 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Sentiment analysis and opinion mining on educational data: A survey
Feb 08, 2023
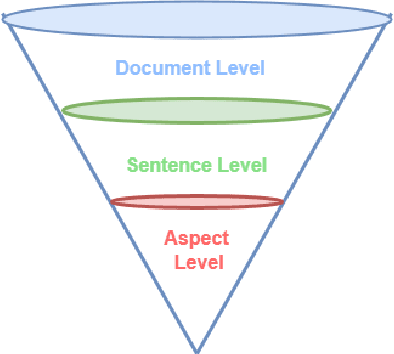
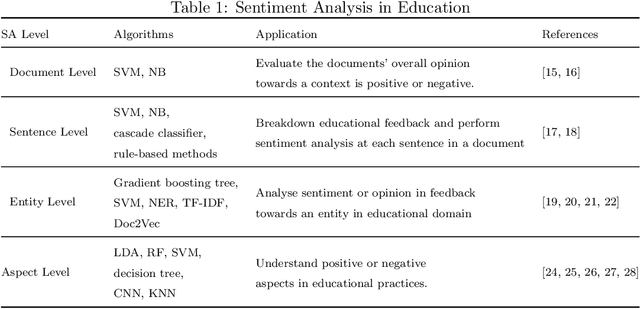
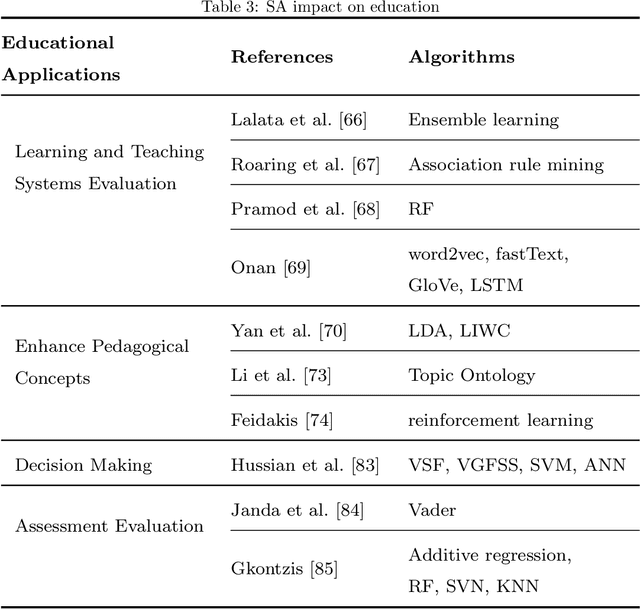
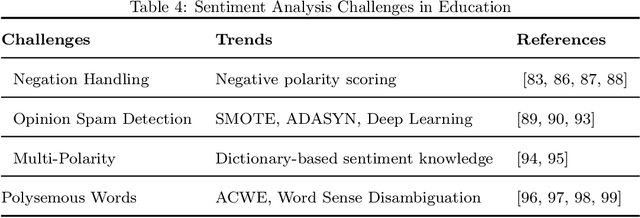
Sentiment analysis AKA opinion mining is one of the most widely used NLP applications to identify human intentions from their reviews. In the education sector, opinion mining is used to listen to student opinions and enhance their learning-teaching practices pedagogically. With advancements in sentiment annotation techniques and AI methodologies, student comments can be labelled with their sentiment orientation without much human intervention. In this review article, (1) we consider the role of emotional analysis in education from four levels: document level, sentence level, entity level, and aspect level, (2) sentiment annotation techniques including lexicon-based and corpus-based approaches for unsupervised annotations are explored, (3) the role of AI in sentiment analysis with methodologies like machine learning, deep learning, and transformers are discussed, (4) the impact of sentiment analysis on educational procedures to enhance pedagogy, decision-making, and evaluation are presented. Educational institutions have been widely invested to build sentiment analysis tools and process their student feedback to draw their opinions and insights. Applications built on sentiment analysis of student feedback are reviewed in this study. Challenges in sentiment analysis like multi-polarity, polysemous, negation words, and opinion spam detection are explored and their trends in the research space are discussed. The future directions of sentiment analysis in education are discussed.
FinEntity: Entity-level Sentiment Classification for Financial Texts
Oct 19, 2023In the financial domain, conducting entity-level sentiment analysis is crucial for accurately assessing the sentiment directed toward a specific financial entity. To our knowledge, no publicly available dataset currently exists for this purpose. In this work, we introduce an entity-level sentiment classification dataset, called \textbf{FinEntity}, that annotates financial entity spans and their sentiment (positive, neutral, and negative) in financial news. We document the dataset construction process in the paper. Additionally, we benchmark several pre-trained models (BERT, FinBERT, etc.) and ChatGPT on entity-level sentiment classification. In a case study, we demonstrate the practical utility of using FinEntity in monitoring cryptocurrency markets. The data and code of FinEntity is available at \url{https://github.com/yixuantt/FinEntity}
UBC-DLNLP at SemEval-2023 Task 12: Impact of Transfer Learning on African Sentiment Analysis
Apr 25, 2023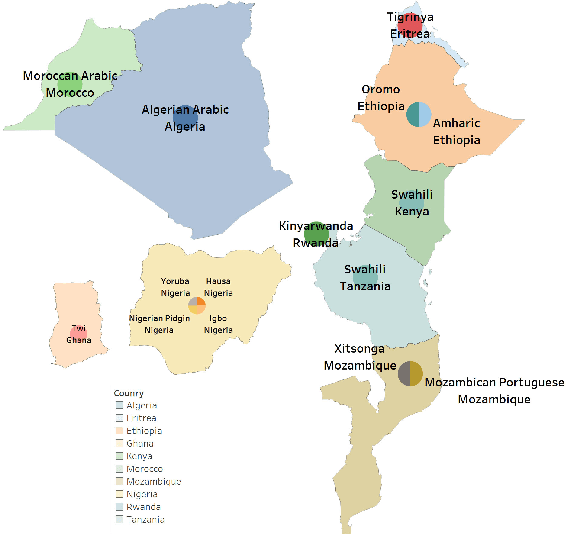
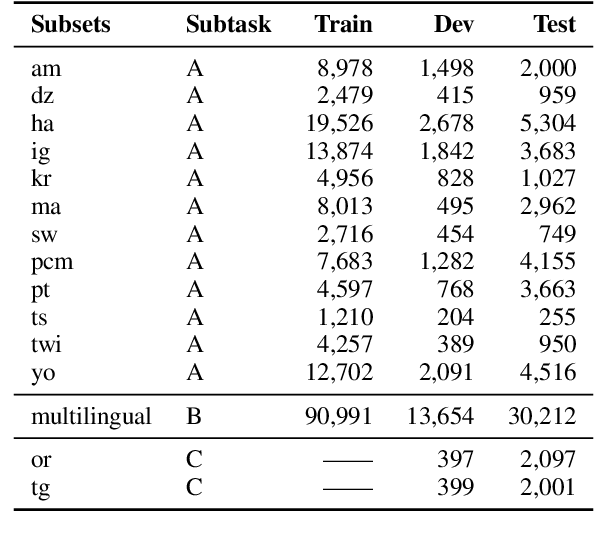
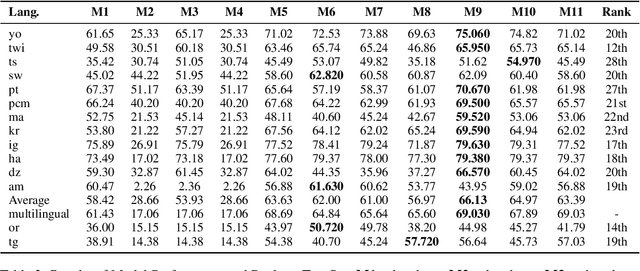
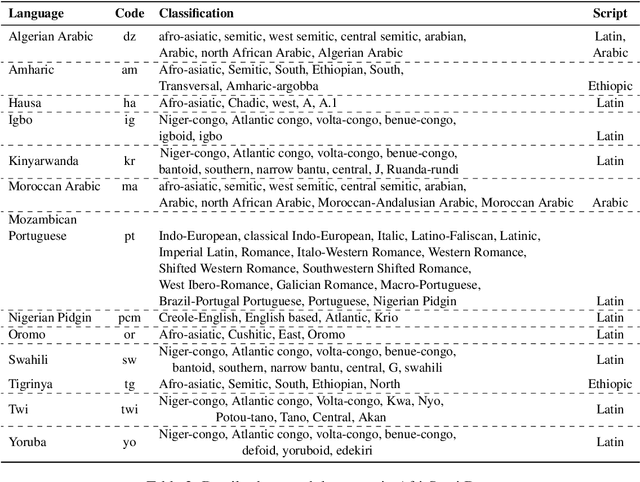
We describe our contribution to the SemEVAl 2023 AfriSenti-SemEval shared task, where we tackle the task of sentiment analysis in 14 different African languages. We develop both monolingual and multilingual models under a full supervised setting (subtasks A and B). We also develop models for the zero-shot setting (subtask C). Our approach involves experimenting with transfer learning using six language models, including further pertaining of some of these models as well as a final finetuning stage. Our best performing models achieve an F1-score of 70.36 on development data and an F1-score of 66.13 on test data. Unsurprisingly, our results demonstrate the effectiveness of transfer learning and fine-tuning techniques for sentiment analysis across multiple languages. Our approach can be applied to other sentiment analysis tasks in different languages and domains.
Longer Fixations, More Computation: Gaze-Guided Recurrent Neural Networks
Oct 31, 2023Humans read texts at a varying pace, while machine learning models treat each token in the same way in terms of a computational process. Therefore, we ask, does it help to make models act more like humans? In this paper, we convert this intuition into a set of novel models with fixation-guided parallel RNNs or layers and conduct various experiments on language modeling and sentiment analysis tasks to test their effectiveness, thus providing empirical validation for this intuition. Our proposed models achieve good performance on the language modeling task, considerably surpassing the baseline model. In addition, we find that, interestingly, the fixation duration predicted by neural networks bears some resemblance to humans' fixation. Without any explicit guidance, the model makes similar choices to humans. We also investigate the reasons for the differences between them, which explain why "model fixations" are often more suitable than human fixations, when used to guide language models.
Dynamic Multi-Scale Context Aggregation for Conversational Aspect-Based Sentiment Quadruple Analysis
Sep 27, 2023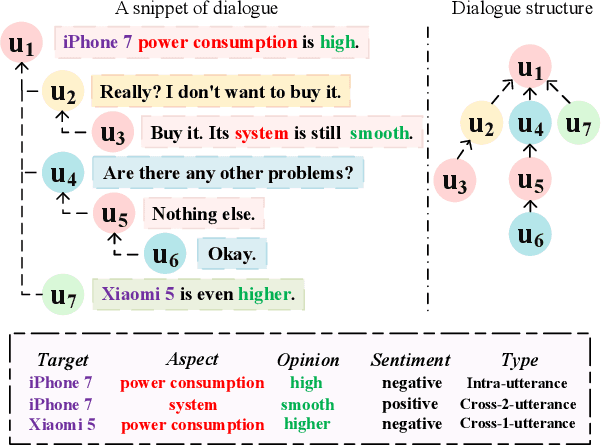

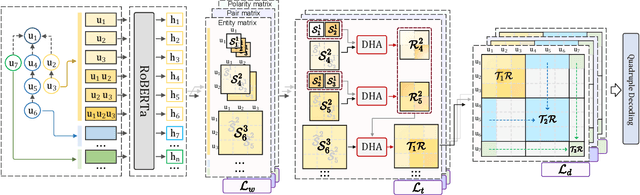
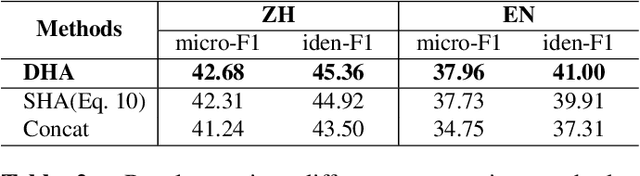
Conversational aspect-based sentiment quadruple analysis (DiaASQ) aims to extract the quadruple of target-aspect-opinion-sentiment within a dialogue. In DiaASQ, a quadruple's elements often cross multiple utterances. This situation complicates the extraction process, emphasizing the need for an adequate understanding of conversational context and interactions. However, existing work independently encodes each utterance, thereby struggling to capture long-range conversational context and overlooking the deep inter-utterance dependencies. In this work, we propose a novel Dynamic Multi-scale Context Aggregation network (DMCA) to address the challenges. Specifically, we first utilize dialogue structure to generate multi-scale utterance windows for capturing rich contextual information. After that, we design a Dynamic Hierarchical Aggregation module (DHA) to integrate progressive cues between them. In addition, we form a multi-stage loss strategy to improve model performance and generalization ability. Extensive experimental results show that the DMCA model outperforms baselines significantly and achieves state-of-the-art performance.
Retrofitting Light-weight Language Models for Emotions using Supervised Contrastive Learning
Oct 29, 2023We present a novel retrofitting method to induce emotion aspects into pre-trained language models (PLMs) such as BERT and RoBERTa. Our method updates pre-trained network weights using contrastive learning so that the text fragments exhibiting similar emotions are encoded nearby in the representation space, and the fragments with different emotion content are pushed apart. While doing so, it also ensures that the linguistic knowledge already present in PLMs is not inadvertently perturbed. The language models retrofitted by our method, i.e., BERTEmo and RoBERTaEmo, produce emotion-aware text representations, as evaluated through different clustering and retrieval metrics. For the downstream tasks on sentiment analysis and sarcasm detection, they perform better than their pre-trained counterparts (about 1% improvement in F1-score) and other existing approaches. Additionally, a more significant boost in performance is observed for the retrofitted models over pre-trained ones in few-shot learning setting.
GPT-4V(ision) as A Social Media Analysis Engine
Nov 13, 2023Recent research has offered insights into the extraordinary capabilities of Large Multimodal Models (LMMs) in various general vision and language tasks. There is growing interest in how LMMs perform in more specialized domains. Social media content, inherently multimodal, blends text, images, videos, and sometimes audio. Understanding social multimedia content remains a challenging problem for contemporary machine learning frameworks. In this paper, we explore GPT-4V(ision)'s capabilities for social multimedia analysis. We select five representative tasks, including sentiment analysis, hate speech detection, fake news identification, demographic inference, and political ideology detection, to evaluate GPT-4V. Our investigation begins with a preliminary quantitative analysis for each task using existing benchmark datasets, followed by a careful review of the results and a selection of qualitative samples that illustrate GPT-4V's potential in understanding multimodal social media content. GPT-4V demonstrates remarkable efficacy in these tasks, showcasing strengths such as joint understanding of image-text pairs, contextual and cultural awareness, and extensive commonsense knowledge. Despite the overall impressive capacity of GPT-4V in the social media domain, there remain notable challenges. GPT-4V struggles with tasks involving multilingual social multimedia comprehension and has difficulties in generalizing to the latest trends in social media. Additionally, it exhibits a tendency to generate erroneous information in the context of evolving celebrity and politician knowledge, reflecting the known hallucination problem. The insights gleaned from our findings underscore a promising future for LMMs in enhancing our comprehension of social media content and its users through the analysis of multimodal information.
Automated Ableism: An Exploration of Explicit Disability Biases in Sentiment and Toxicity Analysis Models
Jul 18, 2023
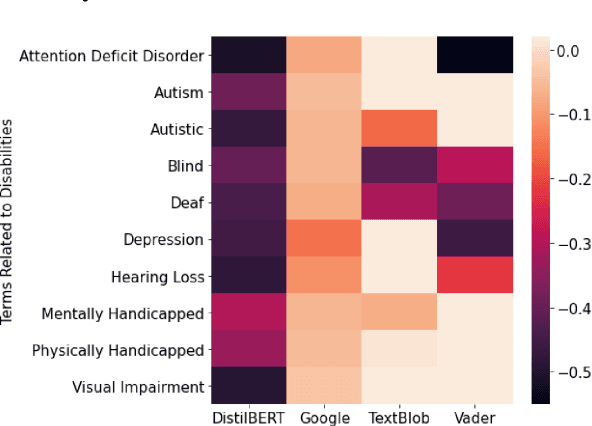


We analyze sentiment analysis and toxicity detection models to detect the presence of explicit bias against people with disability (PWD). We employ the bias identification framework of Perturbation Sensitivity Analysis to examine conversations related to PWD on social media platforms, specifically Twitter and Reddit, in order to gain insight into how disability bias is disseminated in real-world social settings. We then create the \textit{Bias Identification Test in Sentiment} (BITS) corpus to quantify explicit disability bias in any sentiment analysis and toxicity detection models. Our study utilizes BITS to uncover significant biases in four open AIaaS (AI as a Service) sentiment analysis tools, namely TextBlob, VADER, Google Cloud Natural Language API, DistilBERT and two toxicity detection models, namely two versions of Toxic-BERT. Our findings indicate that all of these models exhibit statistically significant explicit bias against PWD.
* TrustNLP at ACL 2023
Tracking public attitudes toward ChatGPT on Twitter using sentiment analysis and topic modeling
Jun 22, 2023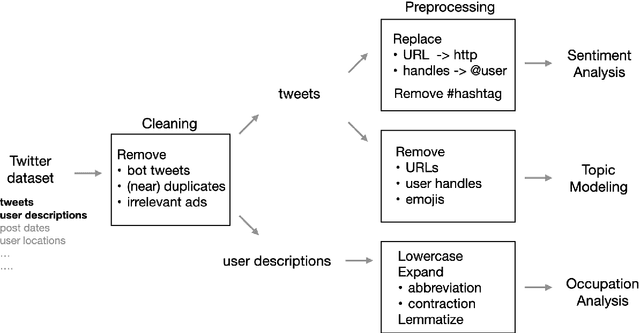
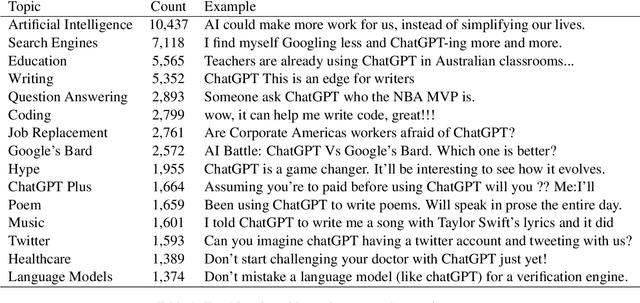
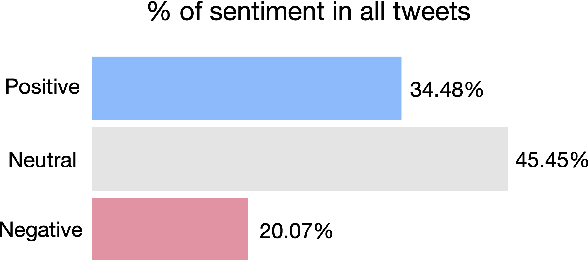
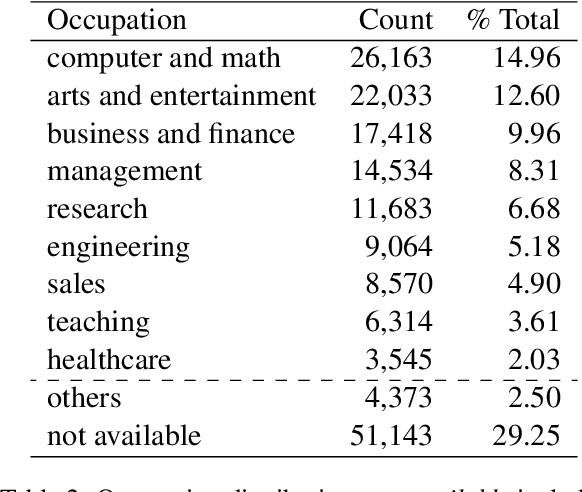
ChatGPT sets a new record with the fastest-growing user base, as a chatbot powered by a large language model (LLM). While it demonstrates state-of-the-art capabilities in a variety of language-generating tasks, it also raises widespread public concerns regarding its societal impact. In this paper, we utilize natural language processing approaches to investigate the public attitudes towards ChatGPT by applying sentiment analysis and topic modeling techniques to Twitter data. Our result shows that the overall sentiment is largely neutral to positive, which also holds true across different occupation groups. Among a wide range of topics mentioned in tweets, the most popular topics are Artificial Intelligence, Search Engines, Education, Writing, and Question Answering.