 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Reducing Computational Costs in Sentiment Analysis: Tensorized Recurrent Networks vs. Recurrent Networks
Jun 16, 2023
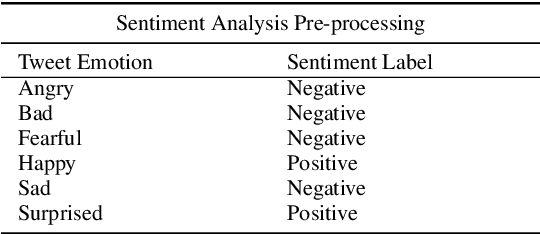
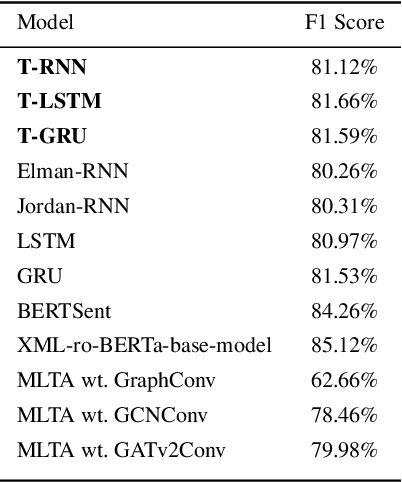
Anticipating audience reaction towards a certain text is integral to several facets of society ranging from politics, research, and commercial industries. Sentiment analysis (SA) is a useful natural language processing (NLP) technique that utilizes lexical/statistical and deep learning methods to determine whether different-sized texts exhibit positive, negative, or neutral emotions. Recurrent networks are widely used in machine-learning communities for problems with sequential data. However, a drawback of models based on Long-Short Term Memory networks and Gated Recurrent Units is the significantly high number of parameters, and thus, such models are computationally expensive. This drawback is even more significant when the available data are limited. Also, such models require significant over-parameterization and regularization to achieve optimal performance. Tensorized models represent a potential solution. In this paper, we classify the sentiment of some social media posts. We compare traditional recurrent models with their tensorized version, and we show that with the tensorized models, we reach comparable performances with respect to the traditional models while using fewer resources for the training.
Bias in Emotion Recognition with ChatGPT
Oct 18, 2023
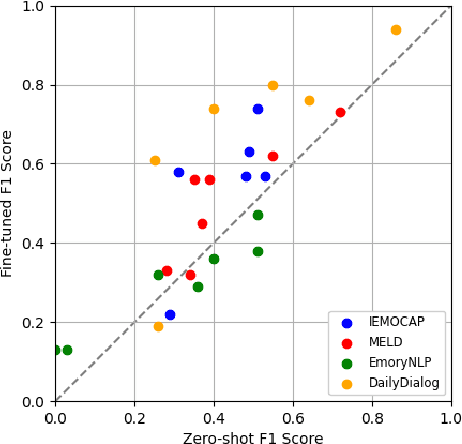

This technical report explores the ability of ChatGPT in recognizing emotions from text, which can be the basis of various applications like interactive chatbots, data annotation, and mental health analysis. While prior research has shown ChatGPT's basic ability in sentiment analysis, its performance in more nuanced emotion recognition is not yet explored. Here, we conducted experiments to evaluate its performance of emotion recognition across different datasets and emotion labels. Our findings indicate a reasonable level of reproducibility in its performance, with noticeable improvement through fine-tuning. However, the performance varies with different emotion labels and datasets, highlighting an inherent instability and possible bias. The choice of dataset and emotion labels significantly impacts ChatGPT's emotion recognition performance. This paper sheds light on the importance of dataset and label selection, and the potential of fine-tuning in enhancing ChatGPT's emotion recognition capabilities, providing a groundwork for better integration of emotion analysis in applications using ChatGPT.
Boosting Data Analytics With Synthetic Volume Expansion
Oct 27, 2023Synthetic data generation, a cornerstone of Generative Artificial Intelligence, signifies a paradigm shift in data science by addressing data scarcity and privacy while enabling unprecedented performance. As synthetic data gains prominence, questions arise concerning the accuracy of statistical methods when applied to synthetic data compared to raw data. In this article, we introduce the Synthetic Data Generation for Analytics framework. This framework employs statistical methods on high-fidelity synthetic data generated by advanced models such as tabular diffusion and Generative Pre-trained Transformer models. These models, trained on raw data, are further enhanced with insights from pertinent studies. A significant discovery within this framework is the generational effect: the error of a statistical method on synthetic data initially diminishes with added synthetic data but may eventually increase or plateau. This phenomenon, rooted in the complexities of replicating raw data distributions, highlights a "reflection point"--an optimal threshold in the size of synthetic data determined by specific error metrics. Through three illustrative case studies-sentiment analysis of texts, predictive modeling of structured data, and inference in tabular data--we demonstrate the effectiveness of this framework over traditional ones. We underline its potential to amplify various statistical methods, including gradient boosting for prediction and hypothesis testing, thereby underscoring the transformative potential of synthetic data generation in data science.
Sentiment analysis and opinion mining on E-commerce site
Nov 28, 2022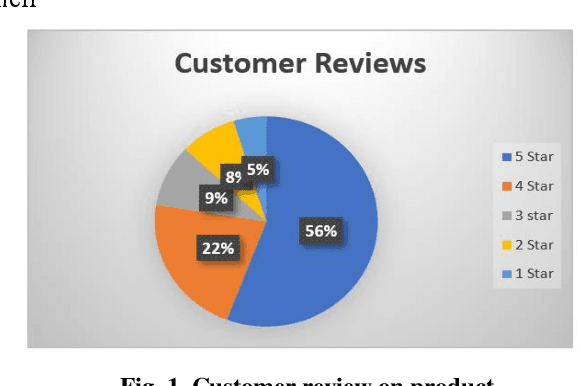
Sentiment analysis or opinion mining help to illustrate the phrase NLP (Natural Language Processing). Sentiment analysis has been the most significant topic in recent years. The goal of this study is to solve the sentiment polarity classification challenges in sentiment analysis. A broad technique for categorizing sentiment opposition is presented, along with comprehensive process explanations. With the results of the analysis, both sentence-level classification and review-level categorization are conducted. Finally, we discuss our plans for future sentiment analysis research.
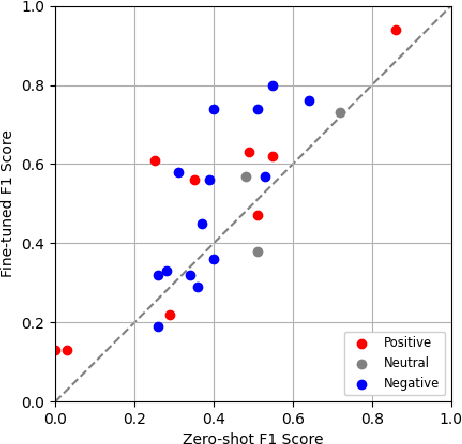
tagE: Enabling an Embodied Agent to Understand Human Instructions
Oct 24, 2023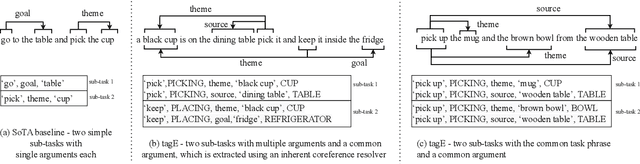
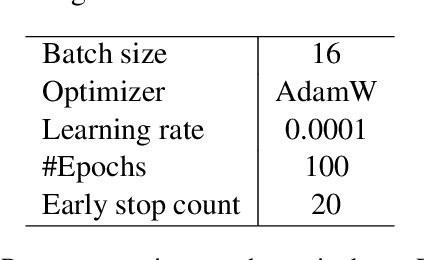

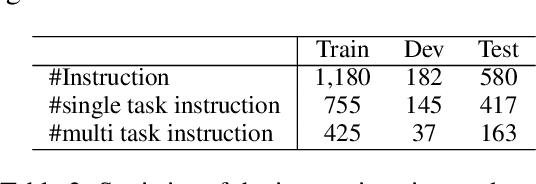
Natural language serves as the primary mode of communication when an intelligent agent with a physical presence engages with human beings. While a plethora of research focuses on natural language understanding (NLU), encompassing endeavors such as sentiment analysis, intent prediction, question answering, and summarization, the scope of NLU directed at situations necessitating tangible actions by an embodied agent remains limited. The inherent ambiguity and incompleteness inherent in natural language present challenges for intelligent agents striving to decipher human intention. To tackle this predicament head-on, we introduce a novel system known as task and argument grounding for Embodied agents (tagE). At its core, our system employs an inventive neural network model designed to extract a series of tasks from complex task instructions expressed in natural language. Our proposed model adopts an encoder-decoder framework enriched with nested decoding to effectively extract tasks and their corresponding arguments from these intricate instructions. These extracted tasks are then mapped (or grounded) to the robot's established collection of skills, while the arguments find grounding in objects present within the environment. To facilitate the training and evaluation of our system, we have curated a dataset featuring complex instructions. The results of our experiments underscore the prowess of our approach, as it outperforms robust baseline models.
RuSentNE-2023: Evaluating Entity-Oriented Sentiment Analysis on Russian News Texts
May 28, 2023

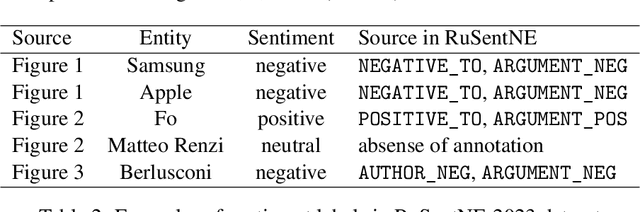

The paper describes the RuSentNE-2023 evaluation devoted to targeted sentiment analysis in Russian news texts. The task is to predict sentiment towards a named entity in a single sentence. The dataset for RuSentNE-2023 evaluation is based on the Russian news corpus RuSentNE having rich sentiment-related annotation. The corpus is annotated with named entities and sentiments towards these entities, along with related effects and emotional states. The evaluation was organized using the CodaLab competition framework. The main evaluation measure was macro-averaged measure of positive and negative classes. The best results achieved were of 66% Macro F-measure (Positive+Negative classes). We also tested ChatGPT on the test set from our evaluation and found that the zero-shot answers provided by ChatGPT reached 60% of the F-measure, which corresponds to 4th place in the evaluation. ChatGPT also provided detailed explanations of its conclusion. This can be considered as quite high for zero-shot application.
ViSoBERT: A Pre-Trained Language Model for Vietnamese Social Media Text Processing
Oct 17, 2023English and Chinese, known as resource-rich languages, have witnessed the strong development of transformer-based language models for natural language processing tasks. Although Vietnam has approximately 100M people speaking Vietnamese, several pre-trained models, e.g., PhoBERT, ViBERT, and vELECTRA, performed well on general Vietnamese NLP tasks, including POS tagging and named entity recognition. These pre-trained language models are still limited to Vietnamese social media tasks. In this paper, we present the first monolingual pre-trained language model for Vietnamese social media texts, ViSoBERT, which is pre-trained on a large-scale corpus of high-quality and diverse Vietnamese social media texts using XLM-R architecture. Moreover, we explored our pre-trained model on five important natural language downstream tasks on Vietnamese social media texts: emotion recognition, hate speech detection, sentiment analysis, spam reviews detection, and hate speech spans detection. Our experiments demonstrate that ViSoBERT, with far fewer parameters, surpasses the previous state-of-the-art models on multiple Vietnamese social media tasks. Our ViSoBERT model is available\footnote{\url{https://huggingface.co/uitnlp/visobert}} only for research purposes.
BanglaBook: A Large-scale Bangla Dataset for Sentiment Analysis from Book Reviews
May 11, 2023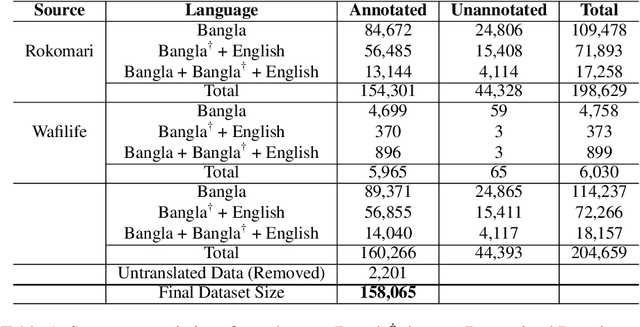
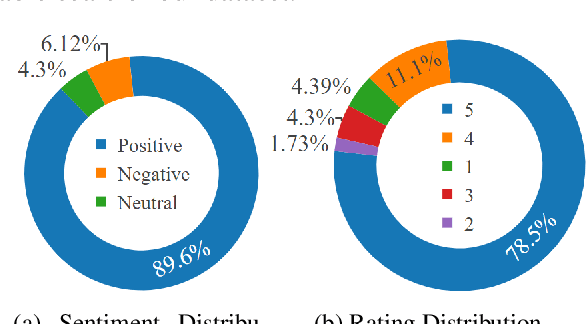
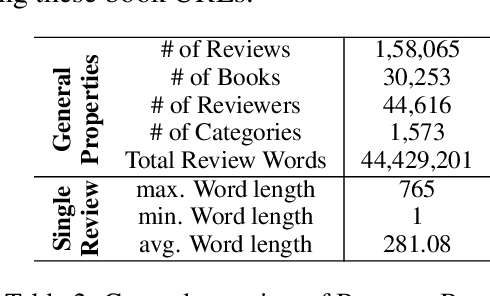
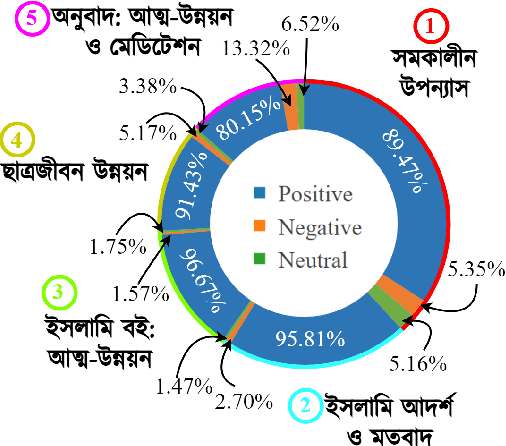
The analysis of consumer sentiment, as expressed through reviews, can provide a wealth of insight regarding the quality of a product. While the study of sentiment analysis has been widely explored in many popular languages, relatively less attention has been given to the Bangla language, mostly due to a lack of relevant data and cross-domain adaptability. To address this limitation, we present BanglaBook, a large-scale dataset of Bangla book reviews consisting of 158,065 samples classified into three broad categories: positive, negative, and neutral. We provide a detailed statistical analysis of the dataset and employ a range of machine learning models to establish baselines including SVM, LSTM, and Bangla-BERT. Our findings demonstrate a substantial performance advantage of pre-trained models over models that rely on manually crafted features, emphasizing the necessity for additional training resources in this domain. Additionally, we conduct an in-depth error analysis by examining sentiment unigrams, which may provide insight into common classification errors in under-resourced languages like Bangla. Our codes and data are publicly available at https://github.com/mohsinulkabir14/BanglaBook.
Assessing Look-Ahead Bias in Stock Return Predictions Generated By GPT Sentiment Analysis
Sep 29, 2023Large language models (LLMs), including ChatGPT, can extract profitable trading signals from the sentiment in news text. However, backtesting such strategies poses a challenge because LLMs are trained on many years of data, and backtesting produces biased results if the training and backtesting periods overlap. This bias can take two forms: a look-ahead bias, in which the LLM may have specific knowledge of the stock returns that followed a news article, and a distraction effect, in which general knowledge of the companies named interferes with the measurement of a text's sentiment. We investigate these sources of bias through trading strategies driven by the sentiment of financial news headlines. We compare trading performance based on the original headlines with de-biased strategies in which we remove the relevant company's identifiers from the text. In-sample (within the LLM training window), we find, surprisingly, that the anonymized headlines outperform, indicating that the distraction effect has a greater impact than look-ahead bias. This tendency is particularly strong for larger companies--companies about which we expect an LLM to have greater general knowledge. Out-of-sample, look-ahead bias is not a concern but distraction remains possible. Our proposed anonymization procedure is therefore potentially useful in out-of-sample implementation, as well as for de-biased backtesting.
Classifying COVID-19 Related Tweets for Fake News Detection and Sentiment Analysis with BERT-based Models
Apr 02, 2023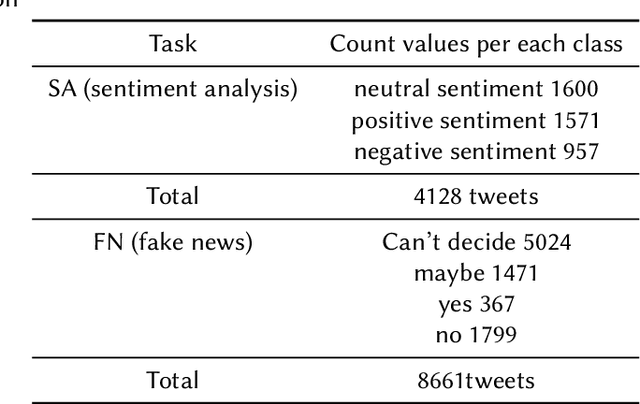
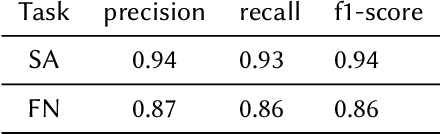
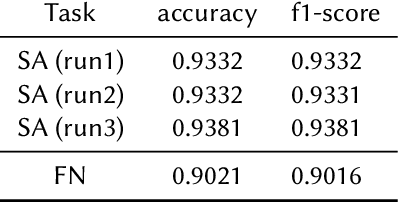
The present paper is about the participation of our team "techno" on CERIST'22 shared tasks. We used an available dataset "task1.c" related to covid-19 pandemic. It comprises 4128 tweets for sentiment analysis task and 8661 tweets for fake news detection task. We used natural language processing tools with the combination of the most renowned pre-trained language models BERT (Bidirectional Encoder Representations from Transformers). The results shows the efficacy of pre-trained language models as we attained an accuracy of 0.93 for the sentiment analysis task and 0.90 for the fake news detection task.