 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
KazSAnDRA: Kazakh Sentiment Analysis Dataset of Reviews and Attitudes
Apr 09, 2024
This paper presents KazSAnDRA, a dataset developed for Kazakh sentiment analysis that is the first and largest publicly available dataset of its kind. KazSAnDRA comprises an extensive collection of 180,064 reviews obtained from various sources and includes numerical ratings ranging from 1 to 5, providing a quantitative representation of customer attitudes. The study also pursued the automation of Kazakh sentiment classification through the development and evaluation of four machine learning models trained for both polarity classification and score classification. Experimental analysis included evaluation of the results considering both balanced and imbalanced scenarios. The most successful model attained an F1-score of 0.81 for polarity classification and 0.39 for score classification on the test sets. The dataset and fine-tuned models are open access and available for download under the Creative Commons Attribution 4.0 International License (CC BY 4.0) through our GitHub repository.
EFSA: Towards Event-Level Financial Sentiment Analysis
Apr 08, 2024In this paper, we extend financial sentiment analysis~(FSA) to event-level since events usually serve as the subject of the sentiment in financial text. Though extracting events from the financial text may be conducive to accurate sentiment predictions, it has specialized challenges due to the lengthy and discontinuity of events in a financial text. To this end, we reconceptualize the event extraction as a classification task by designing a categorization comprising coarse-grained and fine-grained event categories. Under this setting, we formulate the \textbf{E}vent-Level \textbf{F}inancial \textbf{S}entiment \textbf{A}nalysis~(\textbf{EFSA} for short) task that outputs quintuples consisting of (company, industry, coarse-grained event, fine-grained event, sentiment) from financial text. A large-scale Chinese dataset containing $12,160$ news articles and $13,725$ quintuples is publicized as a brand new testbed for our task. A four-hop Chain-of-Thought LLM-based approach is devised for this task. Systematically investigations are conducted on our dataset, and the empirical results demonstrate the benchmarking scores of existing methods and our proposed method can reach the current state-of-the-art. Our dataset and framework implementation are available at https://anonymous.4open.science/r/EFSA-645E
TRABSA: Interpretable Sentiment Analysis of Tweets using Attention-based BiLSTM and Twitter-RoBERTa
Mar 30, 2024Sentiment analysis is crucial for understanding public opinion and consumer behavior. Existing models face challenges with linguistic diversity, generalizability, and explainability. We propose TRABSA, a hybrid framework integrating transformer-based architectures, attention mechanisms, and BiLSTM networks to address this. Leveraging RoBERTa-trained on 124M tweets, we bridge gaps in sentiment analysis benchmarks, ensuring state-of-the-art accuracy. Augmenting datasets with tweets from 32 countries and US states, we compare six word-embedding techniques and three lexicon-based labeling techniques, selecting the best for optimal sentiment analysis. TRABSA outperforms traditional ML and deep learning models with 94% accuracy and significant precision, recall, and F1-score gains. Evaluation across diverse datasets demonstrates consistent superiority and generalizability. SHAP and LIME analyses enhance interpretability, improving confidence in predictions. Our study facilitates pandemic resource management, aiding resource planning, policy formation, and vaccination tactics.
A Hybrid Approach To Aspect Based Sentiment Analysis Using Transfer Learning
Mar 25, 2024Aspect-Based Sentiment Analysis (ABSA) aims to identify terms or multiword expressions (MWEs) on which sentiments are expressed and the sentiment polarities associated with them. The development of supervised models has been at the forefront of research in this area. However, training these models requires the availability of manually annotated datasets which is both expensive and time-consuming. Furthermore, the available annotated datasets are tailored to a specific domain, language, and text type. In this work, we address this notable challenge in current state-of-the-art ABSA research. We propose a hybrid approach for Aspect Based Sentiment Analysis using transfer learning. The approach focuses on generating weakly-supervised annotations by exploiting the strengths of both large language models (LLM) and traditional syntactic dependencies. We utilise syntactic dependency structures of sentences to complement the annotations generated by LLMs, as they may overlook domain-specific aspect terms. Extensive experimentation on multiple datasets is performed to demonstrate the efficacy of our hybrid method for the tasks of aspect term extraction and aspect sentiment classification. Keywords: Aspect Based Sentiment Analysis, Syntactic Parsing, large language model (LLM)
TCAN: Text-oriented Cross Attention Network for Multimodal Sentiment Analysis
Apr 06, 2024Multimodal Sentiment Analysis (MSA) endeavors to understand human sentiment by leveraging language, visual, and acoustic modalities. Despite the remarkable performance exhibited by previous MSA approaches, the presence of inherent multimodal heterogeneities poses a challenge, with the contribution of different modalities varying considerably. Past research predominantly focused on improving representation learning techniques and feature fusion strategies. However, many of these efforts overlooked the variation in semantic richness among different modalities, treating each modality uniformly. This approach may lead to underestimating the significance of strong modalities while overemphasizing the importance of weak ones. Motivated by these insights, we introduce a Text-oriented Cross-Attention Network (TCAN), emphasizing the predominant role of the text modality in MSA. Specifically, for each multimodal sample, by taking unaligned sequences of the three modalities as inputs, we initially allocate the extracted unimodal features into a visual-text and an acoustic-text pair. Subsequently, we implement self-attention on the text modality and apply text-queried cross-attention to the visual and acoustic modalities. To mitigate the influence of noise signals and redundant features, we incorporate a gated control mechanism into the framework. Additionally, we introduce unimodal joint learning to gain a deeper understanding of homogeneous emotional tendencies across diverse modalities through backpropagation. Experimental results demonstrate that TCAN consistently outperforms state-of-the-art MSA methods on two datasets (CMU-MOSI and CMU-MOSEI).
M2SA: Multimodal and Multilingual Model for Sentiment Analysis of Tweets
Apr 02, 2024In recent years, multimodal natural language processing, aimed at learning from diverse data types, has garnered significant attention. However, there needs to be more clarity when it comes to analysing multimodal tasks in multi-lingual contexts. While prior studies on sentiment analysis of tweets have predominantly focused on the English language, this paper addresses this gap by transforming an existing textual Twitter sentiment dataset into a multimodal format through a straightforward curation process. Our work opens up new avenues for sentiment-related research within the research community. Additionally, we conduct baseline experiments utilising this augmented dataset and report the findings. Notably, our evaluations reveal that when comparing unimodal and multimodal configurations, using a sentiment-tuned large language model as a text encoder performs exceptionally well.
Sentiment Analysis of Citations in Scientific Articles Using ChatGPT: Identifying Potential Biases and Conflicts of Interest
Apr 06, 2024Scientific articles play a crucial role in advancing knowledge and informing research directions. One key aspect of evaluating scientific articles is the analysis of citations, which provides insights into the impact and reception of the cited works. This article introduces the innovative use of large language models, particularly ChatGPT, for comprehensive sentiment analysis of citations within scientific articles. By leveraging advanced natural language processing (NLP) techniques, ChatGPT can discern the nuanced positivity or negativity of citations, offering insights into the reception and impact of cited works. Furthermore, ChatGPT's capabilities extend to detecting potential biases and conflicts of interest in citations, enhancing the objectivity and reliability of scientific literature evaluation. This study showcases the transformative potential of artificial intelligence (AI)-powered tools in enhancing citation analysis and promoting integrity in scholarly research.
Ensemble Language Models for Multilingual Sentiment Analysis
Mar 10, 2024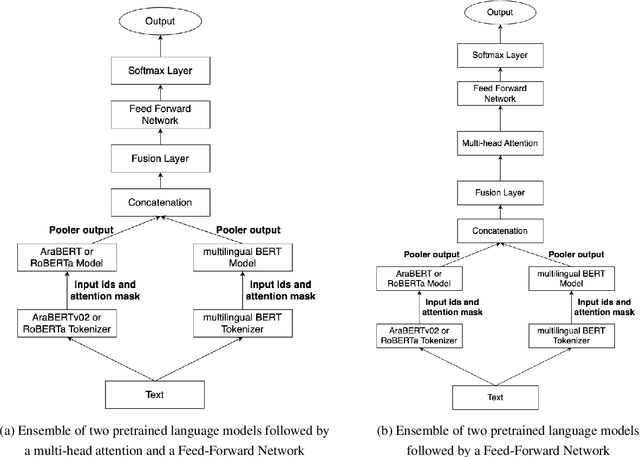
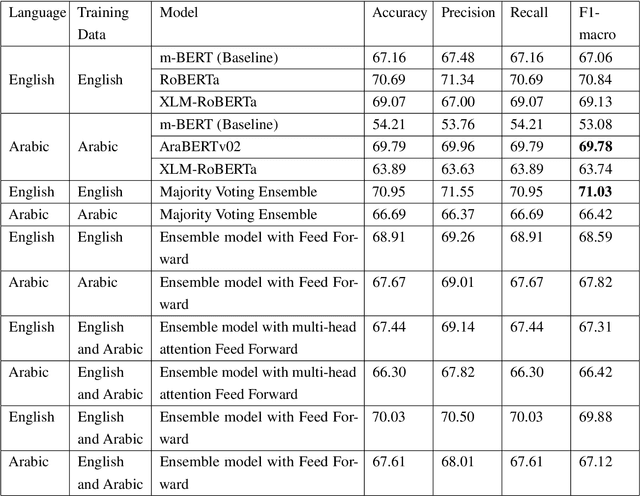
The rapid advancement of social media enables us to analyze user opinions. In recent times, sentiment analysis has shown a prominent research gap in understanding human sentiment based on the content shared on social media. Although sentiment analysis for commonly spoken languages has advanced significantly, low-resource languages like Arabic continue to get little research due to resource limitations. In this study, we explore sentiment analysis on tweet texts from SemEval-17 and the Arabic Sentiment Tweet dataset. Moreover, We investigated four pretrained language models and proposed two ensemble language models. Our findings include monolingual models exhibiting superior performance and ensemble models outperforming the baseline while the majority voting ensemble outperforms the English language.
Research on the Application of Deep Learning-based BERT Model in Sentiment Analysis
Mar 13, 2024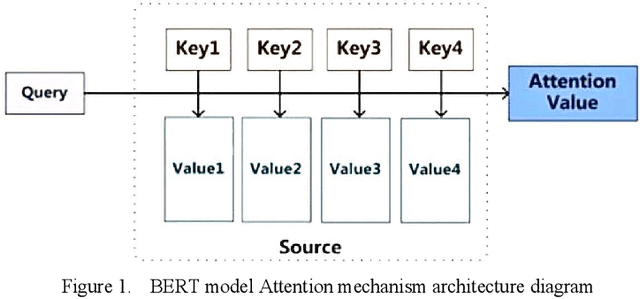
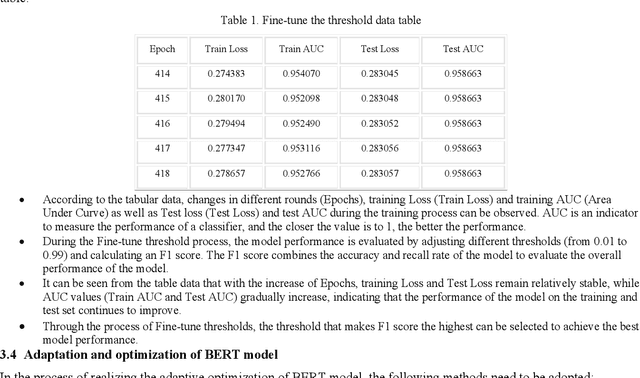
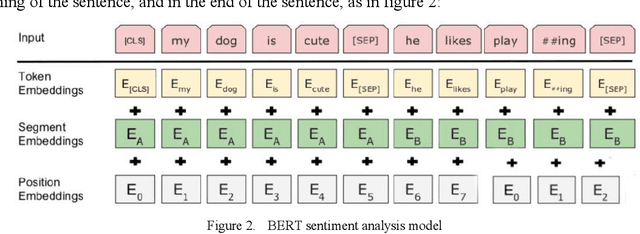
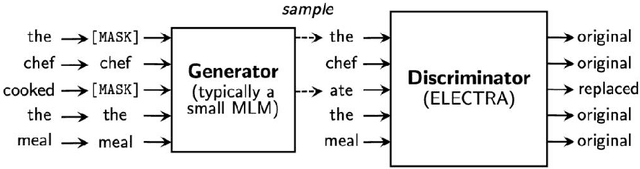
This paper explores the application of deep learning techniques, particularly focusing on BERT models, in sentiment analysis. It begins by introducing the fundamental concept of sentiment analysis and how deep learning methods are utilized in this domain. Subsequently, it delves into the architecture and characteristics of BERT models. Through detailed explanation, it elucidates the application effects and optimization strategies of BERT models in sentiment analysis, supported by experimental validation. The experimental findings indicate that BERT models exhibit robust performance in sentiment analysis tasks, with notable enhancements post fine-tuning. Lastly, the paper concludes by summarizing the potential applications of BERT models in sentiment analysis and suggests directions for future research and practical implementations.