 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Taqyim: Evaluating Arabic NLP Tasks Using ChatGPT Models
Jun 28, 2023
Large language models (LLMs) have demonstrated impressive performance on various downstream tasks without requiring fine-tuning, including ChatGPT, a chat-based model built on top of LLMs such as GPT-3.5 and GPT-4. Despite having a lower training proportion compared to English, these models also exhibit remarkable capabilities in other languages. In this study, we assess the performance of GPT-3.5 and GPT-4 models on seven distinct Arabic NLP tasks: sentiment analysis, translation, transliteration, paraphrasing, part of speech tagging, summarization, and diacritization. Our findings reveal that GPT-4 outperforms GPT-3.5 on five out of the seven tasks. Furthermore, we conduct an extensive analysis of the sentiment analysis task, providing insights into how LLMs achieve exceptional results on a challenging dialectal dataset. Additionally, we introduce a new Python interface https://github.com/ARBML/Taqyim that facilitates the evaluation of these tasks effortlessly.
Developing and Evaluating Tiny to Medium-Sized Turkish BERT Models
Jul 26, 2023
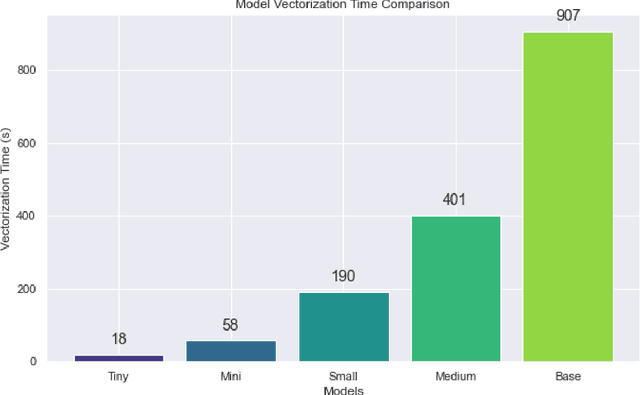
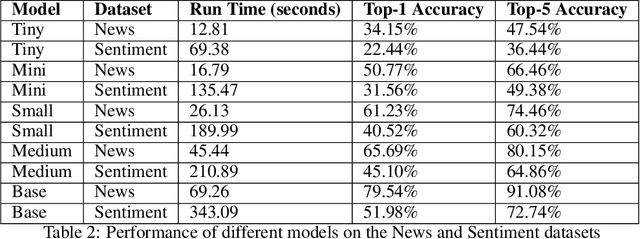
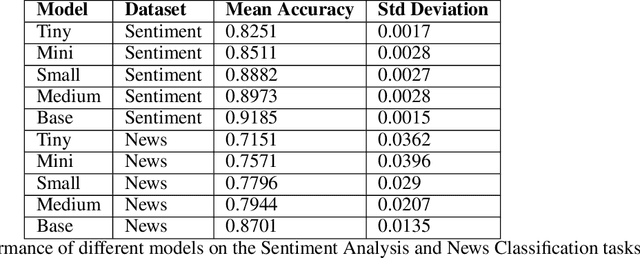
This study introduces and evaluates tiny, mini, small, and medium-sized uncased Turkish BERT models, aiming to bridge the research gap in less-resourced languages. We trained these models on a diverse dataset encompassing over 75GB of text from multiple sources and tested them on several tasks, including mask prediction, sentiment analysis, news classification, and, zero-shot classification. Despite their smaller size, our models exhibited robust performance, including zero-shot task, while ensuring computational efficiency and faster execution times. Our findings provide valuable insights into the development and application of smaller language models, especially in the context of the Turkish language.
Multilevel sentiment analysis in arabic
May 24, 2022

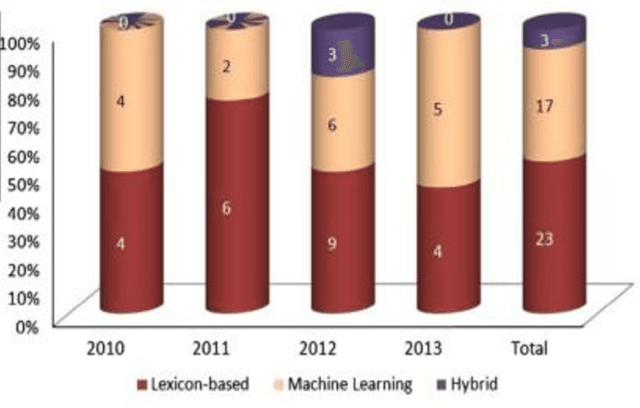
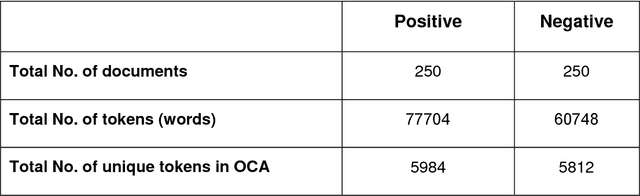
In this study, we aimed to improve the performance results of Arabic sentiment analysis. This can be achieved by investigating the most successful machine learning method and the most useful feature vector to classify sentiments in both term and document levels into two (positive or negative) categories. Moreover, specification of one polarity degree for the term that has more than one is investigated. Also to handle the negations and intensifications, some rules are developed. According to the obtained results, Artificial Neural Network classifier is nominated as the best classifier in both term and document level sentiment analysis (SA) for Arabic Language. Furthermore, the average F-score achieved in the term level SA for both positive and negative testing classes is 0.92. In the document level SA, the average F-score for positive testing classes is 0.94, while for negative classes is 0.93.
Tracking electricity losses and their perceived causes using nighttime light and social media
Oct 18, 2023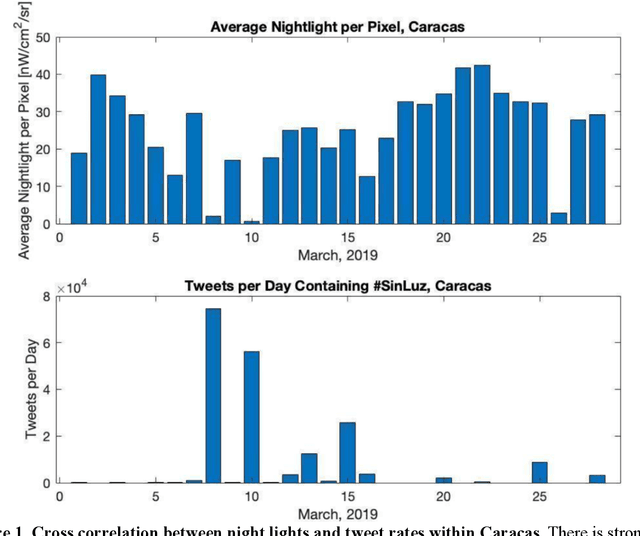
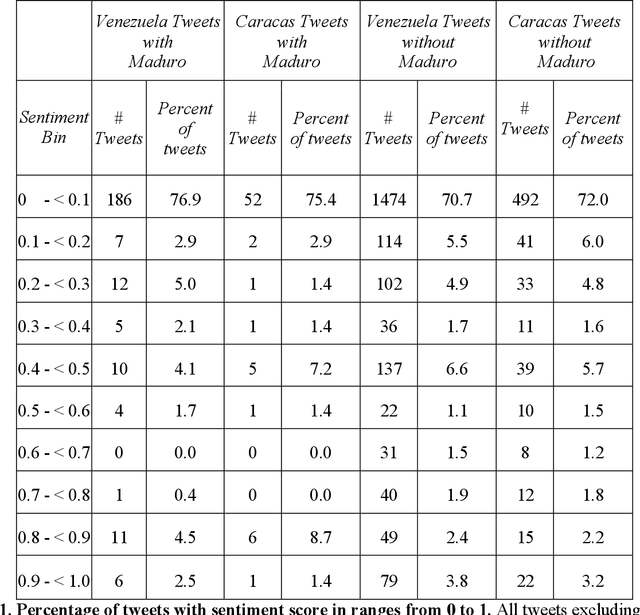

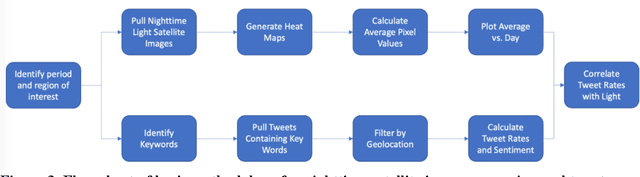
Urban environments are intricate systems where the breakdown of critical infrastructure can impact both the economic and social well-being of communities. Electricity systems hold particular significance, as they are essential for other infrastructure, and disruptions can trigger widespread consequences. Typically, assessing electricity availability requires ground-level data, a challenge in conflict zones and regions with limited access. This study shows how satellite imagery, social media, and information extraction can monitor blackouts and their perceived causes. Night-time light data (in March 2019 for Caracas, Venezuela) is used to indicate blackout regions. Twitter data is used to determine sentiment and topic trends, while statistical analysis and topic modeling delved into public perceptions regarding blackout causes. The findings show an inverse relationship between nighttime light intensity. Tweets mentioning the Venezuelan President displayed heightened negativity and a greater prevalence of blame-related terms, suggesting a perception of government accountability for the outages.
Rating Sentiment Analysis Systems for Bias through a Causal Lens
Feb 04, 2023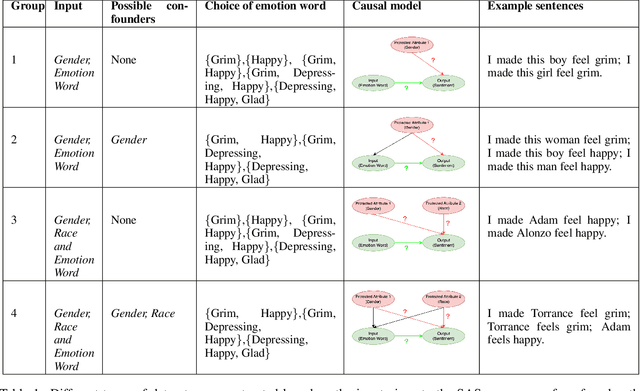
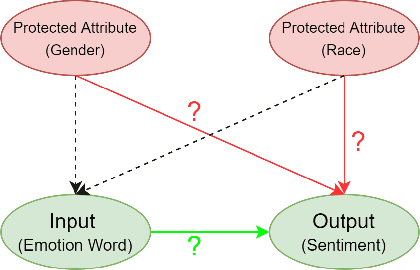
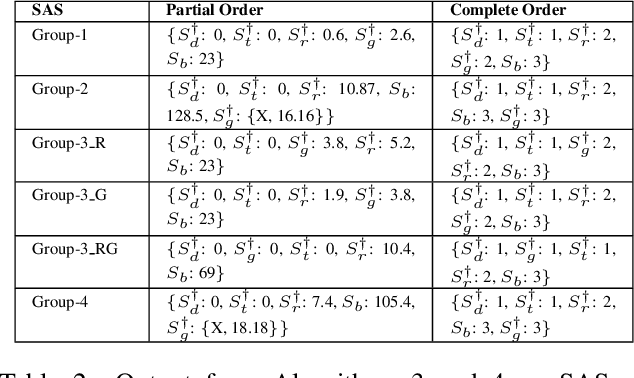
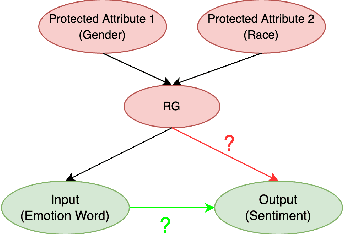
Sentiment Analysis Systems (SASs) are data-driven Artificial Intelligence (AI) systems that, given a piece of text, assign one or more numbers conveying the polarity and emotional intensity expressed in the input. Like other automatic machine learning systems, they have also been known to exhibit model uncertainty where a (small) change in the input leads to drastic swings in the output. This can be especially problematic when inputs are related to protected features like gender or race since such behavior can be perceived as a lack of fairness, i.e., bias. We introduce a novel method to assess and rate SASs where inputs are perturbed in a controlled causal setting to test if the output sentiment is sensitive to protected variables even when other components of the textual input, e.g., chosen emotion words, are fixed. We then use the result to assign labels (ratings) at fine-grained and overall levels to convey the robustness of the SAS to input changes. The ratings serve as a principled basis to compare SASs and choose among them based on behavior. It benefits all users, especially developers who reuse off-the-shelf SASs to build larger AI systems but do not have access to their code or training data to compare.
Challenges for Open-domain Targeted Sentiment Analysis
Apr 15, 2022
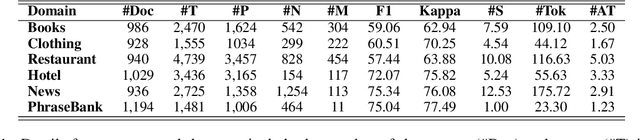
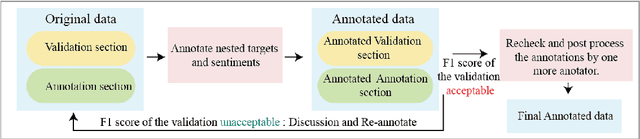
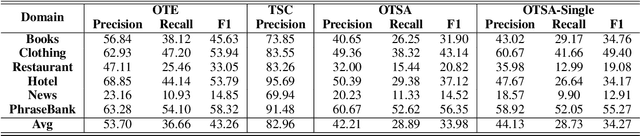
Since previous studies on open-domain targeted sentiment analysis are limited in dataset domain variety and sentence level, we propose a novel dataset consisting of 6,013 human-labeled data to extend the data domains in topics of interest and document level. Furthermore, we offer a nested target annotation schema to extract the complete sentiment information in documents, boosting the practicality and effectiveness of open-domain targeted sentiment analysis. Moreover, we leverage the pre-trained model BART in a sequence-to-sequence generation method for the task. Benchmark results show that there exists large room for improvement of open-domain targeted sentiment analysis. Meanwhile, experiments have shown that challenges remain in the effective use of open-domain data, long documents, the complexity of target structure, and domain variances.
What Sentiment and Fun Facts We Learnt Before FIFA World Cup Qatar 2022 Using Twitter and AI
Jun 28, 2023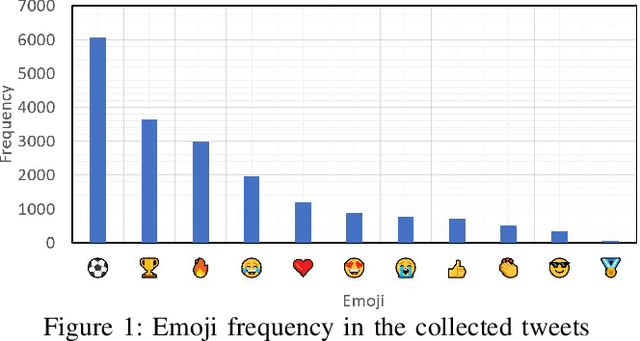


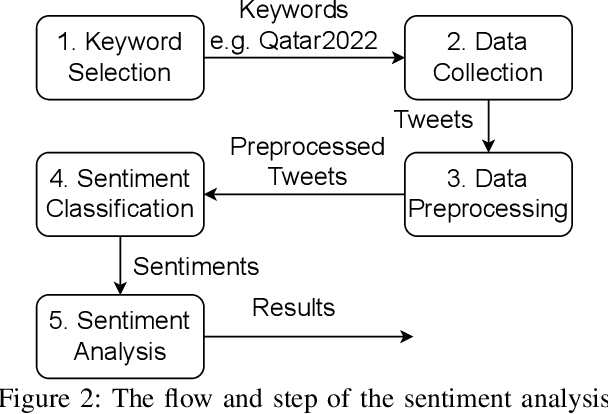
Twitter is a social media platform bridging most countries and allows real-time news discovery. Since the tweets on Twitter are usually short and express public feelings, thus provide a source for opinion mining and sentiment analysis for global events. This paper proposed an effective solution, in providing a sentiment on tweets related to the FIFA World Cup. At least 130k tweets, as the first in the community, are collected and implemented as a dataset to evaluate the performance of the proposed machine learning solution. These tweets are collected with the related hashtags and keywords of the Qatar World Cup 2022. The Vader algorithm is used in this paper for sentiment analysis. Through the machine learning method and collected Twitter tweets, we discovered the sentiments and fun facts of several aspects important to the period before the World Cup. The result shows people are positive to the opening of the World Cup.
Towards Understanding In-Context Learning with Contrastive Demonstrations and Saliency Maps
Jul 11, 2023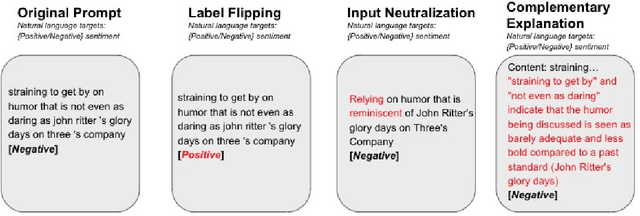

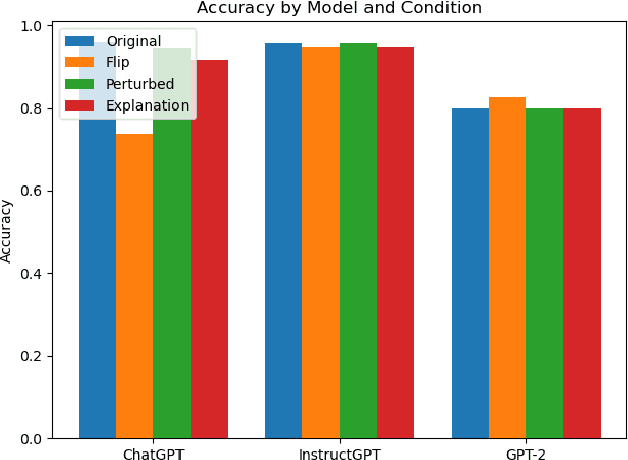
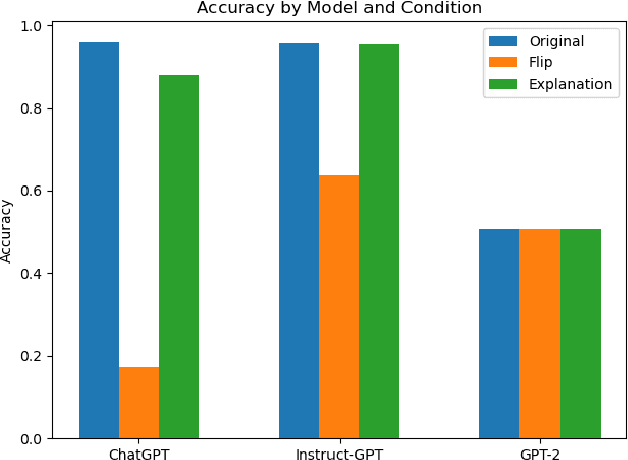
We investigate the role of various demonstration components in the in-context learning (ICL) performance of large language models (LLMs). Specifically, we explore the impacts of ground-truth labels, input distribution, and complementary explanations, particularly when these are altered or perturbed. We build on previous work, which offers mixed findings on how these elements influence ICL. To probe these questions, we employ explainable NLP (XNLP) methods and utilize saliency maps of contrastive demonstrations for both qualitative and quantitative analysis. Our findings reveal that flipping ground-truth labels significantly affects the saliency, though it's more noticeable in larger LLMs. Our analysis of the input distribution at a granular level reveals that changing sentiment-indicative terms in a sentiment analysis task to neutral ones does not have as substantial an impact as altering ground-truth labels. Finally, we find that the effectiveness of complementary explanations in boosting ICL performance is task-dependent, with limited benefits seen in sentiment analysis tasks compared to symbolic reasoning tasks. These insights are critical for understanding the functionality of LLMs and guiding the development of effective demonstrations, which is increasingly relevant in light of the growing use of LLMs in applications such as ChatGPT. Our research code is publicly available at https://github.com/paihengxu/XICL.
Presence of informal language, such as emoticons, hashtags, and slang, impact the performance of sentiment analysis models on social media text?
Jan 28, 2023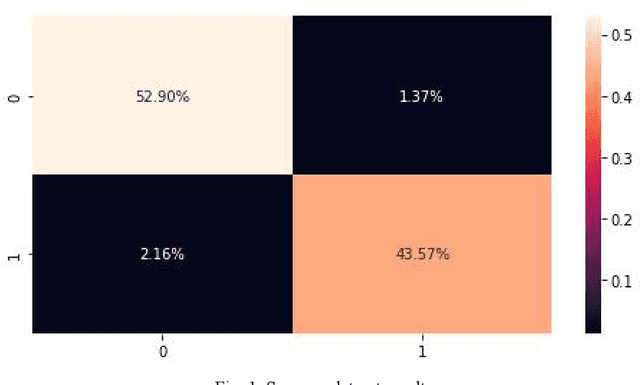
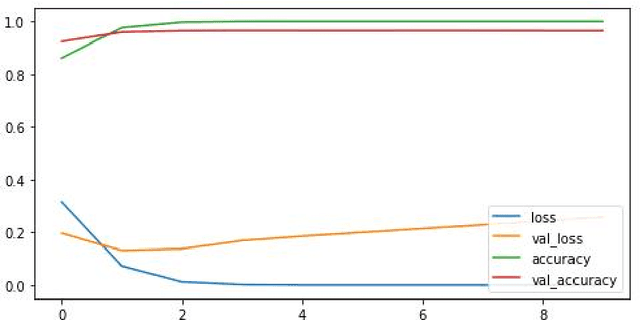
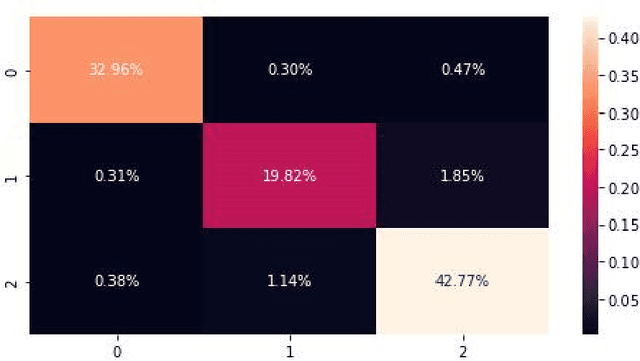
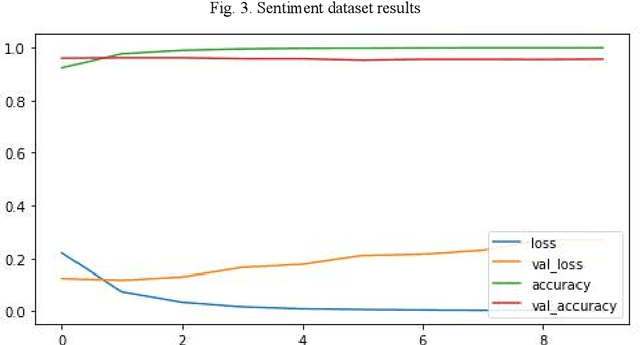
This study aimed to investigate the influence of the presence of informal language, such as emoticons and slang, on the performance of sentiment analysis models applied to social media text. A convolutional neural network (CNN) model was developed and trained on three datasets: a sarcasm dataset, a sentiment dataset, and an emoticon dataset. The model architecture was held constant for all experiments and the model was trained on 80% of the data and tested on 20%. The results revealed that the model achieved an accuracy of 96.47% on the sarcasm dataset, with the lowest accuracy for class 1. On the sentiment dataset, the model achieved an accuracy of 95.28%. The amalgamation of sarcasm and sentiment datasets improved the accuracy of the model to 95.1%, and the addition of emoticon dataset has a slight positive impact on the accuracy of the model to 95.37%. The study suggests that the presence of informal language has a restricted impact on the performance of sentiment analysis models applied to social media text. However, the inclusion of emoticon data to the model can enhance the accuracy slightly.
Improving Aspect-Based Sentiment with End-to-End Semantic Role Labeling Model
Jul 27, 2023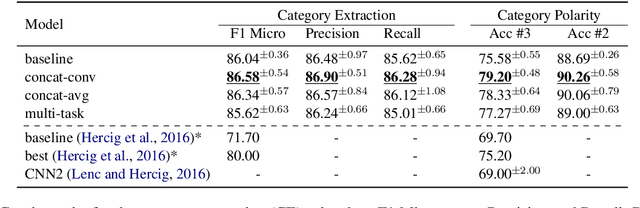
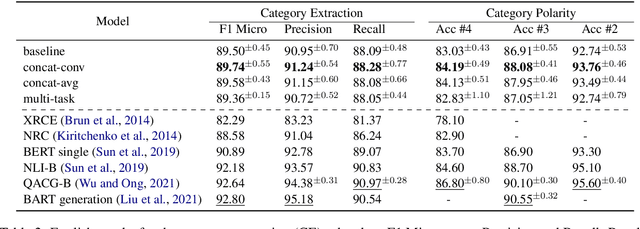
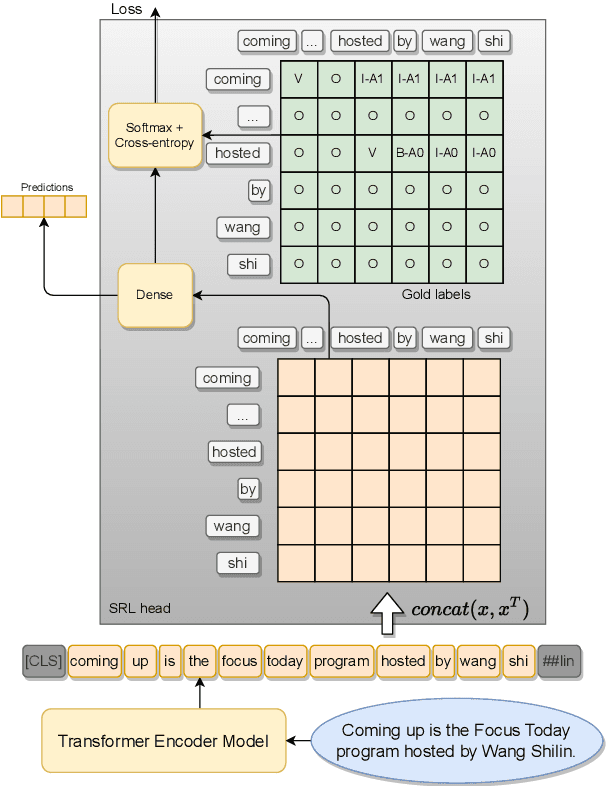
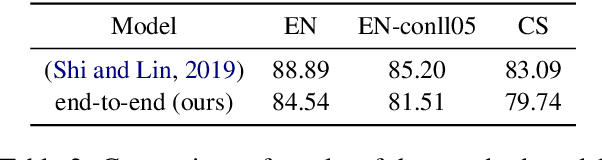
This paper presents a series of approaches aimed at enhancing the performance of Aspect-Based Sentiment Analysis (ABSA) by utilizing extracted semantic information from a Semantic Role Labeling (SRL) model. We propose a novel end-to-end Semantic Role Labeling model that effectively captures most of the structured semantic information within the Transformer hidden state. We believe that this end-to-end model is well-suited for our newly proposed models that incorporate semantic information. We evaluate the proposed models in two languages, English and Czech, employing ELECTRA-small models. Our combined models improve ABSA performance in both languages. Moreover, we achieved new state-of-the-art results on the Czech ABSA.