 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
AlbMoRe: A Corpus of Movie Reviews for Sentiment Analysis in Albanian
Jun 14, 2023



Lack of available resources such as text corpora for low-resource languages seriously hinders research on natural language processing and computational linguistics. This paper presents AlbMoRe, a corpus of 800 sentiment annotated movie reviews in Albanian. Each text is labeled as positive or negative and can be used for sentiment analysis research. Preliminary results based on traditional machine learning classifiers trained with the AlbMoRe samples are also reported. They can serve as comparison baselines for future research experiments.
GIELLM: Japanese General Information Extraction Large Language Model Utilizing Mutual Reinforcement Effect
Nov 12, 2023Information Extraction (IE) stands as a cornerstone in natural language processing, traditionally segmented into distinct sub-tasks. The advent of Large Language Models (LLMs) heralds a paradigm shift, suggesting the feasibility of a singular model addressing multiple IE subtasks. In this vein, we introduce the General Information Extraction Large Language Model (GIELLM), which integrates text Classification, Sentiment Analysis, Named Entity Recognition, Relation Extraction, and Event Extraction using a uniform input-output schema. This innovation marks the first instance of a model simultaneously handling such a diverse array of IE subtasks. Notably, the GIELLM leverages the Mutual Reinforcement Effect (MRE), enhancing performance in integrated tasks compared to their isolated counterparts. Our experiments demonstrate State-of-the-Art (SOTA) results in five out of six Japanese mixed datasets, significantly surpassing GPT-3.5-Turbo. Further, an independent evaluation using the novel Text Classification Relation and Event Extraction(TCREE) dataset corroborates the synergistic advantages of MRE in text and word classification. This breakthrough paves the way for most IE subtasks to be subsumed under a singular LLM framework. Specialized fine-tune task-specific models are no longer needed.
ALERTA-Net: A Temporal Distance-Aware Recurrent Networks for Stock Movement and Volatility Prediction
Oct 28, 2023For both investors and policymakers, forecasting the stock market is essential as it serves as an indicator of economic well-being. To this end, we harness the power of social media data, a rich source of public sentiment, to enhance the accuracy of stock market predictions. Diverging from conventional methods, we pioneer an approach that integrates sentiment analysis, macroeconomic indicators, search engine data, and historical prices within a multi-attention deep learning model, masterfully decoding the complex patterns inherent in the data. We showcase the state-of-the-art performance of our proposed model using a dataset, specifically curated by us, for predicting stock market movements and volatility.
AoM: Detecting Aspect-oriented Information for Multimodal Aspect-Based Sentiment Analysis
May 31, 2023
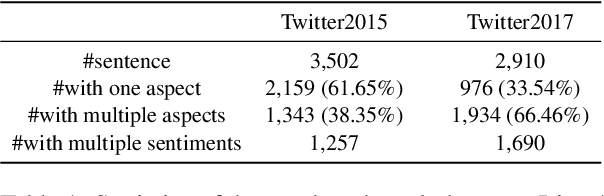
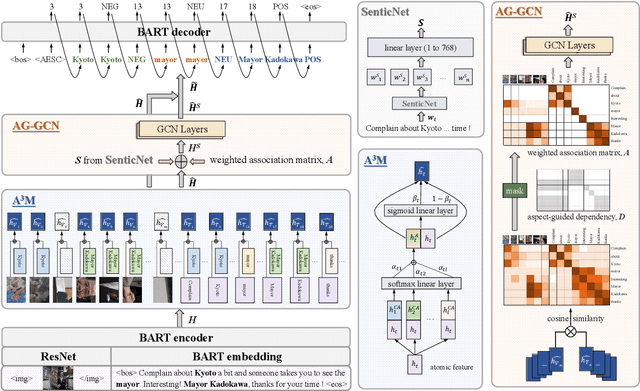
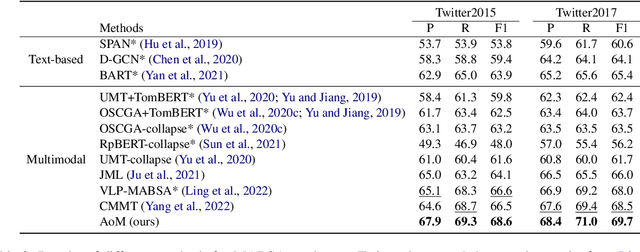
Multimodal aspect-based sentiment analysis (MABSA) aims to extract aspects from text-image pairs and recognize their sentiments. Existing methods make great efforts to align the whole image to corresponding aspects. However, different regions of the image may relate to different aspects in the same sentence, and coarsely establishing image-aspect alignment will introduce noise to aspect-based sentiment analysis (i.e., visual noise). Besides, the sentiment of a specific aspect can also be interfered by descriptions of other aspects (i.e., textual noise). Considering the aforementioned noises, this paper proposes an Aspect-oriented Method (AoM) to detect aspect-relevant semantic and sentiment information. Specifically, an aspect-aware attention module is designed to simultaneously select textual tokens and image blocks that are semantically related to the aspects. To accurately aggregate sentiment information, we explicitly introduce sentiment embedding into AoM, and use a graph convolutional network to model the vision-text and text-text interaction. Extensive experiments demonstrate the superiority of AoM to existing methods. The source code is publicly released at https://github.com/SilyRab/AoM.
FinXABSA: Explainable Finance through Aspect-Based Sentiment Analysis
Mar 16, 2023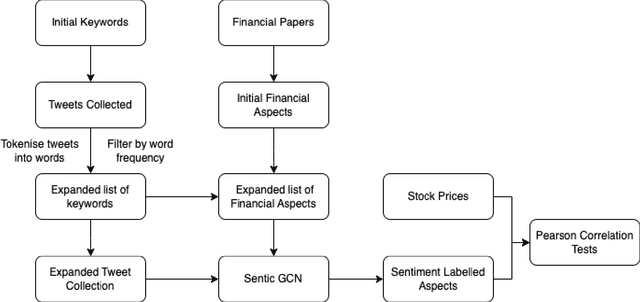
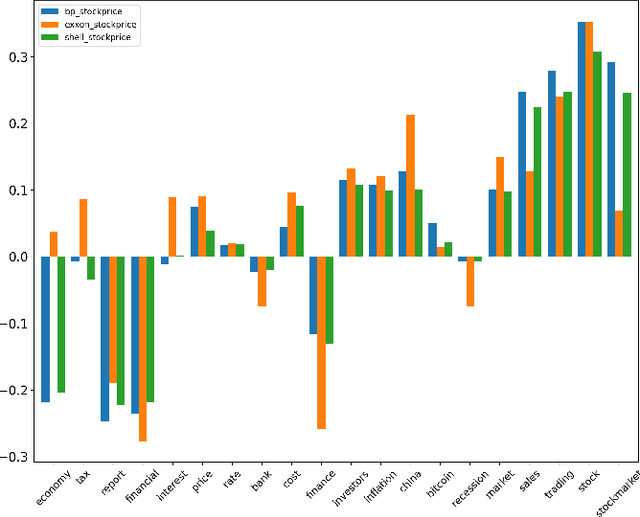
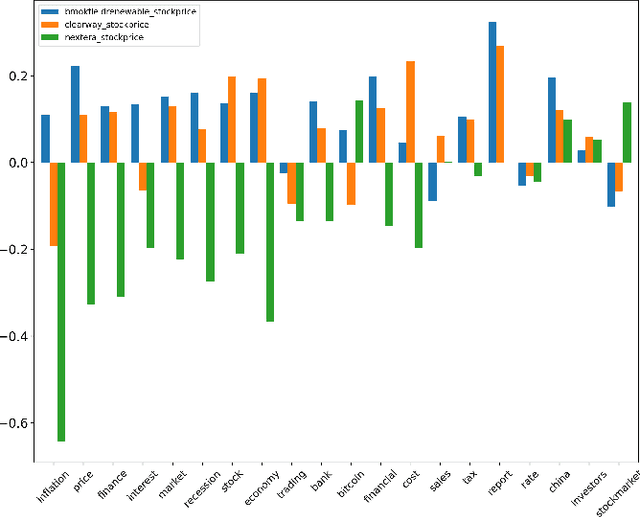
This paper presents a novel approach for explainability in financial analysis by utilizing the Pearson correlation coefficient to establish a relationship between aspect-based sentiment analysis and stock prices. The proposed methodology involves constructing an aspect list from financial news articles and analyzing sentiment intensity scores for each aspect. These scores are then compared to the stock prices for the relevant companies using the Pearson coefficient to determine any significant correlations. The results indicate that the proposed approach provides a more detailed and accurate understanding of the relationship between sentiment analysis and stock prices, which can be useful for investors and financial analysts in making informed decisions. Additionally, this methodology offers a transparent and interpretable way to explain the sentiment analysis results and their impact on stock prices. Overall, the findings of this paper demonstrate the importance of explainability in financial analysis and highlight the potential benefits of utilizing the Pearson coefficient for analyzing aspect-based sentiment analysis and stock prices. The proposed approach offers a valuable tool for understanding the complex relationships between financial news sentiment and stock prices, providing a new perspective on the financial market and aiding in making informed investment decisions.
Efficient Sentiment Analysis: A Resource-Aware Evaluation of Feature Extraction Techniques, Ensembling, and Deep Learning Models
Aug 03, 2023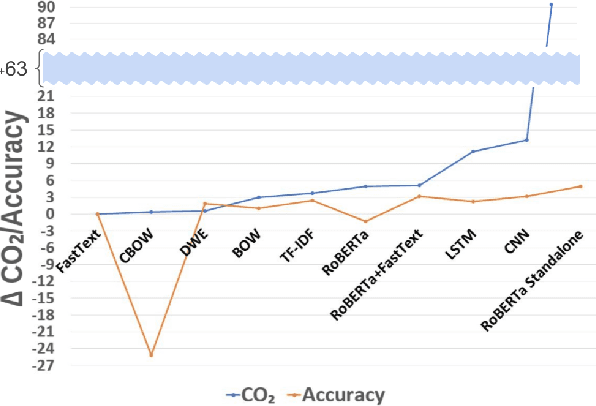
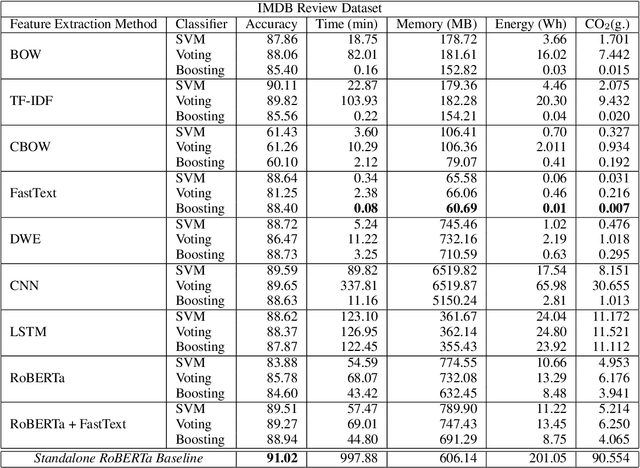
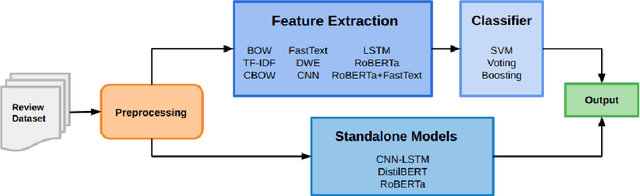
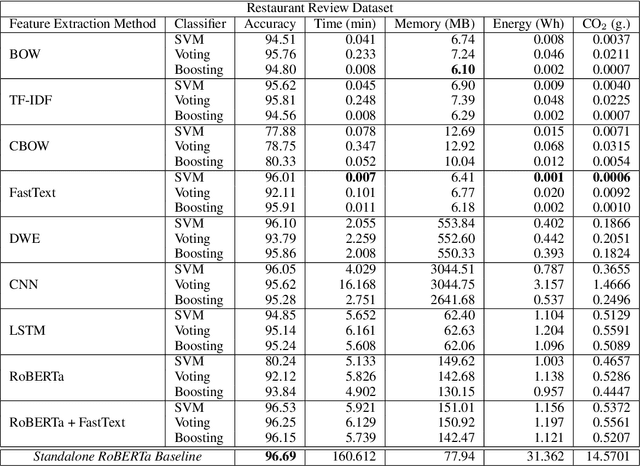
While reaching for NLP systems that maximize accuracy, other important metrics of system performance are often overlooked. Prior models are easily forgotten despite their possible suitability in settings where large computing resources are unavailable or relatively more costly. In this paper, we perform a broad comparative evaluation of document-level sentiment analysis models with a focus on resource costs that are important for the feasibility of model deployment and general climate consciousness. Our experiments consider different feature extraction techniques, the effect of ensembling, task-specific deep learning modeling, and domain-independent large language models (LLMs). We find that while a fine-tuned LLM achieves the best accuracy, some alternate configurations provide huge (up to 24, 283 *) resource savings for a marginal (<1%) loss in accuracy. Furthermore, we find that for smaller datasets, the differences in accuracy shrink while the difference in resource consumption grows further.
Heuristics-Driven Link-of-Analogy Prompting: Enhancing Large Language Models for Document-Level Event Argument Extraction
Nov 11, 2023In this study, we investigate in-context learning (ICL) in document-level event argument extraction (EAE). The paper identifies key challenges in this problem, including example selection, context length limitation, abundance of event types, and the limitation of Chain-of-Thought (CoT) prompting in non-reasoning tasks. To address these challenges, we introduce the Heuristic-Driven Link-of-Analogy (HD-LoA) prompting method. Specifically, we hypothesize and validate that LLMs learn task-specific heuristics from demonstrations via ICL. Building upon this hypothesis, we introduce an explicit heuristic-driven demonstration construction approach, which transforms the haphazard example selection process into a methodical method that emphasizes task heuristics. Additionally, inspired by the analogical reasoning of human, we propose the link-of-analogy prompting, which enables LLMs to process new situations by drawing analogies to known situations, enhancing their adaptability. Extensive experiments show that our method outperforms the existing prompting methods and few-shot supervised learning methods, exhibiting F1 score improvements of 4.53% and 9.38% on the document-level EAE dataset. Furthermore, when applied to sentiment analysis and natural language inference tasks, the HD-LoA prompting achieves accuracy gains of 2.87% and 2.63%, indicating its effectiveness across different tasks.
New Adversarial Image Detection Based on Sentiment Analysis
May 03, 2023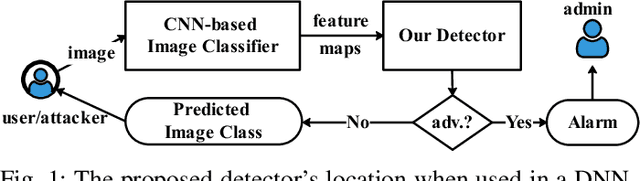
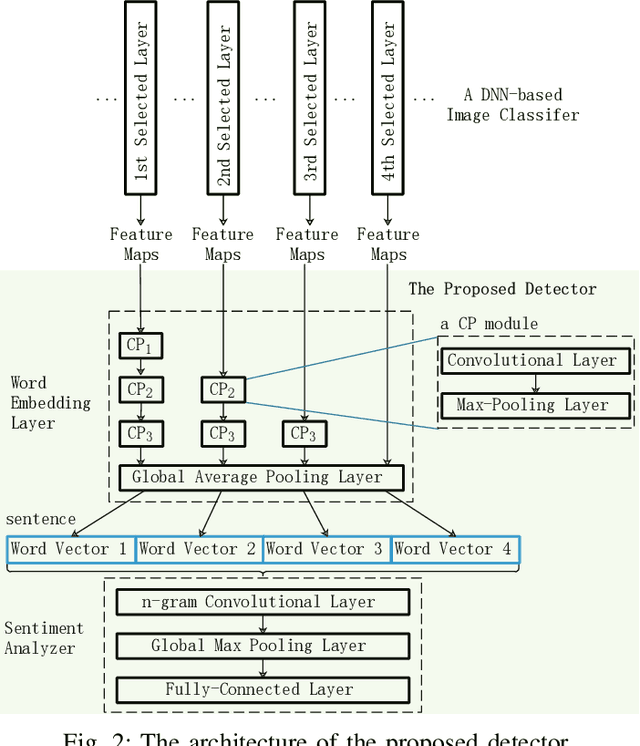
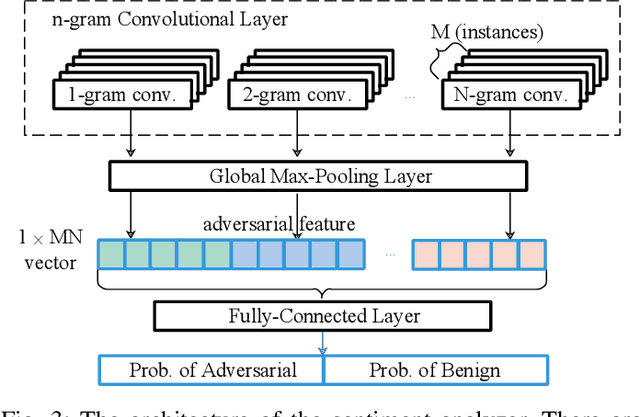

Deep Neural Networks (DNNs) are vulnerable to adversarial examples, while adversarial attack models, e.g., DeepFool, are on the rise and outrunning adversarial example detection techniques. This paper presents a new adversarial example detector that outperforms state-of-the-art detectors in identifying the latest adversarial attacks on image datasets. Specifically, we propose to use sentiment analysis for adversarial example detection, qualified by the progressively manifesting impact of an adversarial perturbation on the hidden-layer feature maps of a DNN under attack. Accordingly, we design a modularized embedding layer with the minimum learnable parameters to embed the hidden-layer feature maps into word vectors and assemble sentences ready for sentiment analysis. Extensive experiments demonstrate that the new detector consistently surpasses the state-of-the-art detection algorithms in detecting the latest attacks launched against ResNet and Inception neutral networks on the CIFAR-10, CIFAR-100 and SVHN datasets. The detector only has about 2 million parameters, and takes shorter than 4.6 milliseconds to detect an adversarial example generated by the latest attack models using a Tesla K80 GPU card.
Interpretable multimodal sentiment analysis based on textual modality descriptions by using large-scale language models
May 12, 2023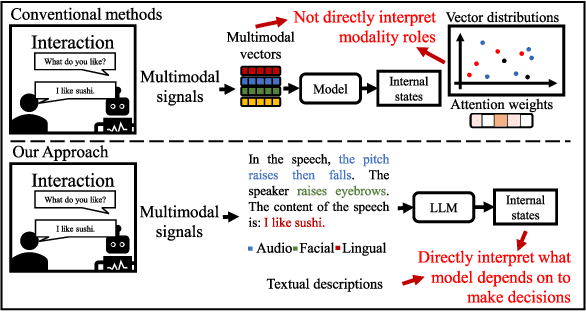

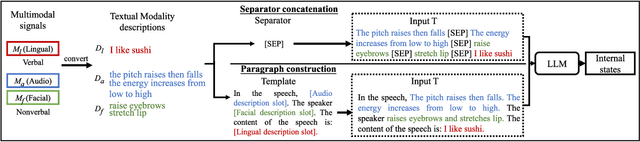
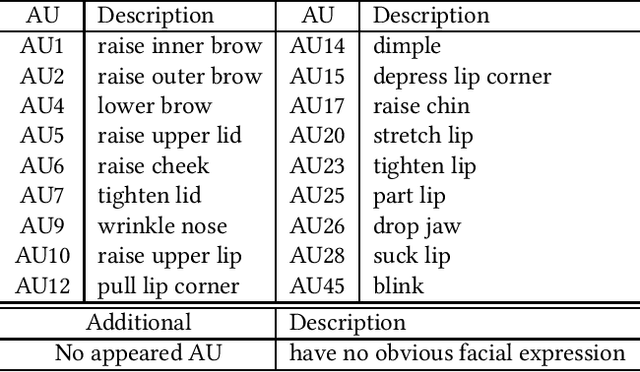
Multimodal sentiment analysis is an important area for understanding the user's internal states. Deep learning methods were effective, but the problem of poor interpretability has gradually gained attention. Previous works have attempted to use attention weights or vector distributions to provide interpretability. However, their explanations were not intuitive and can be influenced by different trained models. This study proposed a novel approach to provide interpretability by converting nonverbal modalities into text descriptions and by using large-scale language models for sentiment predictions. This provides an intuitive approach to directly interpret what models depend on with respect to making decisions from input texts, thus significantly improving interpretability. Specifically, we convert descriptions based on two feature patterns for the audio modality and discrete action units for the facial modality. Experimental results on two sentiment analysis tasks demonstrated that the proposed approach maintained, or even improved effectiveness for sentiment analysis compared to baselines using conventional features, with the highest improvement of 2.49% on the F1 score. The results also showed that multimodal descriptions have similar characteristics on fusing modalities as those of conventional fusion methods. The results demonstrated that the proposed approach is interpretable and effective for multimodal sentiment analysis.
mahaNLP: A Marathi Natural Language Processing Library
Nov 05, 2023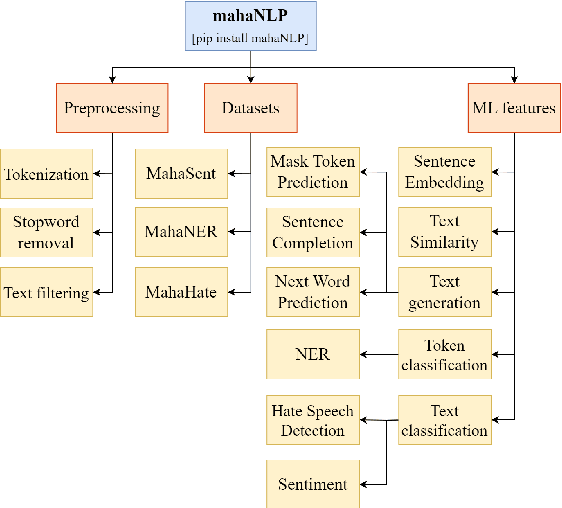
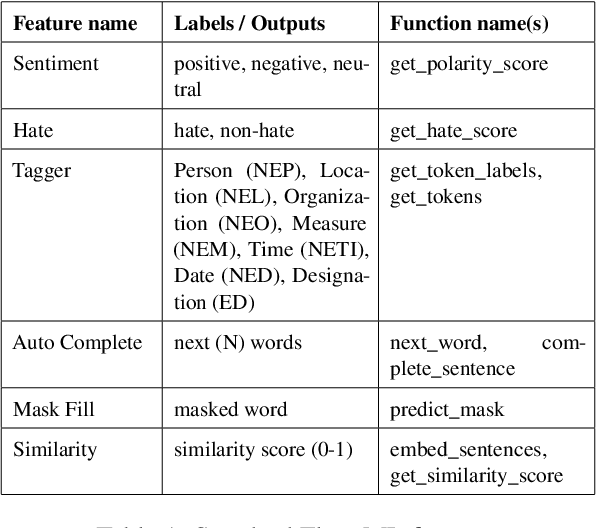
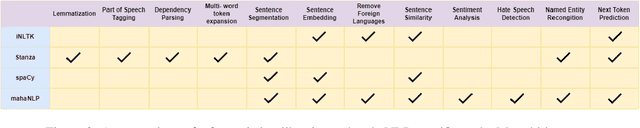

We present mahaNLP, an open-source natural language processing (NLP) library specifically built for the Marathi language. It aims to enhance the support for the low-resource Indian language Marathi in the field of NLP. It is an easy-to-use, extensible, and modular toolkit for Marathi text analysis built on state-of-the-art MahaBERT-based transformer models. Our work holds significant importance as other existing Indic NLP libraries provide basic Marathi processing support and rely on older models with restricted performance. Our toolkit stands out by offering a comprehensive array of NLP tasks, encompassing both fundamental preprocessing tasks and advanced NLP tasks like sentiment analysis, NER, hate speech detection, and sentence completion. This paper focuses on an overview of the mahaNLP framework, its features, and its usage. This work is a part of the L3Cube MahaNLP initiative, more information about it can be found at https://github.com/l3cube-pune/MarathiNLP .