 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
MONOVAB : An Annotated Corpus for Bangla Multi-label Emotion Detection
Sep 27, 2023
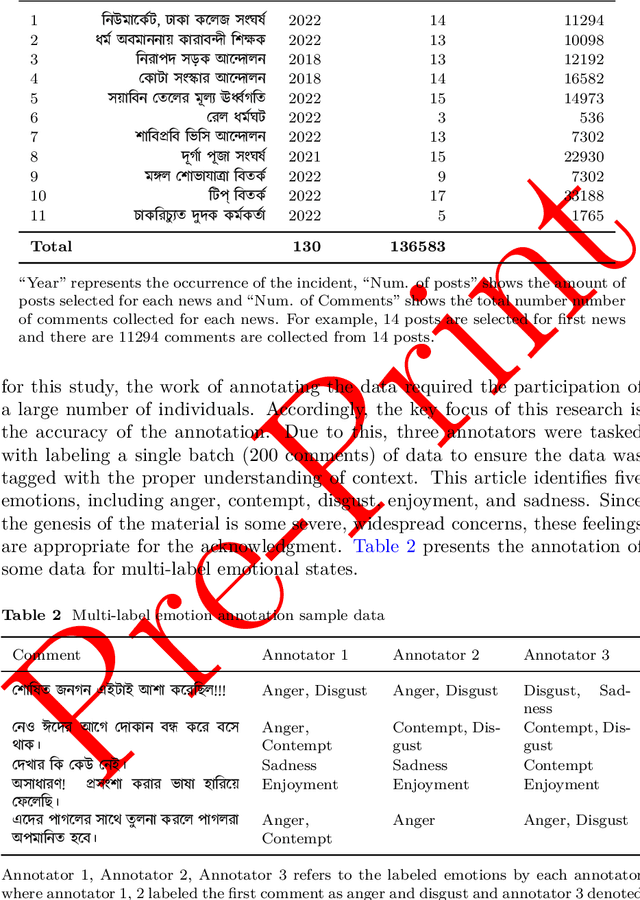
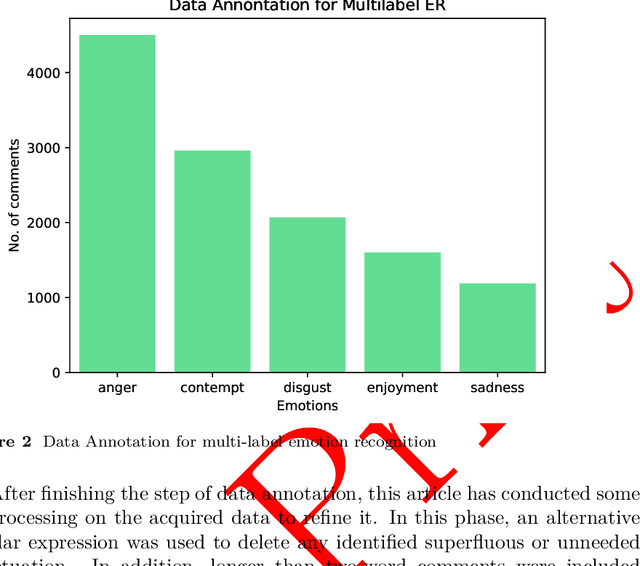
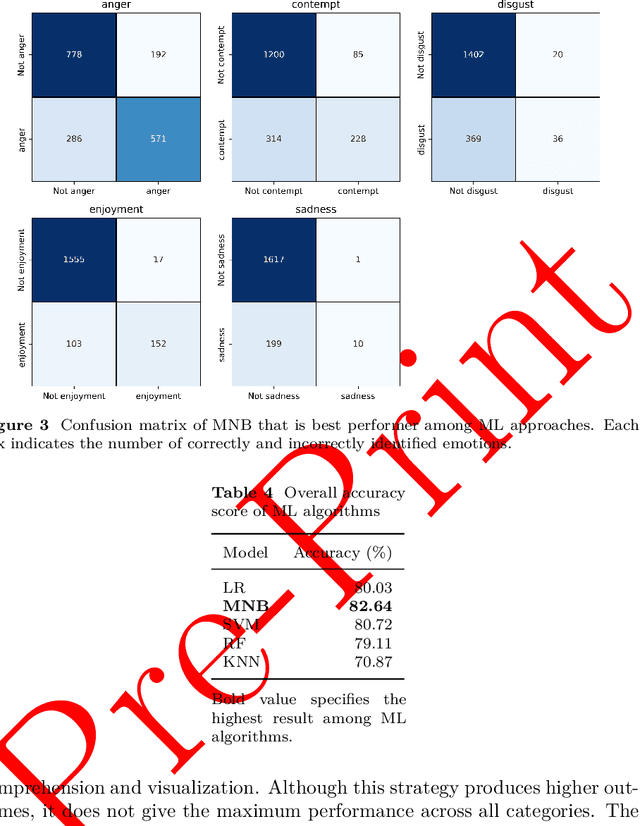
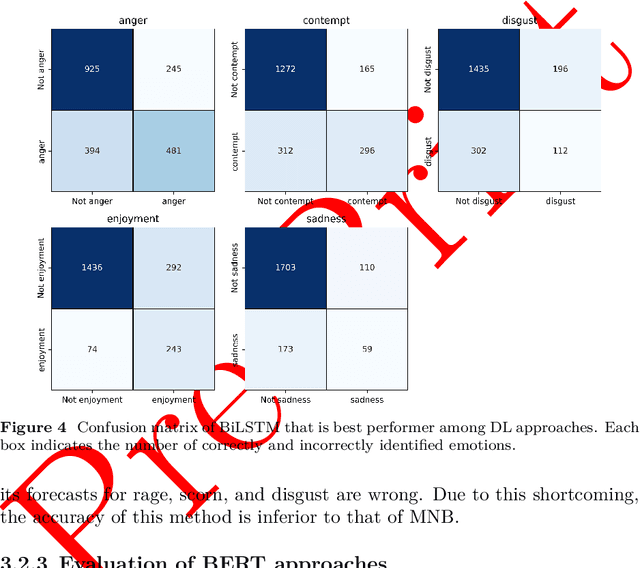
In recent years, Sentiment Analysis (SA) and Emotion Recognition (ER) have been increasingly popular in the Bangla language, which is the seventh most spoken language throughout the entire world. However, the language is structurally complicated, which makes this field arduous to extract emotions in an accurate manner. Several distinct approaches such as the extraction of positive and negative sentiments as well as multiclass emotions, have been implemented in this field of study. Nevertheless, the extraction of multiple sentiments is an almost untouched area in this language. Which involves identifying several feelings based on a single piece of text. Therefore, this study demonstrates a thorough method for constructing an annotated corpus based on scrapped data from Facebook to bridge the gaps in this subject area to overcome the challenges. To make this annotation more fruitful, the context-based approach has been used. Bidirectional Encoder Representations from Transformers (BERT), a well-known methodology of transformers, have been shown the best results of all methods implemented. Finally, a web application has been developed to demonstrate the performance of the pre-trained top-performer model (BERT) for multi-label ER in Bangla.
CrudeBERT: Applying Economic Theory towards fine-tuning Transformer-based Sentiment Analysis Models to the Crude Oil Market
May 10, 2023Predicting market movements based on the sentiment of news media has a long tradition in data analysis. With advances in natural language processing, transformer architectures have emerged that enable contextually aware sentiment classification. Nevertheless, current methods built for the general financial market such as FinBERT cannot distinguish asset-specific value-driving factors. This paper addresses this shortcoming by presenting a method that identifies and classifies events that impact supply and demand in the crude oil markets within a large corpus of relevant news headlines. We then introduce CrudeBERT, a new sentiment analysis model that draws upon these events to contextualize and fine-tune FinBERT, thereby yielding improved sentiment classifications for headlines related to the crude oil futures market. An extensive evaluation demonstrates that CrudeBERT outperforms proprietary and open-source solutions in the domain of crude oil.
Presenting an approach based on weighted CapsuleNet networks for Arabic and Persian multi-domain sentiment analysis
Jun 12, 2023
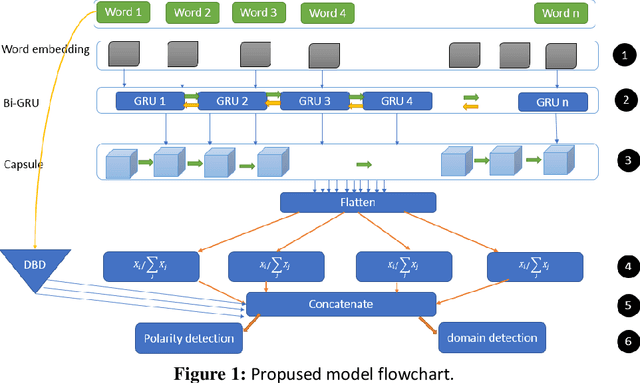

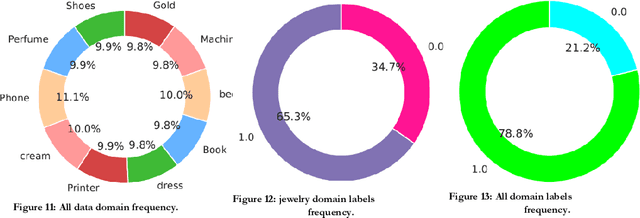
Sentiment classification is a fundamental task in natural language processing, assigning one of the three classes, positive, negative, or neutral, to free texts. However, sentiment classification models are highly domain dependent; the classifier may perform classification with reasonable accuracy in one domain but not in another due to the Semantic multiplicity of words getting poor accuracy. This article presents a new Persian/Arabic multi-domain sentiment analysis method using the cumulative weighted capsule networks approach. Weighted capsule ensemble consists of training separate capsule networks for each domain and a weighting measure called domain belonging degree (DBD). This criterion consists of TF and IDF, which calculates the dependency of each document for each domain separately; this value is multiplied by the possible output that each capsule creates. In the end, the sum of these multiplications is the title of the final output, and is used to determine the polarity. And the most dependent domain is considered the final output for each domain. The proposed method was evaluated using the Digikala dataset and obtained acceptable accuracy compared to the existing approaches. It achieved an accuracy of 0.89 on detecting the domain of belonging and 0.99 on detecting the polarity. Also, for the problem of dealing with unbalanced classes, a cost-sensitive function was used. This function was able to achieve 0.0162 improvements in accuracy for sentiment classification. This approach on Amazon Arabic data can achieve 0.9695 accuracies in domain classification.
GRASS: Unified Generation Model for Speech-to-Semantic Tasks
Sep 11, 2023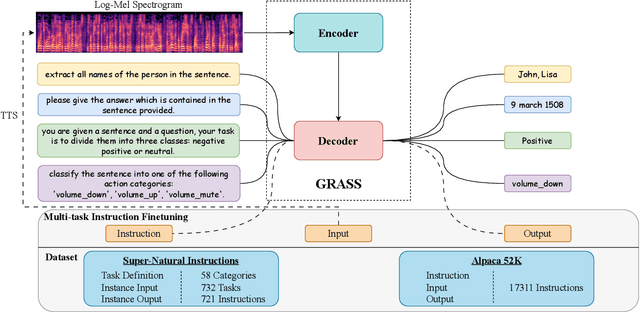
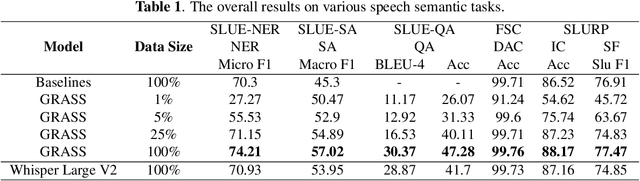

This paper explores the instruction fine-tuning technique for speech-to-semantic tasks by introducing a unified end-to-end (E2E) framework that generates target text conditioned on a task-related prompt for audio data. We pre-train the model using large and diverse data, where instruction-speech pairs are constructed via a text-to-speech (TTS) system. Extensive experiments demonstrate that our proposed model achieves state-of-the-art (SOTA) results on many benchmarks covering speech named entity recognition, speech sentiment analysis, speech question answering, and more, after fine-tuning. Furthermore, the proposed model achieves competitive performance in zero-shot and few-shot scenarios. To facilitate future work on instruction fine-tuning for speech-to-semantic tasks, we release our instruction dataset and code.
SemEval-2023 Task 12: Sentiment Analysis for African Languages (AfriSenti-SemEval)
Apr 13, 2023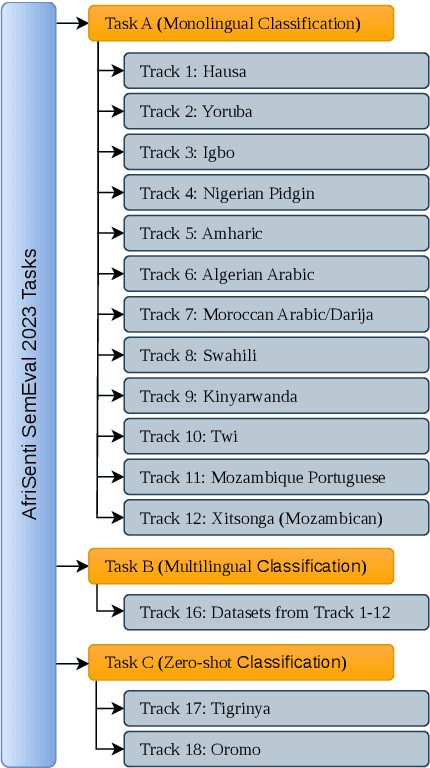
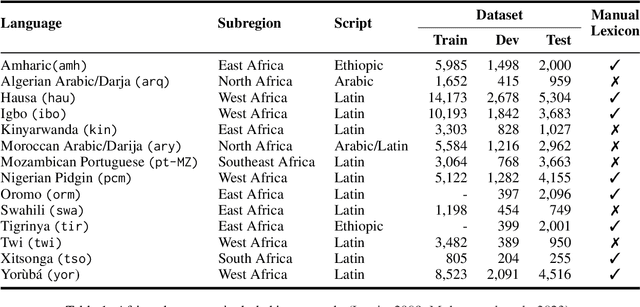
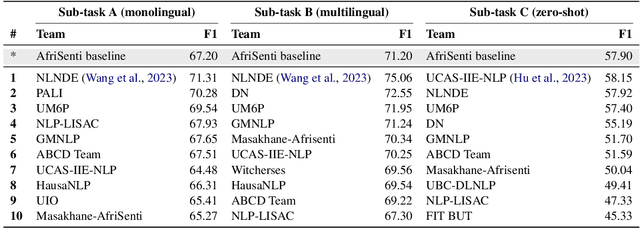
We present the first Africentric SemEval Shared task, Sentiment Analysis for African Languages (AfriSenti-SemEval) - the dataset is available at https://github.com/afrisenti-semeval/afrisent-semeval-2023. AfriSenti-SemEval is a sentiment classification challenge in 14 African languages - Amharic, Algerian Arabic, Hausa, Igbo, Kinyarwanda, Moroccan Arabic, Mozambican Portuguese, Nigerian Pidgin, Oromo, Swahili, Tigrinya, Twi, Xitsonga, and Yor\`ub\'a (Muhammad et al., 2023), using a 3-class labeled data: positive, negative, and neutral. We present three subtasks: (1) Task A: monolingual classification, which received 44 submissions; (2) Task B: multilingual classification, which received 32 submissions; and (3) Task C: zero-shot classification, which received 34 submissions. The best system for tasks A and B was achieved by NLNDE team with 71.31 and 75.06 weighted F1, respectively. UCAS-IIE-NLP achieved the best system on average for task C with 58.15 weighted F1. We describe the various approaches adopted by the top 10 systems and their approaches.
Transfer Learning with Joint Fine-Tuning for Multimodal Sentiment Analysis
Oct 11, 2022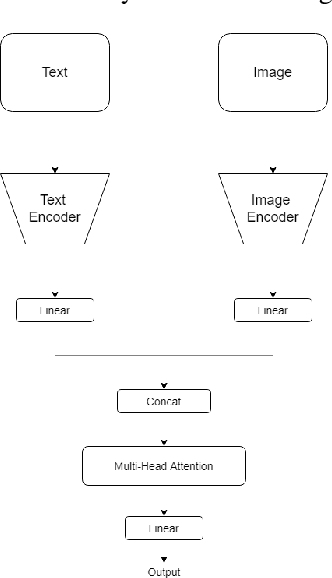
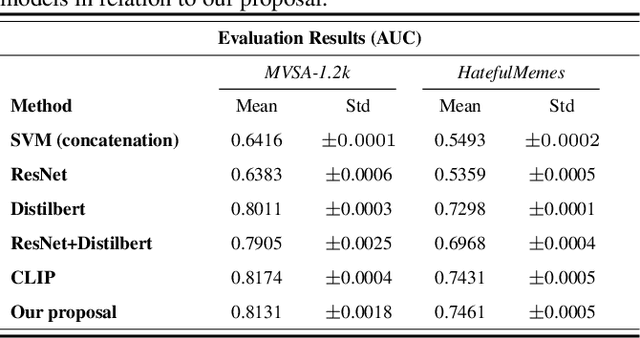
Most existing methods focus on sentiment analysis of textual data. However, recently there has been a massive use of images and videos on social platforms, motivating sentiment analysis from other modalities. Current studies show that exploring other modalities (e.g., images) increases sentiment analysis performance. State-of-the-art multimodal models, such as CLIP and VisualBERT, are pre-trained on datasets with the text paired with images. Although the results obtained by these models are promising, pre-training and sentiment analysis fine-tuning tasks of these models are computationally expensive. This paper introduces a transfer learning approach using joint fine-tuning for sentiment analysis. Our proposal achieved competitive results using a more straightforward alternative fine-tuning strategy that leverages different pre-trained unimodal models and efficiently combines them in a multimodal space. Moreover, our proposal allows flexibility when incorporating any pre-trained model for texts and images during the joint fine-tuning stage, being especially interesting for sentiment classification in low-resource scenarios.
Interpreting Sentiment Composition with Latent Semantic Tree
Aug 31, 2023
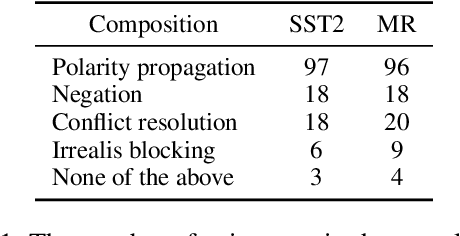
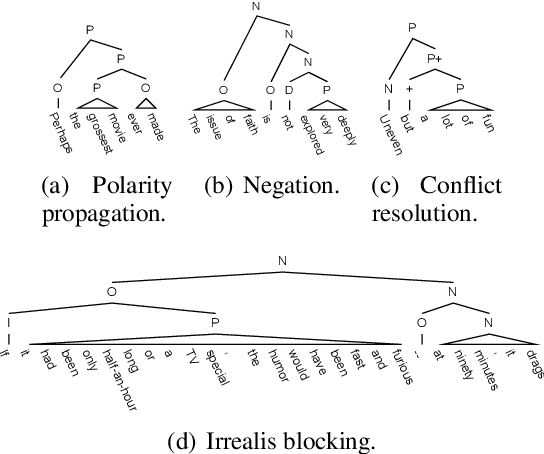
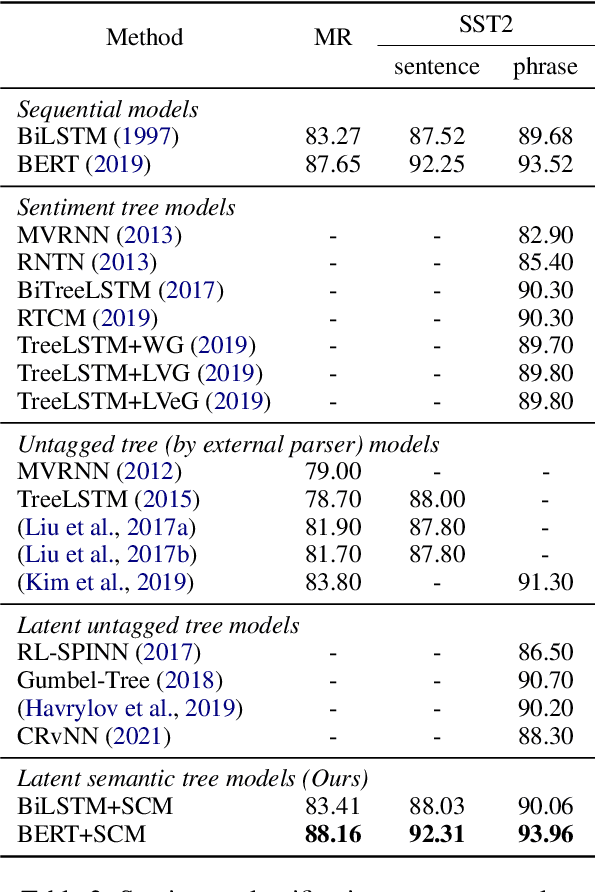
As the key to sentiment analysis, sentiment composition considers the classification of a constituent via classifications of its contained sub-constituents and rules operated on them. Such compositionality has been widely studied previously in the form of hierarchical trees including untagged and sentiment ones, which are intrinsically suboptimal in our view. To address this, we propose semantic tree, a new tree form capable of interpreting the sentiment composition in a principled way. Semantic tree is a derivation of a context-free grammar (CFG) describing the specific composition rules on difference semantic roles, which is designed carefully following previous linguistic conclusions. However, semantic tree is a latent variable since there is no its annotation in regular datasets. Thus, in our method, it is marginalized out via inside algorithm and learned to optimize the classification performance. Quantitative and qualitative results demonstrate that our method not only achieves better or competitive results compared to baselines in the setting of regular and domain adaptation classification, and also generates plausible tree explanations.
SynGen: A Syntactic Plug-and-play Module for Generative Aspect-based Sentiment Analysis
Feb 25, 2023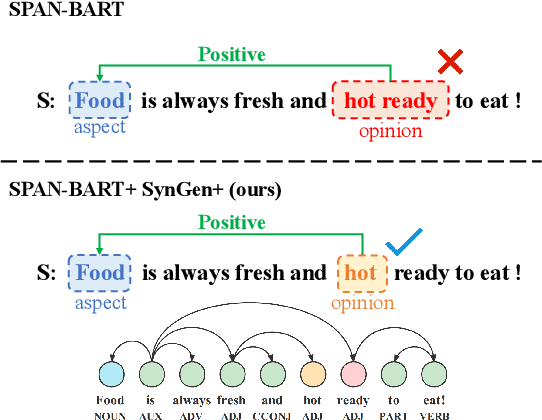
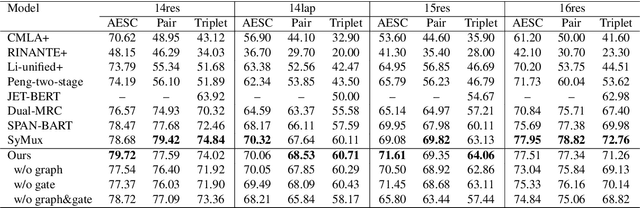
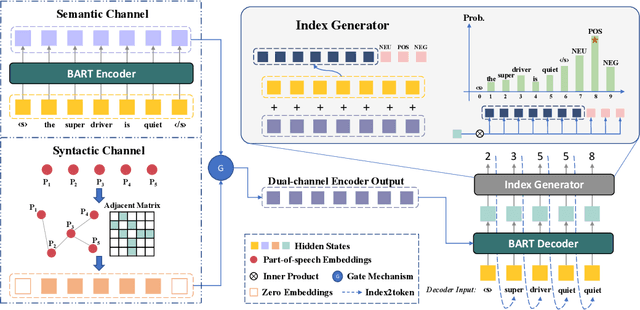
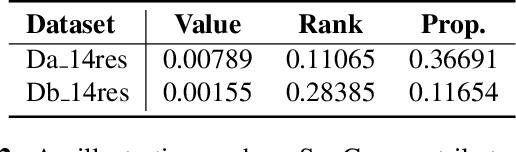
Aspect-based Sentiment Analysis (ABSA) is a sentiment analysis task at fine-grained level. Recently, generative frameworks have attracted increasing attention in ABSA due to their ability to unify subtasks and their continuity to upstream pre-training tasks. However, these generative models suffer from the neighboring dependency problem that induces neighboring words to get higher attention. In this paper, we propose SynGen, a plug-and-play syntactic information aware module. As a plug-in module, our SynGen can be easily applied to any generative framework backbones. The key insight of our module is to add syntactic inductive bias to attention assignment and thus direct attention to the correct target words. To the best of our knowledge, we are the first one to introduce syntactic information to generative ABSA frameworks. Our module design is based on two main principles: (1) maintaining the structural integrity of backbone PLMs and (2) disentangling the added syntactic information and original semantic information. Empirical results on four popular ABSA datasets demonstrate that SynGen enhanced model achieves a comparable performance to the state-of-the-art model with relaxed labeling specification and less training consumption.
* 4 pages, 2 figure, 2 tables
Entity-level Sentiment Analysis in Contact Center Telephone Conversations
Oct 26, 2022
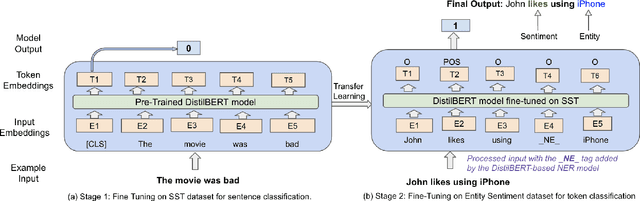


Entity-level sentiment analysis predicts the sentiment about entities mentioned in a given text. It is very useful in a business context to understand user emotions towards certain entities, such as products or companies. In this paper, we demonstrate how we developed an entity-level sentiment analysis system that analyzes English telephone conversation transcripts in contact centers to provide business insight. We present two approaches, one entirely based on the transformer-based DistilBERT model, and another that uses a convolutional neural network supplemented with some heuristic rules.
Improving Multimodal Classification of Social Media Posts by Leveraging Image-Text Auxiliary tasks
Sep 14, 2023
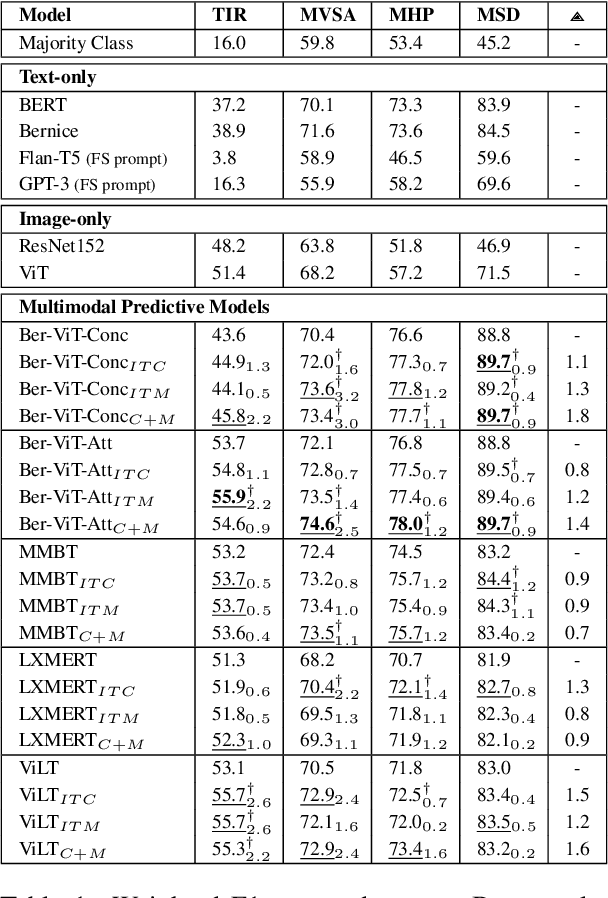
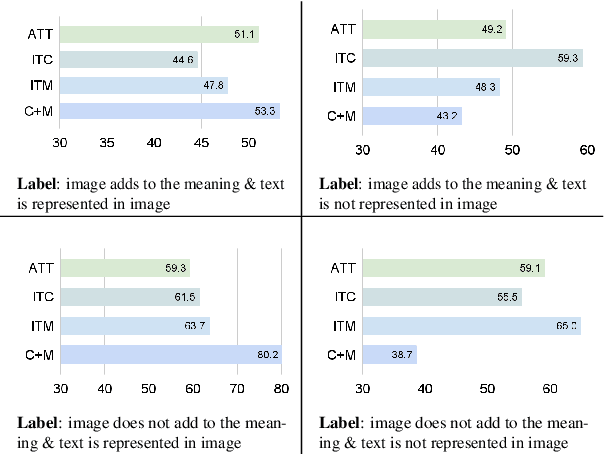

Effectively leveraging multimodal information from social media posts is essential to various downstream tasks such as sentiment analysis, sarcasm detection and hate speech classification. However, combining text and image information is challenging because of the idiosyncratic cross-modal semantics with hidden or complementary information present in matching image-text pairs. In this work, we aim to directly model this by proposing the use of two auxiliary losses jointly with the main task when fine-tuning any pre-trained multimodal model. Image-Text Contrastive (ITC) brings image-text representations of a post closer together and separates them from different posts, capturing underlying dependencies. Image-Text Matching (ITM) facilitates the understanding of semantic correspondence between images and text by penalizing unrelated pairs. We combine these objectives with five multimodal models, demonstrating consistent improvements across four popular social media datasets. Furthermore, through detailed analysis, we shed light on the specific scenarios and cases where each auxiliary task proves to be most effective.