 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
An Extended Variational Mode Decomposition Algorithm Developed Speech Emotion Recognition Performance
Dec 18, 2023
Emotion recognition (ER) from speech signals is a robust approach since it cannot be imitated like facial expression or text based sentiment analysis. Valuable information underlying the emotions are significant for human-computer interactions enabling intelligent machines to interact with sensitivity in the real world. Previous ER studies through speech signal processing have focused exclusively on associations between different signal mode decomposition methods and hidden informative features. However, improper decomposition parameter selections lead to informative signal component losses due to mode duplicating and mixing. In contrast, the current study proposes VGG-optiVMD, an empowered variational mode decomposition algorithm, to distinguish meaningful speech features and automatically select the number of decomposed modes and optimum balancing parameter for the data fidelity constraint by assessing their effects on the VGG16 flattening output layer. Various feature vectors were employed to train the VGG16 network on different databases and assess VGG-optiVMD reproducibility and reliability. One, two, and three-dimensional feature vectors were constructed by concatenating Mel-frequency cepstral coefficients, Chromagram, Mel spectrograms, Tonnetz diagrams, and spectral centroids. Results confirmed a synergistic relationship between the fine-tuning of the signal sample rate and decomposition parameters with classification accuracy, achieving state-of-the-art 96.09% accuracy in predicting seven emotions on the Berlin EMO-DB database.
* 12 pages
Twitter Sentiment Analysis of Covid Vacciness
Nov 08, 2023In this paper, we look at a database of tweets sorted by various keywords that could indicate the users sentiment towards covid vaccines. With social media becoming such a prevalent source of opinion, sorting and ranking tweets that hold important information such as opinions on covid vaccines is of utmost importance. Two different ranking scales were used, and ranking a tweet in this way could represent the difference between an opinion being lost and an opinion being featured on the site, which affects the decisions and behavior of people, and why researchers were interested in it. Using natural language processing techniques, our aim is to determine and categorize opinions about covid vaccines with the highest accuracy possible.
Leveraging ChatGPT As Text Annotation Tool For Sentiment Analysis
Jun 18, 2023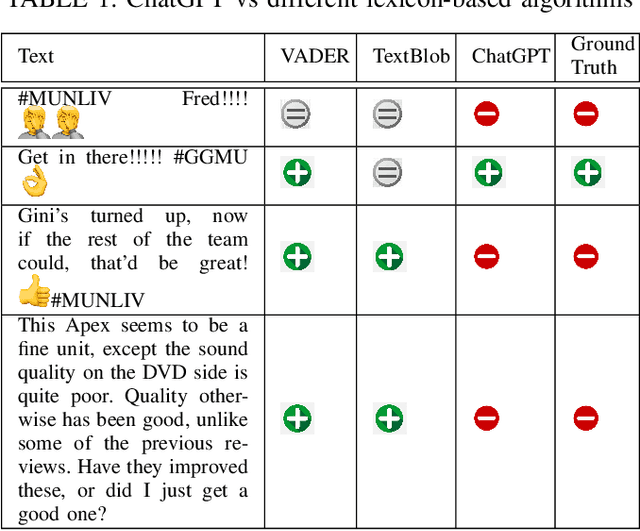
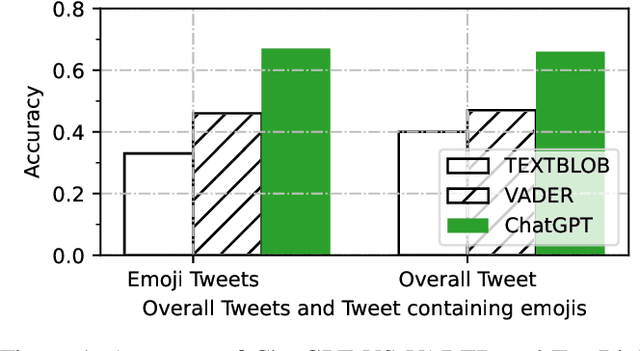
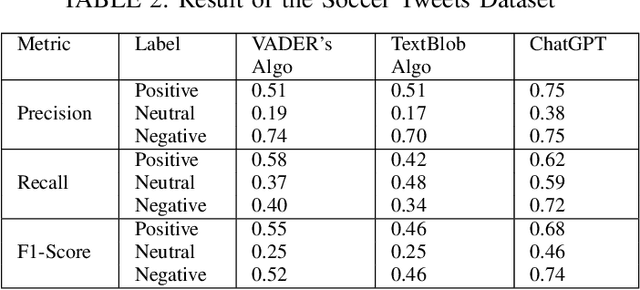
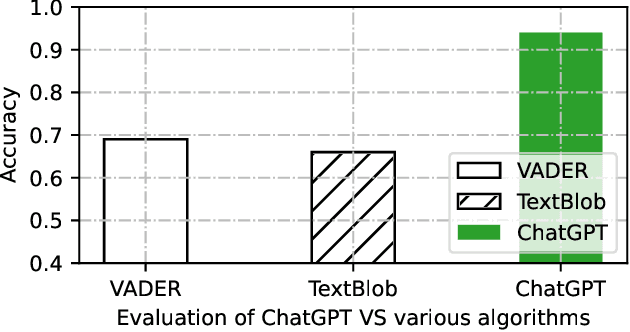
Sentiment analysis is a well-known natural language processing task that involves identifying the emotional tone or polarity of a given piece of text. With the growth of social media and other online platforms, sentiment analysis has become increasingly crucial for businesses and organizations seeking to monitor and comprehend customer feedback as well as opinions. Supervised learning algorithms have been popularly employed for this task, but they require human-annotated text to create the classifier. To overcome this challenge, lexicon-based tools have been used. A drawback of lexicon-based algorithms is their reliance on pre-defined sentiment lexicons, which may not capture the full range of sentiments in natural language. ChatGPT is a new product of OpenAI and has emerged as the most popular AI product. It can answer questions on various topics and tasks. This study explores the use of ChatGPT as a tool for data labeling for different sentiment analysis tasks. It is evaluated on two distinct sentiment analysis datasets with varying purposes. The results demonstrate that ChatGPT outperforms other lexicon-based unsupervised methods with significant improvements in overall accuracy. Specifically, compared to the best-performing lexical-based algorithms, ChatGPT achieves a remarkable increase in accuracy of 20% for the tweets dataset and approximately 25% for the Amazon reviews dataset. These findings highlight the exceptional performance of ChatGPT in sentiment analysis tasks, surpassing existing lexicon-based approaches by a significant margin. The evidence suggests it can be used for annotation on different sentiment analysis events and taskss.
Multimodal Sentiment Analysis: A Survey
May 12, 2023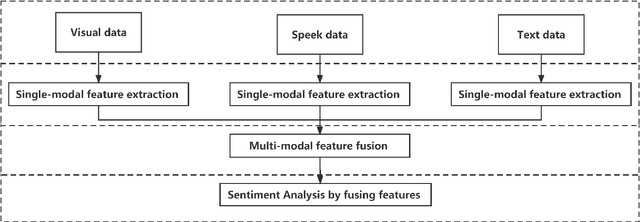
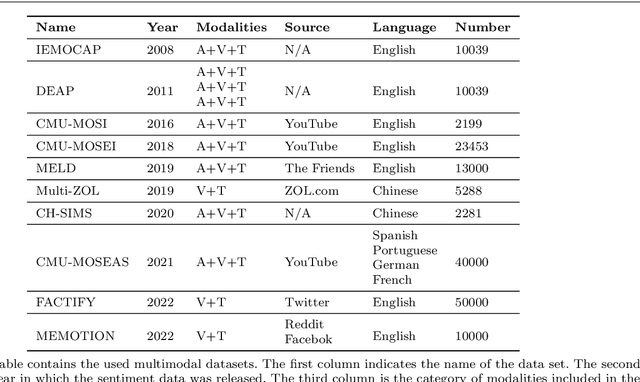
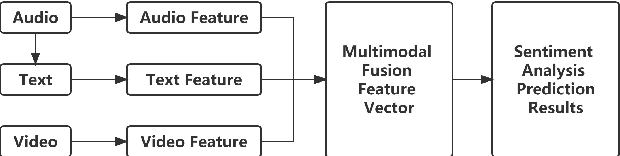
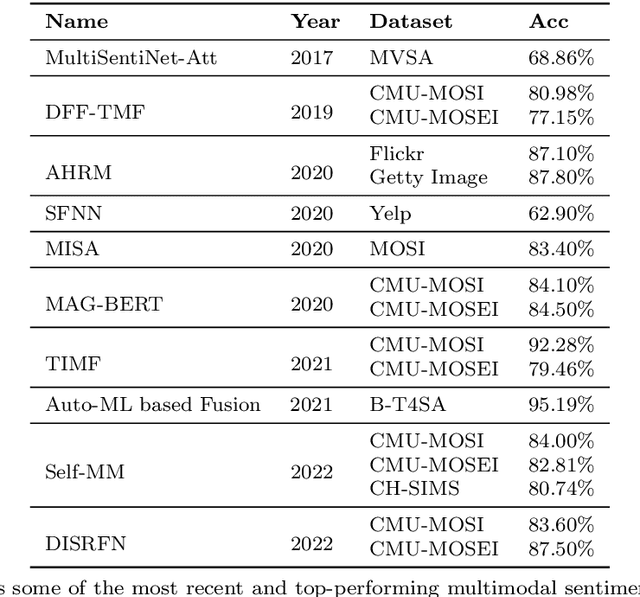
Multimodal sentiment analysis has become an important research area in the field of artificial intelligence. With the latest advances in deep learning, this technology has reached new heights. It has great potential for both application and research, making it a popular research topic. This review provides an overview of the definition, background, and development of multimodal sentiment analysis. It also covers recent datasets and advanced models, emphasizing the challenges and future prospects of this technology. Finally, it looks ahead to future research directions. It should be noted that this review provides constructive suggestions for promising research directions and building better performing multimodal sentiment analysis models, which can help researchers in this field.
Non-Compositionality in Sentiment: New Data and Analyses
Oct 31, 2023When natural language phrases are combined, their meaning is often more than the sum of their parts. In the context of NLP tasks such as sentiment analysis, where the meaning of a phrase is its sentiment, that still applies. Many NLP studies on sentiment analysis, however, focus on the fact that sentiment computations are largely compositional. We, instead, set out to obtain non-compositionality ratings for phrases with respect to their sentiment. Our contributions are as follows: a) a methodology for obtaining those non-compositionality ratings, b) a resource of ratings for 259 phrases -- NonCompSST -- along with an analysis of that resource, and c) an evaluation of computational models for sentiment analysis using this new resource.
Applying QNLP to sentiment analysis in finance
Jul 31, 2023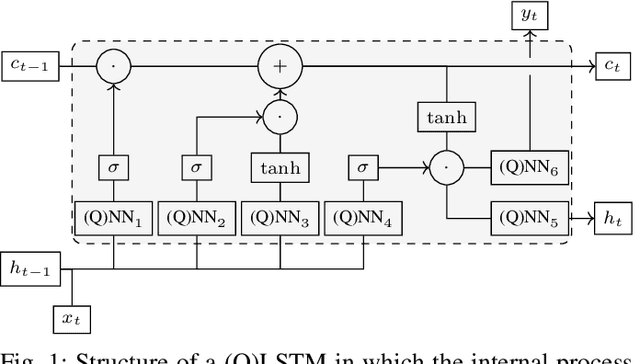
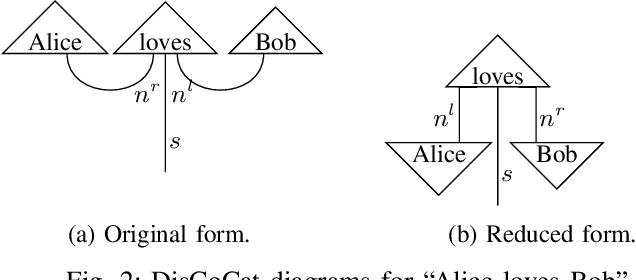
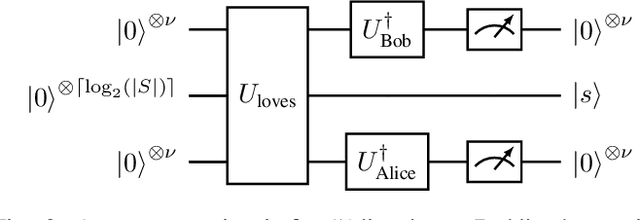
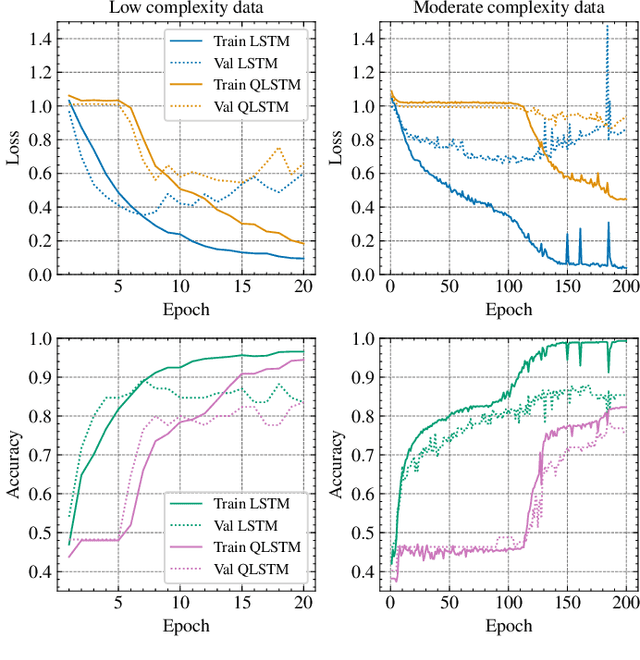
As an application domain where the slightest qualitative improvements can yield immense value, finance is a promising candidate for early quantum advantage. Focusing on the rapidly advancing field of Quantum Natural Language Processing (QNLP), we explore the practical applicability of the two central approaches DisCoCat and Quantum-Enhanced Long Short-Term Memory (QLSTM) to the problem of sentiment analysis in finance. Utilizing a novel ChatGPT-based data generation approach, we conduct a case study with more than 1000 realistic sentences and find that QLSTMs can be trained substantially faster than DisCoCat while also achieving close to classical results for their available software implementations.
A Review of Hybrid and Ensemble in Deep Learning for Natural Language Processing
Dec 09, 2023This review presents a comprehensive exploration of hybrid and ensemble deep learning models within Natural Language Processing (NLP), shedding light on their transformative potential across diverse tasks such as Sentiment Analysis, Named Entity Recognition, Machine Translation, Question Answering, Text Classification, Generation, Speech Recognition, Summarization, and Language Modeling. The paper systematically introduces each task, delineates key architectures from Recurrent Neural Networks (RNNs) to Transformer-based models like BERT, and evaluates their performance, challenges, and computational demands. The adaptability of ensemble techniques is emphasized, highlighting their capacity to enhance various NLP applications. Challenges in implementation, including computational overhead, overfitting, and model interpretation complexities, are addressed alongside the trade-off between interpretability and performance. Serving as a concise yet invaluable guide, this review synthesizes insights into tasks, architectures, and challenges, offering a holistic perspective for researchers and practitioners aiming to advance language-driven applications through ensemble deep learning in NLP.
Analyzing Public Reactions, Perceptions, and Attitudes during the MPox Outbreak: Findings from Topic Modeling of Tweets
Dec 19, 2023The recent outbreak of the MPox virus has resulted in a tremendous increase in the usage of Twitter. Prior works in this area of research have primarily focused on the sentiment analysis and content analysis of these Tweets, and the few works that have focused on topic modeling have multiple limitations. This paper aims to address this research gap and makes two scientific contributions to this field. First, it presents the results of performing Topic Modeling on 601,432 Tweets about the 2022 Mpox outbreak that were posted on Twitter between 7 May 2022 and 3 March 2023. The results indicate that the conversations on Twitter related to Mpox during this time range may be broadly categorized into four distinct themes - Views and Perspectives about Mpox, Updates on Cases and Investigations about Mpox, Mpox and the LGBTQIA+ Community, and Mpox and COVID-19. Second, the paper presents the findings from the analysis of these Tweets. The results show that the theme that was most popular on Twitter (in terms of the number of Tweets posted) during this time range was Views and Perspectives about Mpox. This was followed by the theme of Mpox and the LGBTQIA+ Community, which was followed by the themes of Mpox and COVID-19 and Updates on Cases and Investigations about Mpox, respectively. Finally, a comparison with related studies in this area of research is also presented to highlight the novelty and significance of this research work.
GPT-4V with Emotion: A Zero-shot Benchmark for Multimodal Emotion Understanding
Dec 07, 2023Recently, GPT-4 with Vision (GPT-4V) has shown remarkable performance across various multimodal tasks. However, its efficacy in emotion recognition remains a question. This paper quantitatively evaluates GPT-4V's capabilities in multimodal emotion understanding, encompassing tasks such as facial emotion recognition, visual sentiment analysis, micro-expression recognition, dynamic facial emotion recognition, and multimodal emotion recognition. Our experiments show that GPT-4V exhibits impressive multimodal and temporal understanding capabilities, even surpassing supervised systems in some tasks. Despite these achievements, GPT-4V is currently tailored for general domains. It performs poorly in micro-expression recognition that requires specialized expertise. The main purpose of this paper is to present quantitative results of GPT-4V on emotion understanding and establish a zero-shot benchmark for future research. Code and evaluation results are available at: https://github.com/zeroQiaoba/gpt4v-emotion.
Syntactic Fusion: Enhancing Aspect-Level Sentiment Analysis Through Multi-Tree Graph Integration
Nov 28, 2023Recent progress in aspect-level sentiment classification has been propelled by the incorporation of graph neural networks (GNNs) leveraging syntactic structures, particularly dependency trees. Nevertheless, the performance of these models is often hampered by the innate inaccuracies of parsing algorithms. To mitigate this challenge, we introduce SynthFusion, an innovative graph ensemble method that amalgamates predictions from multiple parsers. This strategy blends diverse dependency relations prior to the application of GNNs, enhancing robustness against parsing errors while avoiding extra computational burdens. SynthFusion circumvents the pitfalls of overparameterization and diminishes the risk of overfitting, prevalent in models with stacked GNN layers, by optimizing graph connectivity. Our empirical evaluations on the SemEval14 and Twitter14 datasets affirm that SynthFusion not only outshines models reliant on single dependency trees but also eclipses alternative ensemble techniques, achieving this without an escalation in model complexity.