is designed to substantially increase feature diversity in audio feature extraction, aiming to improve classification accuracy by providing more comprehensive acoustic representations. To empower the model to handle redundant visual features, the second module is addressed to efficiently filter the redundant visual frames during integrating audiovisual data. Moreover, a classifier group consisting of several image classification networks is introduced to predict sentiment polarities and emotion categories. Extensive experimental results on RAVDESS, CMU-MOSI, and CMU-MOSEI benchmarks indicate that VCAN is significantly superior to the state-of-the-art methods for improving the classification accuracy of multimodal sentiment analysis.
Adapted Multimodal BERT with Layer-wise Fusion for Sentiment Analysis
Dec 01, 2022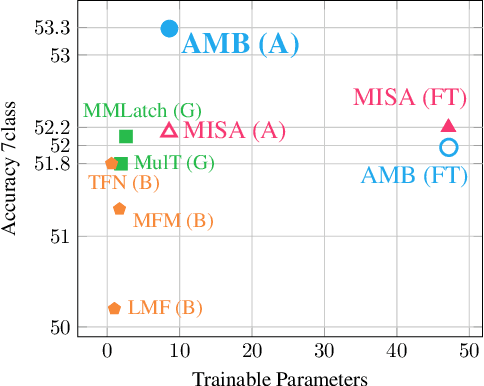
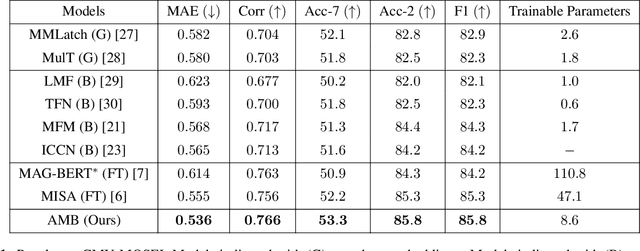
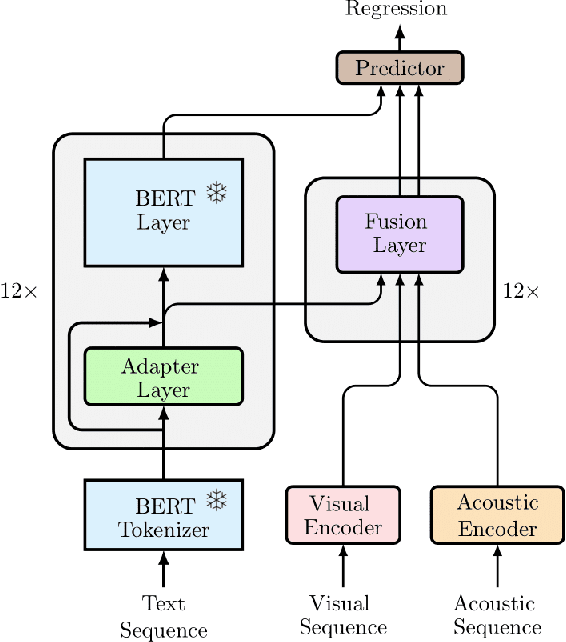
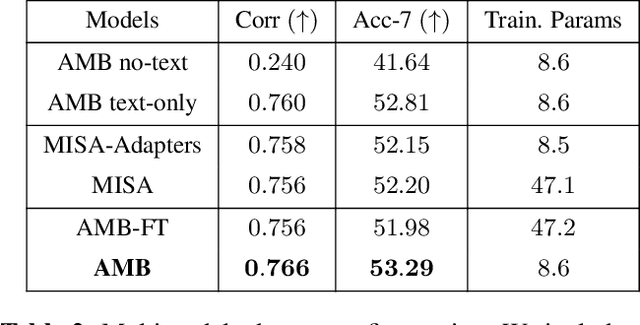
Multimodal learning pipelines have benefited from the success of pretrained language models. However, this comes at the cost of increased model parameters. In this work, we propose Adapted Multimodal BERT (AMB), a BERT-based architecture for multimodal tasks that uses a combination of adapter modules and intermediate fusion layers. The adapter adjusts the pretrained language model for the task at hand, while the fusion layers perform task-specific, layer-wise fusion of audio-visual information with textual BERT representations. During the adaptation process the pre-trained language model parameters remain frozen, allowing for fast, parameter-efficient training. In our ablations we see that this approach leads to efficient models, that can outperform their fine-tuned counterparts and are robust to input noise. Our experiments on sentiment analysis with CMU-MOSEI show that AMB outperforms the current state-of-the-art across metrics, with 3.4% relative reduction in the resulting error and 2.1% relative improvement in 7-class classification accuracy.
The use of new technologies to support Public Administration. Sentiment analysis and the case of the app IO
Jan 10, 2023
App IO is an app developed for the Italian PA. It is definitely useful for citizens to interact with the PA and to get services that were not digitized yet. Nevertheless, it was not perceived in a good way by the citizens and it has been criticized. As we wanted to find the root that caused all these bad reviews we scraped feedback from mobile app stores using custom-coded automated tools and - after that - we trained two machine learning models to perform both sentiment analysis and emotion detection to understand what caused the bad reviews.
AI Chatbots as Multi-Role Pedagogical Agents: Transforming Engagement in CS Education
Aug 08, 2023
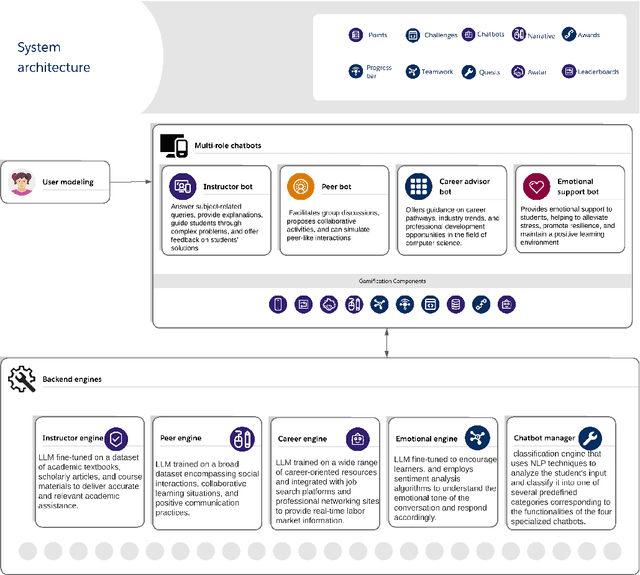
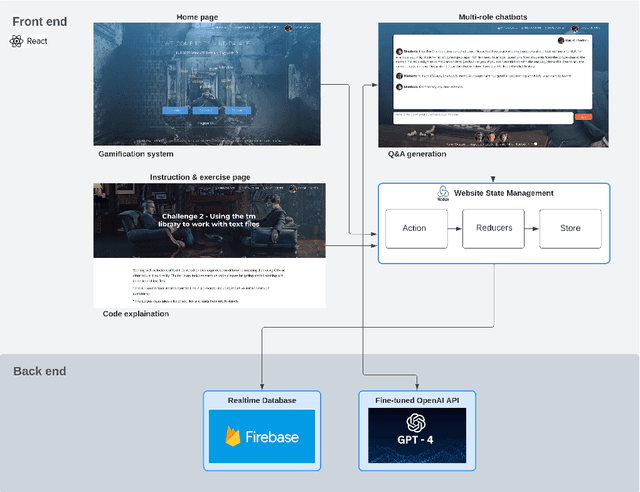
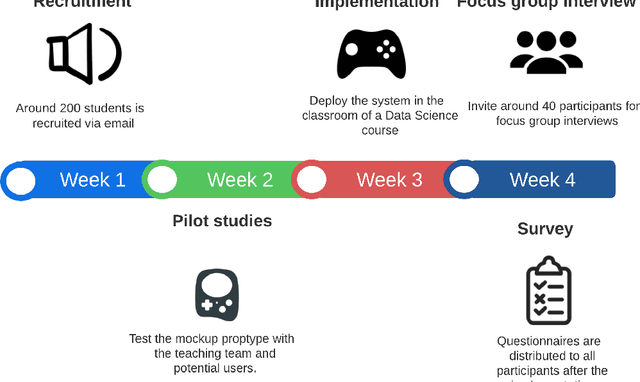
This study investigates the use of Artificial Intelligence (AI)-powered, multi-role chatbots as a means to enhance learning experiences and foster engagement in computer science education. Leveraging a design-based research approach, we develop, implement, and evaluate a novel learning environment enriched with four distinct chatbot roles: Instructor Bot, Peer Bot, Career Advising Bot, and Emotional Supporter Bot. These roles, designed around the tenets of Self-Determination Theory, cater to the three innate psychological needs of learners - competence, autonomy, and relatedness. Additionally, the system embraces an inquiry-based learning paradigm, encouraging students to ask questions, seek solutions, and explore their curiosities. We test this system in a higher education context over a period of one month with 200 participating students, comparing outcomes with conditions involving a human tutor and a single chatbot. Our research utilizes a mixed-methods approach, encompassing quantitative measures such as chat log sequence analysis, and qualitative methods including surveys and focus group interviews. By integrating cutting-edge Natural Language Processing techniques such as topic modelling and sentiment analysis, we offer an in-depth understanding of the system's impact on learner engagement, motivation, and inquiry-based learning. This study, through its rigorous design and innovative approach, provides significant insights into the potential of AI-empowered, multi-role chatbots in reshaping the landscape of computer science education and fostering an engaging, supportive, and motivating learning environment.
Chinese Financial Text Emotion Mining: GCGTS -- A Character Relationship-based Approach for Simultaneous Aspect-Opinion Pair Extraction
Aug 04, 2023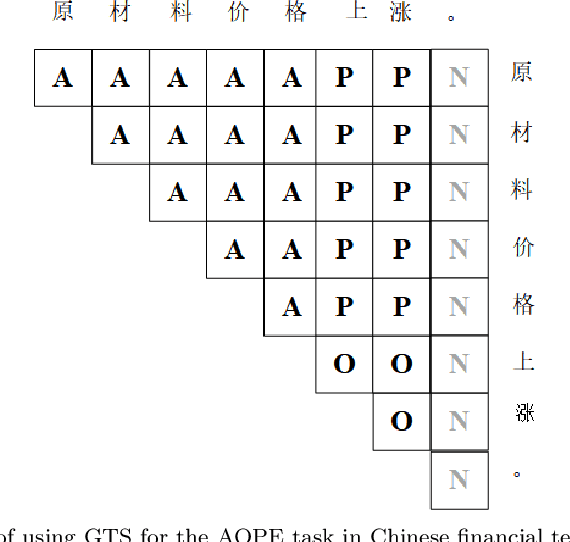

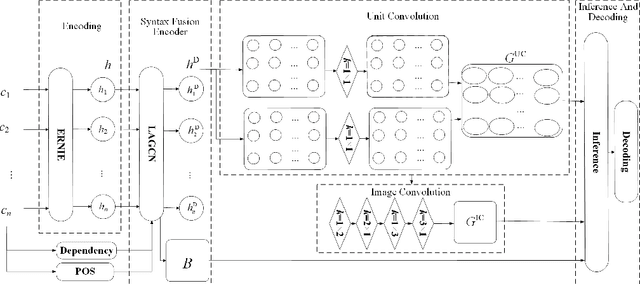
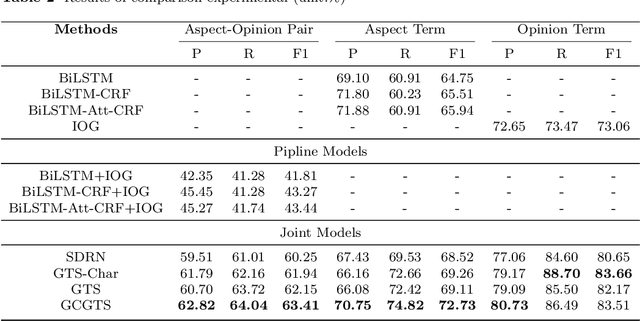
Aspect-Opinion Pair Extraction (AOPE) from Chinese financial texts is a specialized task in fine-grained text sentiment analysis. The main objective is to extract aspect terms and opinion terms simultaneously from a diverse range of financial texts. Previous studies have mainly focused on developing grid annotation schemes within grid-based models to facilitate this extraction process. However, these methods often rely on character-level (token-level) feature encoding, which may overlook the logical relationships between Chinese characters within words. To address this limitation, we propose a novel method called Graph-based Character-level Grid Tagging Scheme (GCGTS). The GCGTS method explicitly incorporates syntactic structure using Graph Convolutional Networks (GCN) and unifies the encoding of characters within the same syntactic semantic unit (Chinese word level). Additionally, we introduce an image convolutional structure into the grid model to better capture the local relationships between characters within evaluation units. This innovative structure reduces the excessive reliance on pre-trained language models and emphasizes the modeling of structure and local relationships, thereby improving the performance of the model on Chinese financial texts. Through comparative experiments with advanced models such as Synchronous Double-channel Recurrent Network (SDRN) and Grid Tagging Scheme (GTS), the proposed GCGTS model demonstrates significant improvements in performance.
An Empirical Study on Fertility Proposals Using Multi-Grained Topic Analysis Methods
Jul 22, 2023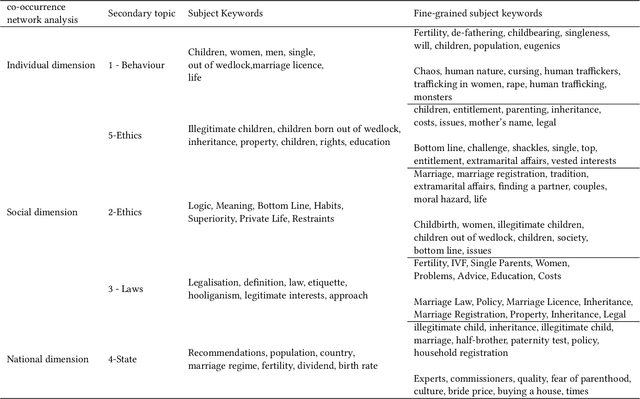
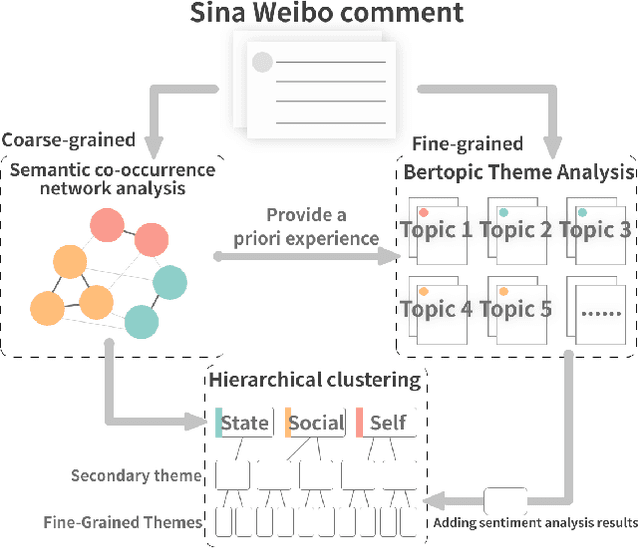
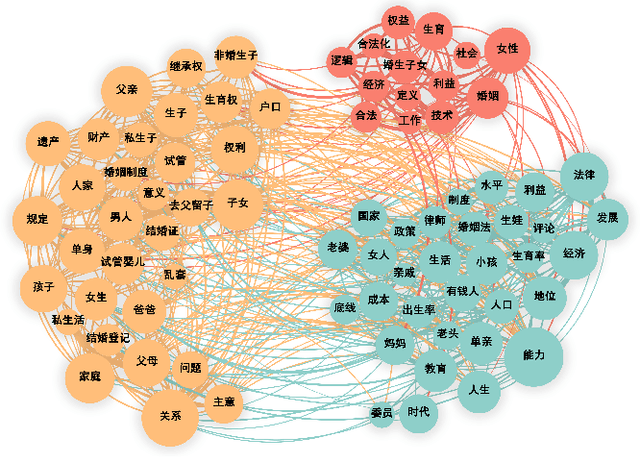
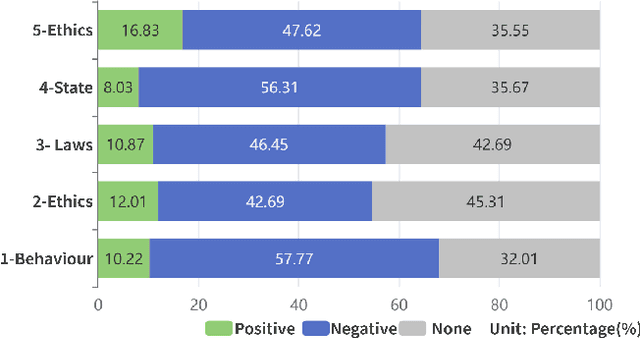
Fertility issues are closely related to population security, in 60 years China's population for the first time in a negative growth trend, the change of fertility policy is of great concern to the community. 2023 "two sessions" proposal "suggests that the country in the form of legislation, the birth of the registration of the cancellation of the marriage restriction" This topic was once a hot topic on the Internet, and "unbundling" the relationship between birth registration and marriage has become the focus of social debate. In this paper, we adopt co-occurrence semantic analysis, topic analysis and sentiment analysis to conduct multi-granularity semantic analysis of microblog comments. It is found that the discussion on the proposal of "removing marriage restrictions from birth registration" involves the individual, society and the state at three dimensions, and is detailed into social issues such as personal behaviour, social ethics and law, and national policy, with people's sentiment inclined to be negative in most of the topics. Based on this, eight proposals were made to provide a reference for governmental decision making and to form a reference method for researching public opinion on political issues.
DiaASQ : A Benchmark of Conversational Aspect-based Sentiment Quadruple Analysis
Nov 20, 2022
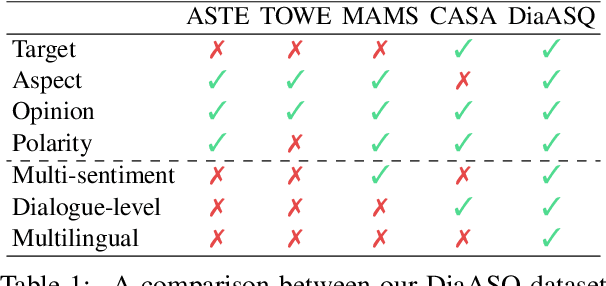
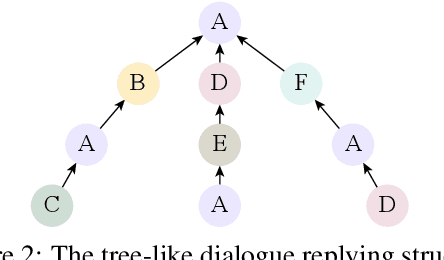
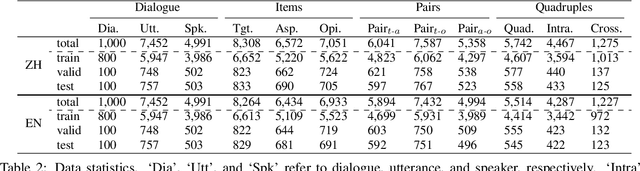
The rapid development of aspect-based sentiment analysis (ABSA) within recent decades shows great potential for real-world society. The current ABSA works, however, are mostly limited to the scenario of a single text piece, leaving the study in dialogue contexts unexplored. In this work, we introduce a novel task of conversational aspect-based sentiment quadruple analysis, namely DiaASQ, aiming to detect the sentiment quadruple of \emph{target-aspect-opinion-sentiment} in a dialogue. DiaASQ bridges the gap between fine-grained sentiment analysis and conversational opinion mining. We manually construct a large-scale high-quality DiaASQ dataset in both Chinese and English languages. We deliberately develop a neural model to benchmark the task, which advances in effectively performing end-to-end quadruple prediction, and manages to incorporate rich dialogue-specific and discourse feature representations for better cross-utterance quadruple extraction. We finally point out several potential future works to facilitate the follow-up research of this new task.
Enhancing Event-Level Sentiment Analysis with Structured Arguments
May 31, 2022

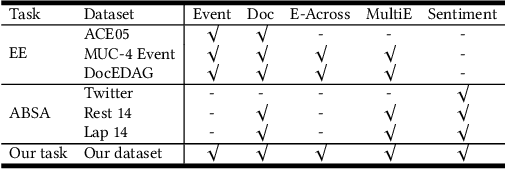
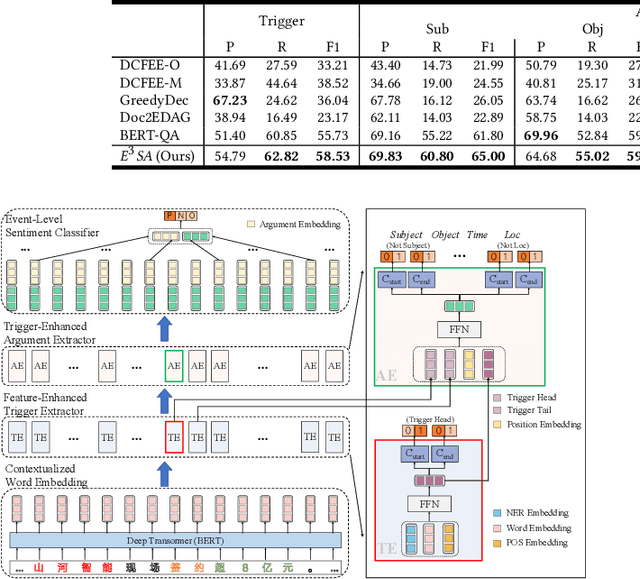
Previous studies about event-level sentiment analysis (SA) usually model the event as a topic, a category or target terms, while the structured arguments (e.g., subject, object, time and location) that have potential effects on the sentiment are not well studied. In this paper, we redefine the task as structured event-level SA and propose an End-to-End Event-level Sentiment Analysis ($\textit{E}^{3}\textit{SA}$) approach to solve this issue. Specifically, we explicitly extract and model the event structure information for enhancing event-level SA. Extensive experiments demonstrate the great advantages of our proposed approach over the state-of-the-art methods. Noting the lack of the dataset, we also release a large-scale real-world dataset with event arguments and sentiment labelling for promoting more researches\footnote{The dataset is available at https://github.com/zhangqi-here/E3SA}.