 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Benchmarking Large Language Model Volatility
Nov 26, 2023
The impact of non-deterministic outputs from Large Language Models (LLMs) is not well examined for financial text understanding tasks. Through a compelling case study on investing in the US equity market via news sentiment analysis, we uncover substantial variability in sentence-level sentiment classification results, underscoring the innate volatility of LLM outputs. These uncertainties cascade downstream, leading to more significant variations in portfolio construction and return. While tweaking the temperature parameter in the language model decoder presents a potential remedy, it comes at the expense of stifled creativity. Similarly, while ensembling multiple outputs mitigates the effect of volatile outputs, it demands a notable computational investment. This work furnishes practitioners with invaluable insights for adeptly navigating uncertainty in the integration of LLMs into financial decision-making, particularly in scenarios dictated by non-deterministic information.
Unveiling Public Perceptions: Machine Learning-Based Sentiment Analysis of COVID-19 Vaccines in India
Nov 26, 2023In March 2020, the World Health Organisation declared COVID-19 a global pandemic as it spread to nearly every country. By mid-2021, India had introduced three vaccines: Covishield, Covaxin, and Sputnik. To ensure successful vaccination in a densely populated country like India, understanding public sentiment was crucial. Social media, particularly Reddit with over 430 million users, played a vital role in disseminating information. This study employs data mining techniques to analyze Reddit data and gauge Indian sentiments towards COVID-19 vaccines. Using Python's Text Blob library, comments are annotated to assess general sentiments. Results show that most Reddit users in India expressed neutrality about vaccination, posing a challenge for the Indian government's efforts to vaccinate a significant portion of the population.
Instruct-FinGPT: Financial Sentiment Analysis by Instruction Tuning of General-Purpose Large Language Models
Jun 22, 2023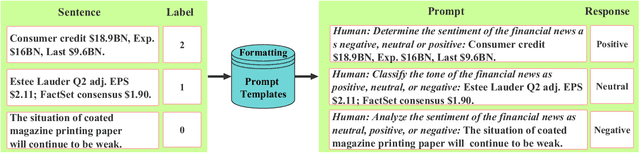
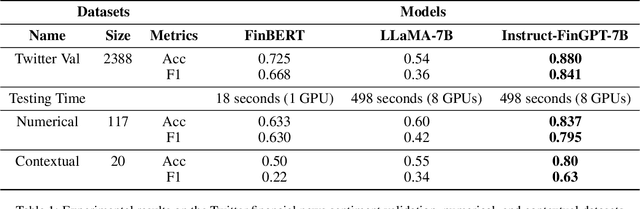
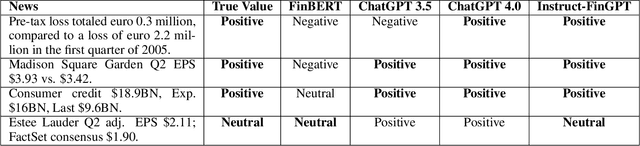
Sentiment analysis is a vital tool for uncovering insights from financial articles, news, and social media, shaping our understanding of market movements. Despite the impressive capabilities of large language models (LLMs) in financial natural language processing (NLP), they still struggle with accurately interpreting numerical values and grasping financial context, limiting their effectiveness in predicting financial sentiment. In this paper, we introduce a simple yet effective instruction tuning approach to address these issues. By transforming a small portion of supervised financial sentiment analysis data into instruction data and fine-tuning a general-purpose LLM with this method, we achieve remarkable advancements in financial sentiment analysis. In the experiment, our approach outperforms state-of-the-art supervised sentiment analysis models, as well as widely used LLMs like ChatGPT and LLaMAs, particularly in scenarios where numerical understanding and contextual comprehension are vital.
Covid-19 Public Sentiment Analysis for Indian Tweets Classification
Aug 01, 2023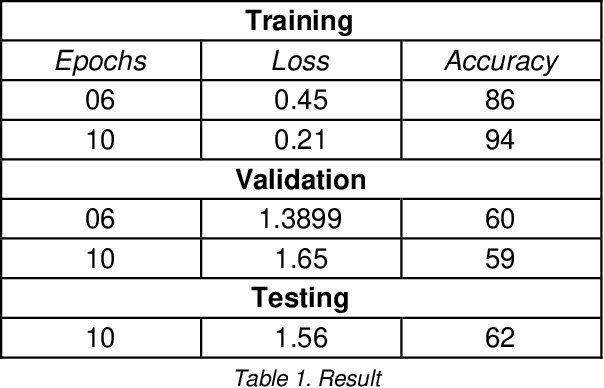
When any extraordinary event takes place in the world wide area, it is the social media that acts as the fastest carrier of the news along with the consequences dealt with that event. One can gather much information through social networks regarding the sentiments, behavior, and opinions of the people. In this paper, we focus mainly on sentiment analysis of twitter data of India which comprises of COVID-19 tweets. We show how Twitter data has been extracted and then run sentimental analysis queries on it. This is helpful to analyze the information in the tweets where opinions are highly unstructured, heterogeneous, and are either positive or negative or neutral in some cases.
BLP 2023 Task 2: Sentiment Analysis
Oct 24, 2023We present an overview of the BLP Sentiment Shared Task, organized as part of the inaugural BLP 2023 workshop, co-located with EMNLP 2023. The task is defined as the detection of sentiment in a given piece of social media text. This task attracted interest from 71 participants, among whom 29 and 30 teams submitted systems during the development and evaluation phases, respectively. In total, participants submitted 597 runs. However, a total of 15 teams submitted system description papers. The range of approaches in the submitted systems spans from classical machine learning models, fine-tuning pre-trained models, to leveraging Large Language Model (LLMs) in zero- and few-shot settings. In this paper, we provide a detailed account of the task setup, including dataset development and evaluation setup. Additionally, we provide a brief overview of the systems submitted by the participants. All datasets and evaluation scripts from the shared task have been made publicly available for the research community, to foster further research in this domain
Zero- and Few-Shot Prompting with LLMs: A Comparative Study with Fine-tuned Models for Bangla Sentiment Analysis
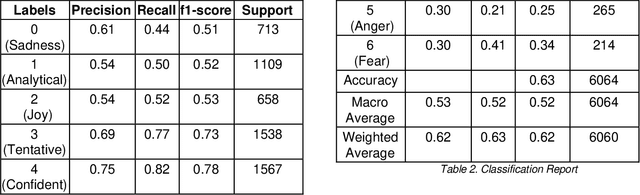
Aug 21, 2023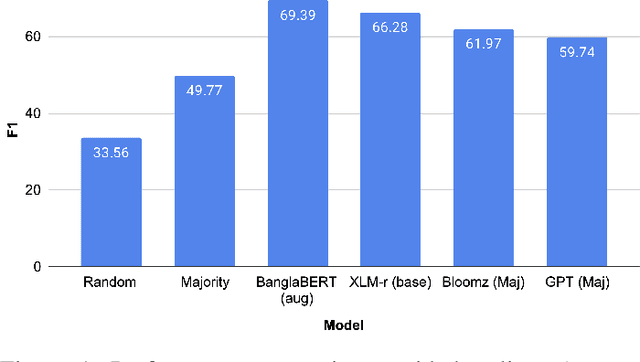
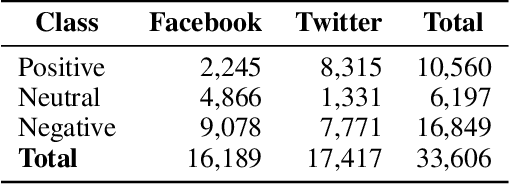
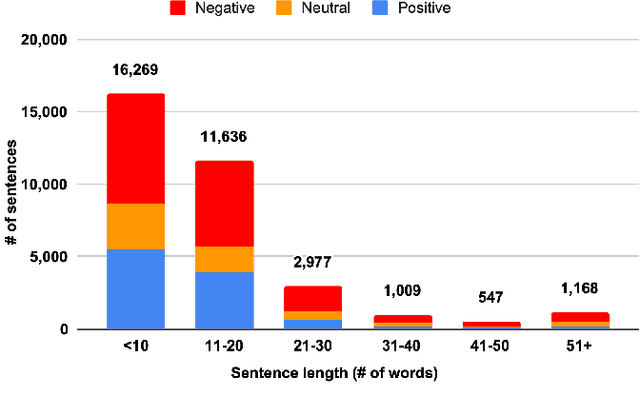
The rapid expansion of the digital world has propelled sentiment analysis into a critical tool across diverse sectors such as marketing, politics, customer service, and healthcare. While there have been significant advancements in sentiment analysis for widely spoken languages, low-resource languages, such as Bangla, remain largely under-researched due to resource constraints. Furthermore, the recent unprecedented performance of Large Language Models (LLMs) in various applications highlights the need to evaluate them in the context of low-resource languages. In this study, we present a sizeable manually annotated dataset encompassing 33,605 Bangla news tweets and Facebook comments. We also investigate zero- and few-shot in-context learning with several language models, including Flan-T5, GPT-4, and Bloomz, offering a comparative analysis against fine-tuned models. Our findings suggest that monolingual transformer-based models consistently outperform other models, even in zero and few-shot scenarios. To foster continued exploration, we intend to make this dataset and our research tools publicly available to the broader research community. In the spirit of further research, we plan to make this dataset and our experimental resources publicly accessible to the wider research community.
Towards Arabic Multimodal Dataset for Sentiment Analysis
Jun 10, 2023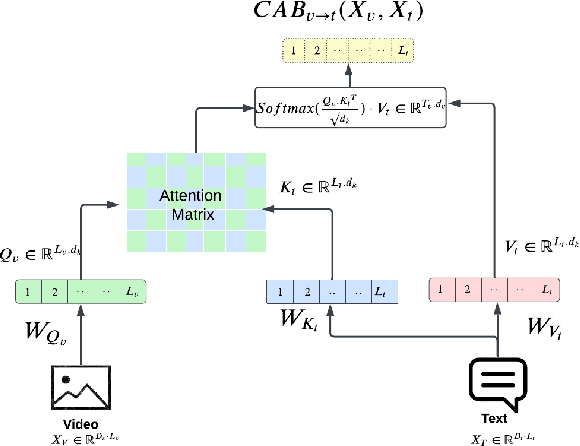

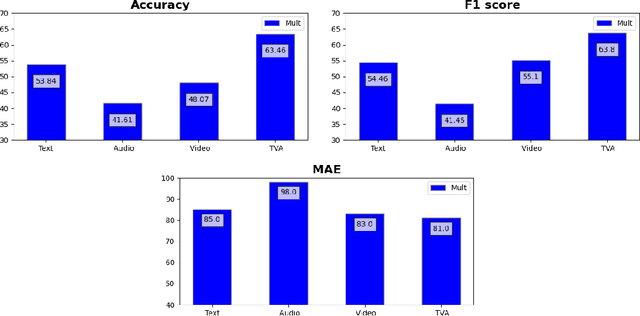
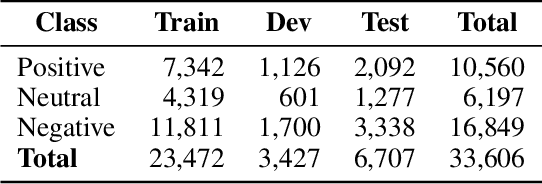
Multimodal Sentiment Analysis (MSA) has recently become a centric research direction for many real-world applications. This proliferation is due to the fact that opinions are central to almost all human activities and are key influencers of our behaviors. In addition, the recent deployment of Deep Learning-based (DL) models has proven their high efficiency for a wide range of Western languages. In contrast, Arabic DL-based multimodal sentiment analysis (MSA) is still in its infantile stage due, mainly, to the lack of standard datasets. In this paper, our investigation is twofold. First, we design a pipeline that helps building our Arabic Multimodal dataset leveraging both state-of-the-art transformers and feature extraction tools within word alignment techniques. Thereafter, we validate our dataset using state-of-the-art transformer-based model dealing with multimodality. Despite the small size of the outcome dataset, experiments show that Arabic multimodality is very promising
Constructing Colloquial Dataset for Persian Sentiment Analysis of Social Microblogs
Jun 22, 2023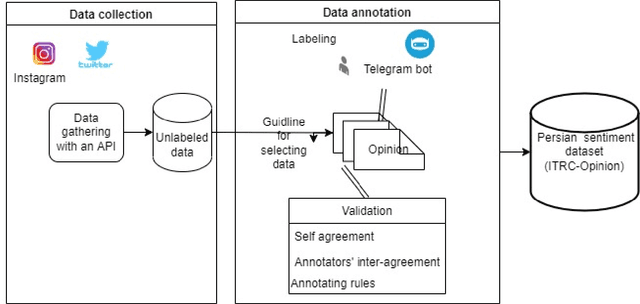

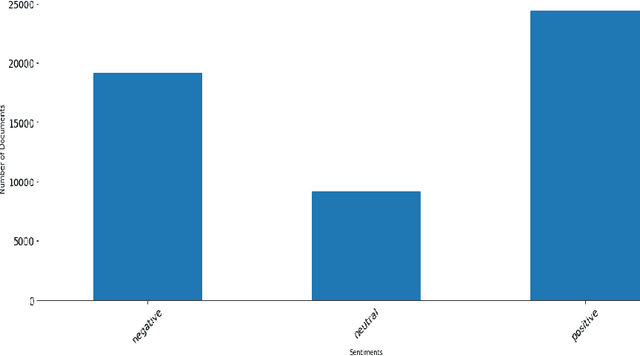
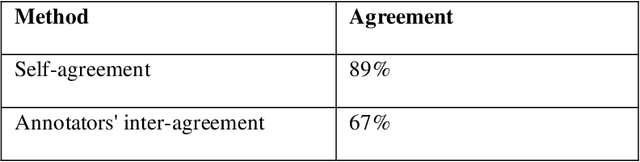
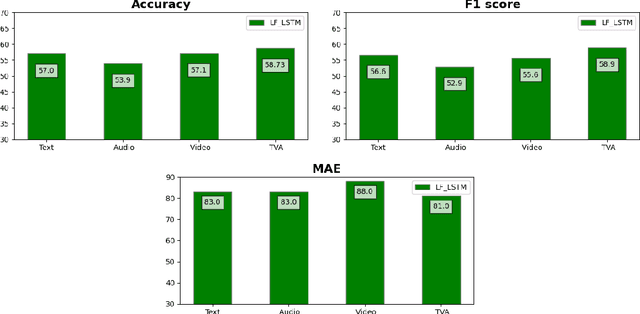
Introduction: Microblogging websites have massed rich data sources for sentiment analysis and opinion mining. In this regard, sentiment classification has frequently proven inefficient because microblog posts typically lack syntactically consistent terms and representatives since users on these social networks do not like to write lengthy statements. Also, there are some limitations to low-resource languages. The Persian language has exceptional characteristics and demands unique annotated data and models for the sentiment analysis task, which are distinctive from text features within the English dialect. Method: This paper first constructs a user opinion dataset called ITRC-Opinion by collaborative environment and insource way. Our dataset contains 60,000 informal and colloquial Persian texts from social microblogs such as Twitter and Instagram. Second, this study proposes a new deep convolutional neural network (CNN) model for more effective sentiment analysis of colloquial text in social microblog posts. The constructed datasets are used to evaluate the presented model. Furthermore, some models, such as LSTM, CNN-RNN, BiLSTM, and BiGRU with different word embeddings, including Fasttext, Glove, and Word2vec, investigated our dataset and evaluated the results. Results: The results demonstrate the benefit of our dataset and the proposed model (72% accuracy), displaying meaningful improvement in sentiment classification performance.
General Debiasing for Multimodal Sentiment Analysis
Aug 07, 2023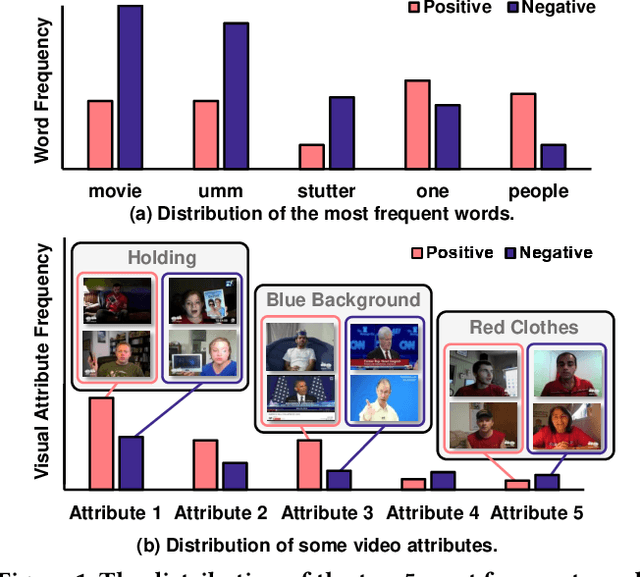

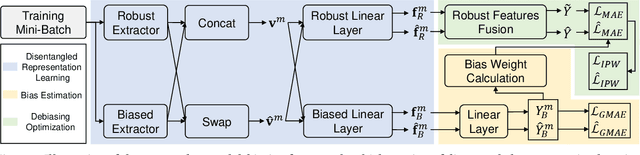
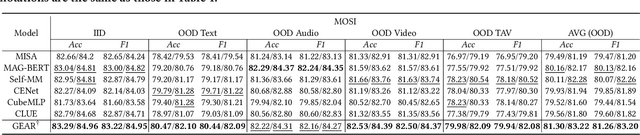
Existing work on Multimodal Sentiment Analysis (MSA) utilizes multimodal information for prediction yet unavoidably suffers from fitting the spurious correlations between multimodal features and sentiment labels. For example, if most videos with a blue background have positive labels in a dataset, the model will rely on such correlations for prediction, while "blue background" is not a sentiment-related feature. To address this problem, we define a general debiasing MSA task, which aims to enhance the Out-Of-Distribution (OOD) generalization ability of MSA models by reducing their reliance on spurious correlations. To this end, we propose a general debiasing framework based on Inverse Probability Weighting (IPW), which adaptively assigns small weights to the samples with larger bias (i.e., the severer spurious correlations). The key to this debiasing framework is to estimate the bias of each sample, which is achieved by two steps: 1) disentangling the robust features and biased features in each modality, and 2) utilizing the biased features to estimate the bias. Finally, we employ IPW to reduce the effects of large-biased samples, facilitating robust feature learning for sentiment prediction. To examine the model's generalization ability, we keep the original testing sets on two benchmarks and additionally construct multiple unimodal and multimodal OOD testing sets. The empirical results demonstrate the superior generalization ability of our proposed framework. We have released the code and data to facilitate the reproduction https://github.com/Teng-Sun/GEAR.
Optimal Strategies to Perform Multilingual Analysis of Social Content for a Novel Dataset in the Tourism Domain
Nov 20, 2023The rising influence of social media platforms in various domains, including tourism, has highlighted the growing need for efficient and automated natural language processing (NLP) approaches to take advantage of this valuable resource. However, the transformation of multilingual, unstructured, and informal texts into structured knowledge often poses significant challenges. In this work, we evaluate and compare few-shot, pattern-exploiting and fine-tuning machine learning techniques on large multilingual language models (LLMs) to establish the best strategy to address the lack of annotated data for 3 common NLP tasks in the tourism domain: (1) Sentiment Analysis, (2) Named Entity Recognition, and (3) Fine-grained Thematic Concept Extraction (linked to a semantic resource). Furthermore, we aim to ascertain the quantity of annotated examples required to achieve good performance in those 3 tasks, addressing a common challenge encountered by NLP researchers in the construction of domain-specific datasets. Extensive experimentation on a newly collected and annotated multilingual (French, English, and Spanish) dataset composed of tourism-related tweets shows that current few-shot learning techniques allow us to obtain competitive results for all three tasks with very little annotation data: 5 tweets per label (15 in total) for Sentiment Analysis, 10% of the tweets for location detection (around 160) and 13% (200 approx.) of the tweets annotated with thematic concepts, a highly fine-grained sequence labeling task based on an inventory of 315 classes. This comparative analysis, grounded in a novel dataset, paves the way for applying NLP to new domain-specific applications, reducing the need for manual annotations and circumventing the complexities of rule-based, ad hoc solutions.