 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
SAIDS: A Novel Approach for Sentiment Analysis Informed of Dialect and Sarcasm
Jan 06, 2023
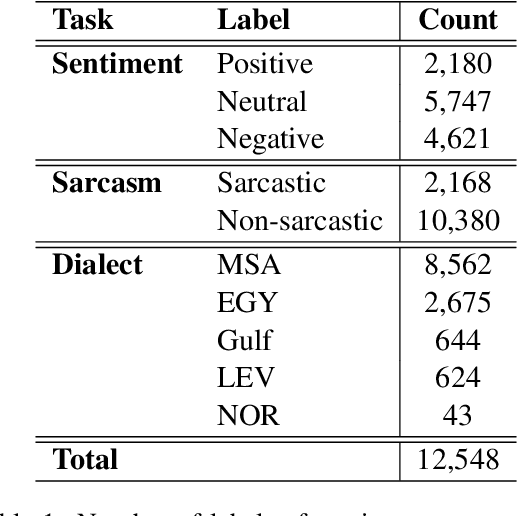
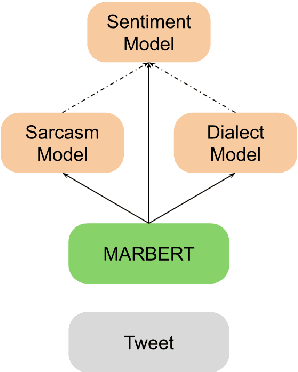
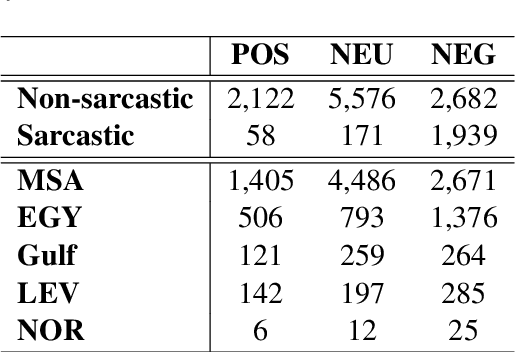
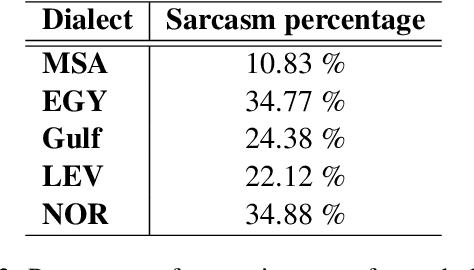
Sentiment analysis becomes an essential part of every social network, as it enables decision-makers to know more about users' opinions in almost all life aspects. Despite its importance, there are multiple issues it encounters like the sentiment of the sarcastic text which is one of the main challenges of sentiment analysis. This paper tackles this challenge by introducing a novel system (SAIDS) that predicts the sentiment, sarcasm and dialect of Arabic tweets. SAIDS uses its prediction of sarcasm and dialect as known information to predict the sentiment. It uses MARBERT as a language model to generate sentence embedding, then passes it to the sarcasm and dialect models, and then the outputs of the three models are concatenated and passed to the sentiment analysis model. Multiple system design setups were experimented with and reported. SAIDS was applied to the ArSarcasm-v2 dataset where it outperforms the state-of-the-art model for the sentiment analysis task. By training all tasks together, SAIDS achieves results of 75.98 FPN, 59.09 F1-score and 71.13 F1-score for sentiment analysis, sarcasm detection, and dialect identification respectively. The system design can be used to enhance the performance of any task which is dependent on other tasks.
Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
Oct 13, 2023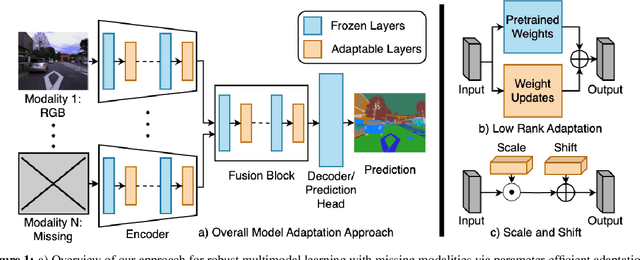
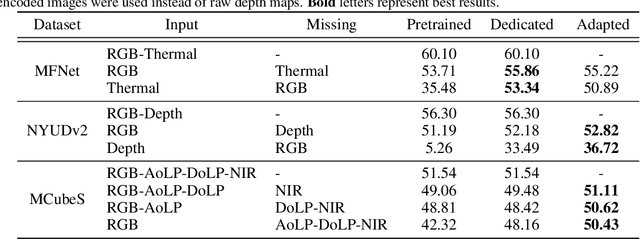
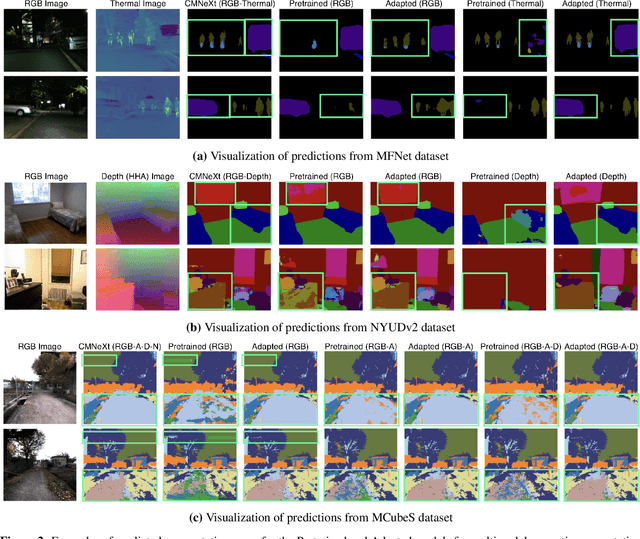
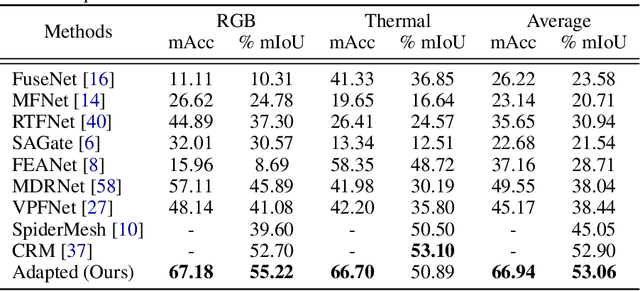
Multimodal learning seeks to utilize data from multiple sources to improve the overall performance of downstream tasks. It is desirable for redundancies in the data to make multimodal systems robust to missing or corrupted observations in some correlated modalities. However, we observe that the performance of several existing multimodal networks significantly deteriorates if one or multiple modalities are absent at test time. To enable robustness to missing modalities, we propose simple and parameter-efficient adaptation procedures for pretrained multimodal networks. In particular, we exploit low-rank adaptation and modulation of intermediate features to compensate for the missing modalities. We demonstrate that such adaptation can partially bridge performance drop due to missing modalities and outperform independent, dedicated networks trained for the available modality combinations in some cases. The proposed adaptation requires extremely small number of parameters (e.g., fewer than 0.7% of the total parameters in most experiments). We conduct a series of experiments to highlight the robustness of our proposed method using diverse datasets for RGB-thermal and RGB-Depth semantic segmentation, multimodal material segmentation, and multimodal sentiment analysis tasks. Our proposed method demonstrates versatility across various tasks and datasets, and outperforms existing methods for robust multimodal learning with missing modalities.
Unlock the Potential of Counterfactually-Augmented Data in Out-Of-Distribution Generalization
Oct 10, 2023
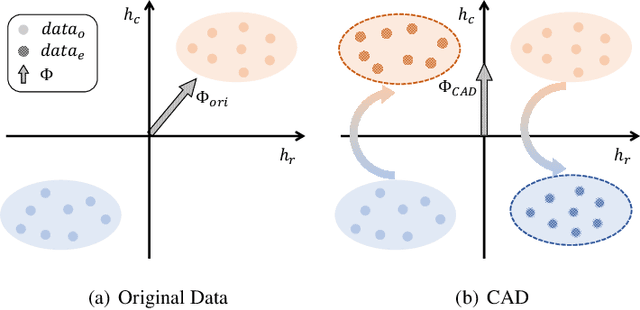
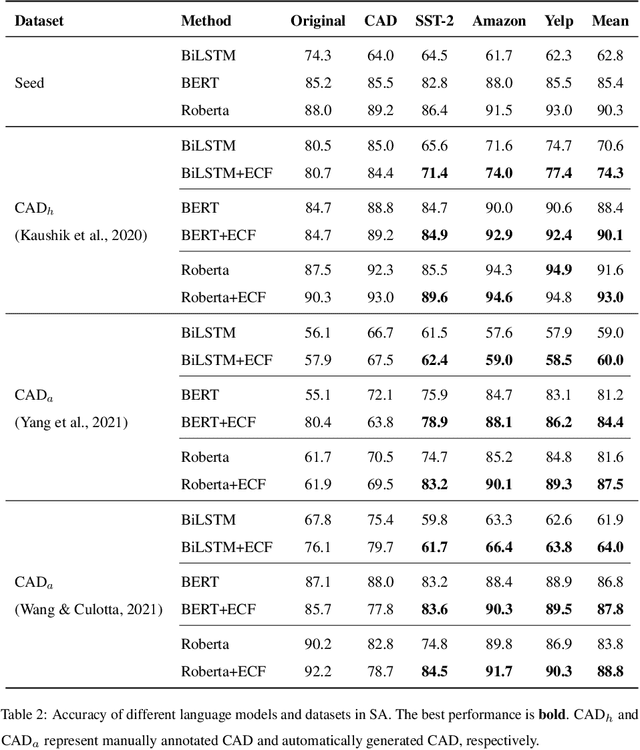
Counterfactually-Augmented Data (CAD) -- minimal editing of sentences to flip the corresponding labels -- has the potential to improve the Out-Of-Distribution (OOD) generalization capability of language models, as CAD induces language models to exploit domain-independent causal features and exclude spurious correlations. However, the empirical results of CAD's OOD generalization are not as efficient as anticipated. In this study, we attribute the inefficiency to the myopia phenomenon caused by CAD: language models only focus on causal features that are edited in the augmentation operation and exclude other non-edited causal features. Therefore, the potential of CAD is not fully exploited. To address this issue, we analyze the myopia phenomenon in feature space from the perspective of Fisher's Linear Discriminant, then we introduce two additional constraints based on CAD's structural properties (dataset-level and sentence-level) to help language models extract more complete causal features in CAD, thereby mitigating the myopia phenomenon and improving OOD generalization capability. We evaluate our method on two tasks: Sentiment Analysis and Natural Language Inference, and the experimental results demonstrate that our method could unlock the potential of CAD and improve the OOD generalization performance of language models by 1.0% to 5.9%.
In-Context Learning with Iterative Demonstration Selection
Oct 15, 2023Spurred by advancements in scale, large language models (LLMs) have demonstrated strong few-shot learning ability via in-context learning (ICL). However, the performance of ICL has been shown to be highly sensitive to the selection of few-shot demonstrations. Selecting the most suitable examples as context remains an ongoing challenge and an open problem. Existing literature has highlighted the importance of selecting examples that are diverse or semantically similar to the test sample while ignoring the fact that the optimal selection dimension, i.e., diversity or similarity, is task-specific. Leveraging the merits of both dimensions, we propose Iterative Demonstration Selection (IDS). Using zero-shot chain-of-thought reasoning (Zero-shot-CoT), IDS iteratively selects examples that are diverse but still strongly correlated with the test sample as ICL demonstrations. Specifically, IDS applies Zero-shot-CoT to the test sample before demonstration selection. The output reasoning path is then used to choose demonstrations that are prepended to the test sample for inference. The generated answer is accompanied by its corresponding reasoning path for extracting a new set of demonstrations in the next iteration. After several iterations, IDS adopts majority voting to obtain the final result. Through extensive experiments on tasks including commonsense reasoning, question answering, topic classification, and sentiment analysis, we demonstrate that IDS can consistently outperform existing ICL demonstration selection methods.
Time-Series Forecasting: Unleashing Long-Term Dependencies with Fractionally Differenced Data
Sep 23, 2023
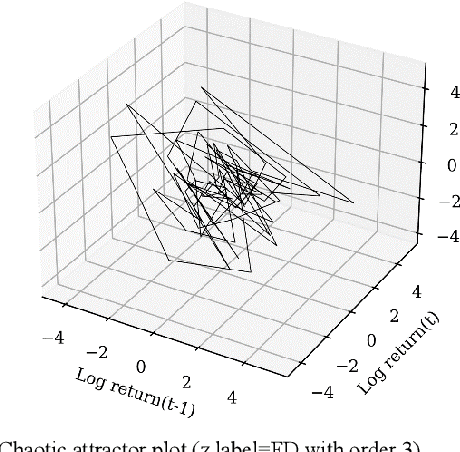
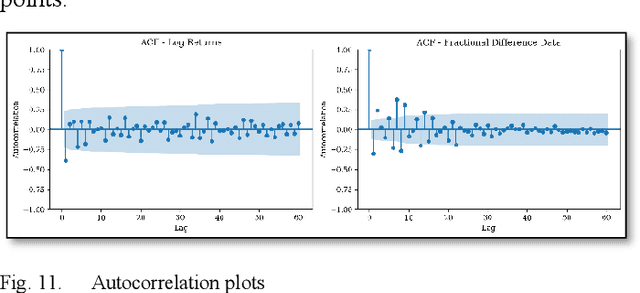
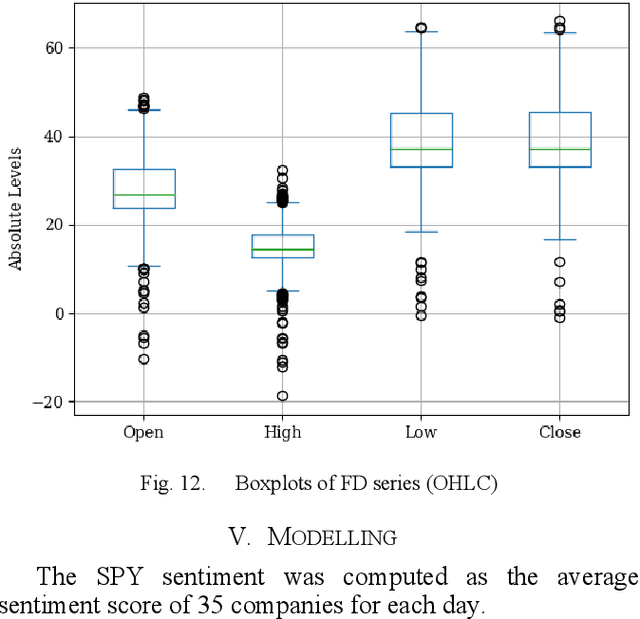
This study introduces a novel forecasting strategy that leverages the power of fractional differencing (FD) to capture both short- and long-term dependencies in time series data. Unlike traditional integer differencing methods, FD preserves memory in series while stabilizing it for modeling purposes. By applying FD to financial data from the SPY index and incorporating sentiment analysis from news reports, this empirical analysis explores the effectiveness of FD in conjunction with binary classification of target variables. Supervised classification algorithms were employed to validate the performance of FD series. The results demonstrate the superiority of FD over integer differencing, as confirmed by Receiver Operating Characteristic/Area Under the Curve (ROCAUC) and Mathews Correlation Coefficient (MCC) evaluations.
Explainable and Accurate Natural Language Understanding for Voice Assistants and Beyond
Sep 25, 2023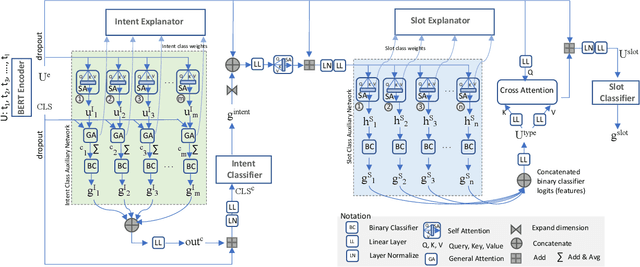
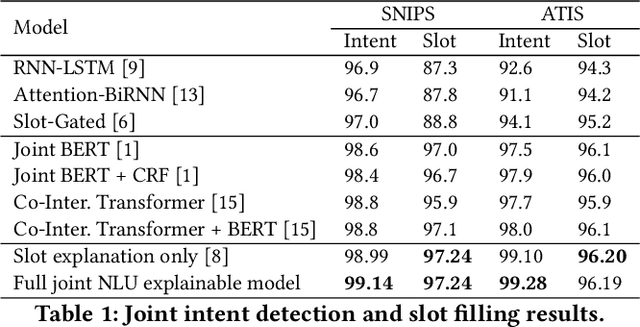
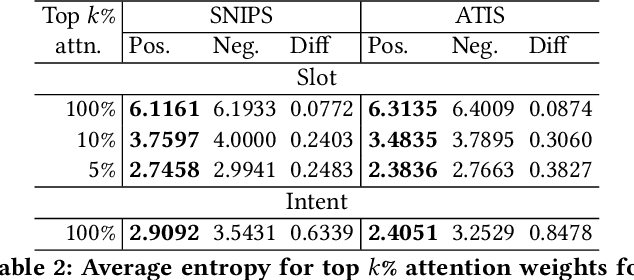

Joint intent detection and slot filling, which is also termed as joint NLU (Natural Language Understanding) is invaluable for smart voice assistants. Recent advancements in this area have been heavily focusing on improving accuracy using various techniques. Explainability is undoubtedly an important aspect for deep learning-based models including joint NLU models. Without explainability, their decisions are opaque to the outside world and hence, have tendency to lack user trust. Therefore to bridge this gap, we transform the full joint NLU model to be `inherently' explainable at granular levels without compromising on accuracy. Further, as we enable the full joint NLU model explainable, we show that our extension can be successfully used in other general classification tasks. We demonstrate this using sentiment analysis and named entity recognition.
Content-Localization based System for Analyzing Sentiment and Hate Behaviors in Low-Resource Dialectal Arabic: English to Levantine and Gulf
Nov 27, 2023Even though online social movements can quickly become viral on social media, languages can be a barrier to timely monitoring and analyzing the underlying online social behaviors (OSB). This is especially true for under-resourced languages on social media like dialectal Arabic; the primary language used by Arabs on social media. Therefore, it is crucial to provide solutions to efficiently exploit resources from high-resourced languages to solve language-dependent OSB analysis in under-resourced languages. This paper proposes to localize content of resources in high-resourced languages into under-resourced Arabic dialects. Content localization goes beyond content translation that converts text from one language to another; content localization adapts culture, language nuances and regional preferences from one language to a specific language/dialect. Automating understanding of the natural and familiar day-to-day expressions in different regions, is the key to achieve a wider analysis of OSB especially for smart cities. In this paper, we utilize content-localization based neural machine translation to develop sentiment and hate classifiers for two low-resourced Arabic dialects: Levantine and Gulf. Not only this but we also leverage unsupervised learning to facilitate the analysis of sentiment and hate predictions by inferring hidden topics from the corresponding data and providing coherent interpretations of those topics in their native language/dialects. The experimental evaluations and proof-of-concept COVID-19 case study on real data have validated the effectiveness of our proposed system in precisely distinguishing sentiments and accurately identifying hate content in both Levantine and Gulf Arabic dialects. Our findings shed light on the importance of considering the unique nature of dialects within the same language and ignoring the dialectal aspect would lead to misleading analysis.
From Words and Exercises to Wellness: Farsi Chatbot for Self-Attachment Technique
Oct 13, 2023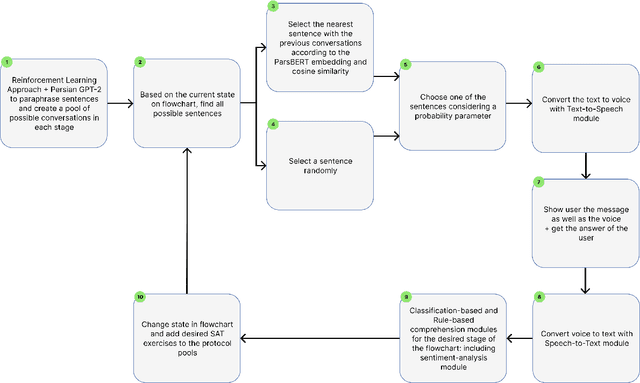
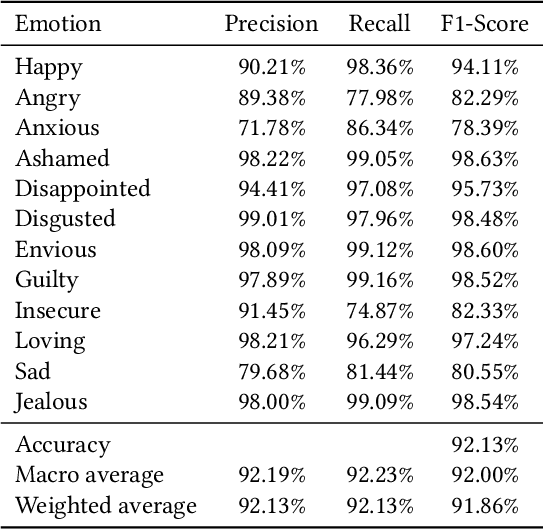
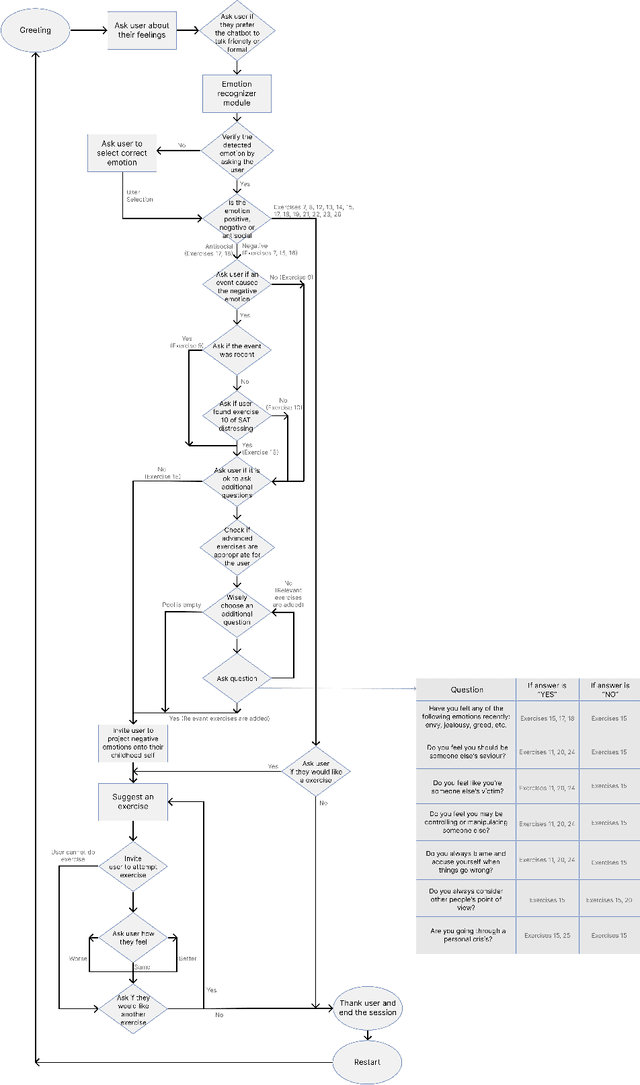

In the wake of the post-pandemic era, marked by social isolation and surging rates of depression and anxiety, conversational agents based on digital psychotherapy can play an influential role compared to traditional therapy sessions. In this work, we develop a voice-capable chatbot in Farsi to guide users through Self-Attachment (SAT), a novel, self-administered, holistic psychological technique based on attachment theory. Our chatbot uses a dynamic array of rule-based and classification-based modules to comprehend user input throughout the conversation and navigates a dialogue flowchart accordingly, recommending appropriate SAT exercises that depend on the user's emotional and mental state. In particular, we collect a dataset of over 6,000 utterances and develop a novel sentiment-analysis module that classifies user sentiment into 12 classes, with accuracy above 92%. To keep the conversation novel and engaging, the chatbot's responses are retrieved from a large dataset of utterances created with the aid of Farsi GPT-2 and a reinforcement learning approach, thus requiring minimal human annotation. Our chatbot also offers a question-answering module, called SAT Teacher, to answer users' questions about the principles of Self-Attachment. Finally, we design a cross-platform application as the bot's user interface. We evaluate our platform in a ten-day human study with N=52 volunteers from the non-clinical population, who have had over 2,000 dialogues in total with the chatbot. The results indicate that the platform was engaging to most users (75%), 72% felt better after the interactions, and 74% were satisfied with the SAT Teacher's performance.
How People Perceive The Dynamic Zero-COVID Policy: A Retrospective Analysis From The Perspective of Appraisal Theory
Sep 17, 2023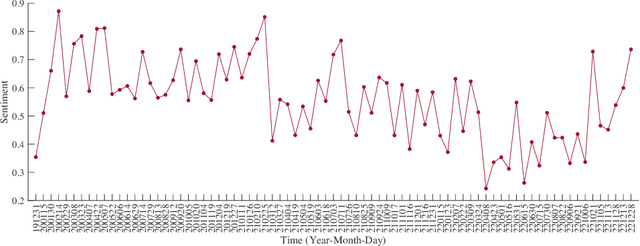
The Dynamic Zero-COVID Policy in China spanned three years and diverse emotional responses have been observed at different times. In this paper, we retrospectively analyzed public sentiments and perceptions of the policy, especially regarding how they evolved over time, and how they related to people's lived experiences. Through sentiment analysis of 2,358 collected Weibo posts, we identified four representative points, i.e., policy initialization, sharp sentiment change, lowest sentiment score, and policy termination, for an in-depth discourse analysis through the lens of appraisal theory. In the end, we reflected on the evolving public sentiments toward the Dynamic Zero-COVID Policy and proposed implications for effective epidemic prevention and control measures for future crises.
Shared and Private Information Learning in Multimodal Sentiment Analysis with Deep Modal Alignment and Self-supervised Multi-Task Learning
May 15, 2023
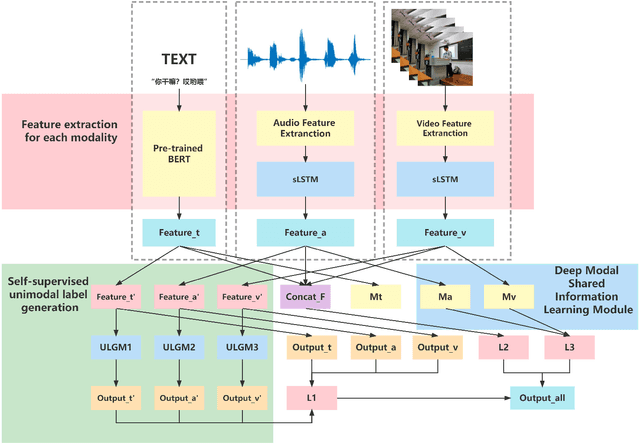
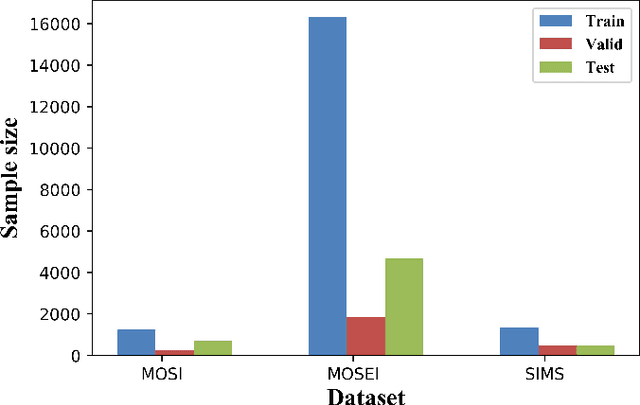
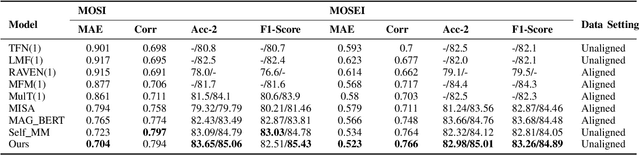
Designing an effective representation learning method for multimodal sentiment analysis tasks is a crucial research direction. The challenge lies in learning both shared and private information in a complete modal representation, which is difficult with uniform multimodal labels and a raw feature fusion approach. In this work, we propose a deep modal shared information learning module based on the covariance matrix to capture the shared information between modalities. Additionally, we use a label generation module based on a self-supervised learning strategy to capture the private information of the modalities. Our module is plug-and-play in multimodal tasks, and by changing the parameterization, it can adjust the information exchange relationship between the modes and learn the private or shared information between the specified modes. We also employ a multi-task learning strategy to help the model focus its attention on the modal differentiation training data. We provide a detailed formulation derivation and feasibility proof for the design of the deep modal shared information learning module. We conduct extensive experiments on three common multimodal sentiment analysis baseline datasets, and the experimental results validate the reliability of our model. Furthermore, we explore more combinatorial techniques for the use of the module. Our approach outperforms current state-of-the-art methods on most of the metrics of the three public datasets.